 為什么基于學習的VO很難超過傳統VSLAM?
為什么基于學習的VO很難超過傳統VSLAM?
0. 筆者個人體會
深度學習在其他CV領域可以說已經完全碾壓了傳統圖像算法,例如語義分割、目標檢測、實例分割、全景分割。但是在VSLAM領域,似乎還是ORB-SLAM3、VINS-Fusion、DSO、SVO這些傳統SLAM算法占據領導地位。那么這背后的原因是什么?基于深度學習的VO目前已經發展到了什么程度?
本文將帶領讀者探討基于學習的VO難以訓練的真正原因,并分析幾個目前SOTA的學習VO,深入淺出理解基于學習的VO和傳統VSLAM算法之間的區別是什么。當然筆者水平有限,如果有不同見解歡迎大家一起討論,共同學習!
1. 為什么基于學習的VO很難超過傳統VSLAM?
最早的基于學習的VO應該是2017年ICRA論文“DeepVO: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks”,這個架構也非常直觀,就是將圖片序列利用CNN提取特征,然后借助RNN輸出位姿。之后它們團隊也在2018年ICRA發表了“End-to-end, sequence-to-sequence probabilistic visual odometry through deep neural networks”,提出了DeepVO的改進版本ESP-VO,但可以看出它們在一些場景的效果還是不太好的。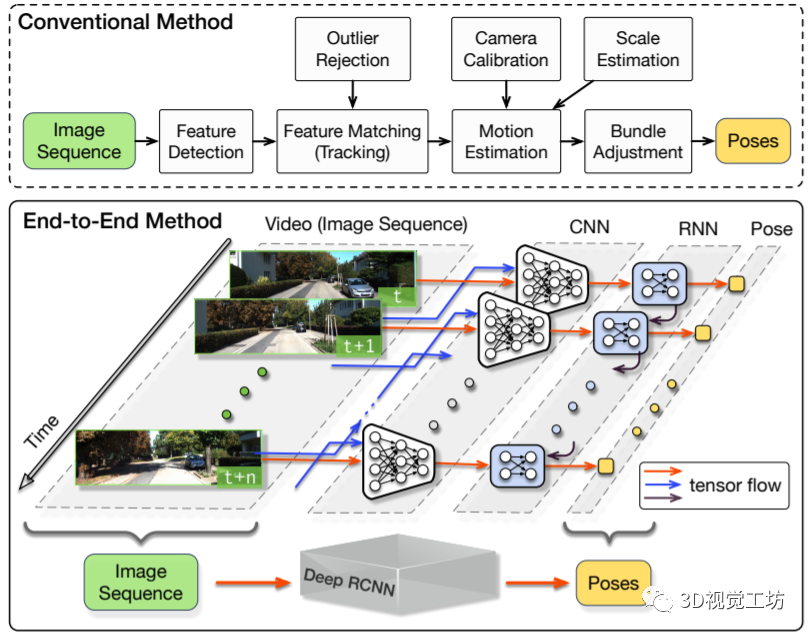
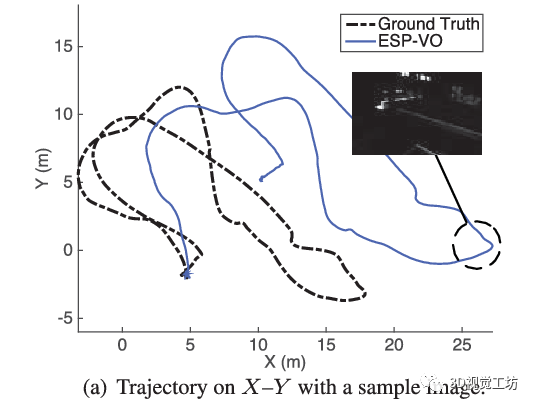
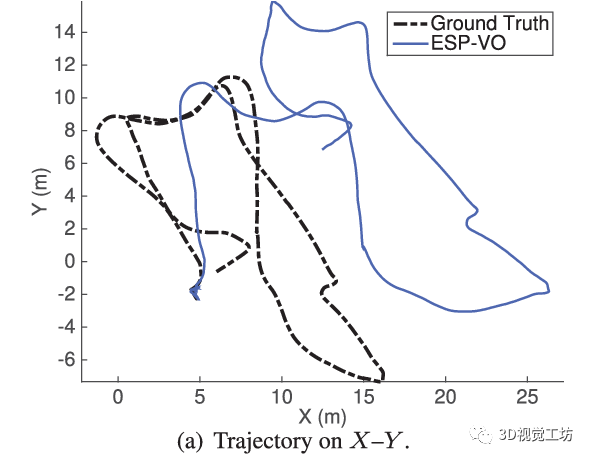
我認為基于學習的VO之所以失敗,主要有六點原因。
首先就是數據量的問題,深度學習是非常吃數據的。
模型越大,想讓網絡權重收斂所需的數據規模也就越大。近些年隨著Transformer的橫空出世,深度網絡的參數量幾乎是呈幾何倍數增長,動不動就出現上億參數的大模型。
但目前VSLAM的評估場景主要是KITTI (22個序列)、EuRoC (11個序列)和TUM (24個序列)這三個數據集。
即使是三個數據集加起來,也沒有ImageNet這一個數據集大。因此想使用深度學習直接定位建圖的話,模型根本喂不飽,訓練就顯得非常困難。
但僅僅如此嗎?
如果只是數據集規模的問題,那直接在車上放一個攝像頭,開車出去采個十幾萬張圖片不就可以輕松解決問題了嗎?或者說根本不需要自己采集數據集,直接使用其他CV領域的數據集,比如伯克利自動駕駛BDD數據集里面有10萬個視頻序列,不一樣可以用嗎? 這里就需要說到另一個很少有人關注的點,就是空間位姿中的主成分問題。
KITTI數據集是用無人車采集的,EuRoC是用無人機采集的,TUM是用手持相機采集的。這里不可避免得就涉及到六個自由度的分布問題,顯然KITTI數據集中的位姿基本都是繞Z軸的旋轉和水平方向的平移(顯然車不可能無緣無故翻滾和上升),EuRoC和TUM數據集中的位姿也是繞Z軸的旋轉和水平方向的平移占主導(這個也很容易理解,錄制視頻的時候也很難有特別復雜的雜技運動)。
這是什么意思呢?
就是說,目前SLAM算法中常用的數據集,基本上只有兩個方向的運動,其他4個自由度的運動很少或基本為0。這就導致基于學習的方法在訓練過程中,只能學習到繞Z軸的旋轉和水平方向的平移這兩個方向的運動,其他4個方向很難得到充分學習。不僅如此,其他4個方向還會帶來大量噪聲,導致本來學好的位姿也不準了!
第三點原因也相當重要,就是圖像分辨率和內參的問題!深度模型在訓練之前,輸入數據會統一Resize為固定的大小,也就是說基于學習的VO在訓練過程中學到的是這一固定分辨率下的位姿估計結果。
當網絡換一個數據集進行測試的時候,由于圖片分辨率變了,網絡沒學習過這種設置下的位姿,所以輸出結果非常受影響。但是傳統SLAM算法不會有這種問題,因為它是完全基于對極幾何和PNP進行求解的,即使換一個數據集,結果也不會受到太大影響。
第四點原因,就是所有單目算法都會面臨的尺度模糊問題。單目算法的尺度不確定性在此不做過多贅述。需要注意的是,基于學習的VO在一個數據集上會學習到這個數據集所對應的尺度,這個尺度還是一個相對尺度。當我們希望將網絡遷移到另一個數據集時,由于這個尺度變化,會導致網絡估計出的位姿非常不準。
第五,基于學習的VO很難實現回環檢測。
熟悉ORB-SLAM3的同學知道,ORB-SLAM3中是存在短期、中期、長期、多地圖這四種數據關聯的。短期數據關聯對應跟蹤線程,也是大多數VO使用的唯一數據關聯類型,一旦地圖元素從視野中消失,就會被丟棄,即使回到原來的地方,也會造成持續的位姿漂移。中期數據關聯對應局部建圖,通過BA優化可以約束具有共視關系的關鍵幀。長期數據關聯指回環和重定位,可以拉回大幅度的累計漂移。
多地圖數據關聯可以使用之前已經建立的多塊地圖來實現地圖中的匹配和BA優化。通過這四種數據關聯模型,ORB-SLAM3實現了非常強的全局一致性約束,使得整體的位姿估計非常準。但是對于基于學習的VO來說,僅有幀間匹配,很難去實現回環這種長期數據關聯,位姿漂移的問題非常嚴重。
最后一個問題就是,現有的深度學習方法非常吃計算資源。2022年了,基本上3090顯卡只能勉強達到深度學習的入門門檻,沒有幾塊A100的話,大模型想都不要想。目前效果最好DROID-SLAM甚至需要4塊3090才能達到實時運行。但SLAM算法的最終目標還是落地,要求的是能在低功耗的嵌入式設備上實時運行。
目前大公司的SLAM算法都在做減法來盡可能縮減算力要求,這時候突然要求GPU加速就有點令人難以接受,畢竟誰也不可能真的給自動駕駛汽車或者配送無人機裝4塊A100吧?
2. 傳統VSLAM就一定穩定嗎?
我們所熟知的ORB-SLAM、VINS等算法在KITTI、EuRoC、TUM這些靜態場景中都已經實現了非常好的效果。但問題是這些場景的規模還是太小了,很少有什么運動模糊的情況,并且也沒有什么動態物體。即使它們之中有一些動態序列,動態物體所占的圖像范圍也沒有多大。
當涉及到一些高動態、無紋理、大范圍遮擋等挑戰性的場景時,傳統的VSLAM算法很容易崩潰。如下圖所示,測試ORB-SLAM在挑戰性數據集Tartan Air中的運行結果時發現,ORB-SLAM平均只能跑完一半的序列,平均絕對軌跡誤差ATE甚至達到了27.67m,雙目比單目的效果好一些,但也沒有好太多。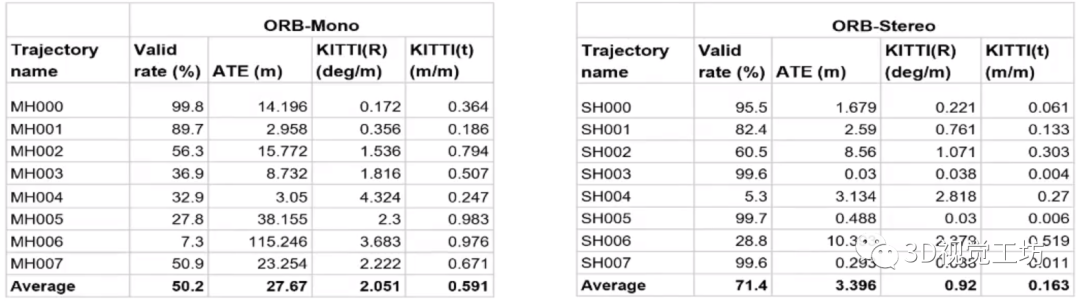

現有的傳統方法也基本都是加入點線面特征,或者引入IMU/激光雷達/輪速計/GNSS等多傳感器來輔助定位和建圖。
但現有算法也基本都是針對特定場景才能運行的,針對這些挑戰性場景,始終都沒有一個統一且完善的解決方案。 但在深度學習領域,這些都不是問題!目前YOLO已經出到了v7版本,可以輕輕松松檢測上千種不同目標,基于Transformer語義分割/實例分割的IoU也已經不停漲點。
不用說檢測出一個動態物體,就是多目標跟蹤的算法現在也已經非常成熟。 所以說,深度學習結合SLAM是一個非常有價值的大方向!雖然現有的深度學習方法也都有不同的問題,但相信隨著時間變化,這些問題都可以被解決。
3. TartanVO
TartanVO來源于2020年CoRL論文“TartanVO: A Generalizable Learning-based VO”,作者是卡內基梅隆大學的王雯珊。
前面說到,ORB-SLAM在挑戰性數據集Tartan Air上運行很容易崩潰,Tartan Air數據集也是王雯珊團隊的工作。
Tartan Air是一個大規模、多場景、高動態的仿真數據集,里面包含20種不同的環境、500+個軌跡以及40萬+幀圖像。雖然Tartan Air并不來源于真實傳感器,只是一個仿真場景,但其實內部的圖像已經足夠真實。
我們沿著TartanVO作者的設計思路來進行分析,首先TartanVO設計了一個簡單并傳統的網絡架構,思路也非常簡單,輸入是連續的兩幀圖像。網絡首先會提取特征并估計光流,之后利用Pose網絡估計出位姿。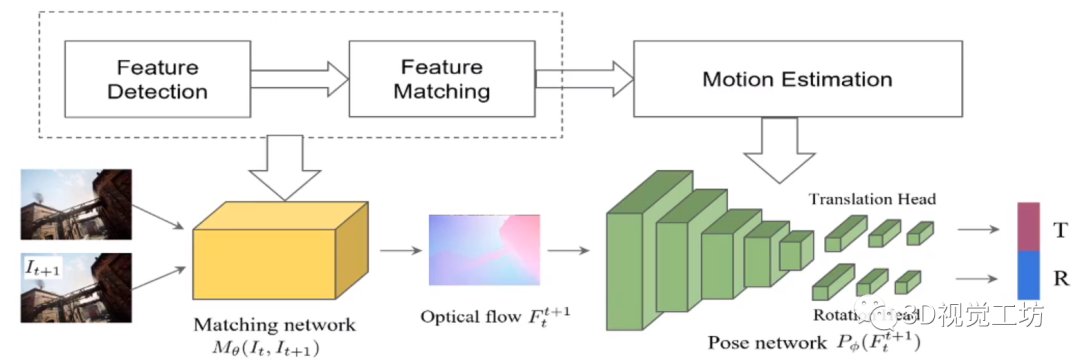
但TartanVO的作者發現,訓練過程中的損失一直降不下來!通過分析發現這是由于平移位姿估計差引起的,那原因就顯而易見了,還是單目尺度不確定問題!為了解決這個問題,作者設計了對應的尺度一致性損失,只估計相對尺度: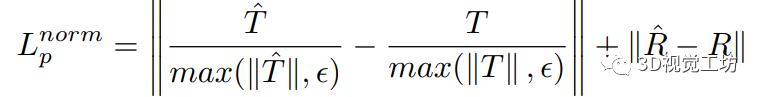
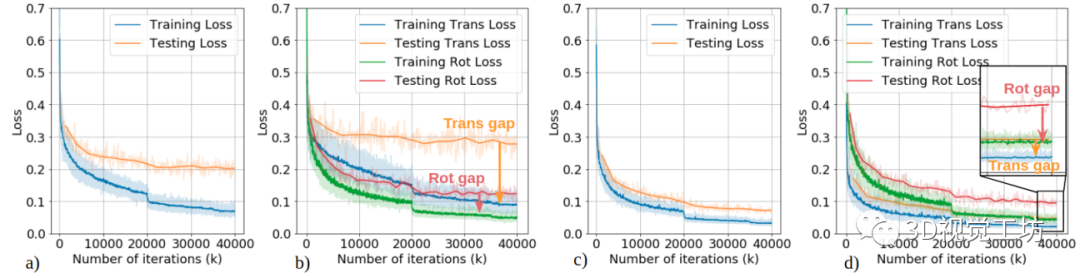
同時TartanVO的另一個重要創新點在于,通用性非常強!前面說到,不同數據集的圖像分辨率和內參不一致,這影響了網絡的泛化性能。
因此TartanVO又加入了內參層,在訓練過程中同時估計相機內參矩陣。同時在訓練過程中對Tartan Air數據集的圖像進行隨機裁剪和縮放,以此來模擬不同的內參。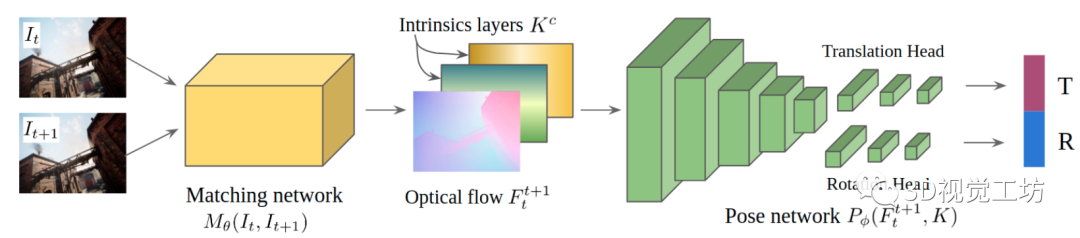
定量結果也證明了網絡的有效性,雖然訓練損失提高了(模型任務復雜了),但測試損失還是得到了明顯降低。
下表是在KITTI數據集上的測試結果,注意TartanVO并沒有進行Finetune,但是效果比其他基于學習的VO方法好。值得一提的是,TartanVO的平移精度很高,但是相較于ORB-SLAM的旋轉精度較低,這是因為ORB-SLAM具有回環檢測模塊。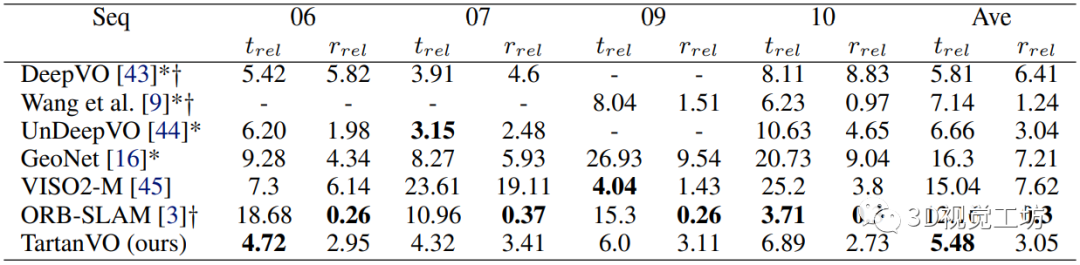
4. 基于TartanVO的動態稠密RGB-D SLAM
這篇論文是今年5月上傳到arXiv的,論文名為“Dynamic Dense RGB-D SLAM using Learning-based Visual Odometry”,同樣是卡內基梅隆大學的研究成果。
這個網絡是基于TartanVO進行的,相當于TartanVO在動態環境中的改進,輸出是沒有動態對象的稠密全局地圖。
算法的主要思想是從兩個連續的RGB圖像中估計光流,并將其傳遞到視覺里程計中,以通過匹配點作為直接法來預測相機運動。然后通過利用光流來執行動態分割,經過多次迭代后,移除動態像素,這樣僅具有靜態像素的RGB-D圖像就被融合到全局地圖中。
不過不知為何,這篇論文沒有進行定量評估,沒有和其他SLAM算法的一些ATE、RTE等參數的對比,只有一些定量對比,可能是工作還在進一步優化。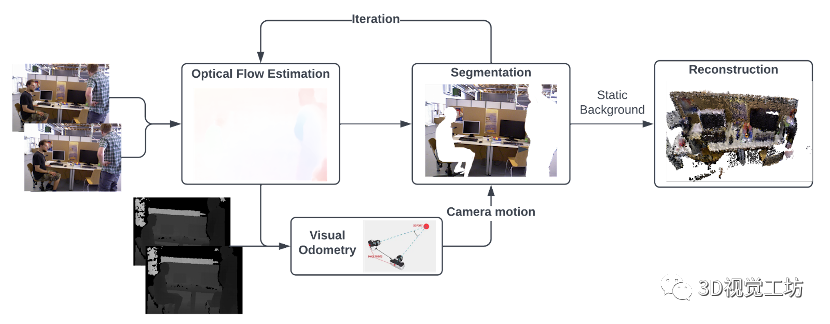
5. DytanVO
DytanVO算是目前最前沿的成果了,論文名“DytanVO: Joint Refinement of Visual Odometry and Motion Segmentation in Dynamic Environments”,同樣是卡內基梅隆大學王雯珊團隊的工作,該論文已經提交到2023 ICRA。 DytanVO的整個網絡架構還是基于TartanVO進行優化的。
DytanVO由從兩幅連續圖像中估計光流的匹配網絡、基于無動態運動的光流估計位姿的位姿網絡和輸出動態概率掩碼的運動分割網絡組成。
匹配網絡僅向前傳播一次,而位姿網絡和分割網絡被迭代以聯合優化位姿估計和運動分割。停止迭代的標準很簡單,即兩個迭代之間旋轉和平移差異小于閾值,并且閾值不固定,而是預先確定一個衰減參數,隨著時間的推移,經驗地降低輸入閾值,以防止在早期迭代中出現不準確的掩碼,而在后期迭代中使用改進的掩碼。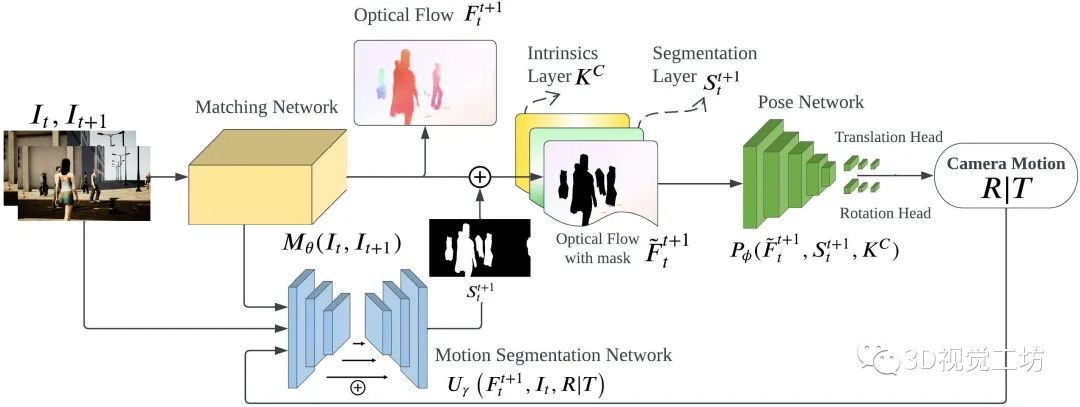
下圖所示是DytanVO的運行示例,包含兩個輸入的圖像幀、估計的光流、運動分割以及在高動態AirDOS-Shibuya數據集上的軌跡評估結果。結果顯示DytanVO精度超越TartanVO達到了最高,并且漂移量很小。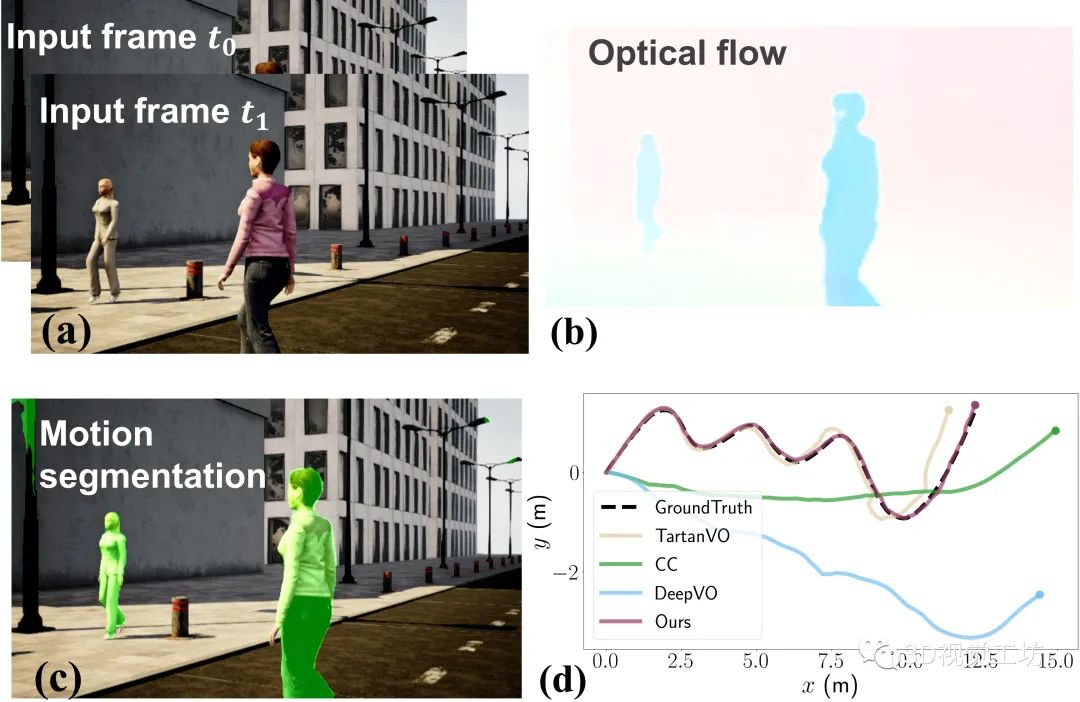
下表是在AirDOS-Shibuya的七個序列上,DytanVO與現有最先進的VO算法進行的定量對比結果。
七個序列分為三個難度等級:大多數人站著不動,很少人在路上走來走去,穿越(容易)包含多個人類進出相機的視野,而在穿越道路(困難)中,人類突然進入相機的視野。
除了VO方法之外,作者還將DytanVO與能夠處理動態場景的SLAM方法進行了比較,包括DROID-SLAM、AirDOS、VDO-SLAM以及DynaSLAM。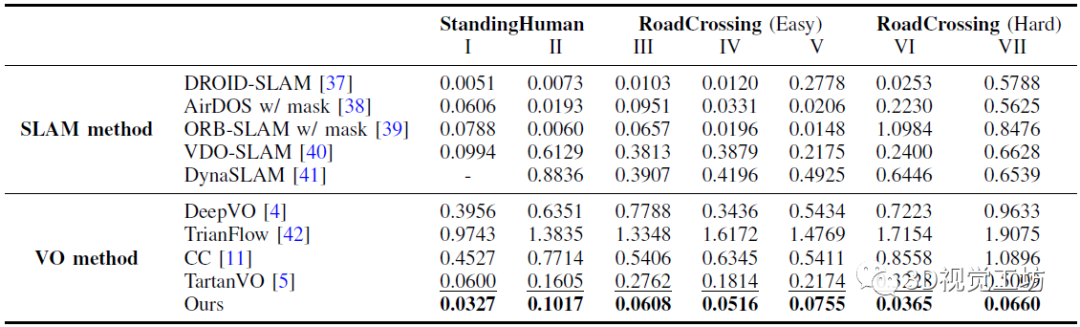
6. 總結
深度學習已經廣泛應用到了各個領域,但在SLAM領域卻沒有取得很好的效果。本文深入探討了為什么基于學習的VO效果不如傳統的SLAM算法,并介紹了三種基于學習的VO的算法原理。
總之,深度學習與SLAM結合是一個大趨勢,現階段無論是基于學習的VO還是傳統SLAM算法都有各自的問題,但兩者結合就可以解決很多困難。
審核編輯:劉清
-
ESP
+關注
關注
0文章
184瀏覽量
34010 -
VSLAM算法
+關注
關注
0文章
5瀏覽量
2248
原文標題:基于學習的VO距離傳統VSLAM還有多遠?
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
大聯大世平集團推出基于Intel技術的雙目VSLAM空間定位解決方案
詮視科技的VSLAM技術突破 看看CEO林瓊如何詮釋
通過持續元學習解決傳統機器學習方式的致命不足
VSLAM系統方法的各種特點
研討會預告 | 在 Jetson 上使用 vSLAM 進行 ROS 2 精準定位
VC-VO異質顆粒的相演化促進鋰硫電池中硫轉化反應
一文梳理缺陷檢測的深度學習和傳統方法
基于事件相機的vSLAM研究進展

基于事件相機的vSLAM研究進展

深度學習與傳統機器學習的對比
傳統機器學習方法和應用指導






 工商網監
工商網監
評論