 MySQL的頁結構及原理
MySQL的頁結構及原理
索引可以說是每個工程師的必備技能點,明白索引的原理對于寫出高質量的 SQL 至關重要,今天我們就從 0 到 1 來理解下索引的原理,相信大家看完不光對索引還會對 MySQL 中 InnoDB 存儲引擎的最小存儲單位「頁」會有更深刻的認識
從實際需求出發
假設有如下用戶表:
CREATETABLE`user`( `id`int(11)unsignedNOTNULLAUTO_INCREMENT, `name`int(11)DEFAULTNULLCOMMENT'姓名', `age`tinyint(3)unsignedDEFAULTNULLCOMMENT'年齡', `height`int(11)DEFAULTNULLCOMMENT'身高', PRIMARYKEY(`id`) )ENGINE=InnoDBDEFAULTCHARSET=utf8COMMENT='用戶表';
可以看到存儲引擎使用的是 InnoDB,我們先來看針對此表而言工作中比較常用的 SQL 語句都有哪此,畢竟技術是要為業務需求服務的,
1.select*fromuserwhereid=xxx 2.select*fromuserorderbyidasc/desc 3.select*fromuserwhereage=xxx 4.selectagefromuserwhereage=xxx 5.selectagefromuserorderbyageasc/desc
既然要查詢那我們首先插入一些數據吧,畢竟沒有數據何來查詢
insertintouser('name','age','height')values('張三',20,170);
insertintouser('name','age','height')values('李四',21,171);
insertintouser('name','age','height')values('王五',22,172);
insertintouser('name','age','height')values('趙六',23,173);
insertintouser('name','age','height')values('錢七',24,174);
插入后表中的數據如下:
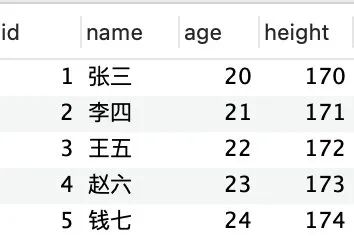
不知你有沒發現我們在插入的時候并沒有指定 id 值,但 InnoDB 為每條記錄默認添加了一個 id 值,而且這個 id 值是遞增的,每插入一條記錄,id 遞增 1,id 為什么要遞增呢,主要是為了查詢方便,每條記錄按 id 由小到大的順序用鏈表連接起來,這樣每次查找 id = xxx 的值就從 id = 1 開始依次往后查找即可

現在假設我們要執行以下 SQL 語句,MySQL 會怎么查詢呢
select*fromuserwhereid=3
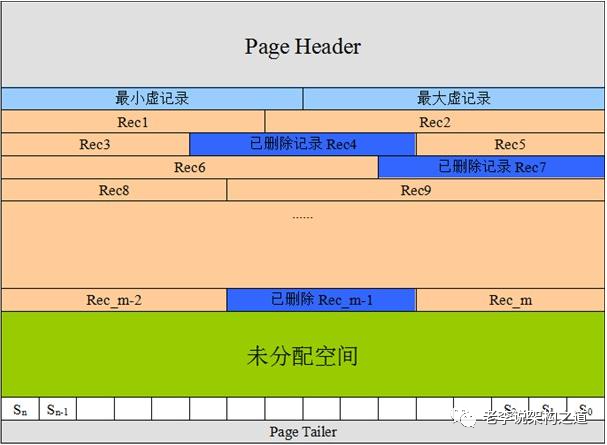
頁
如前所述,首先從 id 最小的記錄也就是 id = 1 讀起,每次讀一條記錄,將其 id 值與要查詢的值比較,連續讀三次記錄于是找到了記錄 3,注意這個讀的操作,是首先需要把存儲在磁盤的記錄讀取到內存然后再比較 id 的,從磁盤讀到內存算一次 IO,也就是說此過程中產生了三次 IO,如果只是幾條記錄還好,但如果要比較的條數多的話對性能是非常嚴重的挑戰,如果我要查詢為 id = 100 的記錄那豈不是要產生 100 次 IO?既然瓶頸在 IO,那該怎么改進呢,很簡單,我們現在的設計一次 IO 只能讀一條記錄,那改為一次 IO 能讀取 100 條甚至更多不就只產生一次 IO 了嗎,這背后的思想就是程序局部性原理:當用到了某項數據時,很可能會用到與之相鄰的數據,所以干脆把相依的數據一起加載進去(你從 id = 1 開始讀,那很可能用到 id = 1 緊隨其后的元素,于是干脆把 id = 1 ~ id = 100 的記錄都加載進去)
當然一次 IO 的讀取記錄也并不是多多益善,總不能為了一條查詢記錄而把很多無關的數據都加載到內存吧,那會造成資源的極大浪費,于是我們采用了一個比較折中的方案,我們規定一次 IO 讀取 16 K 的數據,假設為 100 條數據好了,這樣如果我們要查詢 id = 100 的記錄,只產生了一次 IO 讀(id=1~id=100 的記錄),比起原來的 100 次 IO 提升了 100 倍的性能
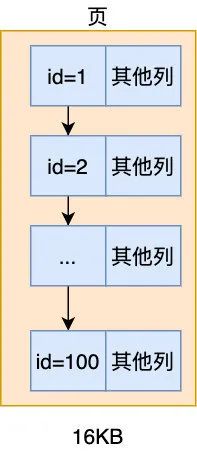
我們把這 16KB 的記錄組合稱為一個頁
頁目錄
一次 IO 會讀取一個頁,然后再在內存里查找頁里的記錄,在內存里查找確實比磁盤快多了,但我們仍不滿意,因為如果要查找 id = 100 的記錄,要先從 id = 1 的記錄比較起,然后是id=2,…,id=100,需要比較 100 次,能否更快一點?
可以參照二分查找,先查找 id = (1+100)/2 = 50,由于 50 < 100,接著在 ?50~100 的記錄中查,然后再在 75~100 中查,這樣經過 7 次就可找到 id = 100 次的記錄,比起原來的 100 次比較又提升了不少性能。但現在問題來了,第一次要找到 id = ?50 的記錄又得從 id = 1 開始遍歷 50 次才能找到,能否一下就定位到 id=50 的記錄呢,如果不能,哪怕第一次從 id = 30 或 40 開始查找也行啊
有什么數據結構能滿足這種需求呢,還記得跳表不,每隔 n 個元素抽出一個組成一級索引,每隔 2*n 個元素組成二級索引。。。
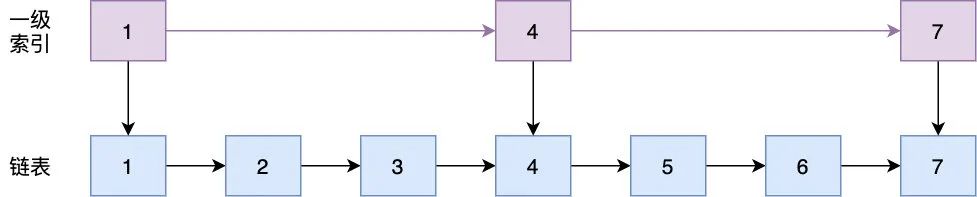
如圖示,以建立一級索引為例,我們在查找的時候先在一級索引查找,在一級索引里定位到了再到鏈表里查找,比如我們要找 7 這個數字,如果不用跳表直接在鏈表里查,需要比較 7 次,而如果用了跳表我們先在一級索引查找,發現只要比較 3 次,減少了四次,所以我們可以利用跳表的思想來減少查詢次數,具體操作如下,每 4 個元素為一組組成一個槽(slot),槽只記錄本組元素最大的那條記錄以及記錄本組有幾條記錄
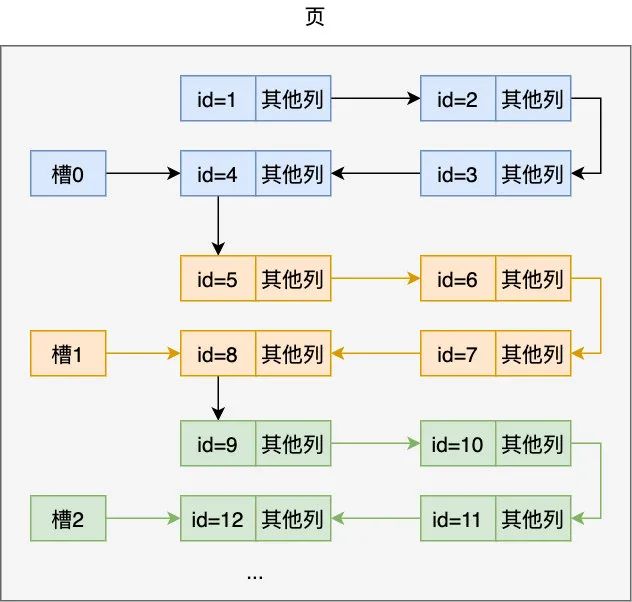
現在假設我們想要定位 id = 9 的那條記錄,該怎么做呢,很簡單:首先定位記錄在哪個槽,然后遍歷此槽中的元素
定位在哪個槽,首先取最小槽和最大槽對應的 id(分別為 4, 12),先通過二分查找取它們的中間值為 (4+12)/2 = 8,8 小于 9,且槽 2 的最大 id 為 12,所以可知 id = 9 的記錄在槽 2 里
遍歷槽 2 中的元素,現在問題來了,我們知道每條記錄都構成了一個單鏈表,而每個槽指向的是此分組中的最大 id 值,該怎么從此槽的第一個元素開始遍歷呢,很簡單,從槽 1 開始遍歷不就行了,因為它指向元素的下一個元素即為槽 2 的起始元素,遍歷后發現槽 2 的 第一個元素即為我們找到的 id 為 9 的元素
可以看到通過這種方式在頁內很快把我們的元素定位出來了,MySQL 規定每個槽中的元素在 1~8 條,所以只要定位了在哪個槽,剩下的比較就不是什么問題了,當然一個頁裝的記錄終究是有限的,如果頁滿了,就要要開辟另外的頁來裝記錄了,頁與頁之間通過鏈表連接起來,但注意看下圖,為啥要用雙向鏈表連接起來呢,別忘了最開頭我們列出的 「order by id asc 」和「order by id desc 」這兩個查詢條件,也就是說記錄需要同時支持正序與逆序查找,這就是為什么要使用雙向鏈表的原因
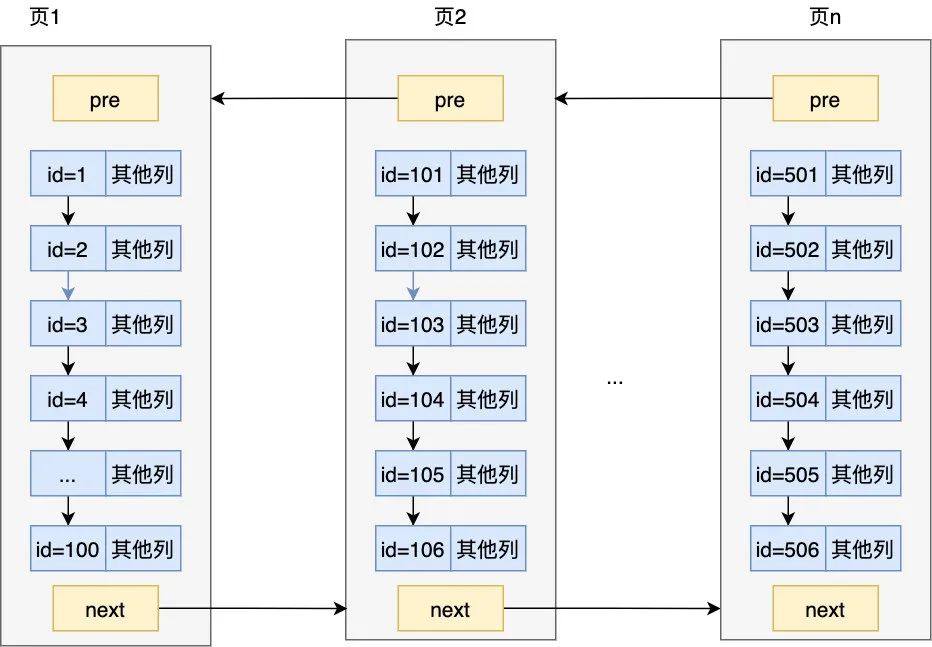
B+ 樹的誕生
現在問題來了,如果有很多頁,該怎么定位元素呢,如果元素剛好在前幾個頁還好,大不了遍歷前幾個頁也很快,但如果要查 id = 100w 這樣的元素一頁頁遍歷的話就要遍歷 1w 頁(假設每頁 100 條記錄),那顯然是不可接受的,如何改進呢,其實之前建的頁內目錄已經給了我們啟發,既然在頁內我們可以通過為記錄建頁目錄的形式來先定位元素在哪個槽然后再找,那針對多頁,能否先定位元素在哪個頁呢,也就是說我們可以為頁也建立一個目錄,這個目錄里的每一條記錄都對應著頁及頁中的最小記錄,當然這個目錄也是以頁的形式存在的,為了便于區分 ,我們把針對頁生成的目錄對應的頁稱為目錄頁,而之前存儲完整記錄的頁稱為數據頁
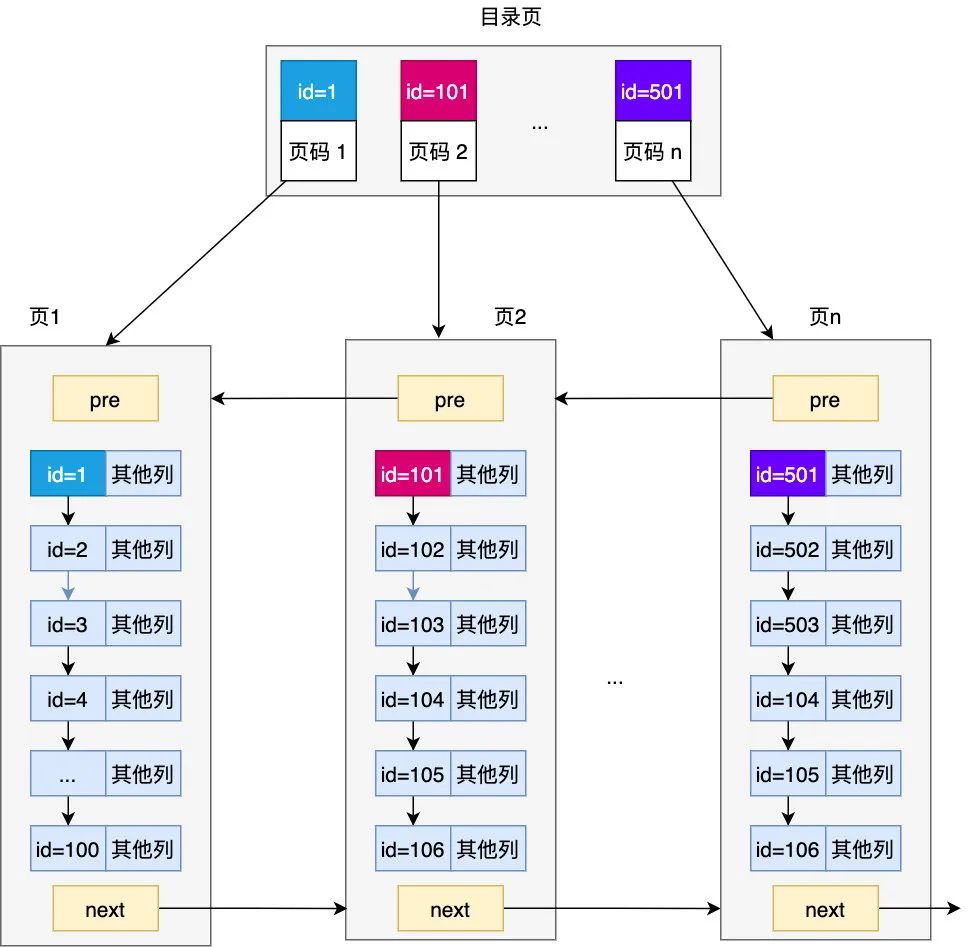
畫外音:目錄頁與數據頁一樣,內部也是有槽的,上文為了方便展示,沒有畫出,目錄頁和數據除了記錄數據不一樣,其他結構都是一致的
現在如果要查找 id = xxx 的記錄就很簡單了,只要先到目錄頁中定位它的起始頁然后再依次查找即可,由于不管是目錄頁還是數據頁里面都有槽,所以無論是定位目錄頁的頁碼還是定位數據頁中的記錄都是非常快的。
當然了,隨著頁的增多,目錄頁存放的記錄也越來越多,目錄頁也終歸會滿的,那就再建一個目錄頁吧,于是現在問題來了,怎么定位要找的 id 是在哪個目錄頁呢,再次制定針對目錄頁的目錄頁不就行了,如下
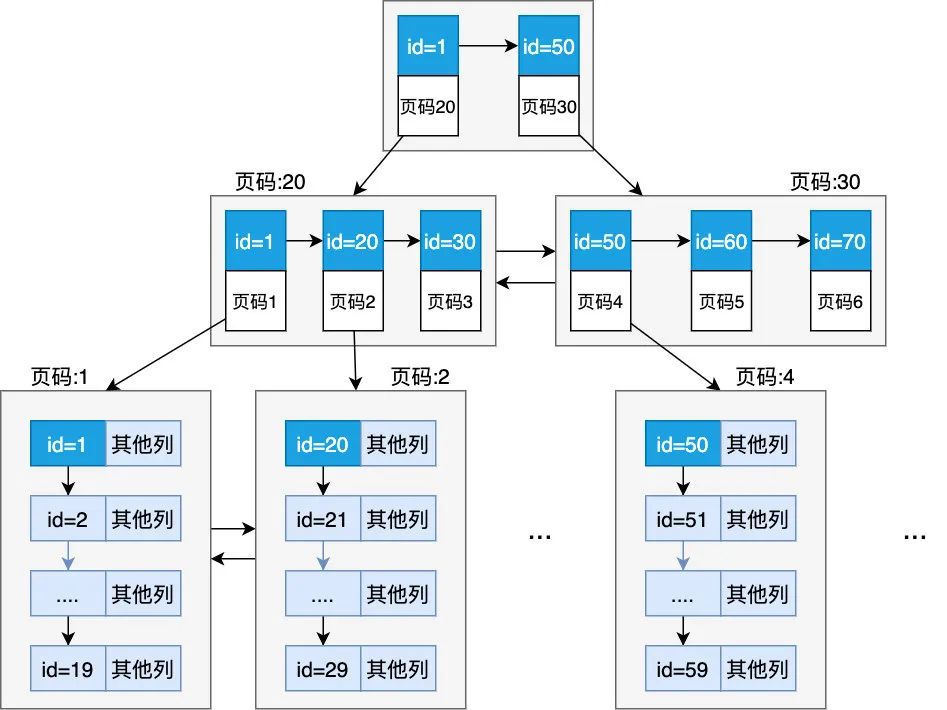
看到上面這個結構你想到了什么?沒錯,這就是一顆 B+ 樹!到此相信你已經明白了 B+ 樹的演進之路,也明白了它的原理,可以看到這顆 B+ 樹有三層,我們把最頂層的目錄頁稱為根節點,最下層的存儲完整記錄的頁稱為葉子節點,
現在我們再來看一下如何查找 id = 55 的記錄,首先會加載根節點,發現應該在頁碼 30 的頁中去找,于是加載頁 30,在頁 30 中又發現應該在頁 4 中查中,于是再次把頁 4 加載進內存中,然后在頁 4 中依次遍歷查找,可以看到總共經歷了 3 次 IO(B+樹有幾層就會有幾次 IO),頁讀取之后會緩存在內存中,再讀的話如果命中內存中的頁就會直接從內存中獲取。有人可能會問,如果 B+ 樹層數很多,那豈不是可能會有很多次 IO,我們簡單的算一下,假設數據頁可以存儲 100 條記錄,目錄頁可以存儲 1000 條記錄(目錄頁由于只存儲了主鍵,不存儲完整的數據,所以可以存儲更多的記錄),那么
如果B+樹只有 1 層,也就是只有 1 個用于存放用戶記錄的節點,最多能存放100條記錄。
如果B+樹有 2 層,最多能存放1000×100=100000條記錄。
如果B+樹有 3 層,最多能存放1000×1000×100=100000000條記錄。
如果B+樹有 4 層,最多能存放1000×1000×1000×100=100000000000條記錄!
所以一般3~4 層的 B+ 樹足以滿足我們的要求,而且每次讀取后會緩存在內存中(當然也會根據一定的算法被換出內存),所以整體來看 3~4 層 B+ 樹足以滿足我們需求
聚簇索引與非聚簇索引
相信你已經發現了,上文中我們舉的 B+ 樹的例子針對的是 id 也就是主鍵的索引,不難發現主鍵索引中的葉子結點存儲了完整的 SQL 記錄,我們把這種存儲了完整記錄的索引稱為聚簇索引,只要你定義了主鍵,那么主鍵索引就是聚簇索引。
那么如果是非主鍵的列創建的索引又是怎樣的形式呢,非葉子節點的形式完全一樣,但葉子節點的存儲則有些不同,非主鍵列索引葉子節點上存儲的是索引列及主鍵值,比如我們假設對 age 這個列建立了索引,那么它的索引樹如下
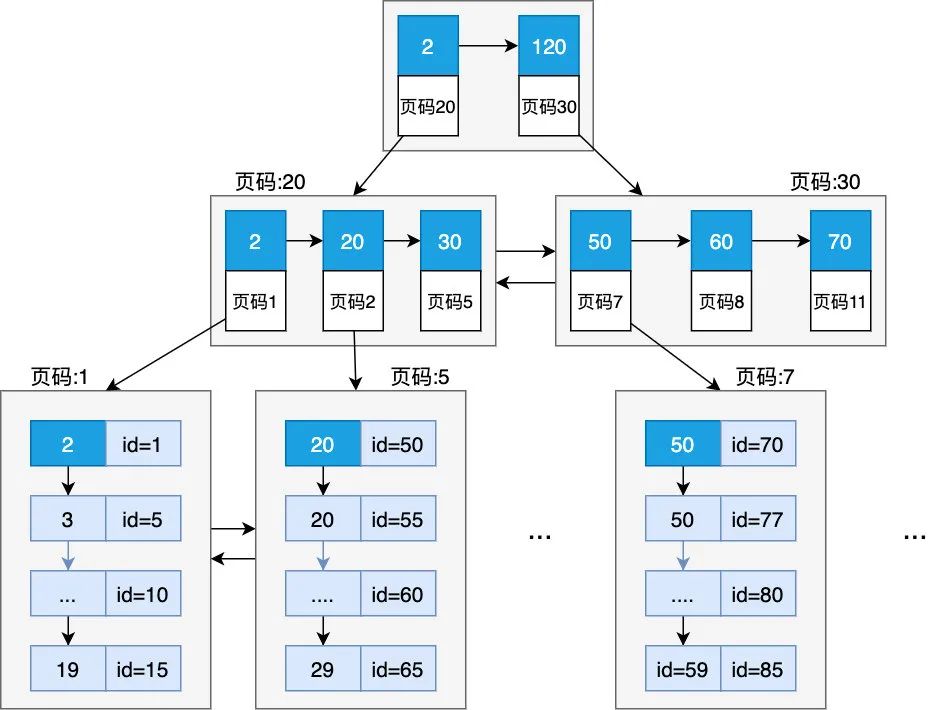
可以看到非葉子節點保存的是「age 值 + 頁碼」,而葉子節點保存的是 「age 值+主鍵值」,那么你可能就會疑惑了,如下 SQL 是怎么取出完整記錄的呢
select*fromuserwhereage=xxx
第一步大家都知道,上述 SQL 可以命中 age 列對應的索引,然后找到葉子節點上對應的記錄(如果有的話),但葉子節點上的記錄只有 age 和 id 這兩列,而你用的是 select *,意味著要查找 user 的所有列信息,該怎么辦呢,答案是根據拿到的 id 再到聚簇索引找 id 對應的完整記錄,這就是我們所說的回表,如果回表多的話顯然會造成一定的性能問題,因為 id 可能分布在不同的頁中,這意味著要將不同的頁從磁盤讀入內存,這些頁很可能不是相鄰的,也就意味著會造成大量的隨機 IO,會嚴重地影響性能,看到這相信大家不難明白一道高頻面試題:為什么設置了命中了索引但還是造成了全表掃描,其中一個原因就是雖然命中了索引但在葉子節點查詢到記錄后還要大量的回表,導致優化器認為這種情況還不如全表掃描會更快些
有人可能會問,為啥都二級索引不存儲完整的記錄呢,當然是為了節省空間,畢竟完整的數據是很耗空間的,如果每加一個索引都要額外存儲完整的記錄,那會造成很多數據冗余。
怎么避免這種情況呢?索引覆蓋,如果如下 SQL 滿足你的需求,那么就建議采用如下形式
selectagefromuserwhereage=xxx selectage,idfromuserwhereage=xxx
不難發現這種 SQL 的特點是要獲取的列(age)就是索引列本身(包括 id),這樣在根據 age 的索引查到葉子節上對應的記錄后,由于記錄本身就包含了這些列,就不需要回表了,能提升性能
磁盤預讀
接下來我們討論一個網上很多人搞不拎清的一個問題,我們知道操作系統是以頁為單位來管理內存的,在 Linux 中,一頁的大小默認為 4 KB,也就是說無論是從磁盤載入數據到內存還是將內存寫回磁盤,操作系統都會以頁為單位進行操作,哪怕你只對一個空文件只寫入了一個字節,操作系統也會為其分配一個頁的大小( 4 KB)
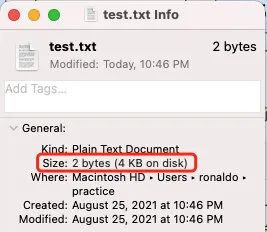
如圖示,向磁盤寫入了兩個 byte ,但操作系統依然為其分配了一個頁(4 KB)的大小
innoDB 也是以頁為單位來存儲與讀取的,而 innoDB 頁的默認大小為 16 KB,那么網上很多人的疑問是這是否意味著它需要執行 4 次 IO 才能把 innoDB 的頁讀完呢?不是的,只需要一次 IO,為什么?這需要理解一點磁盤讀取數據的工作原理
磁盤的構造
首先我們來看看磁盤的物理結構
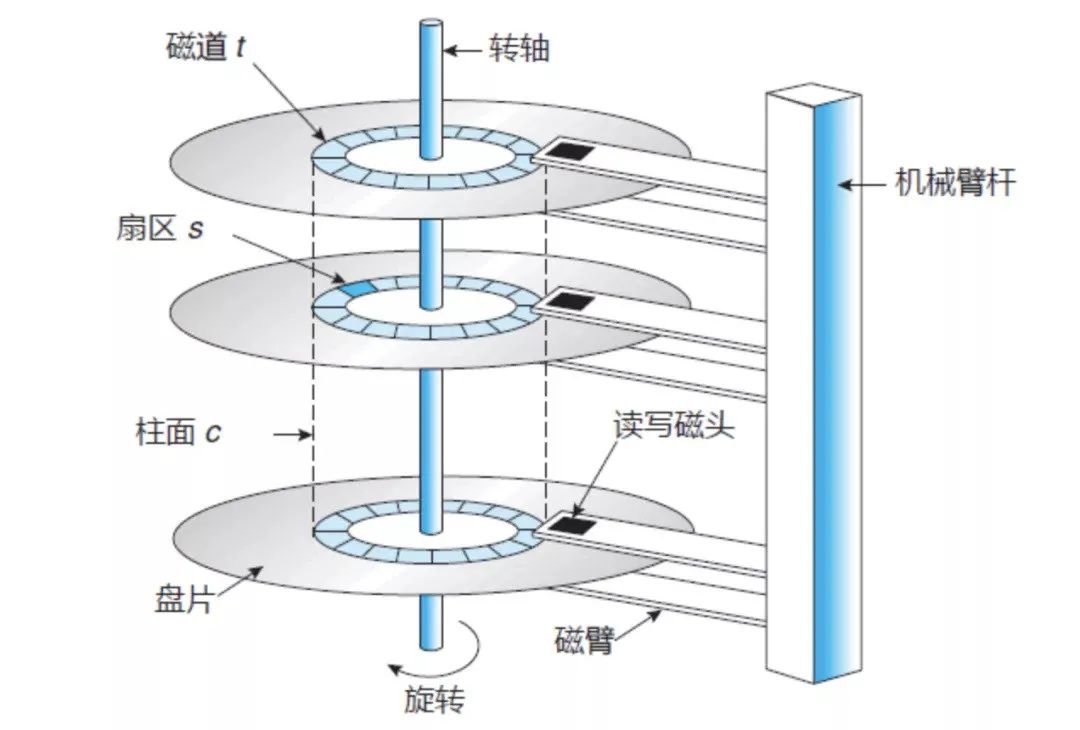
硬盤內部主要部件為磁盤盤片、傳動磁臂、讀寫磁頭和轉軸,數據主要寫入磁盤的盤片上的,盤片又是由若干個扇區構成的,數據寫入讀取都是以扇區為基本單位的,另外以盤片中心為圓心,把盤片分成若干個同心圓,那每一個劃分圓的“線條”,就稱為磁道
那么數據是如何讀取與寫入的呢,主要有三步
尋道:既然數據是保存在扇區上的,那我首先我們需要知道它到底是在哪個扇區上吧,這就需要先讓磁頭移動到扇區所在的磁道上,我們把它稱為尋道時間,平均尋道時間一般在3-15ms
旋轉延遲: 磁盤移動到扇區所在的磁盤上時,此時的磁頭對準的還不一定我們想要的數據對應的扇區,所以需要等待盤片旋轉片刻,等到我們想要的數據對應的扇區落到磁頭下,旋轉延遲取決于磁盤轉速,通常用磁盤旋轉一周所需時間的1/2表示。比如:7200rpm的磁盤平均旋轉延遲大約為60*1000/7200/2 = 4.17ms,而轉速為15000rpm的磁盤其平均旋轉延遲為2ms
數據傳輸:經過前面的兩步,磁頭終于開始讀寫數據了,目前IDE/ATA能達到133MB/s,SATA II可達到300MB/s的接口數據傳輸率,數據傳輸時間通常遠小于前兩部分消耗時間。可忽略不計
注意數據傳輸中的忽略不計是有前提的,即是需要讀取連續相鄰的扇區,也就是我們常說的順序 IO,磁盤順序 IO 的讀寫速度可以媲美甚至超越內存的隨機 IO,所以這部分時間可以忽略不計,(大家熟知的 Kafka 之所以性能強悍,有一個重要原因就是利用了磁盤的順序讀寫),但如果要讀取的數據是分布在不同的扇區的話,也就變成了隨機 IO,隨機 IO 毫無疑問增大了尋道時間和旋轉延遲,性能是非常堪憂的(典型代表就是上文提到的 回表時大量 id 分布在不同的頁上,造成了大量的隨機 IO)
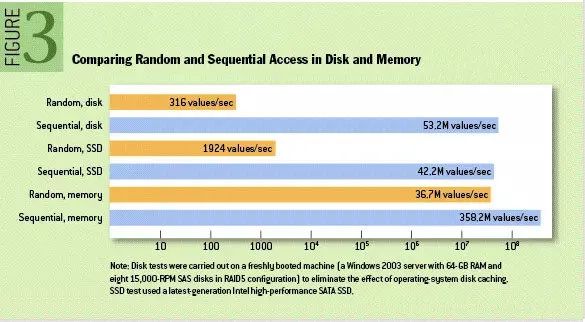
如圖示:圖片來自著名學術期刊 ACM Queue 上的性能對比圖,可以看到磁盤順序 IO(Sequential Disk)的速度比內存隨機讀寫(Random memory)還快
那讀取 innoDB 中的一個頁為啥算一次 IO 呢,相信你已經猜到了,因為這一個頁是連續分配的,也即意味著它們的扇區是相鄰的,所以它是順序 IO
操作系統是以頁為單位來管理內存的,它可以一次加載整數倍的頁,而 innoDB 的頁大小為 16KB,剛好是操作系統頁(4KB)的 4 倍,所以可以指定在讀取的起始地址連續讀取 4 個操作系統頁,即 16 KB,這就是我們說的磁盤預讀,至此相信大家不難明白為啥說讀取一頁其實只是一次 IO 而不是 4 次了
總結
看完本文相信大家能明白索引的由來了,此外對頁以及磁盤預讀對性能的提升應該也有不少了解,其實 MySQL 的頁結構與我們推演的結構有些許出入,不過不影響整體的理解。
-
存儲
+關注
關注
13文章
4314瀏覽量
85851 -
SQL
+關注
關注
1文章
764瀏覽量
44134 -
MySQL
+關注
關注
1文章
809瀏覽量
26576
原文標題:你管這破玩意叫B+樹?
文章出處:【微信號:良許Linux,微信公眾號:良許Linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
詳解Linux系統文件頁表目錄和Linux系統頁表結構

redis緩存mysql數據
MySQL數據結構及算法原理的介紹

MySQL中的高級內容詳解
MySQL中的redo log是什么
id的機制不同在mysql的索引結構以及優缺點

MySQL為什么選擇B+樹作為索引結構?
MySQL導出的步驟
適用于MySQL的dbForge架構比較





 工商網監
工商網監
評論