 使用無監督學習和合成數據作為數據增強方法來分類異常
使用無監督學習和合成數據作為數據增強方法來分類異常
導讀
創建異常檢測模型,實現生產線上異常檢測過程的自動化。在選擇數據集來訓練和測試模型之后,我們能夠成功地檢測出86%到90%的異常。
介紹
異常是指偏離預期的事件或項目。與標準事件的頻率相比,異常事件的頻率較低。產品中可能出現的異常通常是隨機的,例如顏色或紋理的變化、劃痕、錯位、缺件或比例錯誤。
異常檢測使我們能夠從生產流程中修復或消除那些處于不良狀態的部件。因此,由于避免生產和銷售有缺陷的產品,制造成本降低了。在工廠中,異常檢測由于其特點而成為質量控制系統的一個有用工具,對機器學習工程師來說是一個巨大的挑戰。
不推薦使用監督學習,因為:在異常檢測中需要內在特征,并且需要在完整數據集(訓練/驗證)中使用少量的異常。
另一方面,圖像比較可能是一個可行的解決方案,但標準圖像處理多個變量,如光線、物體位置、到物體的距離等,它不允許與標準圖像進行像素對像素的比較。在異常檢測中,像素到像素的比較是不可或缺的。
除了最后的條件外,我們的建議包括使用合成數據作為增加訓練數據集的方法,我們選擇了兩種不同的合成數據,隨機合成數據和相似異常合成數據。(詳見數據部分)
這個項目的目標是使用無監督學習和合成數據作為數據增強方法來分類異常 — 非異常。
背景研究
異常檢測與金融和檢測“銀行欺詐、醫療問題、結構缺陷、設備故障”有關(Flovik等,2018年)。該項目的重點是利用圖像數據集進行異常檢測。它的應用是在生產線上。在項目開始時,我們熟悉了自動編碼器在異常檢測中的功能和架構。作為數據計劃的一部分,我們研究了包括合成噪聲圖像和真實噪聲圖像的重要性(Dwibedi et al, 2017)。
數據計劃是這個項目的重要組成部分。選擇一個數據集,有足夠的原始圖像和足夠的真實噪聲的圖像。同時使用合成圖像和真實圖像。在處理真實圖像時,這些數據需要對目標有全覆蓋,但是在尺度和視角方面無法完全獲得。“……要區分這些實例需要數據集對對象的視角和尺度有很好的覆蓋”(Dwibedi et al, 2017)。
合成數據的使用允許“實例和視角的良好覆蓋”(Dwibedi et al, 2017)。合成圖像數據集的創建,包括合成渲染的場景和對象,是通過使用Flip Library完成的,這是一個由LinkedAI創建的開源python庫。“剪切,粘貼和學習:非常簡單的合成實例檢測”,通過這些數據的訓練和評估表明,使用合成數據集的訓練在結果上與在真實圖像數據集上的訓練具有可比性。
自動編碼器體系結構“通常”學習數據集的表示,以便對原始數據進行維數縮減(編碼),從而產生bottleneck。從原始的簡化編碼,產生一個表示。生成的表示(重構)盡可能接近原始。
自動編碼器的輸入層和輸出層節點數相同。“bottleneck值是通過從隨機正態分布中挑選出來的”(Patuzzo, 2020)。在重構后的輸出圖像中存在一些重構損失(Flovik, 2018),可以通過分布來定義原始圖像輸入的閾值。閾值是可以確定異常的值。
去噪自動編碼器允許隱藏層學習“更魯棒的濾波器”并減少過擬合。一個自動編碼器被“從它的一個損壞版本”來訓練來重建輸入(去噪自動編碼器(dA))。訓練包括原始圖像以及噪聲或“損壞的圖像”。隨著隨機破壞過程的引入,去噪自編碼器被期望對輸入進行編碼,然后通過去除圖像中的噪聲(破壞)來重建原始輸入。
用去噪自編碼器提取和組合魯棒特征,去噪自編碼器應該能夠找到結構和規律作為輸入的特征。關于圖像,結構和規律必須是“從多個輸入維度的組合”捕獲。Vincent等(2020)的假設引用“對輸入的部分破壞的魯棒性”應該是“良好的中間表示”的標準。
在這種情況下,重點將放在獲取和創建大量原始和有噪聲圖像的能力上。我們使用真實數據和合成數據創建了大量的圖像來訓練我們的模型。
根據Huszar(2016)的說法,擴張卷積自動編碼器“支持感受野的指數擴展,而不丟失分辨率或覆蓋范圍。“保持圖像的分辨率和覆蓋范圍,對于通過擴大卷積自動編碼器重建圖像和使用圖像進行異常檢測是不可或缺的。這使得自動編碼器在解碼器階段,從創建原始圖像的重建到更接近“典型”自動編碼器結構可能產生的結果。
Dilated Convolutional Autoencoders Yu et al.(2017),“Network Intrusion Detection through Stacking Dilated Convolutional Autoencoders”,該模型的目標是將無監督學習特征和CNN結合起來,從大量未標記的原始流量數據中學習特征。他們的興趣在于識別和檢測復雜的攻擊。通過允許“非常大的感受野,而只以對數的方式增加參數的數量”,Huszar (2016),結合無監督CNN的特征學習,將這些層堆疊起來(Yu et al., 2017),能夠從他們的模型中獲得“卓越的性能”。
技術
Flip Library (LinkedAI):https://github.com/LinkedAi/flip
Flip是一個python庫,允許你從由背景和對象組成的一小組圖像(可能位于背景中的圖像)中在幾步之內生成合成圖像。它還允許你將結果保存為jpg、json、csv和pascal voc文件。
Python Libraries
在這個項目中有幾個Python庫被用于不同的目的:
可視化(圖像、指標):
OpenCV
Seaborn
Matplotlib
處理數組:
Numpy
模型:
Keras
Random
圖像相似度比較:
Imagehash
PIL
Seaborn (Histogram)
Weights and Biases
Weights and bias是一個開發者工具,它可以跟蹤機器學習模型,并創建模型和訓練的可視化。它是一個Python庫,可以作為import wandb導入。
它工作在Tensorflow, Keras, Pytorch, Scikit,Hugging Face,和XGBoost上。使用wandb.config配置輸入和超參數,跟蹤指標并為輸入、超參數、模型和訓練創建可視化,使它更容易看到可以和需要更改的地方來改進模型。
模型&結構
我們基于當前的自動編碼器架構開始了我們的項目,該架構專注于使用帶有卷積網絡的圖像(見下圖)。經過一些初步的測試,基于研究(參見參考資料)和導師的建議,我們更改為最終的架構。
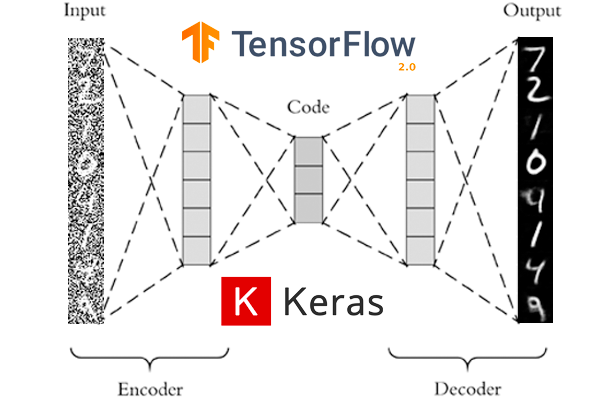
自編碼器的典型結構
使用擴張特征
擴張特征是一種特殊的卷積網絡,在傳統的卷積核中插入孔洞。在我們的項目中,我們特別的對通道維度應用了膨,不影響圖像分辨率。
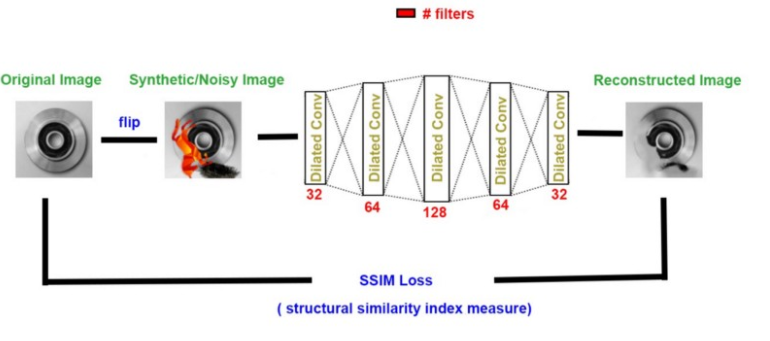
最終的結構
圖像相似度
這個項目的關鍵點之一是找到一個圖像比較的指標。利用圖像比較度量對模型進行訓練,建立直方圖,并計算閾值,根據該閾值對圖像進行異常和非異常的分類。
我們從逐個像素的L2歐氏距離開始。結果并不能確定其中的一些差異。我們使用了帶有不同散列值(感知、平均和差異)的Python Imagehash庫,對于相似的圖像,我們得到了不同的結果。
我們發現SSIM(結構相似度指數度量)度量為我們提供了一對圖像之間相似度的度量,此外,它是Keras庫的一個內置損失。
直方圖
在對模型進行訓練和評估后,利用其各自的數據集,對重建后的圖像和原始圖像之間的相似度進行識別。當然,由于原始圖像的多樣性(如,大小,位置,顏色,亮度和其他變量),這種相似性有一個范圍。
我們使用直方圖作為圖的表示,以可視化這個范圍,并觀察在哪個點會有不同的圖像。
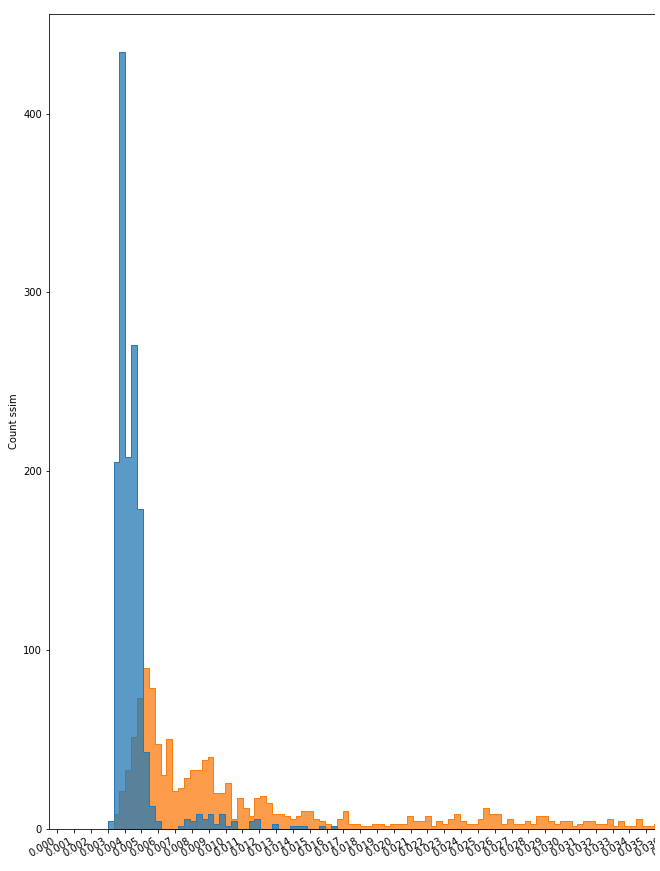
直方圖的例子
數據
使用的數據從Kaggle下載:表面裂紋檢測數據集:https://www.kaggle.com/arunrk7/surface-crack-detection和鑄造產品質量檢查圖像數據:https://www.kaggle.com/ravirajsinh45/real-life-industrial-dataset-of-casting-product?select=casting_data。
第一個是裂縫數據集,包含20,000張負樣本墻圖像(無裂縫)和20,000張正樣本墻圖像(有裂縫)。在這種情況下,裂縫被認為是異常的。所有數據都是227x227像素的RGB通道。下面顯示了每個組的示例。

我們從沒有異常的組中選取了10,000張圖像來生成不同的合成數據集。然后合成的數據集被分為兩種類型:一種是帶有類似異常的噪聲(51張圖像是用Photoshop創建的),另一種是使用水果、植物和動物等隨機物體。所有用作噪聲的圖像都是png格式的,背景是透明的。下面是用于模型訓練的兩種類型的數據集的一些例子。

第二個數據集,cast數據集分為兩組,一組為512x512像素的圖像(有異常的781張,無異常的519張),另一組為300x300像素的圖像(有異常的3137張,有異常的4211張)。
所有圖像都有RGB通道。使用的是300 x 300像素的圖像。后者,來自Kaggle,91.65%的數據被分為訓練,其余的測試。對于該數據集,異常包括:邊緣碎片、劃痕、表面翹曲和孔洞。下面是一些有和沒有異常的圖像示例。

我們使用1,000張屬于訓練組的無缺陷圖像來生成合成數據數據集。
在前面的例子中,我們創建了兩種類型的數據集:一種帶有類似于異常的噪聲(51張圖像是用Photoshop創建的),另一種帶有隨機對象的噪聲,如動物、花朵和植物(裂縫數據集中使用的相同的80張圖像)。
下面是一些在模型訓練中使用的圖像示例。

所有合成數據都是使用Flip庫創建的。在每個生成的圖像中,選擇兩個對象并隨機放置。
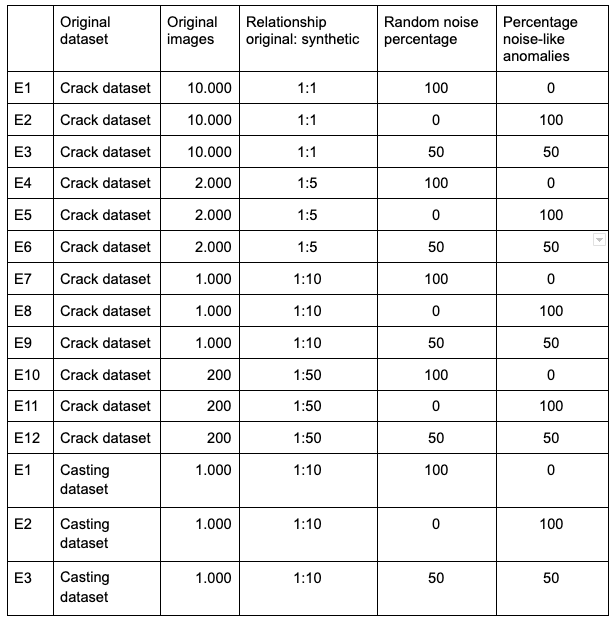
對象應用了三種類型的轉換:翻轉、旋轉和調整大小。生成的圖像保存為jpg格式。項目使用的數據集如下表所示:
實驗
根據上述表格說明,我們的主要目的是研究數據集的哪些變化可能呈現最好的結果,我們用這些數據和獲得的結果訓練了模型(見下面的圖表)。
對于每個數據集,我們評估了幾個指標,如(SSIM)損失、召回、精度、F1和精度。在每一次實驗中,我們將評估代表這組噪聲圖像和重建圖像之間圖像相似性的直方圖。
為了跟蹤和比較我們的結果,我們使用了library Weight & bias,它允許一種簡單的方式來存儲和比較每個實驗的結果。

訓練
為了在我們的環境中保持少量的變量,我們決定總是使用一個有1000個樣本的數據集,而不管真實數據和合成數據之間的關系。
在算法中,我們將各自的數據集分割為95%進行訓練,5%進行測試結果。除此之外,我們的評估只使用了真實的數據。

評估和結果
下面是一些實驗的主要結果。你可在以下連結找到所有的結果:
裂縫數據集:https://wandb.ai/heimer-rojas/anomaly-detector-cracks?workspace=user-
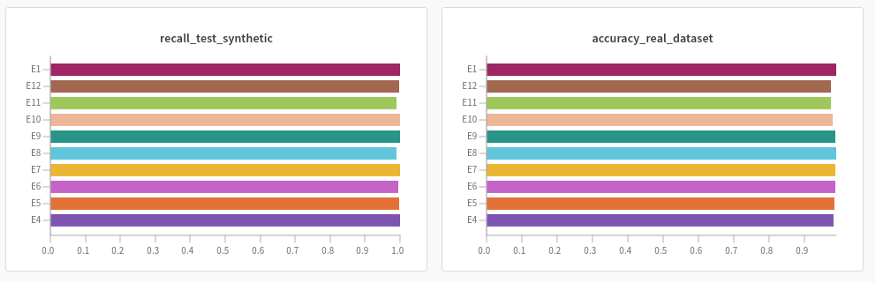
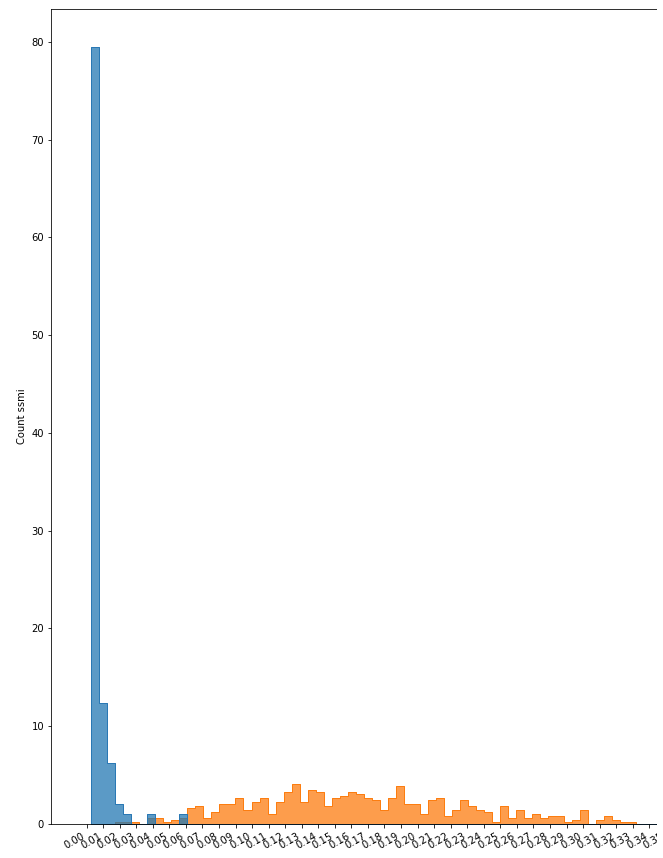
裂縫直方圖

裂縫數據集的異常檢測
對于裂紋數據集,實驗結果也很好(91% ~ 98%),實驗之間沒有顯著差異。與無異常的圖像相比,其行為主要取決于裂紋大小和顏色等變量。
鑄造工件數據集:https://wandb.ai/heimer-rojas/anomaly-detector-cast?workspace=user-heimer-rojas
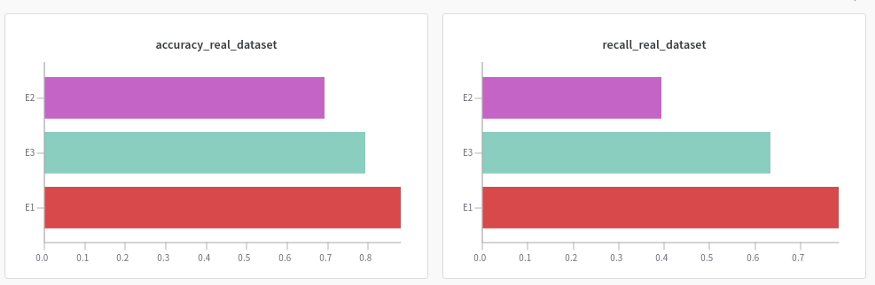
鑄造工件數據集的準確率和召回率
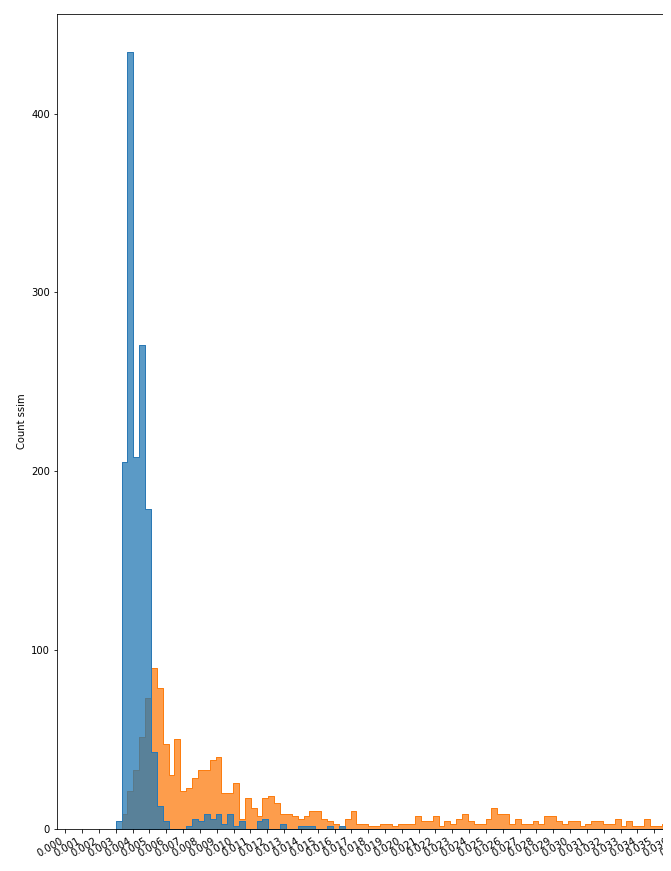
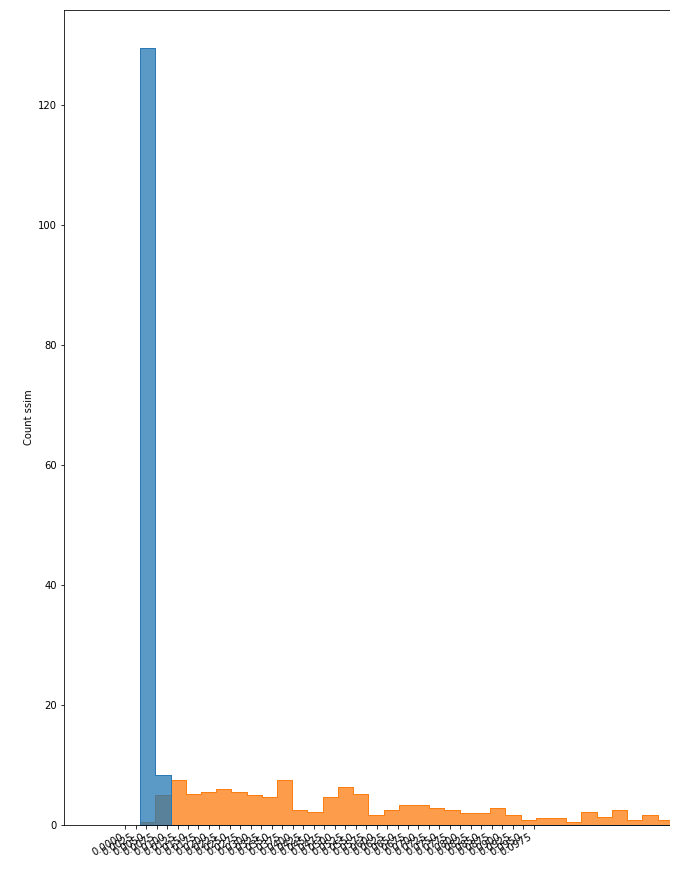
鑄造件E1&E3

鑄造件數據集的異常檢測
挑戰
訓練時間長,在谷歌Colab和專業版中使用GPU訓練。
通過上傳壓縮后的zip格式的數據來解決長時間的數據加載問題,這樣每個數據集上傳一個文件,大大減少了時間。
最初的提議是使用哥倫比亞汽車生產線的數據集,不幸的是,正樣本和負樣本圖像的質量和數量都不足以創建一個合適的機器學習模型。這種情況促使我們決定使用Kaggle的數據集,與生產線生產的條件類似。
每個數據集在異常情況下的可視化差異是不同的,需要考慮正常的圖像結構,如圖像的顏色、亮度等內在特征
需要人類的專業知識來根據真實數據或合成數據的閾值選擇適當的閾值。這可能要視情況而定。
討論
實現一個真正的機器學習項目需要幾個步驟,從想法到模型的實現。這包括數據集的選擇、收集和處理。
在使用圖像的項目中有“調試腳本”是很重要的。在我們的例子中,我們使用了一個允許我們可視化的腳本:原始數據集、新的合成圖像和自編碼器去噪之后的圖像,使我們能夠評估模型的性能。
審核編輯:劉清
-
編碼器
+關注
關注
45文章
3643瀏覽量
134512 -
OpenCV
+關注
關注
31文章
635瀏覽量
41347 -
python
+關注
關注
56文章
4797瀏覽量
84683
原文標題:詳解如何用深度學習實現異常檢測/缺陷檢測
文章出處:【微信號:機器視覺沙龍,微信公眾號:機器視覺沙龍】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
適用于任意數據模態的自監督學習數據增強技術

基于transformer和自監督學習的路面異常檢測方法分享

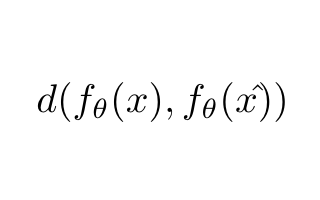






 工商網監
工商網監
評論