") NVIDIA“全堆棧計(jì)算”策略應(yīng)對(duì)AI加速計(jì)算時(shí)代挑戰(zhàn)
NVIDIA“全堆棧計(jì)算”策略應(yīng)對(duì)AI加速計(jì)算時(shí)代挑戰(zhàn)
在神經(jīng)網(wǎng)絡(luò)和機(jī)器學(xué)習(xí)技術(shù)的推動(dòng)下,特別是2016年谷歌的AlphaGo在多次與人類頂尖圍棋棋手的對(duì)戰(zhàn)中大獲全勝后,給全世界做了一次人工智能(AI)科普,人工智能的新一波發(fā)展浪潮開始了。
“計(jì)算技術(shù)正在蓬勃發(fā)展,推動(dòng)這枚火箭的引擎是加速計(jì)算,而燃料則是 AI。” NVIDIA 創(chuàng)始人兼首席執(zhí)行官黃仁勛在2022秋季GTC 大會(huì)主題演講中表示。也就是說AI加速計(jì)算時(shí)代已經(jīng)悄然來臨。
近10年來,數(shù)據(jù)量和數(shù)據(jù)處理方式都發(fā)生了很大的改變。大量的數(shù)據(jù)不再是人類事件生成,而是各種類型的傳感器和設(shè)備所生成,數(shù)據(jù)量正在呈指數(shù)級(jí)在往上增長(zhǎng)。比如說,智能手表會(huì)收集用戶運(yùn)動(dòng)健身和健康狀況相關(guān)的詳細(xì)數(shù)據(jù),自動(dòng)駕駛汽車在行駛過程中會(huì)不斷收集周圍環(huán)境的信息,據(jù)統(tǒng)計(jì)一輛汽車一小時(shí)就可以生成5TB的數(shù)據(jù),未來隨著自動(dòng)駕駛汽車數(shù)量的持續(xù)增長(zhǎng),將會(huì)產(chǎn)生龐大的數(shù)據(jù)量。
隨著數(shù)據(jù)量的爆炸式增長(zhǎng),人們開始使用AI來分析數(shù)據(jù),因?yàn)锳I不僅能夠分辨出語音和視頻模式,強(qiáng)化學(xué)習(xí)技術(shù),還能夠從大量的可能性中識(shí)別出最佳結(jié)果,從而為使用者提供最有價(jià)值的分析。而NVIDIA在AI加速計(jì)算領(lǐng)域這幾年一路狂奔,取得亮眼成績(jī)。
談到原因,黃仁勛認(rèn)為這與NVIDIA這些年來持續(xù)推行“全堆棧計(jì)算”策略是分不開的。“為了在加速計(jì)算領(lǐng)域取得成功,我們不再只是做別人曾經(jīng)做的事情,而是把它整合成一家縱向一體化的公司。”在他看來,“在AI加速計(jì)算領(lǐng)域,如果不垂直整合,就不會(huì)成功。因?yàn)闆]有人會(huì)專門為你寫操作系統(tǒng),在云端、超級(jí)計(jì)算和企業(yè)中,也沒有人會(huì)開發(fā)你的分布式操作系統(tǒng),而沒有完整的堆棧,用戶就無法使用你的平臺(tái),所以你別無選擇,只能自己動(dòng)手。”
黃仁勛認(rèn)為,客戶要購(gòu)買的不是NVIDIA的芯片,而是NVIDIA的計(jì)算堆棧。他同時(shí)強(qiáng)調(diào),NVIDIA的全堆棧,主要包括四大平臺(tái),即NVIDIA RTX、NVIDIA HPC、NVIDIA AI和NVIDIA Omniverse。
NVIDIA RTX:推出全新架構(gòu)RTX 40系列GPU
NVIDIA RTX是NVIDIA在Siggraph 2018上推出的全新GPU架構(gòu),通過兩個(gè)全新處理器來擴(kuò)展可編程著色器。RT Core 用于加速實(shí)時(shí)光線追蹤,Tensor Core 用于處理矩陣運(yùn)算,這是深度學(xué)習(xí)的核心。
在2022 秋季 GTC 大會(huì)上,NVIDIA宣布推出其第3代RTX架構(gòu)------Ada Lovelace,這代 RTX 以數(shù)學(xué)家 Ada Lovelace 的名字命名,她被公認(rèn)為世界上第一位計(jì)算機(jī)程序員。

圖:NVIDIA Racer RTX 是利用 GeForce RTX 40 系列 GPU 和 NVIDIA DLSS 3 創(chuàng)建未來游戲內(nèi)容的例子
同時(shí),NVIDIA還推出了基于Ada Lovelace架構(gòu)的RTX 40系列GPU,該系列GPU采用了TSMC的4N工藝,可集成760億個(gè)晶體管和超過16000個(gè)CUDA核心。其主要技術(shù)創(chuàng)新包括:
- 流式多處理器具有高達(dá)83 TFLOPS 的著色器能力,吞吐量超過上一代產(chǎn)品2倍。
- 第三代RT Core的有效光線追蹤計(jì)算能力達(dá)到191 TFLOPS,是上一代產(chǎn)品2.8倍。
- 第四代Tensor Core具有高達(dá)1.32 Petaflops 的 FP8 張量處理性能,超過上一代使用 FP8 加速性能的5倍。
- 著色器執(zhí)行重排序(SER)通過即時(shí)重新安排著色器負(fù)載來提高執(zhí)行效率,從而更好地利用 GPU 資源。作為與 CPU 的亂序執(zhí)行一樣的重大創(chuàng)新,SER 為光線追蹤帶來最高可達(dá)3倍的性能提升,整體游戲性能提升可高達(dá)25%。
- Ada光流加速器帶來2倍的性能提升,使 DLSS 3 能夠預(yù)測(cè)場(chǎng)景中的運(yùn)動(dòng),使神經(jīng)網(wǎng)絡(luò)能夠在保持圖像質(zhì)量的同時(shí)提高幀率。
- 架構(gòu)上的改進(jìn),與 TSMC 4N 定制工藝技術(shù)緊密結(jié)合,實(shí)現(xiàn)了高達(dá)2倍的性能功耗比飛躍。
- 雙NVIDIA編碼器(NVENC)將輸出時(shí)間至多縮短一半,并支持 AV1。OBS、Blackmagic Design DaVinci Resolve、Discord 以及更多的公司都已在采用 NVENC AV1 編碼器。
在產(chǎn)品方面,NVIDIA推出了首款基于Ada Lovelace架構(gòu)的工作站顯卡NVIDIA RTX 6000,該工作站顯卡具有142個(gè)第三代RT Core、568個(gè)第四代Tensor Core、18,176個(gè)CUDA核心,以及48GB顯存,可為工程師、設(shè)計(jì)師和科學(xué)家提供助力,滿足在虛擬世界中構(gòu)建世界所需的苛刻的內(nèi)容創(chuàng)建、渲染、人工智能和模擬工作負(fù)載的需求。
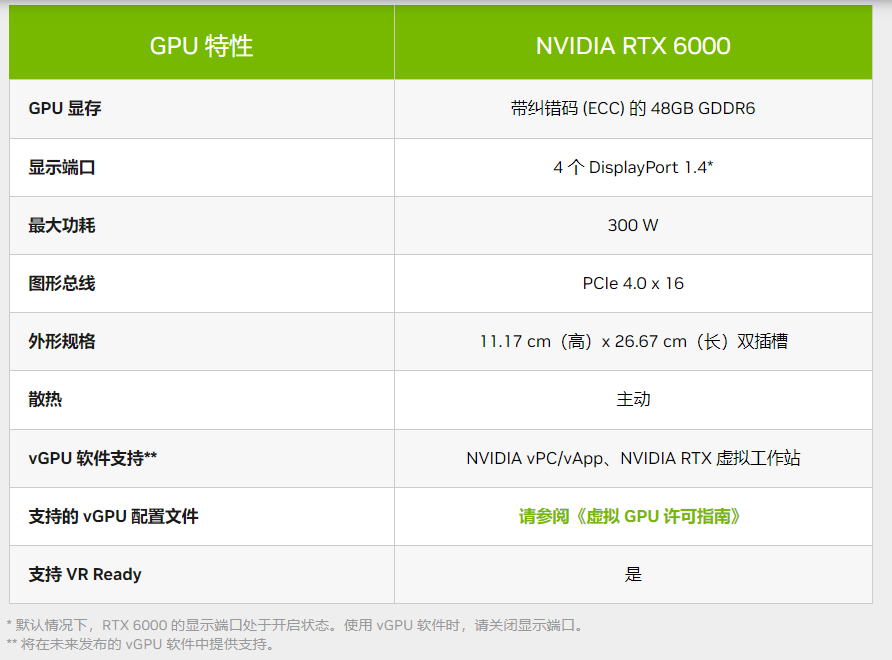
圖:NVIDIA RTX 6000具體參數(shù)(來源:NVIDIA官網(wǎng))
據(jù)NVIDIA介紹,與其前代產(chǎn)品相比,全新的RTX 6000可在企業(yè)環(huán)境中提供2~4倍的性能提升,包括最多2倍的光追性能、AI訓(xùn)練性能、及單精度浮點(diǎn)性能等。NVIDIA還為其配備了48GB支持ECC的GDDR6顯存,以支持最大體積的3D模型渲染或AI計(jì)算。此外,該RTX 6000采用了PCIe 4×16接口,整卡最大功耗為300W。
值得注意的是,全新的RTX 6000的開始出貨時(shí)間應(yīng)該是今年12月。
NVIDIA HPC:具有AI支持的全堆棧科學(xué)計(jì)算
NVIDIA HPC是NVIDIA的科學(xué)計(jì)算堆棧,在AI的支持下,其GPU、CPU、DPU和軟件將共同幫助數(shù)據(jù)中心擴(kuò)大規(guī)模,為量子計(jì)算、分子動(dòng)力學(xué)、流體動(dòng)力學(xué)、氣候研究等科學(xué)研究做出支持。
NVIDIA HPC包括了HOLOSCAN(邊緣計(jì)算和人工智能平臺(tái)可捕獲和分析來自醫(yī)療設(shè)備和科學(xué)儀器的數(shù)據(jù))、MODULUS、CUQANTUM(量子計(jì)算)等數(shù)據(jù)中心工作負(fù)載和技術(shù)。
具體來看,針對(duì)HPC的HOLOSCAN SDK可以幫助科學(xué)家和研究人員加速科學(xué)儀器應(yīng)用的相關(guān)發(fā)現(xiàn)。該SDK引入了用于創(chuàng)建管道流邊緣的高性能框架,允許用戶用C++,Python和jax開發(fā)應(yīng)用程序。而且后續(xù)還會(huì)推出更多的功能。

NVIDIA Modulus是用于開發(fā)基于物理學(xué)的機(jī)器學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)模型的平臺(tái)。它允許用戶以治理偏微分方程或PDES的形式融合物理學(xué)的力量。用數(shù)據(jù)建立高保真的參數(shù)化代用模型,具有近乎實(shí)時(shí)的延時(shí)。它可以支持處理AI驅(qū)動(dòng)的物理問題以及復(fù)雜的非線性多物理系統(tǒng)設(shè)計(jì)數(shù)字孿生模型等工作。而且,它在提供相同準(zhǔn)確性的同時(shí),比單獨(dú)的模擬快了110萬倍。
在量子計(jì)算方面,已經(jīng)有25個(gè)國(guó)家級(jí)的量子計(jì)劃在運(yùn)作了,過去12個(gè)月有超過2100篇量子計(jì)算相關(guān)的文章得到了發(fā)布。而且,目前已經(jīng)出現(xiàn)了超過250家量子計(jì)算初創(chuàng)企業(yè)。NVIDIA也在2022 秋季 GTC 大會(huì)上推出了由優(yōu)化庫和工具優(yōu)化構(gòu)建的SDK------cuQuantum和混合量子經(jīng)典應(yīng)用開發(fā)平臺(tái)QODA。
其中,cuQuantum可用于量子電路模擬開發(fā),借助cuQuantum,一臺(tái)32個(gè)節(jié)點(diǎn)的DGX Pod,可以模擬一臺(tái)40量子位的量子計(jì)算機(jī)。目前,cuQuantum得到廣泛運(yùn)用,包括AWS、Google、IBM、Oracle以及很多初創(chuàng)公司和超算中心都在采用該SDK,比如Oracle正在為OCI云構(gòu)建量子模擬虛擬機(jī);AWS將cuQuantum集成到其Braket量子計(jì)算服務(wù)中,實(shí)現(xiàn)了900倍的加速和3.5倍的成本縮減。
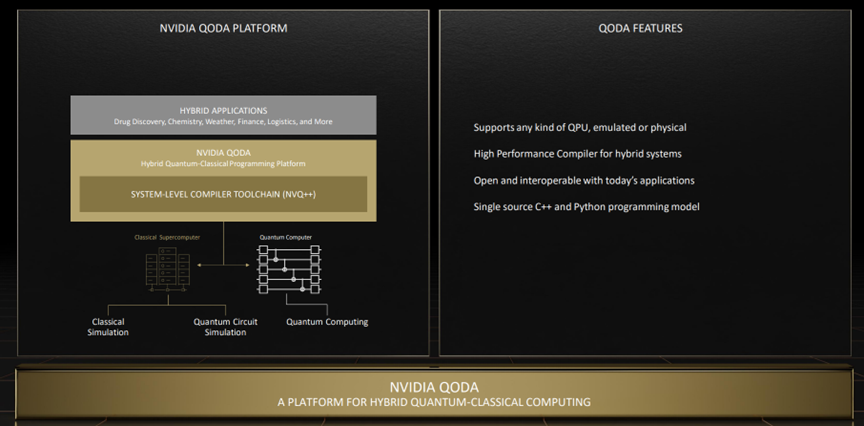
而QODA是一個(gè)開放的,與處理器無關(guān)的量子平臺(tái),適用于混合量子加速計(jì)算,它為研究人員提供了量子加速計(jì)算的編程模型。
NVIDIA AI:本質(zhì)上是現(xiàn)代AI的操作系統(tǒng)
在黃仁勛看來,NVIDIA AI本質(zhì)上是現(xiàn)代AI的操作系統(tǒng),它從數(shù)據(jù)采集、數(shù)據(jù)處理,發(fā)展到深度學(xué)習(xí),再到如今的的圖表分析和圖表學(xué)習(xí)系統(tǒng),再到推論工具Triton,不斷在向前演化。“所以這個(gè)端到端平臺(tái)是NVIDIA人工智能的一部分。如果你在任何地方做機(jī)器學(xué)習(xí)或任何類型的人工智能模型,你都可以使用NVIDIA AI。”他表示。
據(jù)他介紹,NVIDIA通過550個(gè)SDK和AI模型為約3000個(gè)應(yīng)用提供加速。在過去12個(gè)月中對(duì)超過100個(gè)SDK進(jìn)行了更新,并推出了25個(gè)新SDK,且每次更新都會(huì)提高計(jì)算機(jī)組合的性能和吞吐量。
下面看看幾個(gè)比較典型的NVIDIA AI應(yīng)用:
Forecast net:以前所未有的需求和準(zhǔn)確性預(yù)測(cè)極端天氣。Forecast net在不到兩秒鐘的時(shí)間內(nèi)就能生成一個(gè)星期的預(yù)報(bào),比歐洲中程天氣預(yù)報(bào)中心的綜合預(yù)報(bào)系統(tǒng)(一種最先進(jìn)的數(shù)值天氣預(yù)報(bào)模型)快了幾個(gè)數(shù)量級(jí)。而且它的準(zhǔn)確度相當(dāng)或更好。
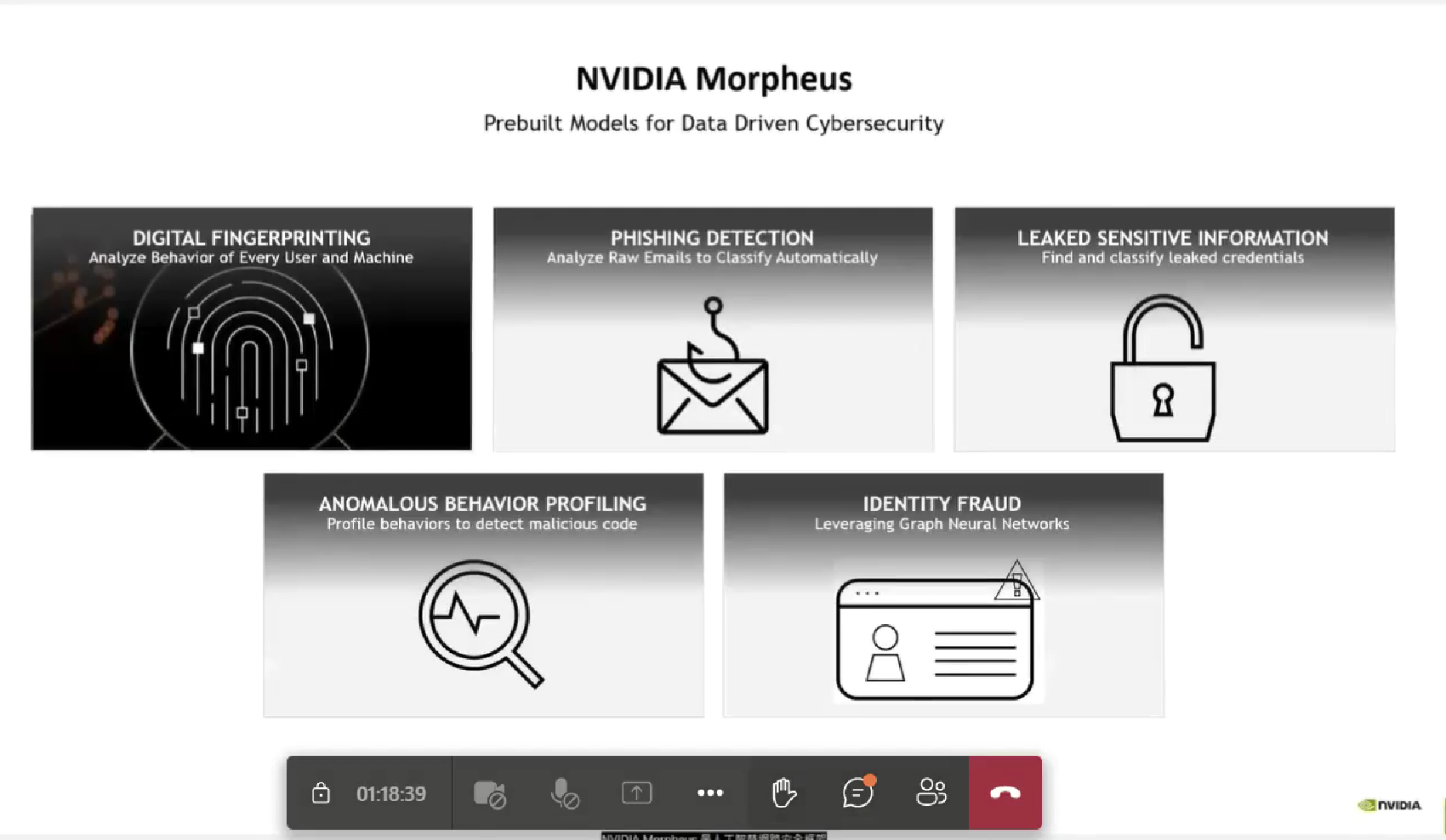
Morpheus:它是AI網(wǎng)絡(luò)安全框架,旨在使整個(gè)安全數(shù)據(jù)推斷更容易、更快、更強(qiáng)大。它由許多模塊組成,可以以各種方式連接,允許開發(fā)人員創(chuàng)建整個(gè)潛能。在輸入方面,Morpheus與數(shù)據(jù)無關(guān)。它提供了以下預(yù)先訓(xùn)練好的模型,以簡(jiǎn)化實(shí)施并加快它們的模型性能。
1.數(shù)字指紋識(shí)別——識(shí)別憑證使用行為的變化,將其歸類為人類與機(jī)器的互動(dòng)和機(jī)器與機(jī)器的互動(dòng);
2.釣魚網(wǎng)站檢測(cè)——分析整個(gè)原始電子郵件,將其分類為掛垃圾郵件或釣魚網(wǎng)站;
3.泄露的敏感數(shù)據(jù)分類——發(fā)現(xiàn)泄露的憑證鑰匙、密碼、信用卡號(hào)碼、銀行賬戶號(hào)碼等的分類。
4.異常行為分析檢測(cè)——以檢測(cè)像加密惡意軟件這樣的東西;
5.基于圖形神經(jīng)網(wǎng)絡(luò)的欺詐檢測(cè)——幫助你用以前所需的一小部分標(biāo)記數(shù)據(jù)獲得高準(zhǔn)確率的結(jié)果。
Triton推理服務(wù)器:Triton 是一款開源的推理服務(wù)軟件,可助力團(tuán)隊(duì)從任何框架、本地存儲(chǔ)或從任何基于 GPU 或 CPU 的基礎(chǔ)架構(gòu)、云、數(shù)據(jù)中心或邊緣的 Google Cloud 平臺(tái)或 AWS S3 中部署經(jīng)過訓(xùn)練的 AI 模型。據(jù)悉,Triton的下載量已超過300萬次,比去年增加了300%。Triton可以在所有主要公有云中使用,并可集成到領(lǐng)先的MLOps平臺(tái)中。目前已受到超過35000家公司的青睞。
cuOPT:它是建立在RAPIDS之上的最新庫之一。cuOPT是一個(gè)AI物流軟件應(yīng)用程序,可以實(shí)現(xiàn)近乎實(shí)時(shí)的路由優(yōu)化。與最先進(jìn)的CPU解決方案相比,它的速度提高了100倍以上,在300個(gè)humberger基準(zhǔn)問題中的190個(gè)問題上的準(zhǔn)確度創(chuàng)下了世界紀(jì)錄,并且可以擴(kuò)展到數(shù)萬個(gè)地點(diǎn),cuOPT極大地方便了物流和運(yùn)籌學(xué)開發(fā)人員。
NVIDIA Omniverse:構(gòu)建和運(yùn)行元宇宙應(yīng)用的平臺(tái)
Omniverse是一個(gè)實(shí)時(shí)的大型3D數(shù)據(jù)庫,基于USD構(gòu)建的網(wǎng)絡(luò),連接3D世界。同時(shí)它也是是一個(gè)計(jì)算平臺(tái),該平臺(tái)適用于從產(chǎn)品設(shè)計(jì)和造型,到工程策劃、制造、營(yíng)銷和運(yùn)營(yíng)的整個(gè)產(chǎn)品生命周期。
在2022秋季GTC 大會(huì)上,NVIDIA宣布了Omniverse的重大更新:
- 支持 Ada Lovelace GPU,在光線追蹤和大型場(chǎng)景性能方面實(shí)現(xiàn)巨大飛躍;
- 基于 GAN 和擴(kuò)散模型的新型神經(jīng)渲染工具;
- OmniGraph 是一個(gè)圖形執(zhí)行引擎,可通過程序化的方式控制行為、動(dòng)作和行動(dòng);
- Omniverse Physics 的重大更新,用來處理復(fù)雜的多連接部件對(duì)象的運(yùn)動(dòng)情況;
- 全新的 Cloud XR,支持在 VR 中實(shí)現(xiàn) Ada 強(qiáng)大的光線追蹤功能;
- 首個(gè)用于合成數(shù)據(jù)生成和數(shù)字孿生模擬的 SimReady 素材庫;
- Replicator 是備受青睞的 Omniverse 應(yīng)用之一,用來生成合成數(shù)據(jù),從而訓(xùn)練自動(dòng)駕駛汽車、機(jī)器人和各種計(jì)算機(jī)視覺模型。
- 新的 Omniverse JT 連接器 則是一款大型應(yīng)用,Siemens 發(fā)明了 JT,這是產(chǎn)品生命周期管理的行業(yè)標(biāo)準(zhǔn)語言,也是 NX、Creo、Catia 和 Inventor 等 CAD 系統(tǒng)的互操作格式,JT 連接器使得工業(yè)和制造業(yè)可以運(yùn)用 Omniverse。目前,Omniverse已擁有150個(gè)連接器,這些都是全球市值 100 萬億美元的產(chǎn)業(yè)所使用的工具和平臺(tái)。這些連接器將 Omniverse 的應(yīng)用范圍拓展到各種公司,覆蓋零售、交通、電信、制造、媒體和娛樂、消費(fèi)品和奢侈品,以及供應(yīng)鏈和物流等大型行業(yè)領(lǐng)域。
其實(shí),Omniverse 是一個(gè)新的計(jì)算平臺(tái),需要采用新的計(jì)算系統(tǒng),Omniverse 計(jì)算平臺(tái)由三部分構(gòu)成:RTX 計(jì)算機(jī)(供創(chuàng)作者、設(shè)計(jì)師和工程師使用)、OVX 服務(wù)器(用來托管與 Nucleus 數(shù)據(jù)庫的連接并運(yùn)行虛擬世界模擬),以及第三部分:NVIDIA GDN(進(jìn)入 Omniverse 的門戶)。
通過 GeForce Now,NVIDIA構(gòu)建了一個(gè)全球圖形交付網(wǎng)絡(luò)(即 GDN),該網(wǎng)絡(luò)覆蓋 100 個(gè)地區(qū),為之提供響應(yīng)靈敏的超快 RTX 圖形內(nèi)容交付網(wǎng)絡(luò) (CDN)。通過 NVIDIA RTX PC、云端的 NVIDIA GPU 和 NVIDIA GDN,NVIDIA打造了一個(gè)覆蓋全球的 Omniverse 計(jì)算平臺(tái)。
在今年9月20日,NVIDIA宣布推出第二代NVIDIA OVX,該系統(tǒng)基于Ada Lovelace GPU 架構(gòu)的 NVIDIA? L40 GPU,能夠?yàn)闃?gòu)建復(fù)雜的工業(yè)數(shù)字孿生提供強(qiáng)大的算力和性能支持。
L40 GPU 包含第三代 RT Core 和第四代 Tensor Core,能夠?yàn)樵?OVX 系統(tǒng)上運(yùn)行的 Omniverse 工作負(fù)載提供強(qiáng)大功能,包括加速的光線追蹤和路徑追蹤材質(zhì)渲染、物理級(jí)精確的模擬以及逼真的 3D 合成數(shù)據(jù)生成。L40 也會(huì)在主要 OEM 廠商的 NVIDIA 認(rèn)證系統(tǒng)服務(wù)器中提供,以驅(qū)動(dòng)數(shù)據(jù)中心的 RTX 工作負(fù)載。
具體規(guī)格方面,每個(gè)OVX 服務(wù)器節(jié)點(diǎn)帶有8個(gè)NVIDIA L40 GPU和3個(gè)ConnectX-7 網(wǎng)卡,可提供100/200/400G網(wǎng)絡(luò)速率。如果 Omniverse工作負(fù)載對(duì)性能和規(guī)模提出更高要求,這些服務(wù)器可以通過 NVIDIA Spectrum?-3以太網(wǎng)平臺(tái)部署在NVIDIA OVX POD和 SuperPOD配置上。
黃仁勛認(rèn)為,Omniverse是用來構(gòu)建和運(yùn)行元宇宙應(yīng)用的平臺(tái),無論是數(shù)字世界和現(xiàn)實(shí)世界在何處教會(huì),Omniverse都能發(fā)揮作用。此外,Omniverse還有一項(xiàng)重要的用途就是機(jī)器人開發(fā),而機(jī)器人將會(huì)是AI的新一波浪潮。
結(jié)語
此外, NVIDIA在2022秋季GTC 大會(huì)上還帶來了新的邊緣AI計(jì)算平臺(tái)IGX平臺(tái),IGX平臺(tái)由NVIDIA IGX Orin超級(jí)計(jì)算機(jī)驅(qū)動(dòng),能更簡(jiǎn)便的為制造、物流、醫(yī)療等安全敏感行業(yè)帶來了安全的工作環(huán)境;史詩級(jí)的超級(jí)芯片DRIVE Thor(雷神),這款SoC將于2025年上市,其AI性能高達(dá)2000TOPS;以及Jetson Orin Nano,它可運(yùn)行NVIDIA Isaac機(jī)器人堆棧,并具有ROS 2 GPU加速框架,速度比之前大受歡迎的Jetson Nano快80倍等產(chǎn)品更新。
-
機(jī)器人
+關(guān)注
關(guān)注
211文章
28520瀏覽量
207527 -
虛擬現(xiàn)實(shí)
+關(guān)注
關(guān)注
15文章
2289瀏覽量
95522 -
數(shù)據(jù)中心
+關(guān)注
關(guān)注
16文章
4813瀏覽量
72217 -
AI
+關(guān)注
關(guān)注
87文章
31139瀏覽量
269476 -
人工智能
+關(guān)注
關(guān)注
1792文章
47432瀏覽量
238975
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
《CST Studio Suite 2024 GPU加速計(jì)算指南》
NVIDIA加速全球大多數(shù)超級(jí)計(jì)算機(jī)推動(dòng)科技進(jìn)步

NVIDIA加速計(jì)算如何推動(dòng)醫(yī)療健康
NVIDIA 以太網(wǎng)加速 xAI 構(gòu)建的全球最大 AI 超級(jí)計(jì)算機(jī)

NVIDIA助力丹麥發(fā)布首臺(tái)AI超級(jí)計(jì)算機(jī)
海外HTTP安全挑戰(zhàn)與應(yīng)對(duì)策略
NVIDIA IGX平臺(tái)加速實(shí)時(shí)邊緣AI應(yīng)用
NVIDIA在加速計(jì)算和生成式AI領(lǐng)域的創(chuàng)新
浪潮信息趙帥:開放計(jì)算創(chuàng)新 應(yīng)對(duì)Scaling Law挑戰(zhàn)

HPE 攜手 NVIDIA 推出 NVIDIA AI Computing by HPE,加速生成式 AI 變革
NVIDIA推出NVIDIA AI Computing by HPE加速生成式 AI 變革
Cadence與NVIDIA聯(lián)合推出利用加速計(jì)算和生成式AI重塑設(shè)計(jì)
NVIDIA cuPQC幫助開發(fā)適用于量子計(jì)算時(shí)代的加密技術(shù)
NVIDIA 推出 Blackwell 架構(gòu) DGX SuperPOD,適用于萬億參數(shù)級(jí)的生成式 AI 超級(jí)計(jì)算






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論