") AMD和Intel叫板英偉達(dá),先后發(fā)布新芯片
AMD和Intel叫板英偉達(dá),先后發(fā)布新芯片
編者按:因?yàn)閾碛袕?qiáng)悍的GPU,英偉達(dá)在多個(gè)領(lǐng)域擁有強(qiáng)悍的競(jìng)爭(zhēng)力,這就吸引了更多的廠商進(jìn)去其專注的市場(chǎng),英特爾和AMD就虎視眈眈。
我們知道,Nvidia 并不是唯一一家創(chuàng)建了專門計(jì)算單元的公司,這些計(jì)算單元擅長(zhǎng)支持 AI 訓(xùn)練的矩陣數(shù)學(xué)和張量處理,并且可以重新用于運(yùn)行 AI 推理。英特爾已經(jīng)收購了兩家這樣的公司——Nervana Systems,緊隨其后的是 Habana Labs,這都是他們叫板Nvidia 的 “武器”。
英特爾是一家優(yōu)秀的公司,正在追逐該公司認(rèn)為在未來五年內(nèi)將產(chǎn)生 500 億美元的人工智能計(jì)算機(jī)會(huì)(用于訓(xùn)練和推理),從現(xiàn)在到 2027 年以 25% 的復(fù)合年增長(zhǎng)率增長(zhǎng),以達(dá)到這一水平。鑒于“Ponte Vecchio”Xe HPC GPU 加速器中的大量矩陣和矢量數(shù)學(xué),以及即將推出的“Sapphire Rapids”Xeon SP CPU 中的 AMX 矩陣數(shù)學(xué)單元中很可能有足夠的推理能力,有理由想知道有多少英特爾預(yù)計(jì)出售的Gaudi訓(xùn)練和Goya 推理芯片。
我們知道,英特爾在 2016 年 8 月完成 3.5 億美元的 Nervana Systems 交易和 2019 年 12 月以 20 億美元收購 Habana Labs時(shí),是在追求知識(shí)產(chǎn)權(quán)和人才,當(dāng)然,因?yàn)檫@就是這場(chǎng) IT 戰(zhàn)爭(zhēng)的打法,但我們一直想知道如果這些設(shè)備以及來自競(jìng)爭(zhēng)對(duì)手 GraphCore、Cerebras、SambaNova Systems 和 Groq 的非常優(yōu)雅和有趣的設(shè)計(jì)能夠部署在類似于主流的東西中。私募股權(quán)投資者一直渴望搭上這輛 AI 芯汁列車,并進(jìn)行了大量投資,上述四家公司迄今共籌集了 28.7 億美元。
陪審團(tuán)仍未出局,所有這些產(chǎn)品都剛剛起步,這就是為什么英特爾在 Nervana 和 Habana 上對(duì)沖它的賭注,就像它對(duì)數(shù)據(jù)中心中的 FPGA 感到害怕(主要?dú)w功于 Microsoft Azure)并于2015 年 6 月斥資 167 億美元收購 Altera。在 2015 年到 2020 年間,當(dāng)英特爾在數(shù)據(jù)中心計(jì)算領(lǐng)域占據(jù)主導(dǎo)地位時(shí),它試圖通過 Xeon CPU 計(jì)算來消除對(duì)其霸權(quán)地位的所有可能威脅,并且它有能力購買一些競(jìng)爭(zhēng)對(duì)手。
現(xiàn)在,既然它想起了自己需要再次成為代工廠,它就不能再做出如此昂貴的進(jìn)攻演習(xí)了,這些進(jìn)攻實(shí)際上既是防守又是進(jìn)攻。現(xiàn)在是時(shí)候嘗試將其支付給 Nervana 和 Habana 的部分錢賺回來了。目前尚不清楚英特爾是否能夠收回所有資金,即使它做出了 23.5 億美元的投資,但正如我們所說,也許這不是重點(diǎn)。也許關(guān)鍵是要對(duì) GraphCore、Cerebras、SambaNova Systems 和 Groq 進(jìn)行反駁,因?yàn)橛⑻貭栐谄?Xeon SP CPU 中添加了 AI 功能,并在今年推出了其獨(dú)立 GPU。(Wave Computing 籌集了 2.033 億美元用于開發(fā)其 AI 芯片,于 2020 年 4 月破產(chǎn),一年后成為 MIPS 芯片技術(shù)的供應(yīng)商,因此我們不再將其視為 AI 芯片的競(jìng)爭(zhēng)者。)
在本周舉行的 Intel Vision 2022 大會(huì)上,Gaudi2 AI 訓(xùn)練芯片是這家芯片制造商推出的新的大型計(jì)算引擎,順便說一下,它并不是英特爾實(shí)際制造的芯片,而是與其前身Gaudi1一樣,由競(jìng)爭(zhēng)對(duì)手臺(tái)積電制造。
與 Nervana Systems 一樣,Habana Labs 非常認(rèn)真地創(chuàng)建了一組芯片,為 AI 工作負(fù)載提供最佳性價(jià)比和最佳性能。Habana Goya HL-1000 推理芯片于 2019 年初發(fā)布,Gaudi1 AI 訓(xùn)練芯片,也稱為 HL-2000,于當(dāng)年夏天晚些時(shí)候首次亮相。
Gaudi1 架構(gòu)有一個(gè)通用矩陣乘法 (GEMM) 前端,后端有 10 個(gè)張量處理器內(nèi)核或 TPC,該芯片僅向用戶公開了其中的 8 個(gè),以幫助提高封裝的良率。(顯然,在英特爾收購 Habana Labs 后的某個(gè)時(shí)候,額外的兩個(gè)張量核心暴露出來了。)
Gaudi1 使用了第二代 TPC,而 Goya HL-1000 AI 推理芯片使用了不那么強(qiáng)大和不那么復(fù)雜的原始 TPC 設(shè)計(jì)。Gadui1 芯片中的 TPC 可使用 C 編程語言直接尋址,具有張量尋址,并支持 BF16 和 FP32 浮點(diǎn)以及 INT8、INT16 和 INT32 整數(shù)格式。TPC 指令集具有加速 Sigmoid、GeLU、Tanh 和其他特殊功能的電路。
Gaudi1 采用 TSMC 的 16 納米工藝實(shí)現(xiàn),具有 24 MB 片上 SRAM、四組 HBM2 內(nèi)存,容量為 32 GB,帶寬為 1 TB/秒。Gaudi1 插入 PCI-Express 4.0 x16 插槽并消耗 350 瓦的電量,并將幾乎所有的電量都轉(zhuǎn)化為熱量,就像芯片一樣。(少量能量用于操作和存儲(chǔ)信息。)
一個(gè)由 8 個(gè) Gaudi2 服務(wù)器組成的集群,每個(gè)服務(wù)器有 8 個(gè) Gaudi2 卡。
英特爾尚未透露對(duì) Gaudi2 架構(gòu)的深入了解,但這就是我們所知道的。
借助 Gaudi2,英特爾正在轉(zhuǎn)向臺(tái)積電的 7 納米工藝,隨著這種微縮,它能夠?qū)⑿酒系?TPC 數(shù)量從 10 個(gè)增加到 24 個(gè),并增加了對(duì) Nvidia 新的 8 位 FP8 數(shù)據(jù)格式的支持。使用 FP8 格式,開發(fā)者現(xiàn)在可以擁有相同格式的低分辨率推理數(shù)據(jù)和高分辨率訓(xùn)練數(shù)據(jù),并且在從訓(xùn)練轉(zhuǎn)移到推理時(shí)不必在浮點(diǎn)和整數(shù)之間轉(zhuǎn)換模型。這對(duì) AI 來說是一個(gè)真正的福音,盡管較低精度的整數(shù)格式可能會(huì)在矩陣和矢量計(jì)算引擎中保留多年,以支持遺留代碼和其他類型的應(yīng)用程序。
Gaudi2 芯片有 48 MB 的 SRAM——如果它與 TPC 數(shù)量成線性比例,您會(huì)期望 2.4 倍而不是 2 倍的 SRAM,或 57.6 MB。
掛在 Gaudi2 芯片上的是 HBM2e 內(nèi)存組,它提供 2.45 TB/秒的帶寬,是 Gaudi1 芯片的 2.45 倍。HBM2e 內(nèi)存組的數(shù)量沒有透露,但 Gaudi2 有 6 個(gè) 16 GB HBM2e 組,而 Gaudi1 有 4 個(gè) 8 GB HBM2 組。僅增加兩個(gè) HBM2e 內(nèi)存控制器就可以將帶寬提高 1.33 倍,而剩余的帶寬增加來自于提高內(nèi)存速度。
Gaudi1 芯片有十個(gè)支持 RoCE 直接內(nèi)存訪問協(xié)議的 100 Gb/秒以太網(wǎng)端口——事實(shí)證明,每個(gè) TPC 一個(gè),但我們當(dāng)時(shí)并不知道,因?yàn)橹伙@示了八個(gè)。但 Gaudi2 有 24 個(gè)以太網(wǎng)端口,以 100 Gb/秒的速度運(yùn)行,每個(gè) TPC 也有一個(gè)。它的功率為 650 瓦。我們假設(shè)該設(shè)備插入 PCI-Express 5.0 插槽,但英特爾尚未證實(shí)這一點(diǎn)。
假設(shè)沒有重大的架構(gòu)變化和工藝從 16 納米縮小到 7 納米并沒有帶來時(shí)鐘速度適度提升,我們預(yù)計(jì) Gaudi2 芯片將提供大約 2.5 倍的 Gaudi2 性能。(還假設(shè)任何給定應(yīng)用程序的處理精度相同。)但英特爾實(shí)際上并沒有說明是否有任何架構(gòu)變化(除了添加了一些媒體處理功能)以及時(shí)鐘速度如何變化,所以我們有來推斷。
我們通過查看這張關(guān)于 ResNet-50 機(jī)器視覺訓(xùn)練操作的圖表來做到這一點(diǎn),該圖表將 Gaudi1 和 Gaudi2 與過去兩代 Nvidia GPU 加速器進(jìn)行對(duì)比:
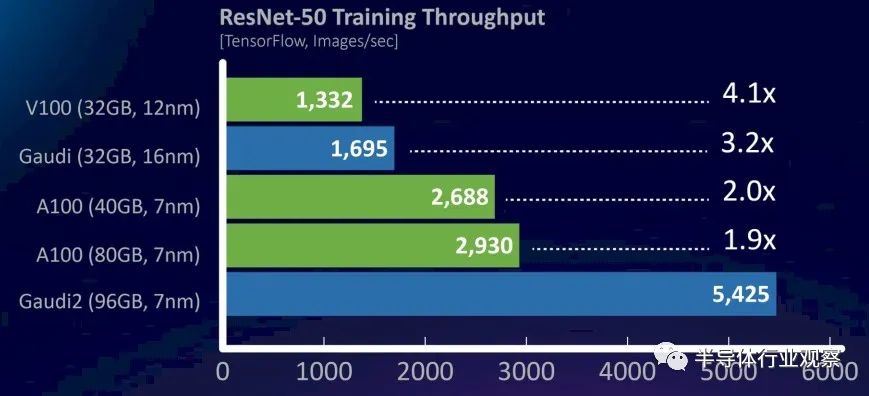
根據(jù)這個(gè) ResNet-50 比較,Gaudi2 的性能是 Gaudi1 的 3.2 倍,但很難估計(jì)性能有多少是由于芯片容量的增加。這個(gè)特定的測(cè)試運(yùn)行 TensorFlow 框架來進(jìn)行圖像識(shí)別訓(xùn)練,顯示的數(shù)據(jù)是每秒處理的圖像數(shù)量。
沒有顯示但很重要的一件事是 Gaudi2 加速器將如何疊加到 Hopper GPU,但 Nvidia 尚未透露任何特定測(cè)試的性能結(jié)果。但由于 H100 中的 HBM3 內(nèi)存運(yùn)行速度比 A100 加速器中使用的 HBM2e 內(nèi)存快 1.5 倍,而 FP16、TF32 和 FP64 在新張量核心上提供 3 倍的性能,因此可以合理地預(yù)期 H100 將提供介于在 ResNet-50 視覺訓(xùn)練工作負(fù)載上的性能是 1.5 倍和 3 倍,因此 H100 在 ResNet-50 測(cè)試中每秒可提供 4,395 到 8,790 張圖像的性能。我們的猜測(cè)是,它將比前者更接近后者,并且比英特爾可以通過 Gaudi2 提供的優(yōu)勢(shì)有相當(dāng)大的優(yōu)勢(shì)。
與使用 BERT 模型的自然語言處理相比,圖像識(shí)別和視頻處理相對(duì)容易。以下是 Gaudi2 與 Nvidia V100 和 A100 的對(duì)比,請(qǐng)注意 Gaudi1 的缺失:
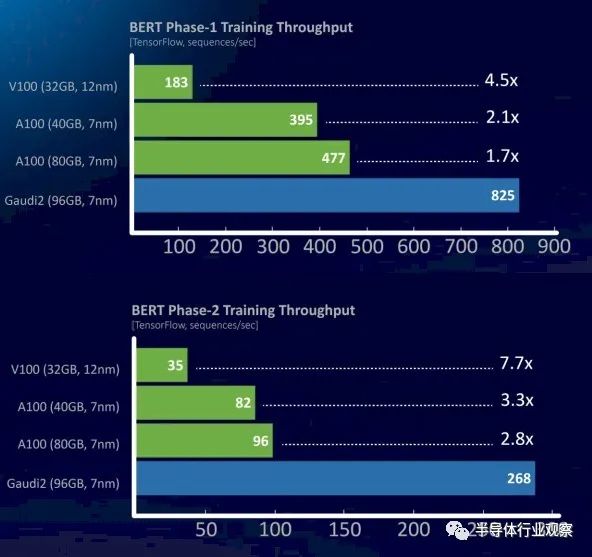
BERT 模型也在 TensorFlow 框架之上運(yùn)行,該數(shù)據(jù)顯示了在兩個(gè)不同的訓(xùn)練階段中每秒吞吐量的序列數(shù)。Habana Labs 部門的首席商務(wù)官 Eitan Medina 在一次簡(jiǎn)報(bào)中表示,Gaudi2 的性能幾乎是 A100 的 2 倍。但 H100 擁有自己的 FP8 格式和 Transformer 引擎,可以動(dòng)態(tài)地改變 AI 訓(xùn)練工作流程不同部分的數(shù)據(jù)和處理精度,可以做得更好。我們不知道多少,但我們強(qiáng)烈懷疑 Nvidia 至少可以縮小與 Gaudi2 的差距,并且很有可能超越它。
為了讓事情變得有趣,英特爾在 Amazon Web Services 上啟動(dòng)了 DL1 Gaudi1 實(shí)例,然后分別基于 A100 和 V100 GPU 啟動(dòng)了 p4d 和 p3 實(shí)例,并進(jìn)行了一些性價(jià)比分析以計(jì)算在 ResNet 中識(shí)別的每張圖像的成本-50 基準(zhǔn)。看看這個(gè):
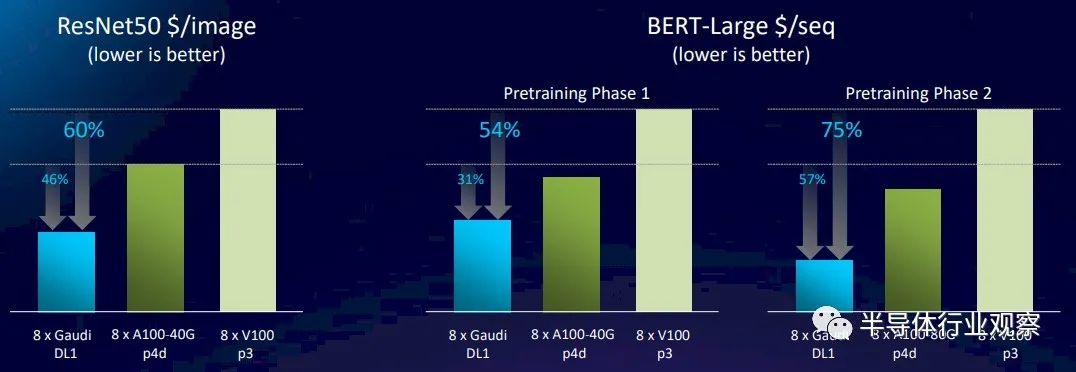
這張圖表的意思是,Gaudi1 的性能略好于 V100——使用英特爾在上圖中針對(duì) ResNet-50 的性能數(shù)據(jù)顯示了 27.3%——而且性價(jià)比高了大約 60%,這意味著 DL1 實(shí)例的成本大大低于使用 V100 的 p3 實(shí)例。隨著遷移到具有 40 GB HBM2e 內(nèi)存的基于 A100 的 p4d 實(shí)例,Nvidia 設(shè)備在 ResNet-50 上的吞吐量比 Gaudi1 高 58.6%,但 Gaudi1 處理每個(gè)圖像的成本降低了 46%。這意味著 A100 實(shí)例確實(shí)要貴一些。如果我們對(duì) Hopper GPU 加速器定價(jià)的猜測(cè)是正確的,而 Nvidia 對(duì)大約 3 倍的性能收取大約 2 倍的費(fèi)用,英特爾將不得不將出售給 AWS 的 Gaudi2 芯片的價(jià)格保持在 AWS 仍然可以顯示出比運(yùn)行 AI 訓(xùn)練的 H100 實(shí)例更好的性價(jià)比的地方。
而在這一切中,Trainium 在哪里?
無論如何,英特爾在其實(shí)驗(yàn)室中運(yùn)行了超過 1,000 個(gè) Gaudi2,因此它可以調(diào)整 SynapseAI 軟件堆棧,其中包括在 Habana 的圖形編譯器、內(nèi)核庫和通信庫上運(yùn)行的 PyTorch 和 TensorFlow 框架。值得一提的是,Gaudi2 芯片現(xiàn)已發(fā)貨。
除了 Gaudi2 芯片,英特爾還在預(yù)覽其 Goya 后續(xù)的 Greco 推理引擎,該引擎也在臺(tái)積電制造。

Greco 推理卡具有 16 GB 的 LPDDR5 主內(nèi)存,提供 204 GB/秒的內(nèi)存帶寬,而之前的 Goya 推理引擎使用 16 GB 的 DDR4 內(nèi)存塊提供 40 GB/秒的內(nèi)存帶寬。Habana 架構(gòu)的這種 Greco 變體支持 INT4、BF16 和 FP16 格式,功耗為 75 瓦,大大低于 2019 年初宣布的 HL-1000 設(shè)備的 200 瓦。如上圖所示,它被壓縮到更緊湊的半高、半長(zhǎng) PCI-Express 卡。目前還沒有關(guān)于這款產(chǎn)品的性能或價(jià)格的消息。
除了英特爾以外,AMD也更新了GPU產(chǎn)品線,以挑戰(zhàn)英偉達(dá)。
AMD 發(fā)布 Radeon RX 6950 XT、6750 XT 和 6650 XT
AMD 今天早上揭開了三款新的 Radeon RX 6000 系列顯卡的面紗,以完善其產(chǎn)品堆棧。新的產(chǎn)品涵蓋了從中端到旗艦市場(chǎng)的所有市場(chǎng),其中, Radeon RX 6950 XT、RX 6750 XT 和 RX 6650 XT 將作為 Radeon 系列的中代產(chǎn)品發(fā)布,為 AMD 最重要的顯卡提供最后的性能提升. 利用更新的 18Gbps GDDR6 內(nèi)存以及略微改進(jìn)的時(shí)鐘速度,今天發(fā)布的新卡承諾適度的性能提升,同時(shí)讓 AMD 有機(jī)會(huì)展示他們的 RDNA2 GPU 架構(gòu)在經(jīng)過近 18 個(gè)月的改進(jìn)后可以做什么。
從高層次上看,這三款新卡都是對(duì) AMD 現(xiàn)有 Radeon RX 6900 XT、RX 6700 XT 和 RX 6600 XT 部件的小更新。為了利用 18Gbps GDDR6 不斷增加的可用性,AMD 選擇將其配備到 RX 6000 系列中的三款最重要的卡上,以便為它們提供適度的內(nèi)存帶寬提升。與此同時(shí),AMD 也在利用這個(gè)機(jī)會(huì)來提高性能——無論是形象上還是字面上——稍微提高顯卡的 TDP 以允許稍微更高的 GPU 時(shí)鐘速度。
如前所述,整體變化很小,無論是在性能還是卡片構(gòu)造方面。除了換成 18Gbps GDDR6 內(nèi)存外,這些更新的規(guī)格都可以通過當(dāng)前的卡設(shè)計(jì)來實(shí)現(xiàn),并且沒有其他硬件變化。與此同時(shí),AMD 自己對(duì)新卡性能提升的估計(jì)約為 5% 到 6%——內(nèi)存帶寬的增加受到 GPU 時(shí)鐘速度的小幅提升的影響。
盡管如此,對(duì)于 AMD 來說,這是一個(gè)進(jìn)一步提高他們?cè)谝恍┳钪匾囊曨l卡上的競(jìng)爭(zhēng)定位的機(jī)會(huì)。在當(dāng)前這一代顯卡的最后六個(gè)月左右,領(lǐng)先于 NVIDIA。NVIDIA 早就展示了他們自己的中代產(chǎn)品,如 3080Ti/3070TI 和 3080 12GB,因此 AMD 獲得了可能成為最后一步的優(yōu)勢(shì)(至少在性能上層) 。
更新的 Radeon RX 6000 產(chǎn)品堆棧:擴(kuò)展和退役
這一切發(fā)生的時(shí)機(jī)確實(shí)讓 AMD 無意中抓住了一把落下的刀,然而,在經(jīng)歷了 18 個(gè)月的挫折之后,顯卡市場(chǎng)終于回歸常態(tài)。由于加密貨幣挖礦盈利能力大幅下降且供應(yīng)情況有所改善,零售視頻卡價(jià)格正在接近其最初的建議零售價(jià)。這對(duì)于游戲玩家、計(jì)算機(jī)科學(xué)家和其他任何想要以(更)合理的價(jià)格購買顯卡的人來說都是個(gè)好消息,但對(duì)于 AMD 在嘗試定價(jià)和定位他們的新部件時(shí)會(huì)遇到更多問題。AMD 甚至在推出新卡之前就已經(jīng)需要重新定價(jià)一次,而現(xiàn)在這些被設(shè)計(jì)為優(yōu)質(zhì)、高價(jià)產(chǎn)品的卡將面臨更大的市場(chǎng)壓力。
除了將 RX 6950 XT、RX 6750 XT 和 RX 6650 XT 添加到 AMD 龐大的 Radeon RX 6000 系列產(chǎn)品堆棧之外,AMD 還利用這個(gè)機(jī)會(huì)淘汰了顯卡Radeon RX 6600 XT——原本最快的 Navi 23 卡,以及 AMD 中端顯卡努力的基石,最終將不復(fù)存在。該卡在市場(chǎng)上的地位正在被最快的 RX 6650 XT 所取代。

除此之外,RX 6900 XT 和 RX 6700 XT 將繼續(xù)生產(chǎn)。盡管最便宜的 6900XT 已經(jīng)達(dá)到 950 美元,但 AMD 及其合作伙伴可能很快就會(huì)發(fā)現(xiàn)自己不得不讓他們的新卡與其他產(chǎn)品堆棧一起降價(jià)。
順便說一句,我很高興看到 AMD 對(duì)這些新部件使用了合理的命名系統(tǒng)。將所有新卡指定為 xx50 可以很容易地判斷它們與現(xiàn)有卡有明顯的不同,并且可以很容易地判斷它們?cè)诟蟮漠a(chǎn)品堆棧中的位置。AMD 有 4 位數(shù)字,很高興看到 AMD 至少使用了 3 個(gè)數(shù)字,而不是添加更多的后綴或完全用多種變體重載產(chǎn)品名稱。
Radeon RX 6950 XT、RX 9750 XT 和 RX 6650 XT
深入了解規(guī)格,讓我們開始研究新卡。
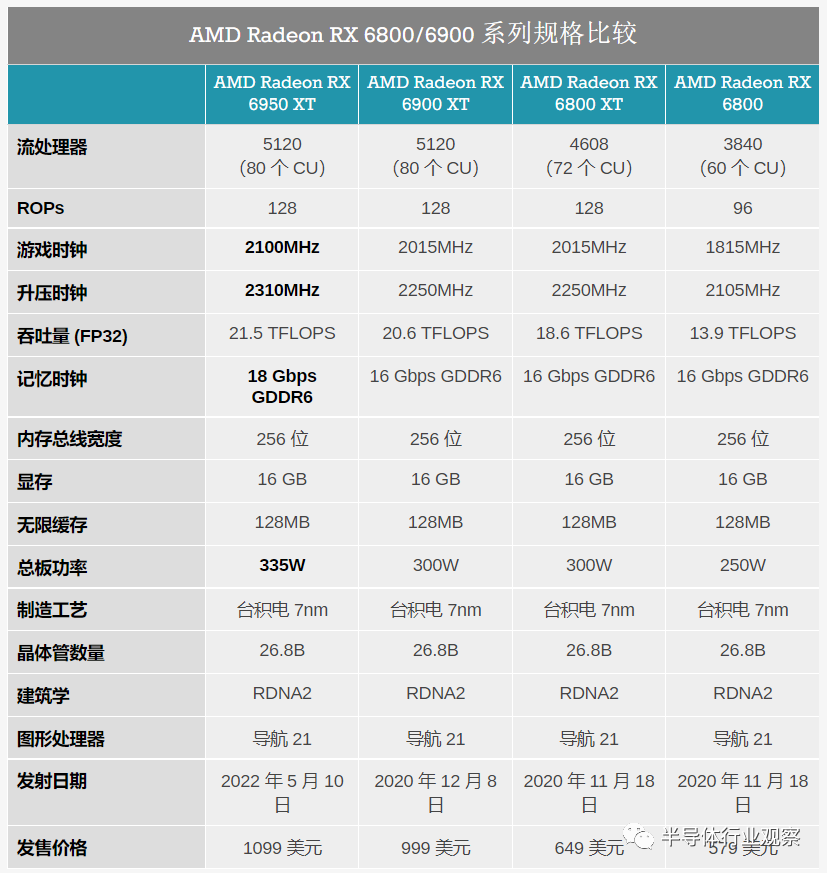
從頂部開始,我們擁有 AMD 的新旗艦 Radeon RX 6950 XT。這是原始 RX 6900 XT 的增強(qiáng)版,現(xiàn)在是 AMD 產(chǎn)品堆棧中功能最強(qiáng)大的顯卡,也是最昂貴的顯卡。

鑒于最初的 RX 6900 XT 已經(jīng)基于具有 40 個(gè) CU 和 128MB 無限緩存的完全啟用的 Navi 21 GPU,AMD 除了提高 GPU 和內(nèi)存時(shí)鐘速度之外,幾乎沒有其他途徑來提高性能,所以這正是他們的目標(biāo),且已經(jīng)完成了。
除了將顯卡與 16GB 最新的 18Gbps GDDR6 內(nèi)存配對(duì)外,顯卡的 GPU 時(shí)鐘速度也得到了提升;官方游戲時(shí)鐘現(xiàn)在是 2100MHz (+10%),最大加速時(shí)鐘是 2310MHz (+3%)。這使 RX 6950 XT 的內(nèi)存帶寬增加了 12.5%,并且整個(gè) GPU 本身的吞吐量平均提高了幾個(gè)百分點(diǎn)。
為了為這種改進(jìn)的性能買單,AMD 還提高了 TBP。最初的 RX 6900 XT 是 300W 卡,而 RX 6950 XT 在參考規(guī)格下是 335W 卡,董事會(huì)合作伙伴可以隨時(shí)進(jìn)一步提高。AMD 在這一點(diǎn)上處于電壓/頻率曲線的遠(yuǎn)端,雖然提高 TBP 確實(shí)可以通過讓卡更頻繁地接近其最大 GPU 時(shí)鐘速度來提高性能,但它們正在逐漸減少此時(shí)返回。所有這些都進(jìn)一步反映在 AMD 的官方性能數(shù)據(jù)中,RX 6950 XT 的著陸速度比原始的 RX 6900 快了約 4%。
關(guān)于這一點(diǎn),值得指出的是,新的 18Gbps GDDR6 也可能是這些新卡 TBP 增加的一個(gè)因素。雖然最新 GDDR6 的電壓保持在 1.35v,但由于支持如此高的信號(hào)速率的電力成本,總體功耗仍會(huì)上升。AMD 沒有正式公布其顯卡的 GPU 和 DRAM 功耗,但如果在所有其他條件相同的情況下,RX 6950 XT 的 DRAM 功耗比 RX 更高,我一點(diǎn)也不感到驚訝6900 XT。在這一點(diǎn)上,如果 AMD 無論如何都需要增加 TBP(以保持時(shí)鐘速度恒定),為什么不增加一點(diǎn)以從 GPU 本身中擠出一些額外的空間。
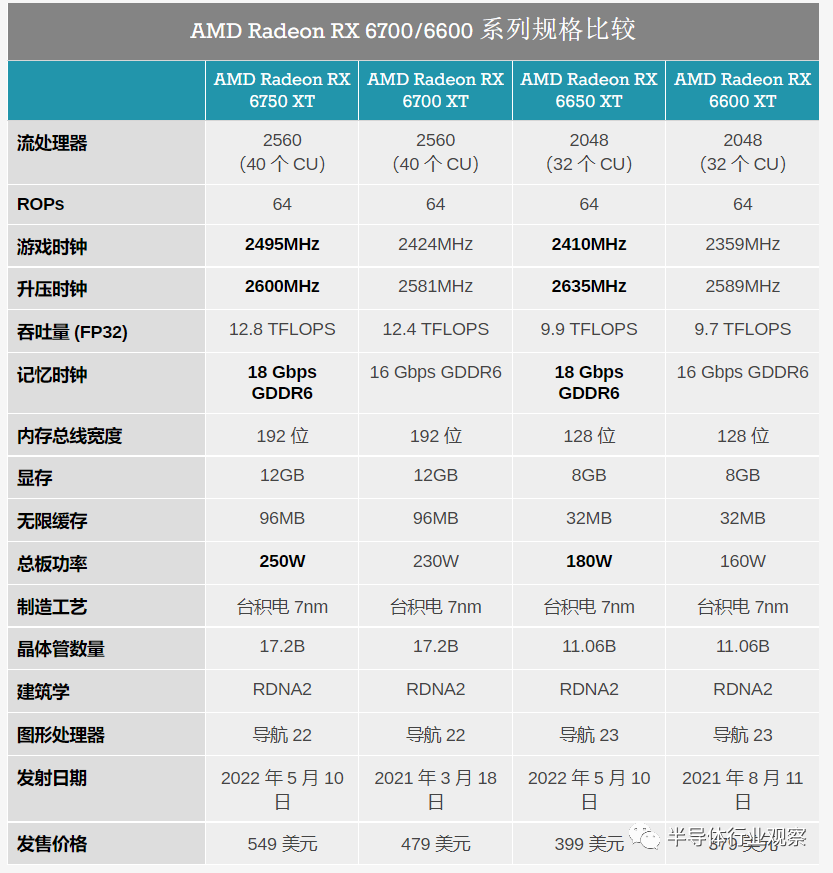
同時(shí),在 AMD Radeon 產(chǎn)品堆棧的中間位置,我們有 RX 6750 XT 和 RX 6650 XT。與 RX 6950 XT 一樣,這些卡的前身已經(jīng)基于完全啟用的 Navi GPU——分別為 Navi 22 和 Navi 23——因此 AMD 正在轉(zhuǎn)向提高時(shí)鐘速度以提高性能。

對(duì)于 RX 6750 XT,與最初的 RX 6700 XT 相比,其最大時(shí)鐘速度已提升至 2600MHz (+
同時(shí),RX 6650 XT 完全取代了原始的 RX 6600 XT,最大時(shí)鐘速度為 2635MHz,游戲時(shí)鐘為 2410MHz,兩者都比原始卡快 2% 左右。而且,盡管 TBP 增加了,內(nèi)存帶寬增加了 12.5%,但它在 AMD 的官方數(shù)據(jù)中顯示出最小的增益,只有 2% 的性能提升。在這種情況下,AMD 不保留原始的 RX 6600 XT 是可以理解的,因?yàn)?RX 6650 XT 的速度不夠快,無法將自己與舊卡有意義地分開。
一旦這些卡開始出貨,我們將看到第三方基準(zhǔn)測(cè)試如何發(fā)揮作用,但假設(shè) AMD 的數(shù)據(jù)在這里是準(zhǔn)確的,這證明了他們的片上 Infinity Cache 的價(jià)值。雖然內(nèi)存帶寬幾乎不會(huì)隨著 1 對(duì) 1 性能的提高而增加,但值得注意的是,額外帶寬所增加的性能是多么少 - 或者相反,Navi 23 GPU 已經(jīng)被 16Gbps GDDR6 在 128位內(nèi)存總線。即使只有 32MB 的緩存也在做大量工作來限制 1080p 的 DRAM 帶寬需求。
最后,與 RX 6950 XT 一樣,這兩張卡的 TBP 也在增加。RX 6750 XT 將搭載 250W 參考 TBP,比原始 RX 6700 XT 高 20W。同時(shí),RX 6650 XT 將調(diào)整為 180W,這也比其前身 RX 6600 XT 高 20W。
驅(qū)動(dòng)程序新聞:隱私視圖和 AMD 超級(jí)分辨率 1.1
在今天的產(chǎn)品公告中,還有一個(gè)關(guān)于 AMD 產(chǎn)品生態(tài)系統(tǒng)驅(qū)動(dòng)程序方面的簡(jiǎn)短更新。
AMD 的 GPU 加速隱私視圖功能,原定于第一季度推出,終于接近發(fā)布,應(yīng)該在本月的驅(qū)動(dòng)程序下降中。同時(shí),根據(jù) AMD 的說法,他們基于驅(qū)動(dòng)程序的 AMD 超分辨率技術(shù)的更新版本正在開發(fā)中。盡管此時(shí)他們沒有透露將針對(duì) Super Resolution 1.1 調(diào)整或添加哪些功能。
合作伙伴卡和產(chǎn)品定位
鑒于今天的發(fā)布是對(duì)一些 AMD 現(xiàn)有卡的相對(duì)較小的更新,AMD 及其董事會(huì)合作伙伴正在開始使用新卡。除了合作伙伴自己的工作外,AMD 還發(fā)布了 RX 6950 XT 和 RX 6750 XT 參考卡的更新版本。因此,喜歡 AMD 參考設(shè)計(jì)的游戲玩家——甚至只是直接從 AMD 購買——將能夠這樣做。

與此同時(shí),董事會(huì)合伙人將一如既往地做自己的事情。期望看到庫存時(shí)鐘和工廠超頻卡的通常組合,董事會(huì)合作伙伴希望從 AMD 的最新硬件中榨取更多。
除了今天發(fā)布的信息之外,AMD 并沒有向我們提供太多關(guān)于可用性的信息。但考慮到底層 GPU 的生產(chǎn)時(shí)間——以及最近幾周 6900XT/6700XT/6600XT 的可用性——這不應(yīng)該是一個(gè)特別瘋狂或供應(yīng)受限的發(fā)布。在過去的 18 個(gè)月之后,所有這些都是一個(gè)不錯(cuò)的變化。
盡管當(dāng)原始顯卡最終降到更合理的價(jià)格時(shí),整個(gè)顯卡市場(chǎng)對(duì)新的高價(jià) Radeon 顯卡有多大的胃口還有待觀察。由于 RX 6800 或 RX 6600 以外的任何產(chǎn)品的供應(yīng)在這一點(diǎn)上基本上不受限制,因此新卡的大部分價(jià)值來自其略高的性能,這意味著生態(tài)系統(tǒng)沒有太多回旋余地來提供更高的性能和價(jià)格。或許 AMD 已經(jīng)在采取進(jìn)一步措施來支撐視頻卡價(jià)格也就不足為奇了,包括即將推出的游戲捆綁優(yōu)惠,盡管它實(shí)際上還沒有上線,但它今天就開始了。
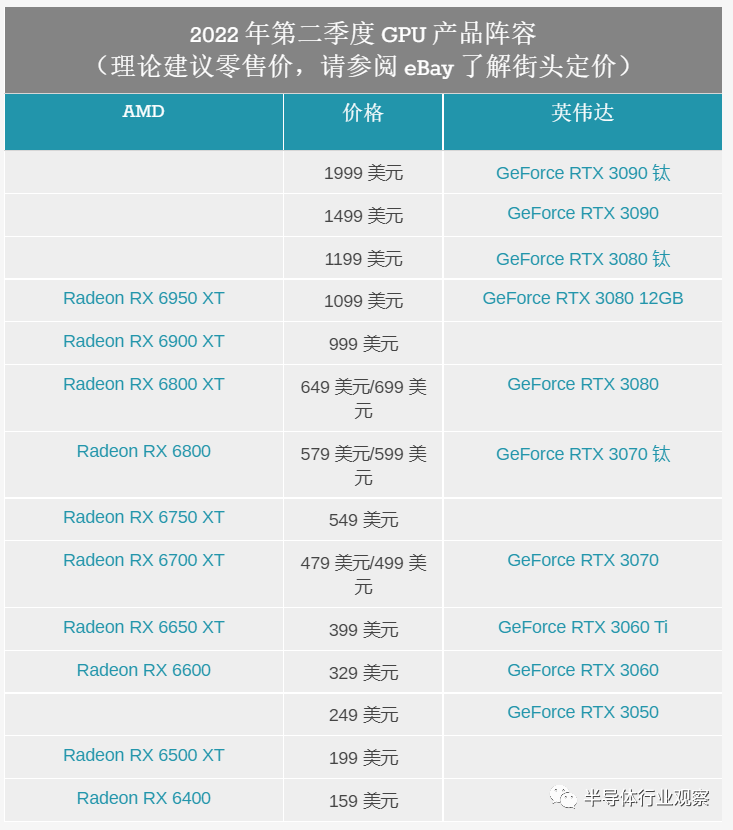
值得慶幸的是 ,AMD的競(jìng)爭(zhēng)對(duì)手不是他們自己,而是市場(chǎng)領(lǐng)導(dǎo)者 NVIDIA。盡管 GeForce 卡的價(jià)格也有所下降,但對(duì)挖礦更友好的卡的降價(jià)速度較慢,因此其中許多卡的售價(jià)仍然比原來的建議零售價(jià)高出不少。因此,AMD 擁有龐大且現(xiàn)在甚至更大的產(chǎn)品堆棧,可以與 NVIDIA 堆棧中的所有產(chǎn)品相媲美——而且就目前而言,它通常具有顯著的價(jià)格優(yōu)勢(shì)。
AMD 認(rèn)為它們也具有性能優(yōu)勢(shì),雖然我非常懷疑 RX 6950 XT 是否會(huì)始終勝過 RTX 3090(AMD 選擇的競(jìng)爭(zhēng)對(duì)手),但 RX 6750 XT 和 RX 6650 XT 相對(duì)于 NVIDIA 的基線表現(xiàn)更好分別是 RTX 3070 和 3060 卡。這次發(fā)布的重點(diǎn)之一是讓事情更上一層樓:讓 AMD 全力以赴,提供新的硬件素材來展示他們與 NVIDIA 的對(duì)比。

總結(jié)一下,期待今天早上在零售貨架上看到新的 Radeon 卡——如果不是更早的話。
編輯:黃飛
-
FPGA
+關(guān)注
關(guān)注
1630文章
21779瀏覽量
604902 -
amd
+關(guān)注
關(guān)注
25文章
5485瀏覽量
134409 -
intel
+關(guān)注
關(guān)注
19文章
3483瀏覽量
186243 -
機(jī)器視覺
+關(guān)注
關(guān)注
162文章
4400瀏覽量
120526 -
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3824瀏覽量
91591
原文標(biāo)題:AMD和Intel發(fā)新芯片,再次挑戰(zhàn)英偉達(dá)
文章出處:【微信號(hào):AI_Architect,微信公眾號(hào):智能計(jì)算芯世界】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
AMD最強(qiáng)AI芯片,性能強(qiáng)過英偉達(dá)H200,但市場(chǎng)仍不買賬,生態(tài)是最大短板?

荷蘭與英偉達(dá)、AMD商討AI設(shè)施建設(shè)
荷蘭與英偉達(dá)、AMD商討共建人工智能設(shè)施

加速拋棄英偉達(dá),微軟又發(fā)布一顆芯片 #微軟 #英偉達(dá) #半導(dǎo)體 #芯片 #電路知識(shí)
AMD發(fā)布英偉達(dá)競(jìng)品AI芯片,預(yù)期市場(chǎng)規(guī)模將大幅增長(zhǎng)
英偉達(dá)Blackwell芯片量產(chǎn)加速,Q4預(yù)計(jì)出貨達(dá)45萬片
英偉達(dá)回應(yīng)AI芯片推遲發(fā)布傳聞






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論