 存儲系統中的算法:LSM樹設計原理
存儲系統中的算法:LSM樹設計原理
我在上篇文章Apache Pulsar 的架構設計中介紹了 Pulsar 存算分離的架構,其中 broker 只負責計算,由 BookKeeper 負責底層的存儲,我還畫了這樣一張圖說明 BookKeeper 讀寫分離的設計:
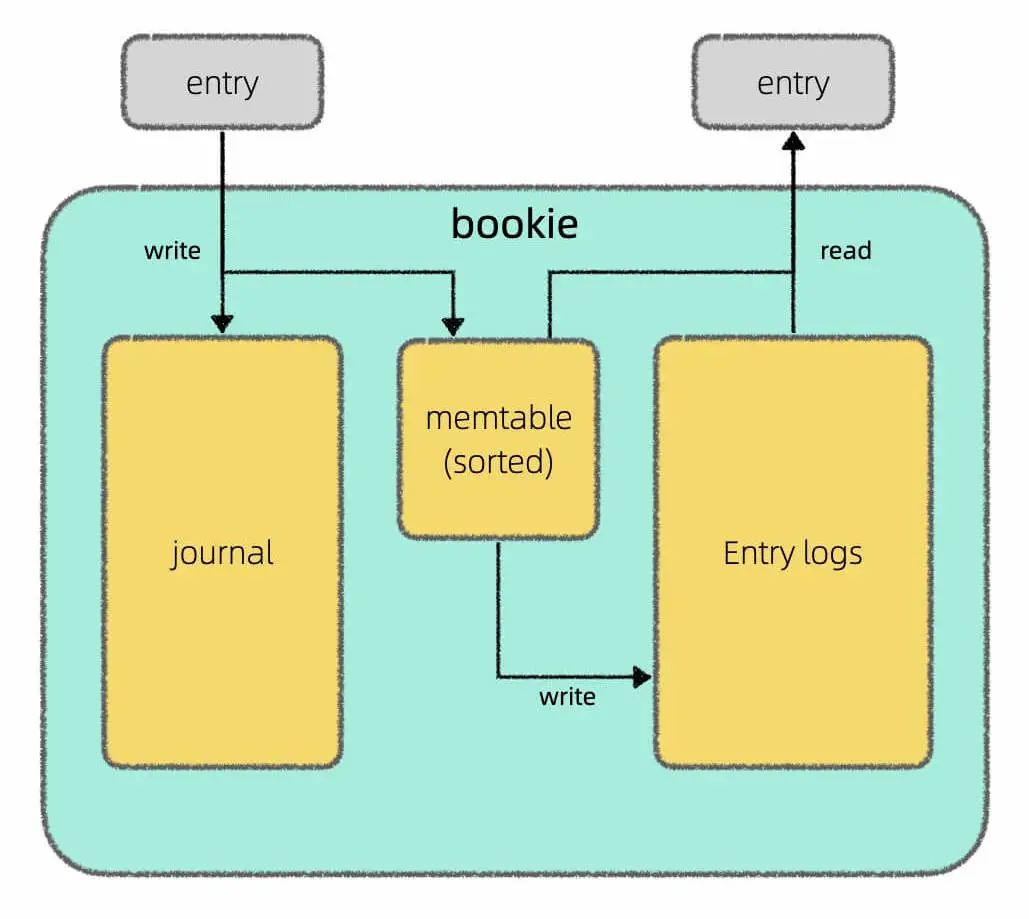
但是再深究下去,memtable具體是以怎樣的格式持久化到磁盤上的呢?又是用什么算法高效查找一條消息的呢?
通過學習相關資料,我發現 Apache BookKeeper 底層存儲引擎用的是 Facebook 開源的 RocksDB,而 RocksDB 又是基于 Google 開源的 LevelDB 改造的,而 LevelDB 的核心是一個叫做 LSM 樹(Log Structured Merge Tree)的結構。
LevelDB 整個庫的代碼只有幾百 KB,所以我去研究了 LSM 樹的代碼實現,總結了這篇文章,帶你了解 LSM 樹的設計原理。
什么是 LSM 樹呢?如果說到 B+ 樹大家應該不陌生,像 MySQL 這樣的關系型數據庫底層一般用 B+ 樹結構來存儲數據。LSM 樹其實就是另一種存儲數據的結構,常見于日志存儲系統中。
首先,我們先來聊聊存儲系統。
內存數據結構 vs 磁盤數據結構
正如前文學習數據結構和算法的框架思維所說,一切數據結構從根本上講都是增刪查改,但在具體實現上,磁盤數據結構和內存數據結構會有比較大的差異。
內存數據結構你直接 new 一個出來就行了,不用關心這個結構在內存中是如何布局的,這些都由操作系統和編程語言代勞了。
但磁盤就不一樣,考慮到磁盤讀取的操作效率相對比較低,且每次只能讀取固定大小的磁盤數據,你要自己設計數據的存儲布局,規定每個字節存什么信息,然后基于你設計的存儲布局實現增刪查改的 API,比較枯燥瑣碎。
比如說,學過 MySQL 的話應該比較熟悉 B+ 樹結構,但你肯定不容易看懂 B+ 樹的代碼。因為 B+ 樹是磁盤數據結構,雖然原理上可以理解為 BST 的加強版,但考慮到數據文件格式的設計,真正的代碼實現非常復雜。
所以一般來說,我們了解磁盤數據結構的原理,了解各個操作的時間復雜度就可以了,沒必要特別糾結它的具體實現。
數據可變 vs 數據不可變
存儲結構可以粗略分為兩類:數據可變的和數據不可變的。所謂可變,就是說已經插入的數據還可以原地進行修改,不可變就是說已經插入的數據就不能再修改了。
B 樹是數據可變的代表結構(B+ 樹等衍生結構都歸為 B 樹一族)。你就想想 BST 吧,數據存在節點上,我們可以隨意插入、刪除、修改 BST 中的節點。
B 樹的理論增刪查改性能和 BST 一樣都是 logN,但 B 樹的實際寫入效率并不是特別高:
一方面是因為 B 樹需要分裂合并等操作保證整棵樹的平衡性,這里面涉及很多磁盤隨機讀寫的操作,性能會比較差;另一方面考慮到并發場景,修改 B 樹結構時需要比較復雜的鎖機制保證并發安全,也會一定程度影響效率。
綜上,B 樹的難點在于平衡性維護和并發控制,一般用在讀多寫少的場景。
LSM 樹是數據不可變的代表結構。你只能在尾部追加新數據,不能修改之前已經插入的數據。
如果不能修改以前的數據,是不是就不能提供刪、查、改的操作 API 呢?其實是可以的。
我們只需要提供set(key, val)和get(key)兩個 API 即可。查詢操作靠get(key),增刪改操作都可以由set(key, val)實現:
如果set的key不存在就是新增鍵值對,如果已經存在,就是更新鍵值對;如果把val設置為一個特殊值(比如 null)就可以代表key被刪掉了(墓碑機制)。
那么我對某個鍵key做了一系列操作后,我只要找到最近一次的操作,就能知道這個鍵當前的值是多少了。
從磁盤的角度來說,在尾部追加的寫入效率非常高,因為不需要像 B 樹那樣維護復雜的樹形結構嘛。但代價就是,查找效率肯定比較低,因為只能通過線性遍歷去查找操作記錄。
后面我會講講真正的 LSM 樹如何針對讀場景進行優化,但再怎么優化,肯定也達不到 B 樹的讀取效率。
同時,LSM 樹還有一個明顯弊端就是存在空間放大。在 B 樹中一個鍵值對就占用一個節點,我更新這個鍵 100 次,它還是只占用一個節點。但在 LSM 樹中,如果我更新一個鍵 100 次,就相當于寫入了 100 條數據,會消耗更多空間。
后面會講到,這個問題的解決方案是壓實(compact),把操作序列中失效的歷史操作消除掉,只保留最近的操作記錄。
綜上,LSM 樹的難點在于 compact 操作和讀取數據時的效率優化,一般用在寫多讀少的場景。
有序 vs 無序
可以說,存儲結構的有序程度直接決定了該類結構的讀寫性能上限。有序度越高,讀性能越強,但相應的,維護有序性的成本也越高,寫入性能也就會越差。
你看 B 樹,作為 BST 的加強版,實際上是維護了所有數據的有序性,讀取性能必然起飛,但寫入性能你也別抱太大希望。
LSM 樹不可能向 B 樹那樣維護所有數據的有序性,但可以維護局部數據的有序性,從而一定程度提升讀性能。
LSM 樹的設計
就我的理解,LSM 樹其實不是一種數據結構,而是一種存儲方案。這里面涉及三個重要的數據組件:memtable,log,SSTable,正如我在Apache Pulsar 的架構設計中畫的這幅圖:
其中Journal就是log,Entry Log就是若干SSTable的集合,叫法不同罷了。
memtable是紅黑樹或者跳表這樣的有序內存數據結構,起到緩存和排序的作用,把新寫入的數據按照鍵的大小進行排序。當memtable到達一定大小之后,會被轉化成SSTable格式刷入磁盤持久化存儲。
SSTable(Sorted String Table)說白了就是一個特殊格式的文件,其中的數據按照鍵的大小排列,你可以把它類比成一個有序數組。而 LSM 樹,說白了就是若干SSTable的集合。
log文件記錄操作日志,在數據寫入memtable的同時也會刷盤寫入到log文件,作用是數據恢復。比如在memtable中的數據還沒轉化成SSTable持久化到磁盤時,如果突然斷電,那么memtable里面的數據都會丟失,但有log文件在,就可以恢復這些數據。當然,等memtable中的數據成功轉化成SSTable落盤之后,log文件中對應的操作日志就沒必要存在了,可以被刪除。
LSM 樹的set寫入過程并不復雜:寫入log和memtable,最后轉化成一個SSTable持久化到磁盤就行了。
最關鍵的應該是讀取和 compact 的過程:SSTable要如何組織,才能快速get到一個key對應的val呢?如何定期對所有 SSTable 做 compact 瘦身呢?
其實有多種方案,其中比較常用的方案是按照層級組織SSTable:
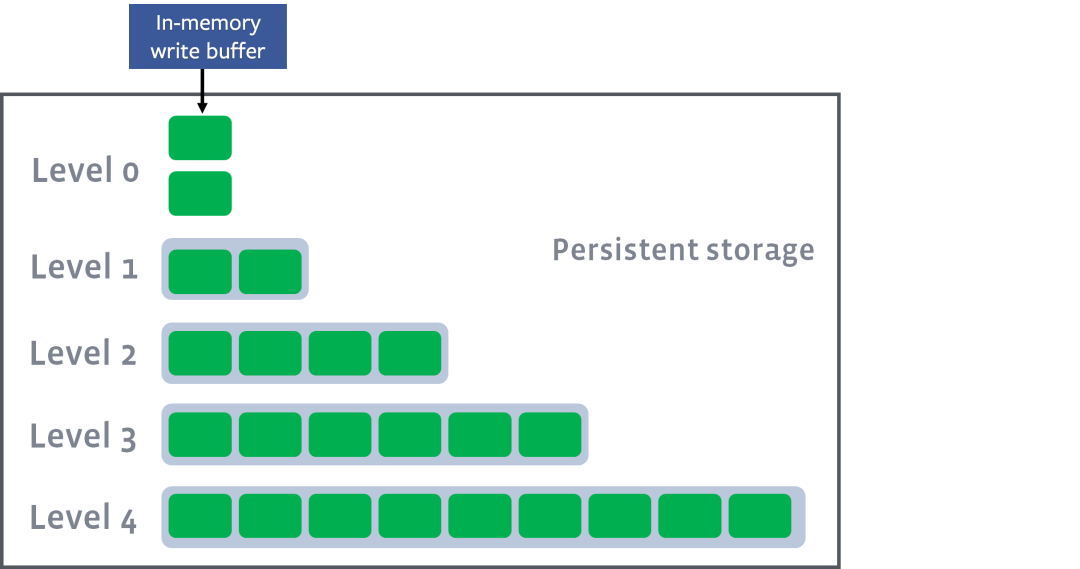
https://github.com/facebook/rocksdb/wiki/Leveled-Compaction
圖中每個綠色方塊代表一個SSTable,若干個SSTable構成一層,總共有若干層,每層能夠容納的SSTable數量上限依次遞增。
新刷入的SSTable在第 0 層,如果某一層的SSTable個數超過上限,則會觸發 compact 操作,從該層選出若干SSTable合并成一個更大的SSTable,移動下一層:
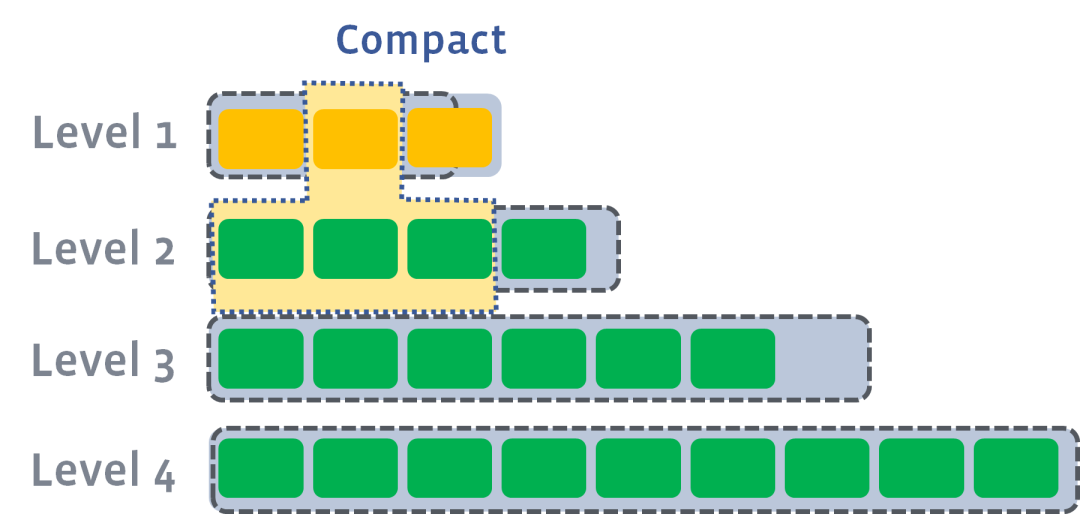
https://github.com/facebook/rocksdb/wiki/Leveled-Compaction
每個SSTable就好比一個有序數組/鏈表,多個SSTable的合并就是前文鏈表雙指針技巧匯總中合并多個有序鏈表的邏輯。
這樣,越靠上層的數據越新,越靠下層的數據越舊,且算法保證同一層的若干SSTable的key不存在重疊:
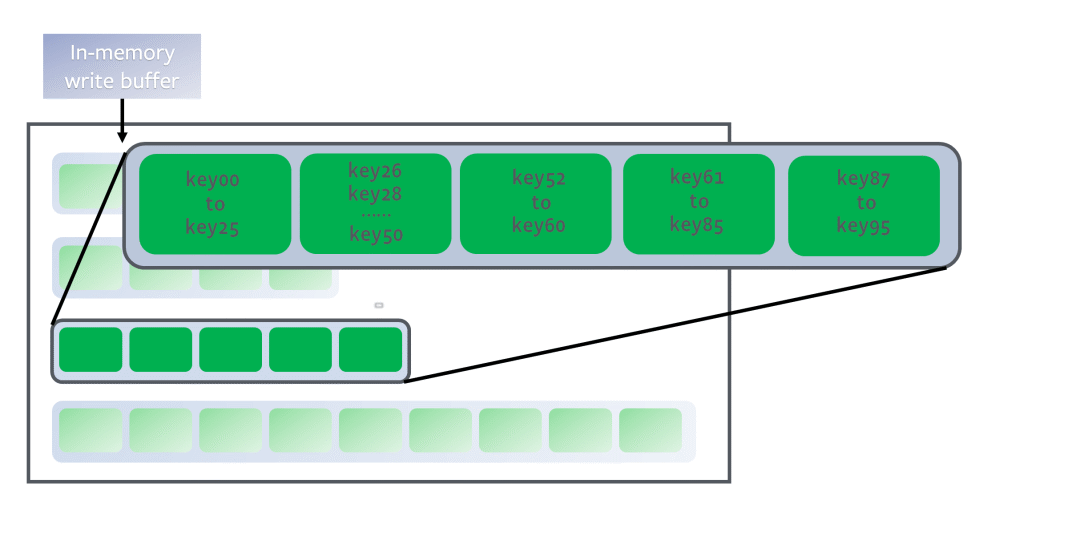
https://github.com/facebook/rocksdb/wiki/Leveled-Compaction
那么假設給一個目標鍵key27,我們只需要從上到下遍歷層,并在每一層中使用二分查找算法找到鍵區間包含key27的SSTable,然后用布隆過濾器快速判斷一下key27是否不存在這個SSTable中。如果可能存在,由于SSTable中的鍵也是有序的,可以再次運用二分查找算法在SSTable中找到鍵對應的值。
這樣,借助 LSM 樹的層級結構和SSTable的有序性,就能利用二分搜索提升查找效率,避免線性查找鍵值對。
以上就是本文的全部內容,LSM 樹的設計思路比較易于理解,但實現起來還有不少細節,如果你對具體實現感興趣,我可以推薦一些學習資料:
LevelDB 的代碼倉庫:
https://github.com/google/leveldb/issues
RocksDB 的 wiki:
https://github.com/facebook/rocksdb/wiki
審核編輯 :李倩
-
算法
+關注
關注
23文章
4612瀏覽量
92894 -
存儲系統
+關注
關注
2文章
410瀏覽量
40860 -
架構
+關注
關注
1文章
514瀏覽量
25471
原文標題:存儲系統中的算法:LSM 樹設計原理
文章出處:【微信號:TheAlgorithm,微信公眾號:算法與數據結構】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何配置 RAID 5 存儲系統

emc企業級存儲系統的特點
存儲器中訪問速度最快的是什么
計算機存儲系統的工作原理和功能
計算機存儲系統的構成
內存、存儲系統和CPU的區別
數據中心存儲系統出現故障的處理方法有哪些?數據中心存儲系統出現故障怎么辦?
兆芯攜手智云創新推出高性能NVMe企業級存儲系統
大數據時代的存儲革命:理解分布式存儲系統
什么是智能存儲系統?對比傳統存儲柜,智能存儲柜有哪些優點?

得瑞領新參編團體標準《高性能計算 分布式存儲系統技術要求》正式發布






 工商網監
工商網監
評論