 深度解析MLPerf競賽Resnet50訓練單機最佳性能
深度解析MLPerf競賽Resnet50訓練單機最佳性能
MLPerf是一套衡量機器學習系統性能的權威標準,于2018年由谷歌、哈佛、斯坦福、百度等機構聯合發起成立,每年定期公布榜單成績,它將在標準目標下訓練或推理機器學習模型的時間,作為一套系統性能的測量標準。MLPerf訓練任務包括圖像分類(ResNet50)、目標物體檢測(SSD)、目標物體檢測(Mask R-CNN)、智能推薦(DLRM)、自然語言處理(BERT)以及強化機器學習(Minigo)等。最新的1.0版本增加了兩項新的測試項目:語音識別(RNN-T)和醫學影像分割(U-Net3D)。
本文將著重討論其中的圖像分類模型Resnet50。
ResNet是殘差網絡,該系列網絡被廣泛用于目標分類等領域,并作為計算機視覺任務主干經典神經網絡的一部分,是一個典型的卷積網絡。ResNet50網絡結構如下圖,首先對輸入做卷積操作,之后經過4個殘差模塊,最后進行一個全連接操作用于分類任務,ResNet50包含50個卷積操作。
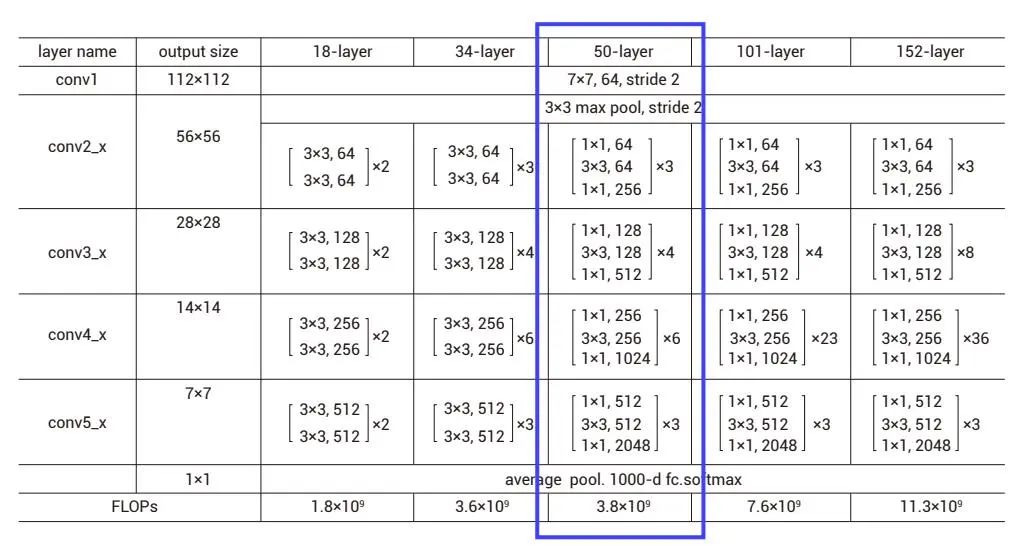
圖1 ResNet網絡結構▲

圖2 ResNet34網絡結構▲
來源:Deep Residual Learning for Image Recognition
作者:何愷明等
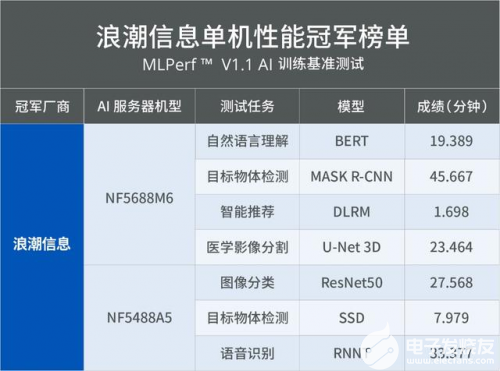
在MLPerf最早版本V0.5中,就包含Resnet50訓練任務。下圖是歷次MLPerf 訓練競賽Resnet50的單機最優性能。在MLPerf V0.7訓練基準測試中,浪潮AI服務器NF5488A5在33.37分鐘內完成ResNet50訓練,在所有提交的單服務器性能成績中名列榜首,比同類配置服務器快16.1%。而在最新的MLPerf 訓練V1.0榜單中,浪潮AI服務器NF5688M6進一步將Resnet50單機訓練提速到27.38分鐘,耗時較V0.7縮短了17.95%。
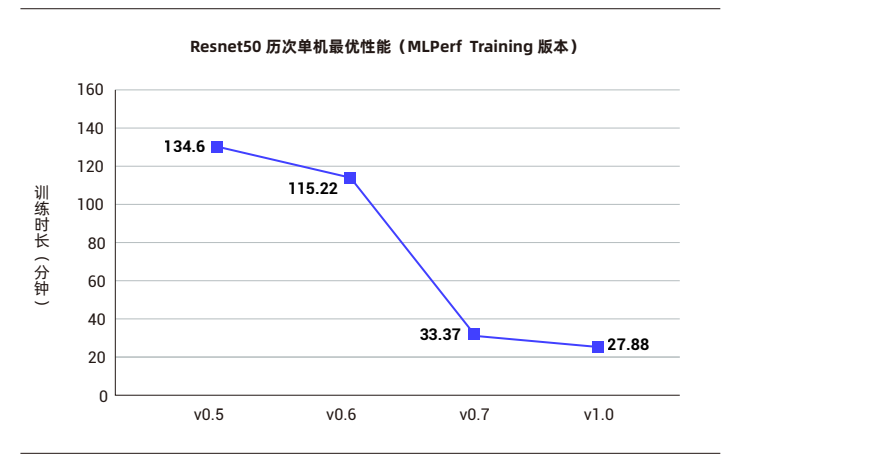
圖3 歷次MLPerf訓練測試Resnet50單機最優性能▲
性能的一次次突破,得益于硬件的發展和軟件的更新及優化。本文將深度解析取得這一成績背后的原因,談談Resnet50對計算平臺的需求以及如何提升訓練速度。
ResNet50訓練流程簡介
在MLPerf訓練V1.0測試中,Resnet50使用的數據集是包含128萬圖片的ImageNet2012(注:數據下載需要注冊),訓練的目標精度是75.9%,共需運行5次。廠商提交的成績是訓練模型達到目標精度所花費的時間(以分鐘為單位),值越小則表示性能越好。去掉一個最差性能和一個最優性能,其余3次的平均值為最終成績。
我們來看看Resnet50模型訓練的流程。首先,需要從硬盤上讀取訓練集,進行解碼,然后對圖像進行預處理,處理后的數據送入訓練框架進行訓練,經過若干個epoch后得到滿足精度要求的模型。
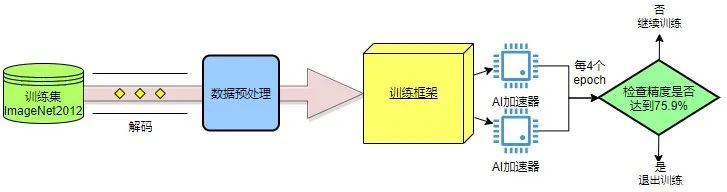
圖4 Resnet50模型訓練流程▲
硬件平臺選取
在Resnet50訓練中,硬件及設備平臺的選取至關重要。其中磁盤讀取性能、CPU運算性能、內存到顯存的傳輸性能以及GPU運算性能對訓練速度的影響都比較大:磁盤讀取性能直接決定訓練數據供給的速度;在引入DALI后,CPU的性能、CPU到GPU的傳輸帶寬以及GPU的性能共同決定了數據前處理的速度;而訓練中的前向推理和反向傳播由GPU的性能及GPU之間的數據傳輸帶寬決定。上述幾個硬件就如同工廠流水線上的幾名工人,任何一名工人的處理速度跟不上就會導致堆積,成為性能瓶頸,影響最終結果。因此這幾個重要部分不能有明顯的短板。
此次MLPerf評測浪潮選取了NF5688M6和NF5488A5服務器作為Resnet50的訓練平臺,不僅保證上述關鍵部件性能十分強勁,而且把它們很好地整合在一起,能更好地發揮它們的性能,滿足了模型訓練對硬件的性能要求,從而能快速地完成訓練任務。
NF5688M6在6U空間內支持2顆Intel最新的Ice Lake CPU和8顆NVIDIA最新的NVSwitch全互聯GPU。支持PCIe Gen4.0高速互聯,實現CPU和GPU之間數據高速傳輸。同時采用完全風道獨立,有效避免回流產生,實現風冷支持8顆 GPU高環溫下穩定工作。在本次MLPerf V1.0訓練測試中,NF5688M6獲得了ResNet50、DLRM和SSD三項任務的單機訓練性能第一。
NF5488A5在4U空間內實現8顆高性能NVIDIA GPU液冷散熱,搭載2顆支持PCIe4.0的AMD EPYC 7742 處理器,能夠為AI 用戶提供超強單機訓練性能和超高數據吞吐。NF5488A5在MLPerf V0.7基準測試中創下Resnet50訓練任務最佳單服務器性能成績,在MLPerf V1.0榜單中獲得了BERT任務的單機訓練性能第一。
訓練調優方法
Resnet50模型的訓練時長主要受兩大因素的影響:一是訓練模型到目標精度的步數,也就是需要多少輪可以達到目標精度,在其它性能相同的情況下步數越短則訓練時間越短,這部分需要找出一組超參數讓步數足夠少;二是圖4所示的數據讀取、數據預處理、訓練等各個步驟的處理速度。Resnet50的訓練數據為128萬張ImageNet2012圖片數據集,訓練過程對傳輸帶寬和計算能力的要求都很高。正如木桶理論所說,模型訓練速度是由流水線上最慢的部分決定,因此需要對流水線上的每一個步驟做分析,特別是著重分析整個流水線上的瓶頸,有針對性地去做優化。
從這兩大因素入手,浪潮主要采用了以下調優方法:
對學習率、batch size、優化器等超參數進行調試,將ResNet50模型收斂的步數從41降為35,帶來了15%左右的性能提升;
通過優化DALI,使用GPU資源加速解碼和數據處理環節,實現了1%左右的性能提升;
使用NCCL提升多GPU卡之間通信效率,加速訓練環節,性能提升0.1%左右。
下面分別按照訓練流程進行詳述。
| 訓練集讀取
訓練集是官方指定的。需要注意是讀取圖像帶來的開銷,如前所述,這個取決于磁盤讀取的速度和傳輸帶寬。好的磁盤自然能帶來更快的速度,另外通過組Raid 0 磁盤陣列也能帶來讀取速度的提升。我們曾在兩種不同的磁盤上使用同樣的Raid 0磁盤陣列,測試結果的訓練時長差異達到5‰左右,所以磁盤的選擇是很重要的。
| 解碼和數據處理
讀取數據后便是解碼和數據處理,通常它們是一起進行的。圖像解碼會比較耗時,常常會成為性能瓶頸,一般的處理方式只能利用CPU資源來進行圖像解碼,性能會受到極大的制約,我們選擇的是DALI(NVIDIA Data Loading Library)框架,這是一款高度優化用來加速計算機視覺深度學習應用的執行引擎,可以利用GPU的資源來做圖像解碼和預處理,號稱可以比原框架帶來4倍的性能提升。使用DALI來做預處理處理是個不錯的選擇,大家可以試試。
選定預處理的方法后,需要對其做優化,充分利用它的優勢,使之適用于我們的系統和數據。首先,我們先找出預處理數據的極限,通過設置訓練數據為模擬的擬合數據,這樣可以拋開數據讀取以及預處理的開銷,評測只有訓練開銷時的吞吐率,后面要做的就是調整DALI參數,讓真實數據的吞吐率接近擬合數據的吞吐率。
我們可以從以下幾個方面入手:
1. DALI的計算分配:DALI可以把預處理的計算按指定的比例分配到CPU和GPU上,如果分配給GPU的比例小了則不能充分利用GPU的性能,如果大了則會擠占后面的訓練資源;
2. DALI的處理線程:這個值大了,會占用資源,并讓一些線程處于等待狀態,這個值小了,不能充分利用資源;
3. ALI的數據預取量:值過小會讓后面的處理等待,值過大會占用過多顯存存儲和計算資源,甚至會耗盡顯存;
4. 使用融合函數:采用ImageDecoderRandomCrop函數,把解碼和隨機裁剪放在一起做,通常會比分開做性能提升不少。
前3個參數值的選取需要針對不同硬件設備和模型進行測試,找出一個最優組合,通過這個部分的優化,可以帶來大概7‰左右的性能提升。而采用融合函數通常能帶來1%左右的性能提升。
上述DALI代碼關鍵就是實現一個自己的Pipeline類,ResNet50的數據前處理關鍵代碼參考如下:
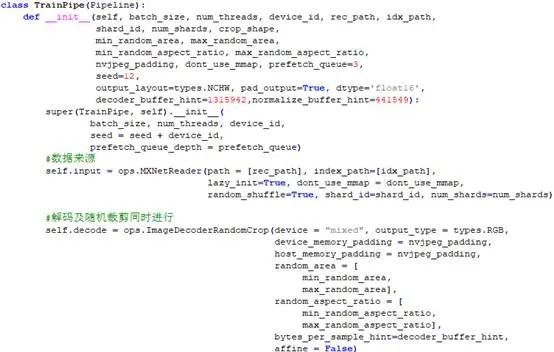
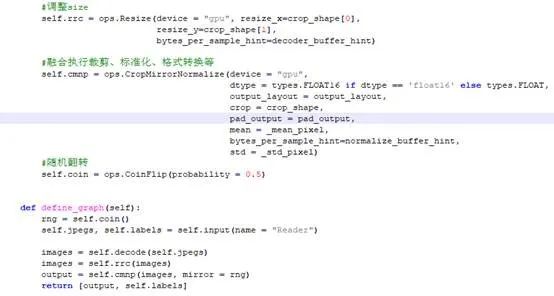
圖6 ResNet50數據前處理關鍵代碼▲
| 訓練框架選取
目前訓練框架有很多,如tensorflow、pytorch、mxnet等。不同的模型在不同的框架下有不一樣的性能表現,通過比較,我們發現mxnet框架在處理resnet50模型的訓練上有較大的優勢。
另外,使用多塊GPU進行訓練時,各卡之間有大量的數據傳輸,各個框架會采用horovod或者直接采用NCCL來進行分布式的訓練,而horovod本質上也是調用NCCL進行的數據傳輸。在MLPerf的示例代碼中有的框架會提供默認的NCCL參數選擇,這在不同的硬件設備中可能會有所不同,例如在最新的NVSWITCH架構中MAXCHANNEL數為32,而在之前的NVLINK架構中默認值為16最佳。在大部分的情況下,NCCL內部的默認值即可滿足其要求, 但仍要注意其傳入參數對傳輸速度的影響。另外經測試最新的NCCL版本,對于不同的硬件設備可能不是速度最快的版本,可通過NCCL_TEST進行測試選擇,這里不再展開說明。
| 超參數調優
訓練中的一個關鍵因素就是超參數的調試,一組好的超參數能讓模型經過更少的epoch就收斂,自然會讓性能提升。試想一下如果兩個廠商的訓練吞吐率一樣,但其中一家的模型要10個epoch才能收斂到目標精度,而另一家的模型可以8個epoch就收斂,相當于2位選手以同樣的速度下山,其中一位選手找到的路需要走10公里,另一位找到的路只需要走8公里,那毫無疑問走8公里路的占有明顯優勢,能更快到達終點。所以挑選一組合適的超參數能事半功倍。實際上,MLPerf Training為了避免走“錯路”帶來的不公平,特意制定了超參數借用規則,讓大家借一條“路”再跑一次,在同一個賽道下的結果才公平。
當然,要找這樣一條“路”是不容易的,下面給出一些超參數調試的小技巧:
學習率(learning rate):學習率對收斂速度和精度都有影響。而調整學習率也是讓人抓狂的事情,經常出現梯度不收斂。一般對于學習率等超參數采用先粗調、再微調的策略。其中在粗調過程中學習率先以10的倍數進行調整,如選取0.01、0.1、1等值進行嘗試,等學習率基本固定后,再進行精調,可以在基準值上每次以10%的變化量進行調整。
batch size:一般來講增大batch size可以提高訓練速度,同時也可以提高AI加速器的利用率,但稍有不慎來個out of memory就可以終止你增大該值的念想,另外過大的batch size也會帶來精度的下降。那么選一個小batch size是否就可以了呢?經實驗驗證,過小的batch size也會導致精度下降,所以該值的選取,也需要調試。此外,batch size和learning rate也會相互影響,一般操作是,在增大batch size的同時,也應對應的增大learning rate。
優化器:一般在分類模型中,最常用的優化器為隨機梯度下降SGD。雖然adam等優化器可以獲取到更快的速度,但是經常會出現精度下降的問題。除此之外還有LARS(Layer-wise Adaptive Rate Scaling:https://arxiv.org/abs/1708.03888)優化器,這是MLPerf中各個參賽廠家普遍使用的優化器。LARS的優化器的公式如下:
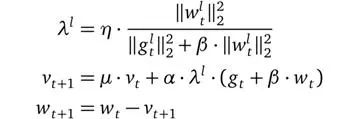
LARS是SGD 的有動量擴展,可以適應每層的學習率,核心是讓網絡的每個層根據自己的情況動態的調整學習率,作用是可以有效緩解在較大batch size訓練的前期由于學習率太大導致的不穩定問題。
按照上述的方法調試超參數,最終我們將ResNet50模型收斂的epoch次數從41降為35,帶來了15%左右的性能提升,看來正確的“路”效果很明顯,超參數帶來的性能提升不容小覷。
總之,影響訓練性能的因素有很多。本文主要從硬件平臺和軟件優化的角度,以MLPerf訓練V1.0榜單中的ResNet50模型為例,從數據處理、訓練框架、超參數等方面來提升訓練速度,取得了不錯的效果。浪潮優化代碼已共享至Github(附1)。如果各位有興趣可以試一試,希望能幫助你提升模型訓練速度。
展望
MLPerf競賽經過3年多時間的發展,已經逐漸進入成熟期,其模型的選取也緊跟時代潮流,為評估各類AI計算平臺在實際應用場景中的性能提供了權威有效的基準。MLPerf是一個開放社區,很多廠商將優化方法回饋至社區,推動AI技術的共同進步。如浪潮已將在MLPerf V0.7中用到的ResNet收斂性優化方案共享給社區成員,得到廣泛采納并應用到本次V1.0測試中。可以預見,隨著谷歌、英偉達、英特爾、浪潮、戴爾等眾多主流芯片及系統廠商持續參與MLPerf,并貢獻軟硬件系統優化方法,未來AI計算平臺的性能將會得到進一步提升,為AI技術在更多應用場景的落地打下堅實的基礎。
* 附:
1.浪潮代碼:
https://github.com/mlcommons/training_results_v1.0/tree/master/Inspur/benchmarks/resnet/implementations/mxnet
按照下面的步驟來搭建環境:
a. 下載以上代碼
b. 按照代碼中README.MD中的描述下載所需數據,并參考附2里的方法對數據進行預處理,生成Mxnet格式的數據集
c. 進入mxnet目錄,通過docker構建所需的image,可參考以下代碼:
cd ./benchmarks/resnet/implementations/mxnet/docker build --pull -t image_name:image_version .
d. Image構建完成后,修改設置參數的配置文件config_NF5688M6.sh,修改參數為適合你的系統的值(填入按照后面的調優方法去找出優化后的值)
e. 至此軟件環境構建完成,可以開始執行訓練, 比如我們使用的系統是“NF5688M6”:
source config_5688M6.sh
DGXSYSTEM="NF5688M6"
CONT=image_name:image_version
DATADIR=/path/to/preprocessed/data
LOGDIR=/path/to/logfile ./run_with_docker.sh
接下來等著訓練結束,通過查找日志里的“run_stop”和“run_start”記錄的時間點就可以計算出整個訓練時間(單位是秒)。
2.數據預處理:
https://github.com/NVIDIA/DeepLearningExamples/blob/master/MxNet/Classification/RN50v1.5/README.md#prepare-dataset
審核編輯:湯梓紅
-
服務器
+關注
關注
12文章
9160瀏覽量
85421 -
浪潮
+關注
關注
1文章
460瀏覽量
23864 -
機器學習
+關注
關注
66文章
8418瀏覽量
132634 -
MLPerf
+關注
關注
0文章
35瀏覽量
640
原文標題:深度解析MLPerf競賽Resnet50訓練單機最佳性能
文章出處:【微信號:浪潮AIHPC,微信公眾號:浪潮AIHPC】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深度學習與圖神經網絡學習分享:CNN經典網絡之-ResNet
YOLOv6中的用Channel-wise Distillation進行的量化感知訓練
【KV260視覺入門套件試用體驗】四、學習過程梳理&DPU鏡像&Resnet50
【KV260視覺入門套件試用體驗】KV260系列之Petalinux鏡像+Resnet 50探索
索尼發布新的方法,在ImageNet數據集上224秒內成功訓練了ResNet-50
百度大腦EdgeBoard計算卡基于Resnet50/Mobile-SSD模型的性能評測
浪潮發布AI服務器NF5488A5,計算性能提升234%
浪潮信息MLPerf單機系統測試:7項性能第一
MLPerf訓練性能測試榜單發布,浪潮信息刷新多項紀錄
【R329開發板評測】實機測試Resnet50

如何使用框架訓練網絡加速深度學習推理

NVIDIA 與飛槳團隊合作開發基于 ResNet50 的模型示例
MLPerf世界紀錄技術分享:優化卷積合并算法提升Resnet50推理性能
基于改進ResNet50網絡的自動駕駛場景天氣識別算法






 工商網監
工商網監
評論