 【AI簡報20221014】2022中國AI芯片企業50強、大眾與地平線成立合資企業
【AI簡報20221014】2022中國AI芯片企業50強、大眾與地平線成立合資企業
嵌入式 AI
AI 簡報 20221014 期
1. 2022中國AI芯片企業50強
原文:
https://app.myzaker.com/news/article.php?pk=63476be18e9f0903ac797c80
(全球 TMT2022 年 10 月 13 日訊)GTIC 2022 全球 AI 芯片峰會日前在深圳市南山區舉行,2022 中國 AI 芯片企業 50 強榜單揭曉。本次榜單基于核心技術實力、團隊建制情況、市場前景空間、商用落地進展、最新融資進度、國產替代價值六大維度進行綜合評分判定,按照分值遴選出當下在 AI 芯片領域擁有突出成就和創新潛力的 50 家中國企業名單。
2022 中國 AI 芯片企業 50 強(排名不分先后,按公司名稱首字母排序):
愛芯元智半導體 ( 上海 ) 有限公司
北京玻色量子科技有限公司
北京地平線信息技術有限公司
北京嘉楠捷思信息技術有限公司
北京君正集成電路股份有限公司
北京靈汐科技有限公司
北京蘋芯科技有限公司
北京清微智能科技有限公司
北京算能科技有限公司
北京探境科技有限公司
北京知存科技有限公司
成都啟英泰倫科技有限公司
成都時識科技有限公司
光子算數 ( 北京 ) 科技有限責任公司
瀚博半導體 ( 上海 ) 有限公司
杭州國芯科技股份有限公司
杭州智芯科微電子科技有限公司
黑芝麻智能科技有限公司
昆侖芯 ( 北京 ) 科技有限公司
墨芯人工智能科技 ( 深圳 ) 有限公司
沐曦集成電路 ( 上海 ) 有限公司
南京后摩智能科技有限公司
南京芯馳半導體科技有限公司
平頭哥半導體有限公司
千芯科技 ( 北京 ) 有限公司
瑞芯微電子股份有限公司
睿思芯科 ( 深圳 ) 技術有限公司
上海埃瓦智能科技有限公司
上海壁仞智能科技有限公司
上海登臨科技有限公司
上海酷芯微電子有限公司
上海齊感電子信息科技有限公司
上海燧原科技有限公司
上海天數智芯半導體有限公司
上海曦智科技有限公司
上海依圖網絡科技有限公司
上海億鑄智能科技有限公司
上海肇觀電子科技有限公司
深圳鯤云信息科技有限公司
深圳市海思半導體有限公司
深圳市九天睿芯科技有限公司
深圳云天勵飛技術股份有限公司
時擎智能科技 ( 上海 ) 有限公司
思必馳科技股份有限公司
銀牛微電子 ( 無錫 ) 有限責任公司
中科寒武紀科技股份有限公司
中科融合感知智能研究院 ( 蘇州工業園區 ) 有限公司
珠海歐比特宇航科技股份有限公司
珠海億智電子科技有限公司

2. 牽手地平線補齊短板,大眾汽車投資24億歐元發力智能駕駛
原文:
https://view.inews.qq.com/a/20221014A00Q4500?tbkt=D&uid=&refer=wx_hot
10月13日,大眾汽車集團宣布旗下軟件公司CARIAD將與地平線成立合資企業,并持有合資企業60%股份。據悉,大眾汽車計劃為本次合作投資約24億歐元(折合人民幣約168億元),該交易預計在明年上半年完成。
此次,CARIAD牽手地平線,主要將發力智能駕駛,開發領先的、高度優化的全棧式高級駕駛輔助系統和自動駕駛解決方案,在單顆芯片上集成多種功能,提高系統穩定性并節約成本降低能耗。

一直以來,合資品牌電動車在智能座艙、智能駕駛上與造車新勢力們有一定的差價,大眾汽車這次牽手地平線,無疑將補上了短板。并且以合資的方式進行合作,而不僅僅將地平線定義為供應商,無疑將加速推進大眾旗下車型的智能化升級。向科技公司轉型的路上,大眾汽車又邁出了堅實的一步。
3. 以太坊合并后:英偉達受難,“礦工”暴富夢終結
原文:
https://36kr.com/p/1931939259730306
在全世界的注視下,世界第二大虛擬貨幣以太坊(ETH)本月正式從PoW轉為PoS機制,完成了業界革命的“The Merge”合并升級。
以太坊合并完成之前,大量持有以太坊的投資者就已經開始拋售,以太坊單幣價格一路走低,從本周的高點1777美元,到合并時的1650美元左右,最終下跌至當前的1333美元,順便還把老對手比特幣也拖下水,目前比特幣再次跌破19000美元關口。
這是區塊鏈誕生以來,史無前例的一次升級,直接將之前的玩法全部推翻,宣告了曾經利用GPU(顯卡)挖礦時代的全面終結,近1億幣圈玩家被影響。大量專職挖礦的礦工們,要開始考慮未來的何去何從。
從2008年開始的挖礦暴富夢,進入了落幕倒計時。
這次以太坊升級轉型的PoS機制,是完全不同運算邏輯, 簡單來說就是不再依賴于顯卡, 而是憑借“幣齡”和持有貨幣的數量來充當“算力”,從而杜絕能源高消耗的情況。
這樣一來,影響最大的就是礦工們手頭里囤積的顯卡。
顯卡作為挖礦的第一生產力工具,價格也在狂熱的挖礦浪潮中一度瘋漲。2021年底,英偉達發布RTX 30系顯卡,原本是游戲玩家剛需的顯卡設備,還沒等玩家下單,礦工們就開始溢價瘋搶,把市面上的RTX 30系顯卡全部買下,再無一例外地投入到挖礦行列當中。
原本定位中端的RTX 3060Ti顯卡,官方定價2999元,在最高峰時價格暴漲近乎破萬,其它高端卡更不用說了,都是溢價三倍起步。最新的顯卡買不到,礦工又盯上了“過時”的設備,上一代的RTX 20系顯卡都迎來不同程度的瘋漲。
甚至一些使用兩三年的RTX 10系顯卡,都能在二手市場以原價賣出,可見挖礦浪潮對顯卡的影響。
4. 1500美元,小扎推出天價頭顯Quest Pro,還給虛擬化身加上了腿
原文:
https://mp.weixin.qq.com/s/qDwVdgPJCkArDOL4azvX1A
今日,Meta Connect 大會在線上舉行。Meta CEO 馬克 · 扎克伯格推出了一款全新的 Quest Pro 虛擬和混合現實頭顯設備,標志著 Meta 進入了擴展現實計算設備的高端市場。
在演講中,扎克伯格部分以真人、部分以虛擬化身出現,他表示,「我希望物理世界和數字世界的融合能夠為計算帶來更多新的用途。」

在技術上,Meta Quest Pro 對現有 Quest 2 頭顯設備進行了全方位升級。
首先,Quest Pro 采用了全新的薄餅(Pancake)透鏡,光學堆棧比 Quest 2 縮減 40%,視覺中心解析度每英寸像素提升 35%。設備瞳孔間距的調節范圍為 55-75 毫米,為用戶提供了更好的視覺體驗并降低眼疲勞。

其次,Quest Pro 在硬件上采用了與高通聯合設計并專為 VR 優化的驍龍 XR2 + 芯片,更好的散熱系統使得續航提升了 50%,也大幅提升了性能。此外,Quest Pro 還附帶 10 個先進的 VR/MR 傳感器、空間音頻、256GB 內存和 12GB RAM。
最后,Quest Pro 配備了重新設計的控制手柄,各自搭載一顆驍龍 662 處理器和三個攝像頭。新的傳感器使得不用頭顯也能在 3D 空間中追蹤位置,用戶可以享受 360 度全方位運動范圍。新的 Trutouch Haptics 為用戶提供了更寬和更精準的反饋效果范圍。
5. 訓練速度提高最多5.4倍,谷歌提出RL訓練新范式ActorQ
原文:
https://mp.weixin.qq.com/s/MyUW7CELJOckFjmYNkQxuA
文章鏈接:
https://ai.googleblog.com/2022/09/quantization-for-fast-and.html
此前,由谷歌大腦團隊科學家 Aleksandra Faust 和研究員 Srivatsan Krishnan 發布的深度強化學習模型在解決導航、核物理、機器人和游戲等現實世界的順序決策問題方面取得巨大進步。它很有應用前景,但缺點之一是訓練時間過長。
雖然可以使用分布式計算加快復雜困難任務的強化學習的訓練,但是需要數百甚至數千個計算節點,且要使用大量硬件資源,這使得強化學習訓練成本變得極其高昂,同時還要考慮對環境的影響。最近的研究表明,對現有硬件進行性能優化可以減少模型訓練的碳足跡(即溫室氣體排放總量)。
借助系統優化,可以縮短強化學習訓練時間、提高硬件利用率、減少二氧化碳(CO2)排放。其中一種技術是量化,將全精度浮點(FP32)數轉換為低精度(int8)數,然后使用低精度數字進行計算。量化可以節省內存成本和帶寬,實現更快、更節能的計算。量化已成功應用于監督學習,以實現機器學習(ML)模型的邊緣部署并實現更快的訓練。同樣也可以將量化應用于強化學習訓練。
近日,谷歌的研究者在《Transactions of Machine Learning Research》期刊上發表了《QuaRL:快速和環境可持續強化學習的量化》,介紹了一種稱為「ActorQ」的新范式。該范式使用了量化,在保持性能的同時,將強化學習訓練速度提高 1.5-5.4 倍。作者證明,與全精度訓練相比,碳足跡也減少了 1.9-3.8 倍。
量化應用于強化學習訓練
在傳統的強化學習訓練中,learner 策略會應用于 actor,actor 使用該策略探索環境并收集數據樣本,actor 收集的樣本隨后被 learner 用于不斷完善初始策略。定期地,針對 learner 的訓練策略被用來更新 actor 的策略。為了將量化應用于強化學習訓練,作者開創了 ActorQ 范式。ActorQ 執行上面描述的相同序列,其中關鍵區別是,從 learner 到 actor 的策略更新是量化的,actor 使用 int8 量化策略探索環境以收集樣本。
以這種方式將量化應用于強化學習訓練有兩個關鍵好處。首先,它減少了策略的內存占用。對于相同的峰值帶寬,learner 和 actor 之間傳輸的數據較少,這降低了 actor 與 learner 之間的策略更新通信成本。其次,actor 對量化策略進行推理,以生成給定環境狀態的操作。與完全精確地執行推理相比,量化推理過程要快得多。
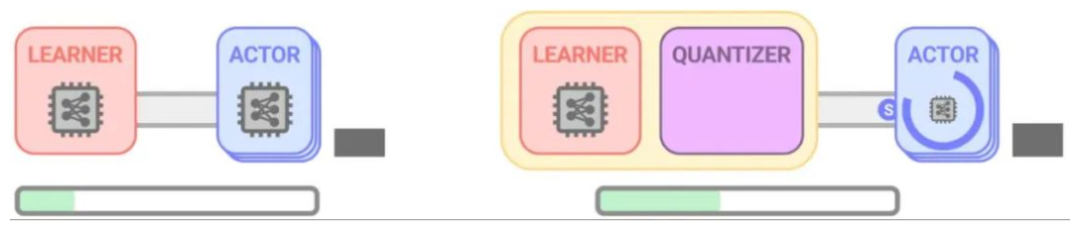
以量化提升強化學習訓練效率
作者在實驗中觀察到訓練強化學習策略的速度顯著加快(1.5 倍至 5.41 倍之間)。更重要的是,即使 actor 進行了基于 int8 的量化推理,也可以保持性能。下圖顯示了用于 Deepmind Control Suite 和 OpenAI Gym 任務的 D4PG 和 DQN 智能體的這一點。
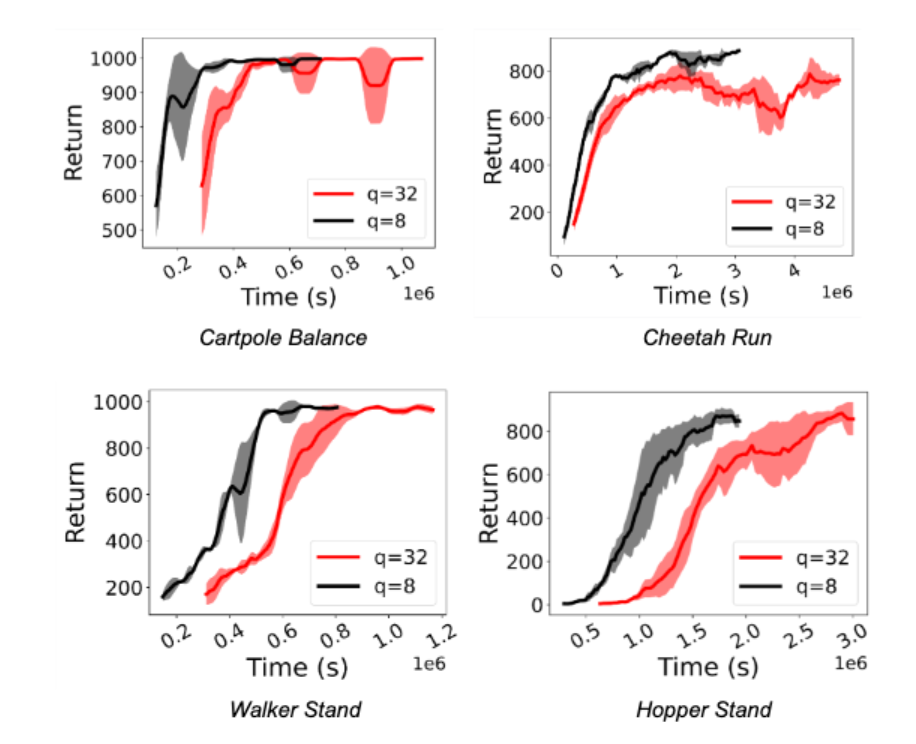
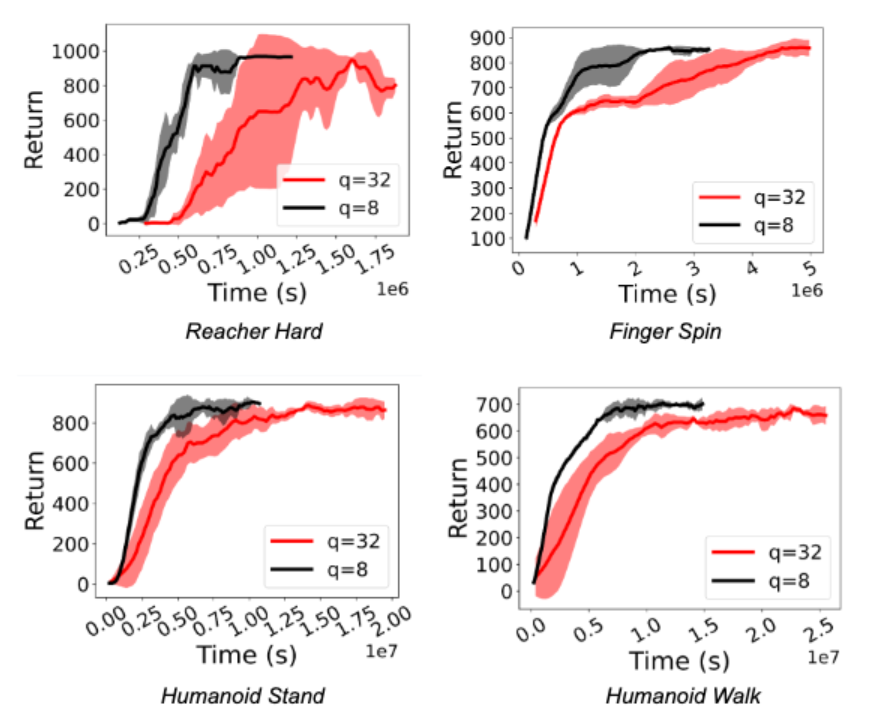
結論和未來方向
作者引入了 ActorQ,這是一種新的范式,將量化應用于強化學習訓練,并在保持性能的同時實現了 1.5-5.4 倍的加速改進。與未應用量化的全精度訓練相比,ActorQ 可以將強化學習訓練的碳足跡減少 1.9-3.8 倍。
ActorQ 證明量化可以有效地應用于強化學習的許多方面,從獲得高質量和高效的量化策略到減少訓練時間和碳排放。隨著強化學習在解決現實問題方面繼續取得長足進步,我們有理由相信,使強化學習訓練實現可持續發展將是關鍵。當將強化學習擴展到數千個 CPU 和 GPU 時,即使 50% 的改進也會在成本、能源和碳排放方面顯著降低。作者的工作是將量化應用于強化學習訓練以實現高效和環境可持續訓練的第一步。
作者在 ActorQ 中的量化設計基于簡單的均勻量化,但實際可以應用其他形式的量化、壓縮和稀疏性(如蒸餾、稀疏化等)。未來的工作將考慮應用更積極的量化和壓縮方法,這可能會為強化學習在訓練性能和精度的權衡上帶來更多的好處。
6. 我傻眼了:一個完全由 AI 生成的播客,采訪了喬布斯
原文:
https://mp.weixin.qq.com/s/rc9AdGFige75ylfehfs-fQ
最近大火的生成式 AI 又有新動作了!
在 podcast.ai 推出的第一集播客節目里,已故的喬布斯竟然“死而復生”成為首位嘉賓,與美國知名播客主持人 Joe Rogan 進行了一場長達20分鐘的對話,討論了關于喬布斯的大學、對計算機的看法、工作狀態以及信仰等等。
是不是聽起來有些毛骨悚然?事實上,這段采訪是由文本生成音頻實現的,屬于 AIGC 中的一個分支。
podcast.ai 是一個完全由 AI 生成的播客,每周都會深入探討一個新話題。在第一期節目中,podcast.ai 通過喬布斯的傳記和收集網絡上關于他的所有錄音,用 Play.ht 的語言模型大量訓練,最終生成了這段假 Joe Rogan 采訪喬布斯的播客內容。
此次 podcast.ai 推出的AI播客,是生成式AI在語音領域的一次新探索。從前段時間全網刷屏的 Stable Diffusion,后有國內平臺掀起AI創作熱,各類生成式AI模型給人們生活帶來了更多的可能性。
Play.ht 表示,“我們相信在未來,所有內容創作都將由人工智能生成,但由人類指導,而最具創造性的工作將取決于人類將他們想要的創作表達到模型中的能力。”
7. Soft Diffusion:谷歌新框架從通用擴散過程中正確調度、學習和采樣
原文:
https://mp.weixin.qq.com/s/Ke_vp6SWxWuygSNTFaO_bg
論文地址:
https://arxiv.org/pdf/2209.05442.pdf
我們知道,基于分數的模型和去噪擴散概率模型(DDPM)是兩類強大的生成模型,它們通過反轉擴散過程來產生樣本。這兩類模型已經在 Yang Song 等研究者的論文《Score-based generative modeling through stochastic differential equations》中統一到了單一的框架下,并被廣泛地稱為擴散模型。
目前,擴散模型在包括圖像、音頻、視頻生成以及解決逆問題等一系列應用中取得了巨大的成功。Tero Karras 等研究者在論文《Elucidating the design space of diffusionbased generative models》中對擴散模型的設計空間進行了分析,并確定了 3 個階段,分別為 i) 選擇噪聲水平的調度,ii) 選擇網絡參數化(每個參數化生成一個不同的損失函數),iii) 設計采樣算法。
近日,在谷歌研究院和 UT-Austin 合作的一篇 arXiv 論文《Soft Diffusion: Score Matching for General Corruptions》中,幾位研究者認為擴散模型仍有一個重要的步驟:損壞(corrupt)。一般來說,損壞是一個添加不同幅度噪聲的過程,對于 DDMP 還需要重縮放。雖然有人嘗試使用不同的分布來進行擴散,但仍缺乏一個通用的框架。因此,研究者提出了一個用于更通用損壞過程的擴散模型設計框架。
具體地,他們提出了一個名為 Soft Score Matching 的新訓練目標和一種新穎的采樣方法 Momentum Sampler。理論結果表明,對于滿足正則條件的損壞過程,Soft Score MatchIng 能夠學習它們的分數(即似然梯度),擴散必須將任何圖像轉換為具有非零似然的任何圖像。
在實驗部分,研究者在 CelebA 以及 CIFAR-10 上訓練模型,其中在 CelebA 上訓練的模型實現了線性擴散模型的 SOTA FID 分數——1.85。同時與使用原版高斯去噪擴散訓練的模型相比,研究者訓練的模型速度顯著更快。

通常來說,擴散模型通過反轉逐漸增加噪聲的損壞過程來生成圖像。研究者展示了如何學習對涉及線性確定性退化和隨機加性噪聲的擴散進行反轉。

具體地,研究者展示了使用更通用損壞模型訓練擴散模型的框架,包含有三個部分,分別為新的訓練目標 Soft Score Matching、新穎采樣方法 Momentum Sampler 和損壞機制的調度。
首先來看訓練目標 Soft Score Matching,這個名字的靈感來自于軟過濾,是一種攝影術語,指的是去除精細細節的過濾器。它以一種可證明的方式學習常規線性損壞過程的分數,還在網絡中合并入了過濾過程,并訓練模型來預測損壞后與擴散觀察相匹配的圖像。
只要擴散將非零概率指定為任何干凈、損壞的圖像對,則該訓練目標可以證明學習到了分數。另外,當損壞中存在加性噪聲時,這一條件總是可以得到滿足。
在過程中,研究者發現噪聲在實證(即更好的結果)和理論(即為了學習分數)這兩方面都很重要。這也成為了其與反轉確定性損壞的并發工作 Cold Diffusion 的關鍵區別。
其次是采樣方法 Momentum Sampling。研究者證明,采樣器的選擇對生成樣本質量具有顯著影響。他們提出了 Momentum Sampler,用于反轉通用線性損壞過程。該采樣器使用了不同擴散水平的損壞的凸組合,并受到了優化中動量方法的啟發。
這一采樣方法受到了上文 Yang Song 等人論文提出的擴散模型連續公式化的啟發。Momentum Sampler 的算法如下所示。

最后是調度。即使退化的類型是預定義的(如模糊),決定在每個擴散步驟中損壞多少并非易事。研究者提出一個原則性工具來指導損壞過程的設計。為了找到調度,他們將沿路徑分布之間的 Wasserstein 距離最小化。直觀地講,研究者希望從完全損壞的分布平穩過渡到干凈的分布。
8. 采樣提速256倍,蒸餾擴散模型生成圖像質量媲美教師模型,只需4步
原文:
https://mp.weixin.qq.com/s/ZpwlJbpQgvDqlmBX67phLw
論文地址:
https://arxiv.org/pdf/2210.03142.pdf
去噪擴散概率模型(DDPM)在圖像生成、音頻合成、分子生成和似然估計領域都已經實現了 SOTA 性能。同時無分類器(classifier-free)指導進一步提升了擴散模型的樣本質量,并已被廣泛應用在包括 GLIDE、DALL·E 2 和 Imagen 在內的大規模擴散模型框架中。
然而,無分類器指導的一大關鍵局限是它的采樣效率低下,需要對兩個擴散模型評估數百次才能生成一個樣本。這一局限阻礙了無分類指導模型在真實世界設置中的應用。盡管已經針對擴散模型提出了蒸餾方法,但目前這些方法不適用無分類器指導擴散模型。
為了解決這一問題,近日斯坦福大學和谷歌大腦的研究者在論文《On Distillation of Guided Diffusion Models》中提出使用兩步蒸餾(two-step distillation)方法來提升無分類器指導的采樣效率。
在第一步中,他們引入單一學生模型來匹配兩個教師擴散模型的組合輸出;在第二步中,他們利用提出的方法逐漸地將從第一步學得的模型蒸餾為更少步驟的模型。
利用提出的方法,單個蒸餾模型能夠處理各種不同的指導強度,從而高效地對樣本質量和多樣性進行權衡。此外為了從他們的模型中采樣,研究者考慮了文獻中已有的確定性采樣器,并進一步提出了隨機采樣過程。

研究者在 ImageNet 64x64 和 CIFAR-10 上進行了實驗,結果表明提出的蒸餾模型只需 4 步就能生成在視覺上與教師模型媲美的樣本,并且在更廣泛的指導強度上只需 8 到 16 步就能實現與教師模型媲美的 FID/IS 分數,具體如下圖 1 所示。

此外,在 ImageNet 64x64 上的其他實驗結果也表明了,研究者提出的框架在風格遷移應用中也表現良好。
9. Batch Normalization和它的“后浪”們匯總
原文:
https://mp.weixin.qq.com/s/DOqUWpoCIOE4RbH88vpgfg
歸一化相關技術已經經過了幾年的發展,目前針對不同的應用場合有相應的方法,在本文將這些方法做了一個總結,介紹了它們的思路,方法,應用場景。主要涉及到:LRN,BN,LN, IN, GN, FRN, WN, BRN, CBN, CmBN等。
本文又名“BN和它的后浪們”,是因為幾乎在BN后出現的所有歸一化方法都是針對BN的三個缺陷改進而來,在本文也介紹了BN的三個缺陷。相信讀者會讀完此文會對歸一化方法有個較為全面的認識和理解。
LRN(2012)
局部響應歸一化(Local Response Normalization, 即LRN)首次提出于AlexNet。自BN提出后,其基本被拋棄了,因此這里只介紹它的來源和主要思想。
LRN的創意來源于神經生物學的側抑制,被激活的神經元會抑制相鄰的神經元。用一句話來形容LRN:讓響應值大的feature map變得更大,讓響應值小的變得更小。
其主要思想在于讓不同卷積核產生feature map之間的相關性更小,以實現不同通道上的feature map專注于不同的特征的作用,例如A特征在一通道上更顯著,B特征在另一通道上更顯著。
Batch Normalization(2015)
論文:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
論文中關于BN提出的解釋:訓練深度神經網絡非常復雜,因為在訓練過程中,隨著先前各層的參數發生變化,各層輸入的分布也會發生變化,圖層輸入分布的變化帶來了一個問題,因為圖層需要不斷適應新的分布,因此訓練變得復雜,隨著網絡變得更深,網絡參數的細微變化也會放大。
由于要求較低的學習率和仔細的參數初始化,這減慢了訓練速度,并且眾所周知,訓練具有飽和非線性的模型非常困難。我們將此現象稱為內部協變量偏移,并通過歸一化層輸入來解決該問題。
其它的解釋:假設輸入數據包含多個特征x1,x2,…xn。每個功能可能具有不同的值范圍。例如,特征x1的值可能在1到5之間,而特征x2的值可能在1000到99999之間。
如下左圖所示,由于兩個數據不在同一范圍,但它們是使用相同的學習率,導致梯度下降軌跡沿一維來回振蕩,從而需要更多的步驟才能達到最小值。且此時學習率不容易設置,學習率過大則對于范圍小的數據來說來回震蕩,學習率過小則對范圍大的數據來說基本沒什么變化。
如下右圖所示,當進行歸一化后,特征都在同一個大小范圍,則loss landscape像一個碗,學習率更容易設置,且梯度下降比較平穩。
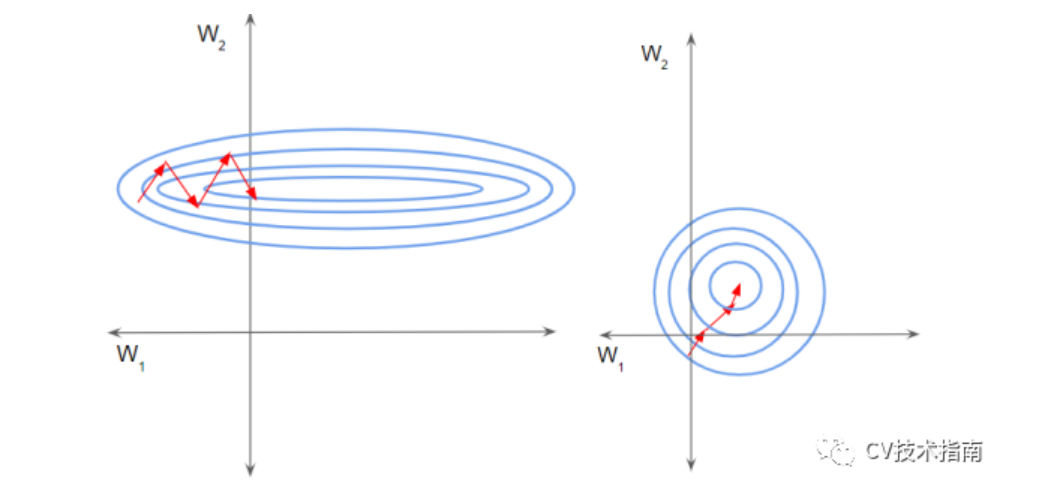
實現算法:

在一個batch中,在每一BN層中,對每個樣本的同一通道,計算它們的均值和方差,再對數據進行歸一化,歸一化的值具有零均值和單位方差的特點,最后使用兩個可學習參數gamma和beta對歸一化的數據進行縮放和移位。
此外,在訓練過程中還保存了每個mini-batch每一BN層的均值和方差,最后求所有mini-batch均值和方差的期望值,以此來作為推理過程中該BN層的均值和方差。
注:BN放在激活函數后比放在激活函數前效果更好。
實際效果:1)與沒有BN相比,可使用更大的學習率2)防止過擬合,可去除Dropout和Local Response Normalization3)由于dataloader打亂順序,因此每個epoch中mini-batch都不一樣,對不同mini-batch做歸一化可以起到數據增強的效果。4)明顯加快收斂速度5)避免梯度爆炸和梯度消失
注:BN存在一些問題,后續的大部分歸一化論文,都是在圍繞BN的這些缺陷來改進的。為了行文的方便,這些缺陷會在后面各篇論文中逐一提到。
BN、LN、IN和GN的區別與聯系
下圖比較明顯地表示出了它們之間的區別。(N表示N個樣本,C表示通道,這里為了表達方便,把HxW的二維用H*W的一維表示。)
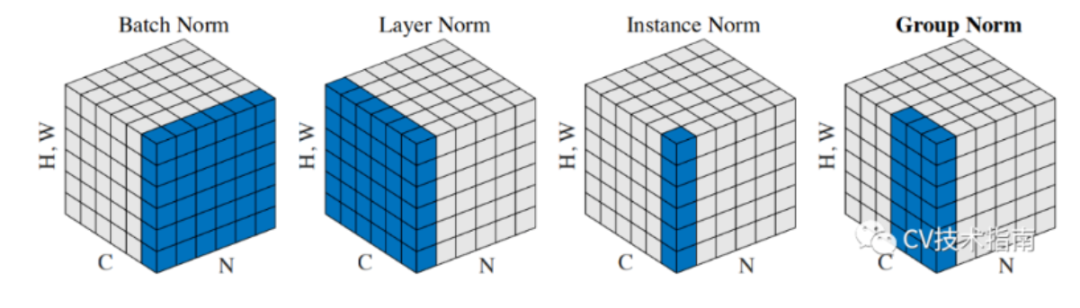
后面這三個解決的主要問題是BN的效果依賴于batch size,當batch size比較小時,性能退化嚴重。可以看到,IN,LN和GN都與batch size無關。
它們之間的區別在于計算均值和方差的數據范圍不同,LN計算單個樣本在所有通道上的均值和方差,IN值計算單個樣本在每個通道上的均值和方差,GN將每個樣本的通道分成g組,計算每組的均值和方差。
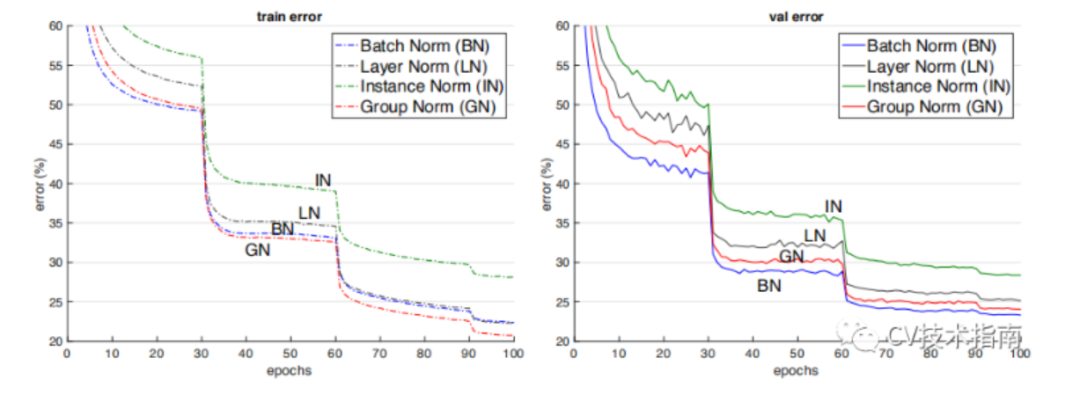
它們之間的效果對比。(注:這個效果是只在同一場合下的對比,實際上它們各有自己的應用場景,且后三者在各自的應用場合上都明顯超過了BN)
Instance Normalization(2016)
論文:Instance Normalization: The Missing Ingredient for Fast Stylization
在圖像視頻等識別任務上,BN的效果是要優于IN的。但在GAN,style transfer和domain adaptation這類生成任務上,IN的效果明顯比BN更好。
從BN與IN的區別來分析產生這種現象的原因:BN對多個樣本統計均值和方差,而這多個樣本的domain很可能是不一樣的,相當于模型把不同domain的數據分布進行了歸一化。
Layer Normalization (2016)
論文:Layer Normalization
BN的第一個缺陷是依賴Batch size,第二個缺陷是對于RNN這樣的動態網絡效果不明顯,且當推理序列長度超過訓練的所有序列長度時,容易出問題。為此,提出了Layer Normalization。
當我們以明顯的方式將批歸一化應用于RNN時,我們需要為序列中的每個時間步計算并存儲單獨的統計信息。如果測試序列比任何訓練序列都長,這是有問題的。LN沒有這樣的問題,因為它的歸一化項僅取決于當前時間步長對層的總輸入。它還只有一組在所有時間步中共享的增益和偏置參數。(注:LN中的增益和偏置就相當于BN中的gamma 和beta)
LN的應用場合:RNN,transformer等。
Group Normalization(2018)
論文:Group Normalization
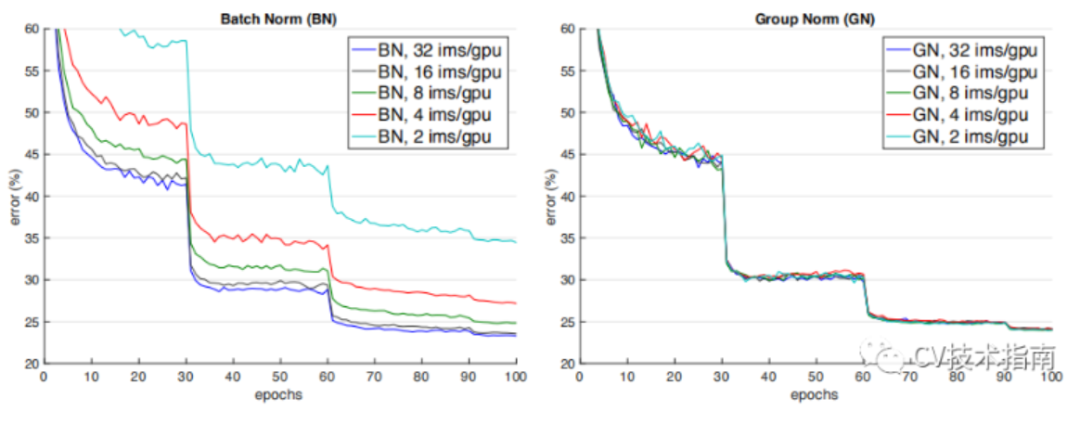
如下圖所示,當batch size減少時,BN退化明顯,而Group Normalization始終一致,在batch size比較大的時候,略低于BN,但當batch size比較小的時候,明顯優于BN。
但GN有兩個缺陷,其中一個是在batchsize大時略低于BN,另一個是由于它是在通道上分組,因此它要求通道數是分組數g的倍數。
GN應用場景:在目標檢測,語義分割等要求盡可能大的分辨率的任務上,由于內存限制,為了更大的分辨率只能取比較小的batch size,可以選擇GN這種不依賴于batchsize的歸一化方法。
GN實現算法

Weights Normalization(2016)
論文:Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks
前面的方法都是基于feature map做歸一化,這篇論文提出對Weights做歸一化。
解釋這個方法要費挺多筆墨,這里用一句話來解釋其主要做法:將權重向量w分解為一個標量g和一個向量v,標量g表示權重向量w的長度,向量v表示權重向量的方向。
這種方式改善了優化問題的條件,并加速了隨機梯度下降的收斂,不依賴于batch size的特點,適用于循環模型(如 LSTM)和噪聲敏感應用(如深度強化學習或生成模型),而批量歸一化不太適合這些應用。
Weight Normalization也有個明顯的缺陷:WN不像BN有歸一化特征尺度的作用,因此WN的初始化需要慎重,為此作者提出了對向量v和標量g的初始化方法。
Batch Renormalization(2017)
Cross-GPU BN(2018)
FRN(2019)
Cross-Iteration BN(2020)
總結
本文介紹了目前比較經典的歸一化方法,其中大部分都是針對BN改進而來,本文比較詳盡地介紹了它們的主要思想,改進方式,以及應用場景,部分方法并沒有詳細介紹實現細節,對于感興趣或有需要的讀者請自行閱讀論文原文。
除了以上方法外,還有很多歸一化方法,例如Eval Norm,Normalization propagation,Normalizing the normalizers等。但這些方法并不常用,這里不作贅述。
- END -

-
RT-Thread
+關注
關注
31文章
1289瀏覽量
40135
原文標題:【AI簡報20221014】2022中國AI芯片企業50強、大眾與地平線成立合資企業
文章出處:【微信號:RTThread,微信公眾號:RTThread物聯網操作系統】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
億鑄科技入選畢馬威中國“芯科技”新銳企業50強
知存科技榮獲2024中國AI算力層創新企業
地平線榮獲比亞迪“最佳合作伙伴獎”
智駕科技企業地平線登陸港交所
智駕科技企業地平線通過港交所聆訊 IPO進入倒計時

地平線港股IPO獲證監會備案
ADVANCE.AI 榮登甲子光年「星辰100:2024中國AI出海服務創新企業」榜單

云天勵飛入選2024中國AI基礎大模型創新企業

智能駕駛企業地平線赴港IPO
智能駕駛頭部企業地平線赴港IPO
智能駕駛領軍企業地平線遞表港交所
集賢科技榮登中國物聯網企業投資價值50強!






 工商網監
工商網監
評論