") 【AI簡報20221021期】英特爾i9-13900K重奪PC性能桂冠、RISC-V可靠矢量處理彎道超車
【AI簡報20221021期】英特爾i9-13900K重奪PC性能桂冠、RISC-V可靠矢量處理彎道超車
嵌入式 AI
AI 簡報 20221021 期
1. 英特爾i9-13900K重奪PC性能桂冠:與AMD 7950X拉開8%差距
原文:
https://app.myzaker.com/news/article.php?pk=63476be18e9f0903ac797c80
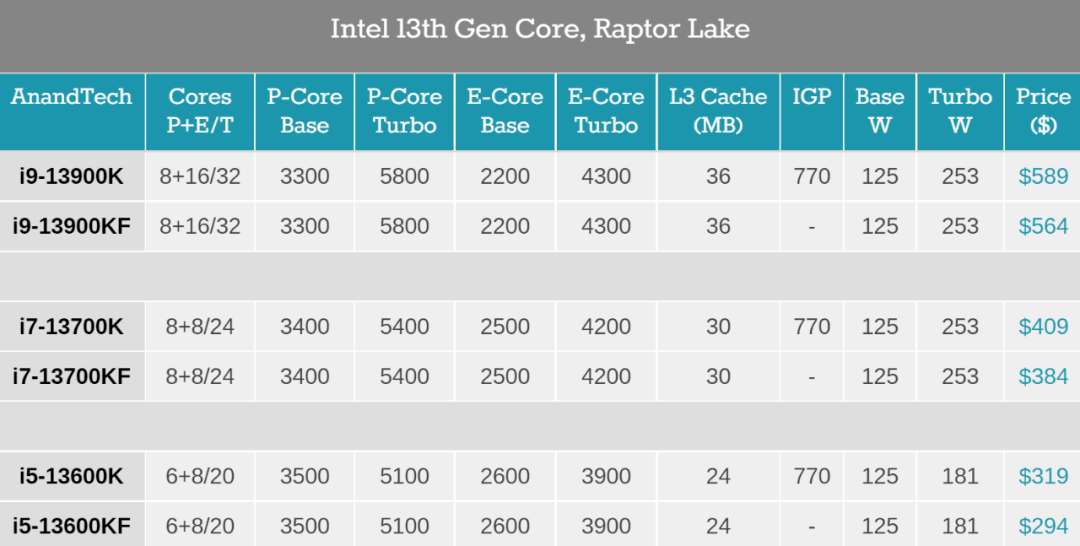
10 月 20 日晚上,英特爾正式解禁了 13 代酷睿臺式機處理器的性能表現(xiàn),包括 Intel Core i9-13900K 和 i5-13600K。美國科技媒體 The Verge 對 i9-13900K 與 AMD Ryzen 9 7950X 進行了比較 ,發(fā)現(xiàn)雖然 AMD 的 Zen 4 架構(gòu) CPU 相較于英特爾 12 代酷睿的性能有所提升,但這次英特爾 13 代酷睿重新奪回了整體性能的桂冠。
先來看下英特爾酷睿 i9-13900K 的相關(guān)參數(shù),作為高端版本,它包括 24 個核心(8 個性能核和 16 個效能核)、32 個線程和高達 5.8GHz 的時鐘速度。
英特爾承諾,酷睿 i9-13900K 的單線程性能較 i9-12900K 提升了 15%,多線程性能提升了 41%。與此同時,它的售價也來到了 589 美元。
過去一周,The Verge 一直在測試酷睿 i9-13900K,它在很大程度上兌現(xiàn)了英特爾聲稱的性能,尤其是多線程性能大幅提升,真正加速了最繁重的工作負(fù)載效率。
具體地,The Verge 在英特爾酷睿 i9-13900K 和 AMD 銳龍 9 7950X 處理器上測試了各種工作負(fù)載、綜合基礎(chǔ)測試和游戲。所有的測試均在最新的 Windows 11 2022 Update 上運行,并關(guān)閉了安全性,啟用了 Resizable BAR,所有游戲都在 1080p 分辨率設(shè)置下運行。
2. 谷歌3D全息電話亭,顛覆現(xiàn)有視頻通話!宛如真人面對面
原文:
https://mp.weixin.qq.com/s/TMhMjFZbw96n4CUkVQ_z1w
在近日的Google Cloud Next 2022上,桑達爾·皮查伊表示,Starline 項目已經(jīng)在谷歌內(nèi)部進行了數(shù)千小時的測試,并在其美國辦公室每天使用,而100多個橫跨媒體、醫(yī)療和零售的企業(yè)合作伙伴已經(jīng)收到了演示。
谷歌還宣布Project Starline正在進入下一個測試階段,計劃是在選定的合作伙伴辦公室部署設(shè)備進行定期測試,谷歌提到的合作伙伴包括Salesforce、WeWork、T-Mobile和Hackensack Meridian Health,這些設(shè)備預(yù)計將在今年年底前完成安裝,開啟初試。
谷歌為什么花費大量時間開展Project Starline呢?根據(jù)項目組給出的答案,就是讓人在通話的時候,感覺你是和一個真正的人在一起。在如今的社會中,人們通常會相隔千里,尤其是近兩年疫情頻繁發(fā)生,人們不得不通過Zoom等遠程會議軟件,進行聯(lián)系、溝通工作。
然而當(dāng)下視頻會議給人的感覺并不好,根據(jù)微軟一份關(guān)于視頻會議對工作效率的影響的報告,人們在視頻會議中會比顯示溝通更容易分析,這是人們在面對高壓力的視頻會議下的自然應(yīng)對反應(yīng)。而谷歌認(rèn)為,能提供真人對話體驗的Project Starline,似乎能夠消除這種壓力感。
谷歌的研究員做了對比實驗,他們發(fā)現(xiàn)相比傳統(tǒng)視頻溝通,使用Project Starline溝通的參會者會有更多眼神接觸和肢體語言,在溝通結(jié)束后能夠回憶的內(nèi)容也要多出28%。
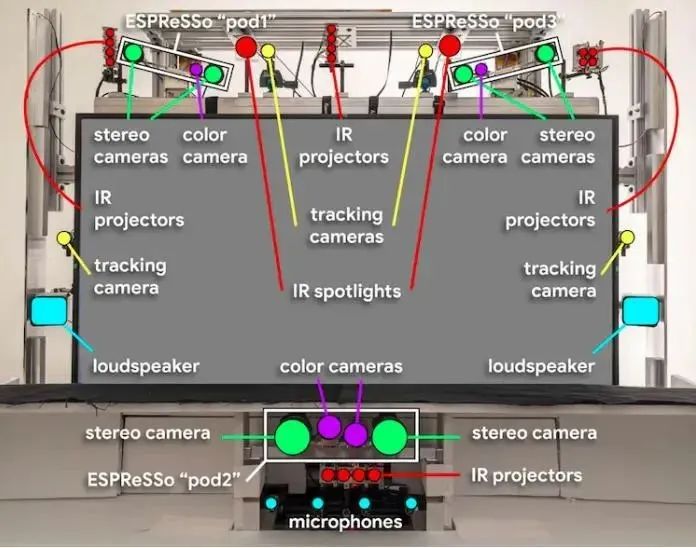
更為重要的是,裝配一套Project Starline,成本相當(dāng)高,光場顯示器和各種光學(xué)攝像頭都非常昂貴,這使得Project Starline短期內(nèi)只能停留在實驗室,而進入消費者市場的可能性很小。Project Starline的產(chǎn)品管理總監(jiān)Andrew Nartker稱,目前它還很難稱得上是一件產(chǎn)品。
整體而言,Project Starline是一個全新技術(shù)的探索,谷歌也會繼續(xù)對其進行優(yōu)化改進。未來,它能否成為一個真正的產(chǎn)品還未可知。不過無論怎樣,任何一項新技術(shù)的探索都值得被關(guān)注。
3. 通用計算仍有差距,RISC-V可靠矢量處理彎道超車
原文:
https://mp.weixin.qq.com/s/mM9Drv8r2QGSD7Hm8i8HWA
對于高效的數(shù)據(jù)并行負(fù)載處理來說,矢量架構(gòu)的吸引力越來越大,主流ISA都開始注意到這一點。就拿我們熟悉的前超算王者——日本的富岳來說,其處理器富士通A64FX就是基于Arm可伸縮矢量擴展(SVE)的。
Arm也在隨后推出的Armv9架構(gòu)中提出了改良版的SVE2,并在其中加入了對NEON的兼容,SVE2在HPC之外的市場應(yīng)用中做出了指令優(yōu)化,甚至可以用于手機、汽車等智能設(shè)備中。
正是因為有了SVE的存在,富岳才得以單靠通用處理器完成高性能的大數(shù)據(jù)運算,而不是像其他主流超算一樣,還要靠堆積GPU、FPGA和AI加速器等片外加速器才能實現(xiàn)可觀的性能,我國的神威太湖之光同樣運用了這樣的矢量設(shè)計思路。但以上這些都是專有架構(gòu),微架構(gòu)不透明的同時也限制了開源和定制化方案的出現(xiàn),而這些均可以在RISC-V上一一實現(xiàn)。
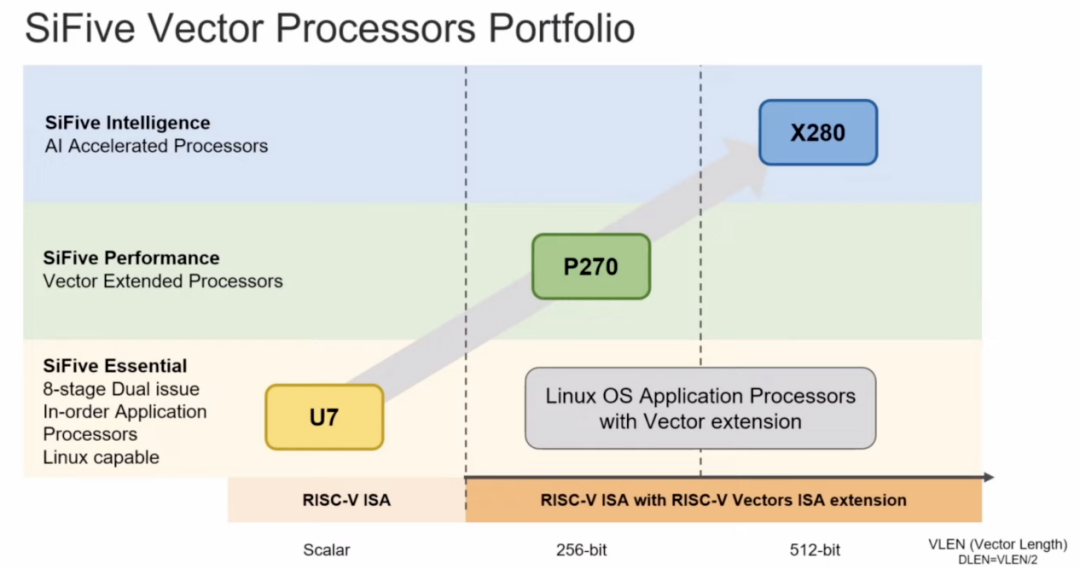
RISC-V的矢量擴展RVV自2015年提出以來,已經(jīng)有了長足的進展,也有了正式的1.0版本規(guī)范。與傳統(tǒng)的SIMD指令相比,RVV提供動態(tài)的矢量長度修改,做到了更高的效率、更小的代碼體積和更簡單的循環(huán)結(jié)束。我們近期已經(jīng)看到了不少RISC-V處理器被廣泛使用的新聞,比如谷歌選擇在其TPU上加入SiFive的X280處理器,其實看重的就是它在矢量處理上的優(yōu)勢。
所以我們看到在SiFive的處理器產(chǎn)品中,像Performance P270和Intelligence X280都擁有優(yōu)秀的矢量處理能力,后者更是引入了一個512位矢量寄存器長度的架構(gòu),在完全支持矢量擴展標(biāo)準(zhǔn)的同時,還支持動態(tài)可變矢量長度的運算。SiFive也在其矢量擴展上做出了改進,稱其為SiFive智能擴展,與直接基于RV64GCV架構(gòu)的設(shè)計相比,X280的智能擴展在INT8格式下的矩陣乘法運算時可將執(zhí)行速度提高12倍。
而且這不僅僅造福的是數(shù)據(jù)中心,還有受制于功耗卻又需要高吞吐量和單線程性能的邊緣應(yīng)用,比如AR/VR、數(shù)碼相機等等。SiFive同樣測試了可用于移動端或嵌入式設(shè)備的輕量級神經(jīng)網(wǎng)絡(luò)MobileNet,相較基于RISC-V標(biāo)量的架構(gòu),SiFive智能擴展可以將速度提升144倍。
AI時代下,矢量處理的應(yīng)用場景已經(jīng)遠超我們的現(xiàn)象,包括深度學(xué)習(xí)、推薦系統(tǒng)、鍵值存儲和HPC等,都已經(jīng)廣泛利用了矢量計算。但如何做到高效高性能,才是未來所有ISA的努力方向,而RISC-V作為后來者,反而能在這上面找到彎道超車的機會。
4. 移動端部署推薦系統(tǒng):快手獲數(shù)據(jù)挖掘頂會CIKM 2022最佳論文
原文:
https://mp.weixin.qq.com/s/x3dnkBF7BKDMEU_rt8QmDg
10 月 20 日,信息檢索和數(shù)據(jù)挖掘領(lǐng)域的頂級會議之一 CIKM 2022 公布論文獎項,快手社區(qū)科學(xué)團隊獲得了應(yīng)用研究方向「最佳論文獎」。

獲獎?wù)撐摹禦eal-time Short Video Recommendation on Mobile Devices》針對短視頻推薦場景,傳統(tǒng)服務(wù)端部署的推薦系統(tǒng)在決策時機和實時特征利用方面的不足問題,通過在移動客戶端部署推薦系統(tǒng)來實時響應(yīng)用戶反饋,提高推薦結(jié)果的精準(zhǔn)度,從而提升用戶體驗。論文提出的方案 100% 流量部署到了快手短視頻推薦生產(chǎn)環(huán)境,影響了日均超過 3.4 億用戶的體驗,是端上智能在大規(guī)模推薦場景落地的創(chuàng)新實踐。

論文鏈接:
https://dl.acm.org/doi/10.1145/3511808.3557065
5. 致敬Metaformer!圖像超分多尺度注意網(wǎng)絡(luò)MAN開源:大核分解與注意力機制的巧妙結(jié)合
原文:
https://mp.weixin.qq.com/s/DF73mR6U4MstHeAHOZTGBw
論文鏈接:
https://arxiv.org/abs/2209.14145
代碼地址:
https://github.com/icandle/MAN
本文基于大核分解和注意機制,提出應(yīng)用于圖像超分的多尺度注意網(wǎng)絡(luò)MAN。通過可解釋的門控空間注意單元來匯總上下文信息,利用多尺度大核注意模塊獲得豐富注意特征圖,并聚合局部-全局信息。本文方法與現(xiàn)有流行方法進行了詳細的實驗對比,獲得了競爭性的對比結(jié)果。
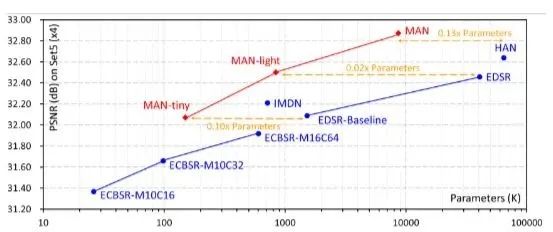
圖像超分旨在從低分辨率輸入重建高分辨輸出。然而基于CNN的方法要么通過更大數(shù)據(jù)集來提高性能,要么引入了更復(fù)雜的網(wǎng)絡(luò)設(shè)計,這些無疑都增加了計算成本消耗。
還記得今年2月份出爐的那篇VAN嗎,VAN通過詳細實驗證明了大核的卷積可以被有效分解為三種卷積的組合,分別為:深度卷積、含膨脹的深度卷積、逐點卷積。這里給出VAN的分解示意圖:
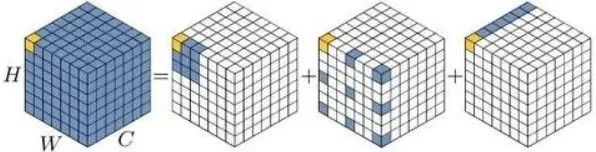
VAN的作者在文末提到,未來對VAN的改進可能包含多分支或多尺度設(shè)計的應(yīng)用。在本文中,作者等人在圖像超分任務(wù)中對VAN進行可行性考察,發(fā)現(xiàn)了一個很重要的問題:VAN的分解過程中,含膨脹的深度卷積會為超分任務(wù)帶來“塊狀偽影(blocking artifacts)”。在損害性能的同時,固定的核大小無法充分局部-全局特征。
綜上,作者將多尺度機制與大核注意機制結(jié)合來解決上述問題,并采用門控機制校準(zhǔn)注意圖,避免含膨脹的深度卷積帶來的塊狀偽影。
6. 一個Trick 搞定 CNN與Transformer,即插即漲點即提速
原文:
https://mp.weixin.qq.com/s/jRfWEgQ6cqVz5hcm6WOa2g
論文鏈接:
https://arxiv.org/abs/2210.04020
近年來,Transformer模型在各個領(lǐng)域都取得了巨大的進展。在計算機視覺領(lǐng)域,視覺Transformer(ViTs)也成為卷積神經(jīng)網(wǎng)絡(luò)(ConvNets)的有力替代品,但它們還無法取代ConvNet,因為兩者都有各自的優(yōu)點。例如,ViT善于利用注意力機制提取全局特征,而ConvNets由于其強烈的歸納偏差,在建模局部關(guān)系時更有效。

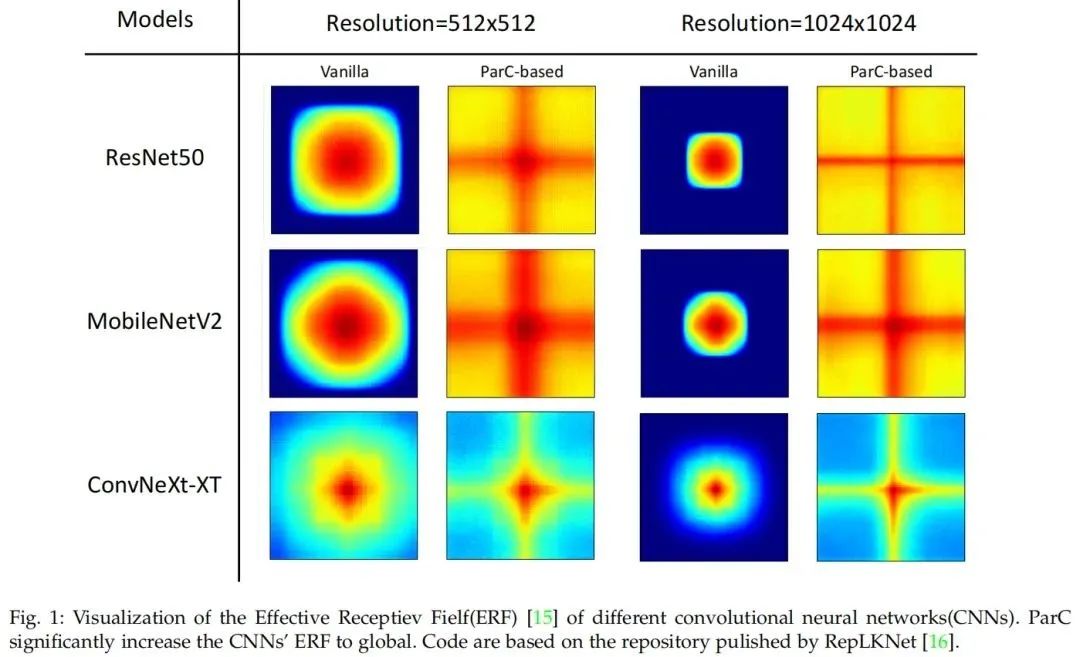
一個自然的想法是結(jié)合ConvNets和ViT的優(yōu)勢來設(shè)計新的結(jié)構(gòu)。本文提出了一種新的基本神經(jīng)網(wǎng)絡(luò)算子,稱為位置感知循環(huán)卷積(ParC)及其加速版本Fast-ParC。ParC算子通過使用全局核和循環(huán)卷積來捕獲全局特征,同時通過位置嵌入來保持位置敏感性。
Fast-ParC使用快速傅里葉變換將ParC的O(n2)時間復(fù)雜度進一步降低為O(n log n)。這種加速使得在具有大型特征映射的模型的早期階段使用全局卷積成為可能,但仍保持與使用3x3或7x7內(nèi)核相當(dāng)?shù)目傮w計算成本。所提出的操作可以以即插即用的方式使用:
1)將ViT轉(zhuǎn)換為純ConvNet架構(gòu),以獲得更廣泛的硬件支持和更高的推理速度;
2)在ConvNets的深層替換傳統(tǒng)的卷積,通過擴大有效感受野來提高準(zhǔn)確性。實驗結(jié)果表明,ParC操作可以有效地擴大傳統(tǒng)ConvNets的感受野,并且在所有三種流行的視覺任務(wù)(圖像分類、目標(biāo)檢測和語義分割)中,采用所提出的操作都有利于ViT和ConvNet模型。
7. 只需一次向前推導(dǎo),深度神經(jīng)網(wǎng)絡(luò)可視化方法來了!
原文:
https://mp.weixin.qq.com/s/rzle3EYD4atj9oJ0Xy43aw
論文地址:
https://arxiv.org/abs/2209.11189

寫在前面的話
類激活圖(CAM)致力于解釋卷積神經(jīng)網(wǎng)絡(luò)的“黑盒”屬性。本文首次提出可學(xué)習(xí)的類激活方法,通過設(shè)計適當(dāng)損失來迫使注意機制學(xué)習(xí)有效CAM輸出,并只需一次前向推理。在ImageNet上與流行類激活方法比較,取得了優(yōu)異且有趣的實驗結(jié)果。最后針對分類錯誤的情況,作者等人進行了細致而全面的分析。
類激活方法與Motivation簡述
深度卷積神經(jīng)網(wǎng)絡(luò)對相關(guān)決策的可解釋性不強,這種“黑盒”屬性影響了該技術(shù)在安全、醫(yī)療等領(lǐng)域的商業(yè)應(yīng)用。由類激活圖(CAM)生成的顯著圖SM(saliency map)描述了對模型決策貢獻最大的圖像區(qū)域,因此是一種為“黑盒”提供可解釋理論的方法。
以往的CAM方法分為基于梯度和基于擾動兩種,如下圖所示:
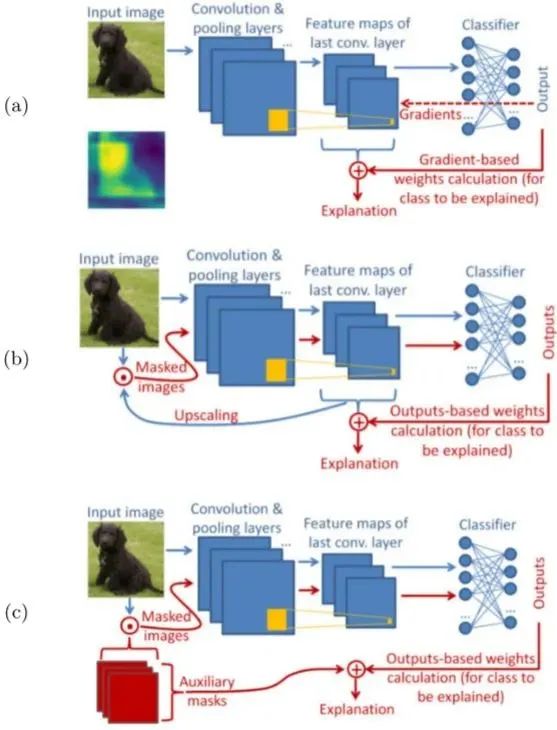
在圖1 (a) 中,基于梯度的方法使用從outputs反向傳播的梯度計算最后一個卷積層中特征權(quán)重,并將特征圖加權(quán)聚合得到CAM,explanation代表由CAM產(chǎn)生的SM。(常見的有Grad-CAM、GradCAM++)
在圖1 (b) 中,基于擾動的方法通常選取模型中不同深度的特征圖,或隨機擾動圖(圖1 (c) ),作為掩碼與輸入圖像點乘,得到擾動輸入,最后通過前向傳遞擾動輸入來生成SM。(常見方法有SIDU、Score-CAM、SISE、ADA-SISE、RISE)
然而這些方法要么基于反向傳播梯度,要么在推理階段需要多次前向傳遞,因此引入了大量的計算開銷。另外,這些方法在關(guān)注模型解釋的同時,忽略了對訓(xùn)練集的有效利用。
因此本文提出了一種僅需一次前向傳遞的方法,同時引入注意機制,用可學(xué)習(xí)的方法,使訓(xùn)練集得到了充分利用。
一些可能的思考與總結(jié)
本文為進一步解釋“黑盒”模型,提出了一種可學(xué)習(xí)的CAM方法,并產(chǎn)生了具有競爭性的實驗結(jié)果。但是有兩個問題筆者不得其解。
第一個問題就是,本文方法通過訓(xùn)練集大量訓(xùn)練獲得四個經(jīng)驗下的正則化參數(shù),那么相比其他方法,是否存在額外增加了實現(xiàn)成本?另外,如果將此參數(shù)應(yīng)用于其他數(shù)據(jù)集上是否能保持原有性能,到時候如果不能是不是又要重新從訓(xùn)練集中獲取呢?
第二,對于ImageNet中的某些包含多標(biāo)簽圖像,錯誤分類的原因是分類器已經(jīng)對某些類別形成既定的學(xué)習(xí)認(rèn)知。那么假如沒有訓(xùn)練這個環(huán)節(jié),是不是就能減少對某些已確定類別的錯誤識別呢,或者說,有沒有其他方法能減少這種情況的發(fā)生呢。
8. AI框架歷史演進和趨勢探索
原文:
https://mp.weixin.qq.com/s/a3GaHwBNq7KJO0Dex-xOUg
AI框架是一種底層開發(fā)工具,是集深度學(xué)習(xí)核心訓(xùn)練和推理框架、基礎(chǔ)模型庫、端到端開發(fā)套件、豐富的工具組件于一體的平臺。
有了AI框架,工程師在工作時調(diào)試算法,就可以更快速、更高效。通俗一點講,AI框架相當(dāng)于是AI時代的操作系統(tǒng),如同PC時代Windows,移動互聯(lián)網(wǎng)時代的iOS和安卓。
AI框架發(fā)展現(xiàn)狀和趨勢
AI框架的歷史并不算長,從2010年誕生的Theano算起,至今不過十二年時間。2017年后,早期的Theano、Caffe、Torch等框架逐漸銷聲匿跡,2016年前后出現(xiàn)的TensorFlow(谷歌)、PyTorch(Facebook)、飛槳(百度)逐漸占據(jù)市場。
從目前市場占有情況看,產(chǎn)業(yè)界以TensorFlow為主,學(xué)術(shù)界以PyTorch為主。與TensorFlow過于注重工業(yè),PyTorch專注學(xué)界不同,飛槳的特性在于工業(yè)學(xué)界兩手抓,通過動態(tài)圖自動解析編譯靜態(tài)圖的技術(shù),兼顧了學(xué)界的靈活,同時也實現(xiàn)了產(chǎn)業(yè)界希望的高效。
除了TensorFlow、PyTorch、飛槳,深度學(xué)習(xí)框架還包括由Amazon設(shè)計研發(fā)并開源的MXNet、微軟在github上開源的CNTK、華為推出的MindSpore、北京一流科技有限公司開發(fā)的OneFlow,以及清華大學(xué)自研的Jittor,和騰訊、字節(jié)跳動、360開源的Angel、BytePS、TensorNet。
過去這些年,AI框架已形成較為完整的技術(shù)體系,當(dāng)前主流AI框架的核心技術(shù)演化出三大層次,分為基礎(chǔ)層、組件層和生態(tài)層,其中基礎(chǔ)層實現(xiàn)AI框架最基礎(chǔ)核心的功能,具體包括編程開發(fā)、編譯優(yōu)化以及硬件使能三個子層。
從技術(shù)生態(tài)體系中的功能定位看,AI框架對下調(diào)用底層硬件計算資源,對上支撐AI應(yīng)用算法模型搭建,提供算法工程化實現(xiàn)的標(biāo)準(zhǔn)環(huán)境,是AI技術(shù)體系的關(guān)鍵核心。
AI框架技術(shù)持續(xù)演進,歷經(jīng)萌芽階段、成長階段、穩(wěn)定階段,當(dāng)前已進入深化階段。AI框架正向著超大規(guī)模AI、全場景支持、安全可信等技術(shù)特性深化探索。
AI框架面臨的挑戰(zhàn)
然而在這個探索的過程中,面臨諸多挑戰(zhàn)。在超大規(guī)模AI方面,當(dāng)前超大規(guī)模AI成為新的深度學(xué)習(xí)范式。OpenAI于2020年5月發(fā)布GPT-3模型,包含1750億參數(shù),數(shù)據(jù)集達到45T,在多項NLP任務(wù)中超越了人類水平。這種超大規(guī)模的模型參數(shù)及超大規(guī)模的數(shù)據(jù)集的AI大模型范式,實現(xiàn)了深度學(xué)習(xí)新的突破。
產(chǎn)業(yè)界和學(xué)術(shù)界看到這種新型范式的潛力后紛紛入局,繼OpenAI后,華為基于MindSpore框架發(fā)布了盤古大模型、智源發(fā)布了悟道模型、阿里發(fā)布了M6模型、百度發(fā)布了文心模型等。超大規(guī)模AI正成為下一代人工智能的突破口,也是最有潛力的強人工智能技術(shù)。
超大規(guī)模AI需要大模型、大數(shù)據(jù)、大算力的三重支持,這就對AI框架提出了新的挑戰(zhàn),比如內(nèi)存墻,大模型訓(xùn)練過程中需要存儲參數(shù)、激活、梯度、優(yōu)化器狀態(tài),鵬程 盤古一個模型的訓(xùn)練就需要近4TB的內(nèi)存。算力墻,以鵬程 . 盤古2000億參數(shù)量的大模型為例,需要3.6EFLOPS的算力支持,要求必須構(gòu)建大規(guī)模的異構(gòu)AI計算集群才能滿足這樣的算力需求,同時算力平臺要滿足智能調(diào)度來提升算力資源的利用率。還有通信墻、調(diào)優(yōu)墻、部署墻等。
在全場景支持方面,隨著云服務(wù)器、邊緣設(shè)備、終端設(shè)備等人工智能硬件運算設(shè)備的不斷涌現(xiàn),以及各類人工智能運算庫、中間表示工具以及編程框架的快速發(fā)展,人工智能軟硬件生態(tài)呈現(xiàn)多樣化發(fā)展趨勢。但主流框架訓(xùn)練出來的模型卻不能通用,學(xué)術(shù)科研項目間難以合作延伸,造成了深度學(xué)習(xí)框架的“碎片化”。
目前業(yè)界并沒有統(tǒng)一的中間表示層標(biāo)準(zhǔn),導(dǎo)致各硬件廠商解決方案存在一定差異,以致應(yīng)用模型遷移不暢,增加了應(yīng)用部署難度。因此,基于AI框架訓(xùn)練出來的模型進行標(biāo)準(zhǔn)化互通將是未來的挑戰(zhàn)。
然而即使面臨諸多挑戰(zhàn),過去兩年,行業(yè)一直在持續(xù)探索,并取得一定突破,如2020年華為推出昇思MindSpore,在全場景協(xié)同、可信賴方面有一定的突破;曠視推出天元MegEngine,在訓(xùn)練推理一體化方面深度布局等。
整體而言,在人工智能體系中,AI框架處于貫通上下的腰部位置,下接芯片、上承應(yīng)用,是一個關(guān)鍵樞紐,是推動AI應(yīng)用大規(guī)模落地的關(guān)鍵力量。因此對于企業(yè)來說,克服AI框架當(dāng)前面臨的挑戰(zhàn),不斷探索新趨勢,進行技術(shù)創(chuàng)新,完善技術(shù)、功能和生態(tài)是關(guān)鍵。
- END -

原文標(biāo)題:【AI簡報20221021期】英特爾i9-13900K重奪PC性能桂冠、RISC-V可靠矢量處理彎道超車
文章出處:【微信公眾號:RTThread物聯(lián)網(wǎng)操作系統(tǒng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
RT-Thread
+關(guān)注
關(guān)注
31文章
1303瀏覽量
40293
原文標(biāo)題:【AI簡報20221021期】英特爾i9-13900K重奪PC性能桂冠、RISC-V可靠矢量處理彎道超車
文章出處:【微信號:RTThread,微信公眾號:RTThread物聯(lián)網(wǎng)操作系統(tǒng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論