 多車立體事件相機數據集:用于3D感知的事件相機數據集
多車立體事件相機數據集:用于3D感知的事件相機數據集
基于事件的攝像機是一種新的無源傳感方式,與傳統的攝像機相比有許多優點,包括極低的延遲、異步數據采集、高動態范圍和極低的功耗。最近,人們對應用算法來使用事件執行各種3D感知任務非常感興趣,比如特征跟蹤、視覺里程數測量和立體深度估計。然而,目前缺乏像傳統相機那樣豐富的標記數據,無法用于測試和開發。在本文中,我們展示了一個大型數據集,該數據集采用了基于事件的同步立體攝影系統,該系統由一個手持式設備攜帶,在各種不同的照明水平和環境中,由一架六軸飛行器飛行,在汽車頂部驅動,并安裝在摩托車上。從每個相機中,我們提供事件流、灰度圖像和IMU讀數。此外,我們利用IMU、剛性安裝的激光雷達系統、室內外運動捕捉和GPS的組合,以高達100Hz的頻率為每個攝像機提供準確的姿勢和深度圖像。為了進行比較,我們還提供了同步的灰度圖像和基于框架的立體攝像機系統的IMU讀數。
I.簡介 基于EVENT的相機通過檢測圖像的對數強度的變化來感知世界。通過以幾十微秒的精度記錄這些變化,以及異步的、幾乎是即時的反饋,與傳統相機通常有幾十毫秒的延遲相比,它們可以實現極低的延遲響應。此外,通過跟蹤日志強度的變化,攝像機具有非常高的動態范圍(>130dB,而傳統攝像機約為60dB),這使得它們對照明的戲劇性變化的場景非常有用,如室內-室外的過渡,以及有強光源的場景,如太陽。然而,大多數現代機器人算法都是為同步傳感器設計的,測量結果以固定的時間間隔到達。此外,生成的事件本身并不帶有任何強度信息。
因此,必須開發新的算法以充分利用該傳感器提供的優勢。不幸的是,由于測量方法的不同,我們不能直接利用傳統相機捕捉到的大量標簽數據。事實證明,這些數據對于為新方法提供真實和一致的評估、訓練機器學習系統以及為無法接觸到這些傳感器的研究人員提供新的發展機會來說,是極其重要的。在這項工作中,我們旨在提供一些不同的序列,以促進研究和開發一些不同問題的新穎解決方案。一個主要的貢獻是建立了第一個具有同步立體事件攝像系統的數據集。經過校準的立體系統對于用度量衡進行深度估計很有幫助,這有助于解決諸如姿勢估計、繪圖、避障和3D重建等問題。在基于事件的攝像機的立體深度估計方面已經有了一些工作,但是,由于缺乏準確的地面實況深度,評估只限于小的、不相干的序列,包括攝像機前面的幾個物體。相比之下,這個數據集提供了來自兩個同步和校準的動態視覺和主動像素傳感器(DAVIS- m346b)的事件流,在各種光照和速度下的室內和室外長序列,以及精確的深度圖像和高達100Hz的姿勢,由安裝在相機頂部的激光雷達系統產生,如圖1,同時還有運動捕捉和GPS。我們希望這個數據集可以幫助為一些應用中基于事件的算法評估提供一個共同的基礎。完整的數據集可以在網上找到:https:// daniilidis-group.github.io/mvse本文的主要貢獻可歸納為:● 第一組帶有同步立體事件相機的數據集,具有準確的地面實況深度和姿態。● 來自手持式鉆機、六軸飛行器、汽車和摩托車的事件數據,以及來自3D激光雷達、IMU和基于框架的圖像的校準傳感器數據,來自各種不同的速度、照明水平和環境。
II.相關工作 A.相關數據集
目前,有一些現有的數據集提供了來自單眼事件相機的事件,并與其他各種傳感方式和地面實況測量相結合,適用于測試一些不同的3D感知任務。
Weikersdorfer等人[1]將早期的128x128分辨率的eDVS傳感器與Primesense RGBD傳感器結合起來,并提供了一個室內序列的數據集,其地面實況姿勢來自運動捕捉系統,深度來自RGBD傳感器。Rueckauer等人[2]提供了來自DAVIS 240C相機的純旋轉運動的數據,以及基于陀螺儀報告的角速度的地面實況光學流,盡管這受到報告速度中的噪音影響。Barranco等人[3]提出了一個數據集,其中的DAVIS 240B相機安裝在一個平移傾斜裝置的頂部,與微軟的Kinect傳感器一起連接在一個移動基地上。該數據集提供了基地在室內環境中以5自由度移動的序列,以及來自基地上的輪子編碼器和平移傾斜裝置的角度的地面實況深度、光學流和姿勢。雖然來自Kinect的深度是準確的,但光學流和姿勢會受到底座的輪子編碼器的位置估計的影響而發生漂移。Mueggler等人[4]提供了一些用于在各種室內和室外環境中進行姿勢估計的手持序列,這些序列由DAVIS 240C生成。一些室內場景提供了姿態的基礎真實,是由動作捕捉系統捕獲的。然而,沒有戶外序列,或其他具有明顯位移的序列,具有地面實況信息。Binas等人[5]提供了一個安裝在汽車擋風玻璃后面的DAVIS 346B的大型數據集,其中有12個小時的駕駛,旨在對各種駕駛相關的任務進行端對端學習。作者提供了一些來自車輛的輔助測量數據,如轉向角、加速器踏板位置、車速等,以及來自GPS裝置的經度和緯度。然而,沒有提供6自由度的姿勢,因為只能從所提供的GPS輸出中推斷出2D平移。這些數據集為開發和評估基于事件的方法提供了寶貴的數據。然而,迄今為止,他們只有單目序列,地面實況6自由度的姿勢僅限于小型室內環境,很少有序列具有地面實況深度。相比之下,這項工作提供了在各種室內和室外環境中具有地面實況姿態和深度圖像的立體序列。B.基于事件的3D感知早期的工作[6],[7]提出了立體深度估計的結果,有一些空間和時間成本。后來在[8]、[9]和[10]的工作中,將立體深度的合作方法適應于基于事件的攝像機,因為它們適用于異步的、基于點的測量。同樣,[11]和[12]應用了一套時間、極性、排序和極性約束來確定匹配,而[13]則將其與基于方位儀庫輸出的匹配進行比較。
作者在[14]中展示了一種新的方法來確定外極線,應用于立體匹配。在[15]中,作者提出了一個新的上下文描述符來進行匹配,[16]中的作者使用了一個經歷純旋轉的立體事件相機來進行深度估計和全景拼接。
也有一些關于基于事件的視覺測距和SLAM問題的工作。作者在[17]和[18]中提出了在事件空間中進行特征跟蹤的新方法,他們在[19]和[20]中對這些方法進行了擴展,分別進行視覺和視覺慣性測距。在[1]中,作者將一個基于事件的相機與深度傳感器結合起來,進行視覺測距和SLAM。[21]中的作者使用事件來估計攝像機的角速度,而[22]和[23]則通過建立一個最高比例的地圖來進行視覺測向。此外,[24]和[25]還將事件與來自IMU的測量值相融合,進行視覺慣性測距。雖然較新的作品基于公共數據集進行評估,如[4],但大多數是在僅為論文而產生的小數據集上進行評估,使得性能的比較變得很困難。對于基于立體事件的攝像機來說,情況尤其如此。在這項工作中,我們試圖產生更廣泛的基礎真相,以便對新算法進行更有意義的評估,為方法之間的比較提供基礎。
III.數據集
對于該數據集中的每個序列,我們以ROS bag1格式提供以下測量結果:● 事件,APS灰度圖像和來自左右DAVIS相機的IMU測量。● 來自VI傳感器的圖像和IMU測量。● 來自Velodyne VLP-16激光雷達2的點云。● 左邊DAVIS相機的地面實況參考姿勢。● 左邊和右邊DAVIS相機的地面實況參考深度圖像。A.傳感器
表I中列出了傳感器及其特點。此外,圖2a顯示了傳感器裝置的CAD圖,所有的傳感器軸都被標明,圖2顯示了傳感器在每輛車上的安裝方式。
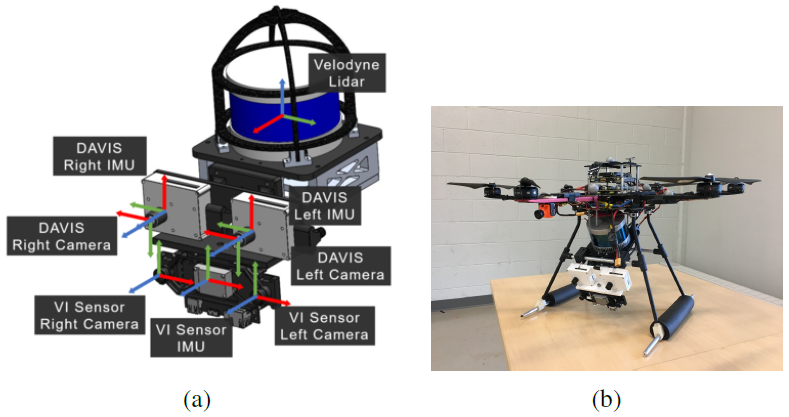

圖2:從左到右:(a):傳感器裝置的CAD模型。所有的傳感器軸都被貼上標簽,并涂上對應的顏色:R:X、G:Y、B:Z,每對軸之間只有大約90度的旋轉組合。(b): 安裝在六軸飛行器上的傳感器包。(c): 使用玻璃吸力三角架安裝在汽車天窗上的傳感器包。(d): DAVIS相機和VI傳感器安裝在摩托車上。請注意,在所有的配置中,VI傳感器都是倒著安裝的。最好以彩色方式觀看。
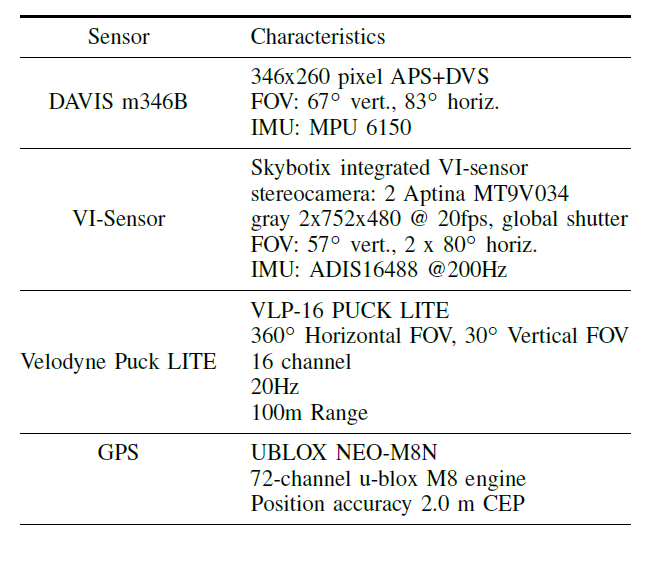
表一:傳感器和特征
如第五節所述,所有傳感器之間的外在因素是通過校準來估計的。對于事件的產生,兩個實驗性的mDAVIS-346B相機被安裝在一個水平的立體設置中。這些相機與[26]相似,但具有更高的346x260像素的分辨率,高達50fps的APS(基于幀的圖像)輸出,和更高的動態范圍。立體聲設備的基線是10厘米,攝像機的時間戳同步是通過使用從左側攝像機(主攝像機)產生的觸發信號,通過外部電線向右側(從攝像機)輸送同步脈沖。兩臺攝像機都有4毫米的鏡頭,水平視場角約為87度,每臺攝像機上都有一個額外的紅外切割濾波器,以抑制來自運動捕捉系統的紅外閃光。APS的曝光是手動設置的(沒有自動曝光),這取決于照明條件,但相機之間總是相同的。雖然灰度DAVIS圖像的時間戳是同步的,但遺憾的是沒有辦法同步圖像采集本身。因此,圖像之間可能有高達10ms的偏移。為了提供地面實況的參考姿勢和深度(第四節),我們將Velodyne Puck LITE安裝在立體DAVIS相機上方。Velodyne激光雷達系統提供了傳感器周圍大量點的高度精確深度。激光雷達的安裝方式是,激光雷達較小的垂直視場與立體DAVIS設備的視場完全重疊。在室外場景中,我們還安裝了一個GPS設備,作為經緯度的第二個地面實況參考。通常情況下,GPS被放置在遠離傳感器裝置的地方,以避免USB 3.0數據線的干擾。此外,我們還安裝了一個VI傳感器[27],最初由Skybotix開發,用于與基于框架的方法進行比較。該傳感器與IMU有一對立體聲,都是同步的。不幸的是,唯一的安裝選擇是將攝像機倒置安裝,但我們提供了它們與DAVIS攝像機之間的轉換。B.序列
表二中列出了所有的序列和統計摘要,圖三中列出了疊加了事件的APS圖像樣本。1) 具有運動捕捉功能的六軸飛行器: 傳感器安裝在六軸飛行器的計算堆下面,向下傾斜25度,如圖2b所示。兩個運動捕捉系統被用來為這個數據集生成序列,一個在室內,一個在室外(圖4)。26.8m x 6.7m x 4.6m的室內區域用20臺Vicon Vantage VP-16攝像機進行檢測。30.5米x 15.3米x 15.3米的戶外網區配備了全天候運動捕捉系統,由34臺高分辨率Qualisys Oqus 700攝像機組成。這兩個系統通過發射紅外頻閃和跟蹤放置在六軸飛行器上的紅外反射標記,以100Hz的頻率提供毫米級精度的姿勢。我們在每個區域提供不同長度和速度的飛行序列。2) 手持式:為了測試高動態范圍情況下的性能,整個傳感器裝置在室外和室內環境以及有無外部照明的室內環境中都進行了循環。地面實況姿態和深度是由激光雷達SLAM提供的。
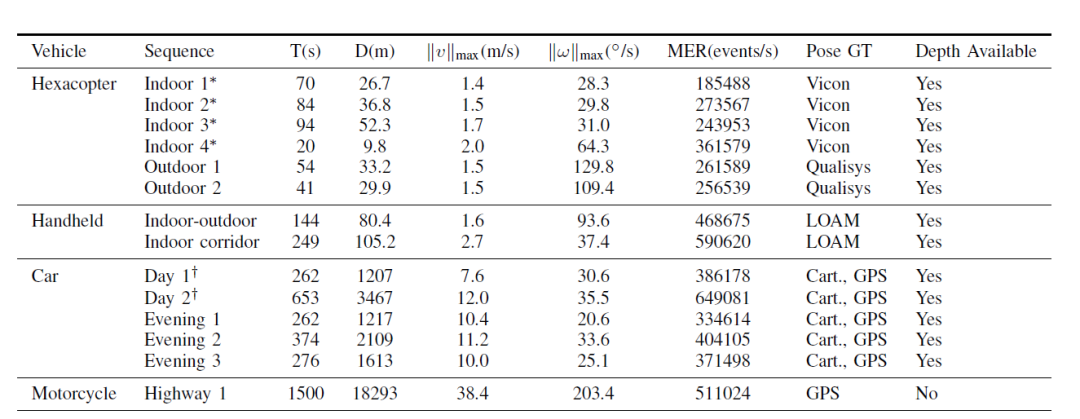

圖3:白天和晚上的室內和室外序列的樣本圖像與重疊的事件(藍色和紅色)。最好以彩色觀看。

圖4:運動捕捉場地。左:室內Vicon場地;右:戶外Qualisys場地。
IV.地面實況的生成
為了提供地面實況姿態,在有條件的情況下,會使用動作捕捉姿態。否則,如果有激光雷達,Cartographer[28]將用于驅動序列,將激光雷達掃描和IMU數據融合成激光雷達的循環閉合2D姿態,利用第五章D節的校準將其轉換為左DAVIS幀。對于戶外場景,我們也提供原始的GPS讀數。
對于每個有激光雷達測量的序列,我們運行激光雷達測繪(LOAM)算法[29]來生成密集的三維局部地圖,這些地圖被投射到每個DAVIS相機中,以20Hz的頻率生成密集的深度圖像,并為手持序列提供3D姿勢。 我們使用了兩種獨立的激光雷達測距算法,因為我們注意到,LOAM產生了更好的、排列更整齊的局部地圖,而Cartographer的環形閉合則產生了更精確的全局位置,對于較長的軌跡來說,漂移更少。 雖然Cartographer只估計了一個2D的姿勢,但我們相信這是一個有效的假設,因為所駕駛的道路在大多數情況下都有一個單一的一致的等級。A.地面實況姿勢
對于室內和室外運動捕捉領域的序列,在每個時間t的傳感器設備worldHbody(t)的主體框架的姿勢是以100Hz測量的,精度為毫米級。對于戶外序列,我們依靠Cartographer來執行循環閉合,并將激光雷達掃描和IMU數據融合到一個單一的循環閉合的主體(在這種情況下是激光雷達)的2D姿勢中,并使其漂移最小。
為了對最終姿勢的質量進行量化衡量,我們將位置與GPS測量值對齊,并為數據集中的每個戶外序列提供疊加的衛星圖像,以及所提供的地面實景和GPS之間的位置差異。圖7提供了Car Day 2的樣本覆蓋,其中Cartographer和GPS之間的平均誤差始終在5m左右,沒有漂移。
這個誤差在所有的戶外駕駛序列中是一致的,總體平均誤差為4.7米,與GPS的預期誤差大小相似。請注意,440秒左右的誤差峰值是由于巨大的GPS誤差造成的,對應于覆蓋圖右上方的黑體部分。
在這兩種情況下,對于每個從左DAVIS幀到幀取點的序列,外在的變換,表示為4×4的同質變換矩陣體worldHDAVIS,然后用來估計時間t的左DAVIS相對于時間t0的第一個左DAVIS的姿勢:
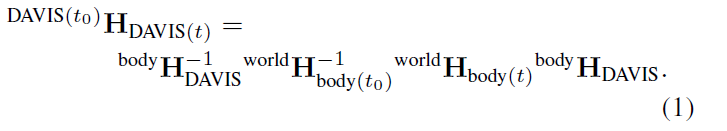
B.深度圖的生成
在有激光雷達的每個序列中,每個DAVIS相機的深度圖像都是為每個激光雷達測量而生成的。我們首先通過將當前測量周圍的局部窗口中的每個激光雷達點云轉換為當前測量的框架,使用LOAM的姿勢來生成一個局部地圖。在每次測量時,確定窗口大小,使窗口中當前、第一和最后一個LOAM姿勢之間的距離至少為d米,并且當前、第一和最后一個LOAM姿勢之間至少有s秒,其中d和s是為每個序列調整的參數。這些地圖的例子可以在圖5中找到。
然后,我們使用標準的針孔投影方程,將所得到的點云中的每個點p投射到每個DAVIS相機的圖像中:
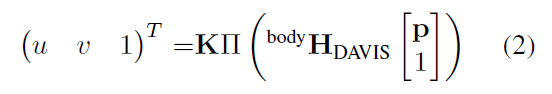
其中Π是投影函數:
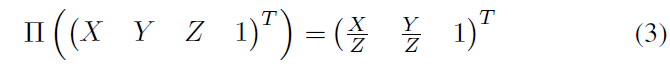
而K是矩形圖像的相機本征矩陣(即投影矩陣的左上方3×3)。 任何落在圖像邊界之外的點都會被丟棄,圖像中每個像素位置上最接近的點被用來生成最終的深度圖,其例子可以在圖6中找到。 此外,我們還通過使用相機本征和OpenCV對矯正后的深度圖像進行取消矯正和扭曲,提供沒有任何失真的原始深度圖像。
V.校準
在這一節中,我們描述了為校準每個DAVIS和VI-Sensor相機的內在參數而進行的各種步驟,以及每個相機、IMU和激光雷達之間的外在轉換。所有的校準結果都以yaml形式提供。 使用Kalibr工具箱3 [30], [31], [32]對相機本征、立體外征和相機-IMU外征進行校準,使用相機和范圍校準工具箱4 [33]對左DAVIS相機和Velodyne激光雷達的外征進行校準。在動作捕捉世界幀中的Mocap模型姿態與左DAVIS相機姿態之間的手眼校準是用CamOdoCal5[34]進行的,并由人工進行微調。

圖5:為地面實況生成的樣本地圖。左圖:汽車第1天序列的全圖,綠色為軌跡; 右圖:來自Hexacopter Indoor 3序列的局部地圖。

圖6:深度圖像(紅色)與事件疊加(藍色),來自Hexacopter Indoor 2和Car Day 1序列。請注意,由于激光雷達的垂直視場和范圍有限,圖像的部分區域(黑色區域,特別是頂部)沒有深度。這些部分在數據中被標記為NaN。最好以彩色方式觀看。
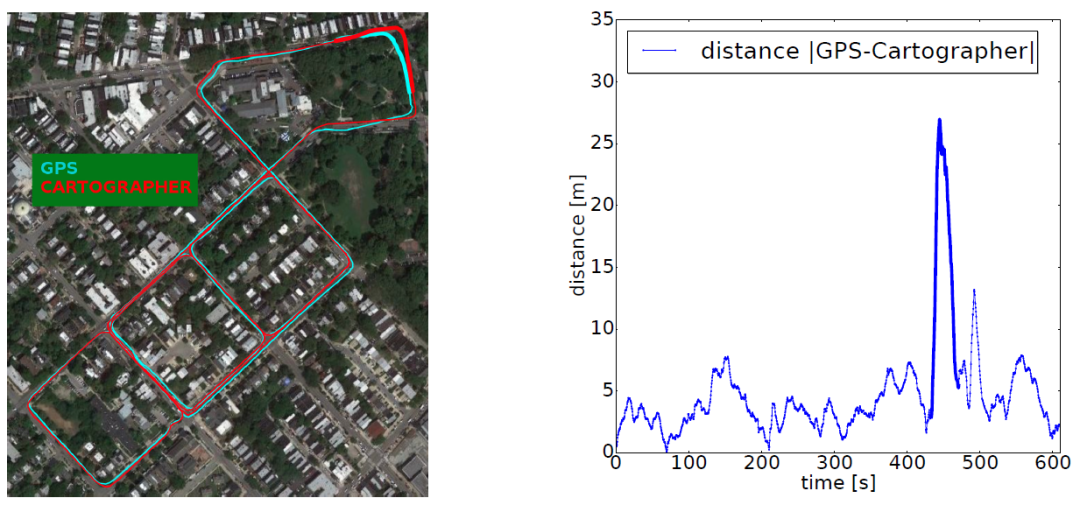
圖7:GPS和Cartographer在衛星圖像上疊加的 Car Day 2 軌跡的比較。請注意,Cartographer和GPS之間的誤差峰值對應于左側覆蓋圖右上方的黑體部分,主要是由于GPS誤差造成的。最好以彩色觀看。
為了抵消所安裝設備的變化,在收集數據的每一天,以及每次修改傳感有效載荷的時候,都要重復每一次校準。除了校準參數外,每天的原始校準數據也可按需提供,以便用戶在需要時進行自己的校準。
A.攝像機的內在、外在和時間校準
為了校準相機和IMU之間的轉換,在傳感器裝置在AprilTag網格前移動的情況下記錄了一個序列。這兩個校準程序是分開的,以優化每個單獨校準的質量。校準序列再次通過Kalibr運行,使用相機-IMU校準來估計每個相機和每個IMU之間的轉換,給定先前的內在校準和相機-相機間的外在校準。 B.攝像機到IMU的外在校準 攝像機的內因和外因是使用AprilTags[35]的網格來估計的,該網格在傳感器支架前移動,并使用Kalibr進行校準。每個校準都提供了每個相機的焦距和主點,以及相機之間的失真參數和外在因素。 此外,我們通過找到能使左DAVIS的IMU和VI傳感器的陀螺儀角速度大小的交叉相關性最大化的時間偏移,來校準DAVIS立體對和VI傳感器之間的時間偏移。然后對數據集中的VI傳感器信息的時間戳進行修改,以抵消這一偏差。
C.運動捕捉到相機的外在校準 每個動作捕捉系統以100Hz的頻率提供動作捕捉幀中的mocap模型的姿勢。然而,Mocap模型幀與任何攝像機幀都不一致,因此需要進一步校準,以從運動捕捉系統中獲得攝像機的姿勢。傳感器裝置以各種不同的姿勢被靜態地固定在April-網格的前面。每個姿勢在時間 ti時,測量網格幀aprilgrid HDAVIS(ti)中左DAVIS相機幀的姿勢,以及mocap幀mocap Hbody(ti)中mocap模型(表示主體)的姿勢。然后,這些姿勢被用來解決手眼校準問題,即把左DAVIS框架中的一個點轉換為模型框架bodyHDAVIS:
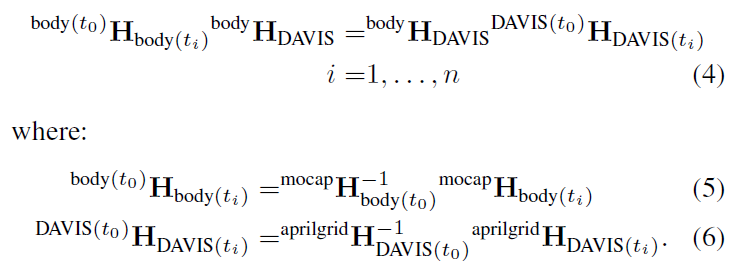
使用CamOdoCal進行優化,使用[36]中的線性方法,并使用[34]中描述的非線性優化方法進行重新篩選。
D.激光雷達到相機的外在校準 將一個點從激光雷達框架帶到左邊的DAVIS框架的轉換,最初是使用相機和范圍校準工具箱[33]進行校準。四個大的棋盤圖案被放置在DAVIS相機的視場內,每臺相機的一對圖像被記錄下來,同時還有一個完整的激光雷達掃描。 校準器然后估計出使攝像機和激光雷達觀測到的棋盤相一致的平移和旋轉。 然而,我們發現,在查看投影的深度圖像時,報告的變換有多達五像素的誤差(圖6)。此外,由于激光雷達和攝像機不是硬件時間同步的,兩個傳感器之間偶爾會有明顯的、持續的時間延遲。為了改善校準,我們根據CAD模型的值來確定翻譯,并手動調整了旋轉和時間偏移,以最大限度地提高深度和事件圖像之間的重疊。為了視覺上的確認,我們提供了每個攝像頭的深度圖像與事件的疊加。數據集中提供的激光雷達信息的時間戳對時間偏移進行了抵消。
VI.已知問題
A.移動對象用于生成深度圖的映射假設場景是靜態的,通常不會過濾掉移動物體上的點。因此,在追蹤其他汽車上的點時,報告的深度圖可能有高達兩米的誤差,等等。然而,與可用的數據總量相比,這些對象通常相當罕見。如果需要,未來的工作可以涉及對圖像中的車輛進行分類,并從深度圖中省略這些點。
B.時鐘同步性運動捕捉和GPS只使用主機的時間與系統的其他部分同步。這可能會導致報告的時間戳與實際測量時間之間出現偏移。我們在一臺電腦上記錄所有的測量結果,以減少這種影響。此外,由于激光雷達的旋轉速度,激光雷達點的測量和信息的時間戳之間可能會有一些延遲。
C.DVS偏置
在生成每個序列時,使用了每個攝像機的默認偏置。然而,人們注意到,對于室內?ying序列,正負事件的比例比通常要高(~2.5-5倍)。在這一點上,我們不知道是什么原因導致了這種不平衡,也不知道調整偏置是否會平衡它。我們注意到,這種不平衡在斑紋層上特別偏斜。我們建議使用事件極性的研究人員在處理這些序列時要注意這種不平衡性。
VII.總結
我們提出了一個新的立體事件相機的數據集,在一些不同的車輛和不同的環境中,有6自由度姿勢和深度圖像的地面實況。我們希望這些數據能夠提供一個標準,在此基礎上對新的基于事件的方法進行評估和比較。
審核編輯 :李倩
-
相機
+關注
關注
4文章
1354瀏覽量
53668 -
激光雷達
+關注
關注
968文章
3981瀏覽量
190022 -
數據集
+關注
關注
4文章
1208瀏覽量
24725
原文標題:多車立體事件相機數據集:用于3D感知的事件相機數據集
文章出處:【微信號:阿寶1990,微信公眾號:阿寶1990】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
用于任意排列多相機的通用視覺里程計系統



奧比中光3D相機打造高質量、低成本的3D動作捕捉與3D動畫內容生成方案
OpenCV攜奧比中光3D相機亮相CVPR 2024

奧比中光正式發布全新Gemini 330系列雙目3D相機

宏集PLC如何應用于建筑的3D打印?

基于深度學習的方法在處理3D點云進行缺陷分類應用
高精度彩色3D相機:開啟嶄新的彩色3D成像時代
友思特分享 | 高精度彩色3D相機:開啟嶄新的彩色3D成像時代

讓協作更便捷,圖漾3D工業相機獲UR+認證







 工商網監
工商網監
評論