") 基于使用對比學習和條件變分自編碼器的新穎框架ADS-Cap
基于使用對比學習和條件變分自編碼器的新穎框架ADS-Cap
01
研究動機
在本文中,我們研究了圖像描述(Image Captioning)領域一個新興的問題——圖像風格化描述(Stylized Image Captioning)。隨著深度學習的發(fā)展,自動圖像描述吸引了計算機視覺和自然語言處理領域研究者們的廣泛關注。現(xiàn)在的圖像描述模型可以為圖像生成準確的文本表述,但在日常生活中,人們在表達想法的同時通常還會帶有自己的情感或者風格,為此研究者們提出了圖像風格化描述任務,希望模型在準確描述視覺內(nèi)容的同時也能在描述中融入指定的語言風格。例如對于圖1展示的圖片,下面列出了傳統(tǒng)的事實性描述和四種風格帶有風格的描述,即幽默的、浪漫的、積極的和消極的,其中畫紅線的部分是體現(xiàn)風格的部分。圖像風格化描述也有許多下游應用,例如在聊天機器人中生成更吸引用戶的圖像描述、以及在社交媒體上通過有吸引力的描述啟發(fā)用戶。
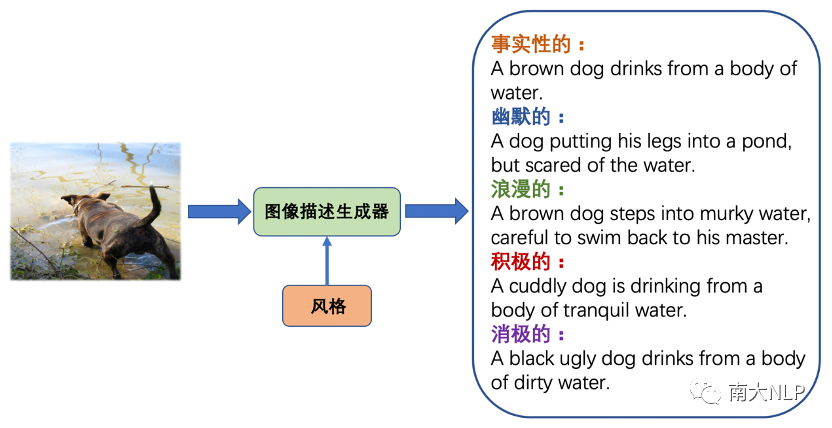 圖1圖像風格化描述(Stylized Image Captioning)任務
圖1圖像風格化描述(Stylized Image Captioning)任務
該任務的一個困難在于,收集圖片和對應人工標注的風格化描述是代價高昂的,為此我們希望能夠僅利用非成對的風格文本語料庫,讓圖像描述模型在這些風格文本上自動學習語言風格知識。因此在訓練時,我們提供事實性的圖像-描述對數(shù)據(jù)集以及不包含圖片的非成對的風格文本語料庫,希望模型通過前者學習如何準確描述圖像內(nèi)容,通過后者學習如何在描述中融入指定語言風格。
在上述設定下,該任務的一個關鍵問題是:如何高效利用成對的事實性數(shù)據(jù)和非成對的風格數(shù)據(jù)。多數(shù)以往工作遵循傳統(tǒng)的方法論:首先在大規(guī)模的成對事實性數(shù)據(jù)上預訓練一個編碼器-解碼器模型,之后在非成對的風格數(shù)據(jù)上,以語言模型的方式微調解碼器,例如StyleNet[1]和MSCap[2]。然而,我們認為在非成對風格數(shù)據(jù)上按照語言模型微調會導致模型過于關注語言風格,而忽略了生成描述和圖像內(nèi)容的一致性,因為在微調時解碼器完全與視覺輸入無關。這最終導致了圖像風格化描述模型無法生成切合圖像內(nèi)容的描述。MemCap[3]提出利用場景圖作為中間媒介,將成對和非成對數(shù)據(jù)的訓練過程統(tǒng)一為根據(jù)場景圖生成描述;然而,由于不同模態(tài)間的差異,文本和圖像抽取的場景圖依然是不一致的,這導致模型在測試時仍然無法很好地兼顧描述圖像內(nèi)容的準確性和融入語言風格。
另一個重要問題是,目前的工作基本上忽略了生成風格表達的多樣性。如圖2所示,對于三張相似場景的圖片,基線模型生成了完全相同的風格短語“to meet his lover”,而當為一張圖片生成多個風格化描述時,基線模型生成的風格表述也缺乏變化。這樣的結果極大偏離了圖像風格化描述任務的初衷:我們希望得到生動多樣的描述,而不僅僅是幾個固定的表達。我們認為造成這一問題的原因是風格語料規(guī)模較小,使得傳統(tǒng)的編碼器-解碼器模型難以生成多樣的風格模式。
 圖2:傳統(tǒng)編碼器-解碼器框架難以建模多樣化的風格表達
圖2:傳統(tǒng)編碼器-解碼器框架難以建模多樣化的風格表達
為了解決上面提到的兩方面問題,我們提出了全新的ADS-Cap框架:通過對比學習對齊圖像文本兩種模態(tài),使模型能夠將成對數(shù)據(jù)和非成對數(shù)據(jù)統(tǒng)一為條件生成的模式,使得模型能夠在準確描述圖像內(nèi)容的同時融入指定語言風格;通過條件變分自編碼器架構,引導隱空間記憶多種多樣的風格表達,有效增強生成時的多樣性。
02
貢獻
1.我們提出了一個新穎的使用對比學習和條件變分自編碼器的圖像風格化描述框架ADS-Cap。
2.當使用非成對風格文本語料庫訓練時,對比學習模塊有效地提升了生成描述與圖像內(nèi)容的一致性。
3.條件變分自編碼器框架通過在隱空間中記憶風格表達并在測試時采樣,顯著提升了圖像風格化描述生成的多樣性。
4.在兩個benchmark圖像風格化描述數(shù)據(jù)集上的實驗結果表明,我們的方法在準確性和多樣性上達到SOTA。
03
解決方案
整體模型架構如下圖3所示,主要由一個條件變分自編碼器框架和一個對比學習模塊組成。藍色部分代表模型的輸入和輸出,黃色部分代表模型的可學習參數(shù),紅色部分是我們模型編碼風格表達的隱空間。
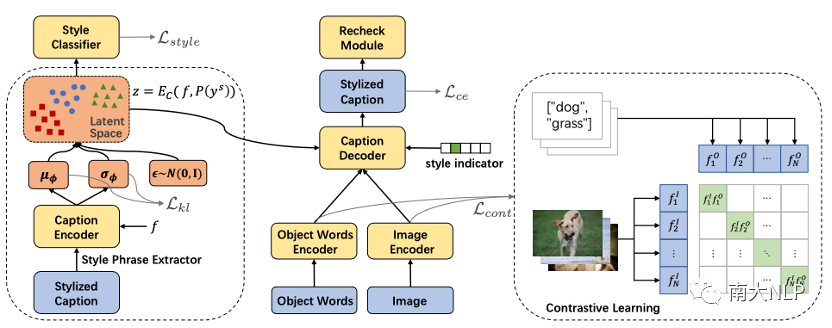 圖3:ADS-Cap框架示意圖
圖3:ADS-Cap框架示意圖
3.1對比學習
我們首先通過一個目標對象詞詞表(來自VG數(shù)據(jù)集),從非成對數(shù)據(jù)的描述中抽取目標對象詞,這樣我們就能夠將成對數(shù)據(jù)和非成對數(shù)據(jù)的訓練統(tǒng)一為條件生成的模式:對于成對的事實性數(shù)據(jù),我們根據(jù)圖像特征生成事實性的描述;對于非成對的風格數(shù)據(jù),我們根據(jù)目標對象詞生成風格化的描述。然而,在測試時,我們需要根據(jù)圖像特征生成風格化的描述,如下圖4黃色箭頭所示。為此我們的解決方案是,使用對比學習將圖像特征和目標對象詞特征編碼到同一個共享的多模態(tài)特征空間,從而對于解碼器來說,根據(jù)圖像生成和根據(jù)目標對象詞生成將不再有差異。
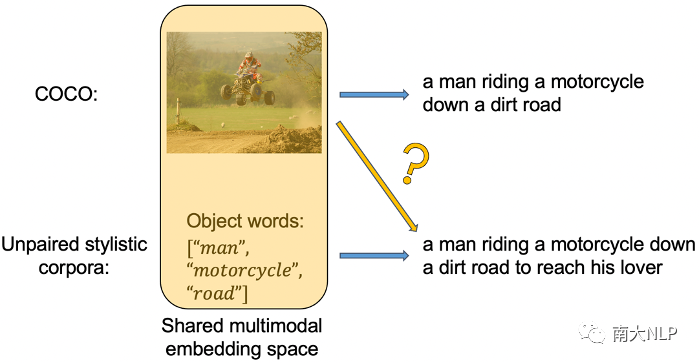 圖4:使用非成對風格文本語料庫帶來的問題
圖4:使用非成對風格文本語料庫帶來的問題
具體而言,對比學習損失最大化一個batch內(nèi)匹配樣本間的余弦相似度,同時最小化不匹配樣本間的余弦相似度[4],從而對齊圖像和目標對象詞兩種模態(tài)的特征到同一個共享的多模態(tài)特征空間中。
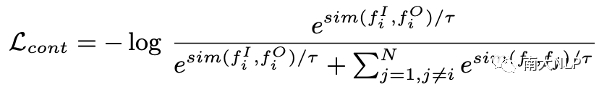
3.2條件變分自編碼器框架
為了提高生成描述的多樣性,我們使用條件變分自編碼器(CVAE)代替了傳統(tǒng)的編碼器-解碼器架構,主要是因為CVAE在許多生成任務上多樣性表現(xiàn)較好,而且對于圖像風格化描述任務來說,可以利用隱空間自動記憶多種多樣的風格表達,從而在測試時在隱空間不同區(qū)域采樣就可以生成帶有不同風格短語的描述。如圖5所示,CVAE的編碼器將樣本的風格表達編碼到隱變量,解碼器通過該隱變量輔助嘗試還原輸入樣本。之后,CVAE的訓練原理也就是KL散度損失和重建損失使得各種各樣的風格表達能夠均勻地分布在隱空間中。
除此之外,我們在隱變量上增加了一個風格分類器,以隱變量為輸入,預測該隱變量對應樣本的風格。這樣一個輔助損失有兩方面好處,一個是可以引導隱空間編碼與風格相關的信息;另外這個單層神經(jīng)網(wǎng)絡+softmax的分類器實際上也將整個隱空間按風格劃分了,這樣在測試時,我們就可以通過拒絕采樣得到我們想要風格的隱變量。
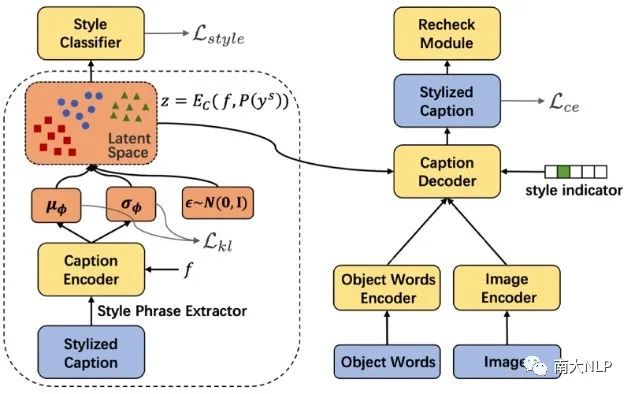 圖5:條件變分自編碼器框架及風格分類器
圖5:條件變分自編碼器框架及風格分類器
04
實驗
我們在圖像風格化描述的兩個benchmark數(shù)據(jù)集FlickrStyle10K[1]和SentiCap[5]上進行實驗。前者包含幽默和浪漫兩種風格,各7000張圖片和對應的風格化描述;后者包含積極和消極兩種風格,共2360張圖片以及9513個風格化描述。數(shù)據(jù)集劃分以及實驗設定上,我們與MSCap[2]和MemCap[3]保持一致。
4.1內(nèi)容準確性&風格準確性
在性能方面,我們首先比較了之前工作采用的內(nèi)容準確率和風格準確率。其中內(nèi)容準確率采用Bleu、CIDEr這類計算和參考句子間n元組重復度的指標,風格準確率則使用生成句子的困惑度ppl、以及一個預訓練好的風格判別器給出的風格準確率cls。可以看到如表1所示,我們的方法相比之前工作在幾乎所有指標上取得了顯著的提升,特別是在FlickrStyle這個風格更復雜的數(shù)據(jù)集上。這也側面證實了以往工作忽略了生成描述和圖像內(nèi)容一致性這個問題,而我們的方法能夠在融入語言風格的同時保持和圖像內(nèi)容的一致性。
表1:內(nèi)容準確性和風格準確性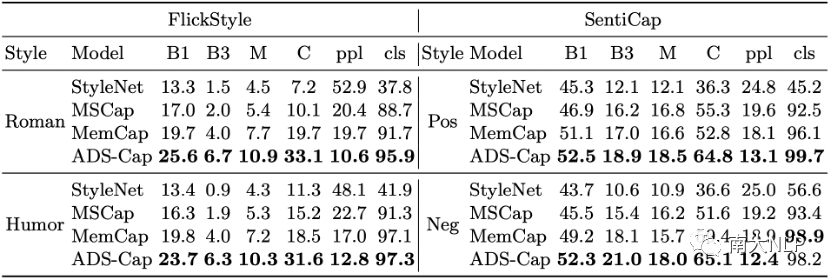
4.2多樣性
我們比較將我們的方法與編碼器-解碼器基線模型在兩類多樣性上進行了比較。圖6展示了兩類多樣性以及我們方法的效果。
 圖6:兩類多樣性及樣例展示
圖6:兩類多樣性及樣例展示
第一類是圖像間的多樣性(Diversity across Images),也就是我們希望同一場景下不同圖像生成的風格化描述應該是多樣的。為此我們考慮了:1.唯一性,不同的風格短語戰(zhàn)全部風格短語的比例;2.均勻性,風格詞概率分布的熵(下式)。從下表2結果中可以看到,在七種典型場景下(各種人物以及動物),我們的CVAE模型均顯著高于編碼器-解碼器基線,但距離人類的表現(xiàn)還有不少距離。
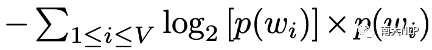
表2:相似場景下風格化描述多樣性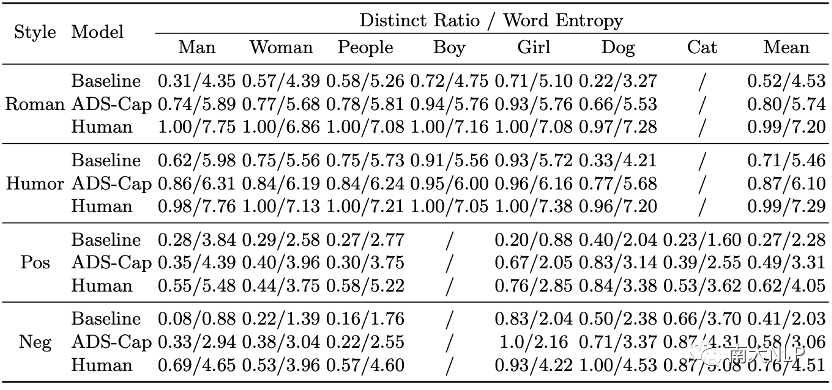
第二類是經(jīng)典的為一張圖像生成多個風格化描述的多樣性。為此我們考慮了圖像描述領域中量此類多樣性的兩個指標:Distinct和Div-n,前者計算不同的風格短語的比例,后者計算不同的n元組的比例。從表2中可以看到,我們的方法同樣優(yōu)于基線模型。
表3:為一張圖像生成多個風格化描述的多樣性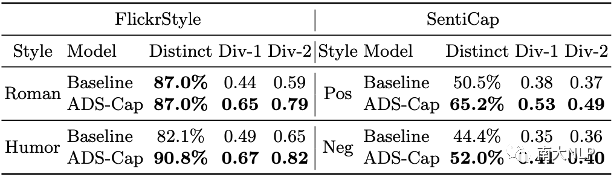
4.3效果分析
為了展示分析對比學習和條件變分自編碼器框架的效果,我們進行了一些可視化。
圖7給出了使用對比學習前后的特征空間分析,綠色代表的是目標對象詞特征,紅色是圖像特征。可以看到對比學習很好地對齊了兩類特征(例如狗的目標對象詞特征和對應圖像特征十分相近),從而成功統(tǒng)一了成對事實性數(shù)據(jù)和非成對風格數(shù)據(jù)的訓練。
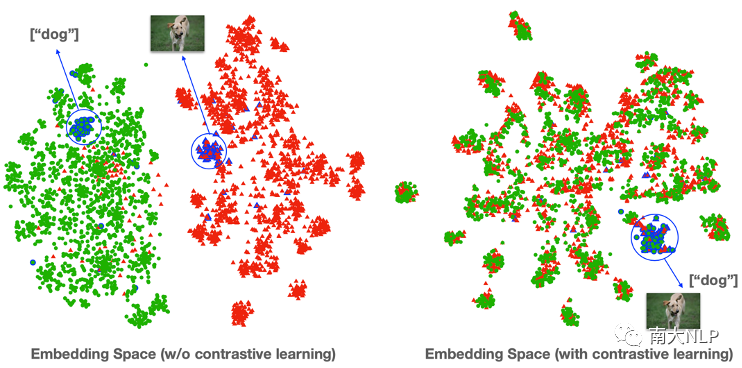 圖7:對比學習效果
圖7:對比學習效果
如圖8所示,訓練好的CVAE隱空間實際上被按照風格劃分為不同的區(qū)域,并且在每個區(qū)域中編碼了多種多樣的風格表達,例如對于浪漫的風格,這里展示了其中幾個點對應的風格表達,有enjoying the beauty of nature、with full joy等等;因此,測試時在每個區(qū)域中采樣即可得到多樣化的風格描述。
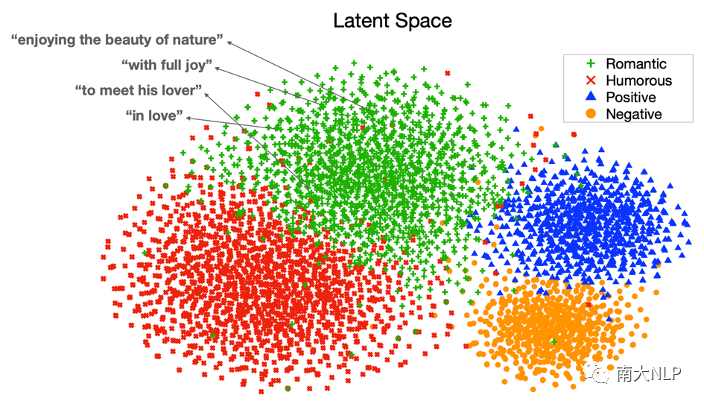 圖8:條件變分自編碼器隱空間
圖8:條件變分自編碼器隱空間
05
總結
本工作為圖像風格化描述任務提出了一個使用對比學習和條件變分自編碼器的新穎框架ADS-Cap。我們的模型能夠高效地利用非成對風格文本語料庫訓練,并能夠生成視覺內(nèi)容準確、文本風格可控且風格表達多樣的圖像風格化描述。在兩個圖像風格化描述benchmark上的實驗證明了我們方法的有效性。
-
編碼器
+關注
關注
45文章
3659瀏覽量
134980 -
模型
+關注
關注
1文章
3286瀏覽量
49007 -
自然語言
+關注
關注
1文章
289瀏覽量
13376
原文標題:NLPCC'22 | 一種兼具準確性和多樣性的圖像風格化描述生成框架
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
基于變分自編碼器的異常小區(qū)檢測
是什么讓變分自編碼器成為如此成功的多媒體生成工具呢?

自編碼器是什么?有什么用
自編碼器介紹
稀疏自編碼器及TensorFlow實現(xiàn)詳解
基于變分自編碼器的海面艦船軌跡預測算法
自編碼器基礎理論與實現(xiàn)方法、應用綜述
一種多通道自編碼器深度學習的入侵檢測方法

一種基于變分自編碼器的人臉圖像修復方法

基于變分自編碼器的網(wǎng)絡表示學習方法
結合深度學習的自編碼器端到端物理層優(yōu)化方案
自編碼器神經(jīng)網(wǎng)絡應用及實驗綜述
基于交叉熵損失函欻的深度自編碼器診斷模型
自編碼器 AE(AutoEncoder)程序






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論