 基于激光雷達的全稀疏3D物體檢測器
基于激光雷達的全稀疏3D物體檢測器
介紹一下我們組前段時間的一個微小工作

Fully Sparse 3D Object Detection (NeurIPS 2022)
Authors:Lue Fan,王峰, 王乃巖,Zhaoxiang Zhang
論文:https://arxiv.org/abs/2207.10035
代碼已經開源在:
https://github.com/tusen-ai/SST
長話短說,我們提出了一種基于激光雷達的全稀疏3D物體檢測器,在Waymo數據集和Argoverse 2數據集上都達到了不錯的精度和速度。下面是一個簡要的介紹。
一、導言
目前以SECOND,PointPillars以及CenterPoint為代表的主流一階段點云物體檢測器都或多或少依賴致密特征圖(dense feature map)。這些方法基本都會把稀疏體素特征“拍成“dense BEV feature map。這樣做可以沿用2D檢測器的很多套路,取得了非常不錯的性能。但是由于dense feature map的計算量和檢測范圍的平方成正比,使得這些檢測器很難scale up到大范圍long-range檢測場景中。比如新出的Argoverse 2數據集具有[-200, 200] x [-200, 200]的理論檢測范圍,比常用的不超過[-75. 75] x [-75, 75]的范圍大了許多。于是便引出了本文想解決的一個痛點問題:
如何去掉這些dense feature map,把檢測器做成fully sparse的,以此高效地實現 long-range LiDAR detection?
這里補一句:全稀疏其實并不是一個新概念,在點云物體檢測發展的早期,以PointRCNN為代表的眾多純point-based 方法天生就是全稀疏的。但由于Neighborhood query和FPS的存在,純point-based方法在大規模點云數據上的效率不是很理想。這就導致純point-based方法在點云規模較大的benchmark上性能表現不佳(沒辦法用較大的模型和分辨率。)
而去掉dense feature map的一個直接問題就是會導致物體中心特征的缺失(center feature missing)。這是由于點云常常分布在物體的側表面,對于大物體尤其如此。在dense detector中,多層的卷積會把物體邊緣的有效特征擴散到物體中心,因此這些檢測器不存在直接的中心特征缺失問題,可以使用已被證明非常有效的center assignment。下圖展示了特征擴散的過程:
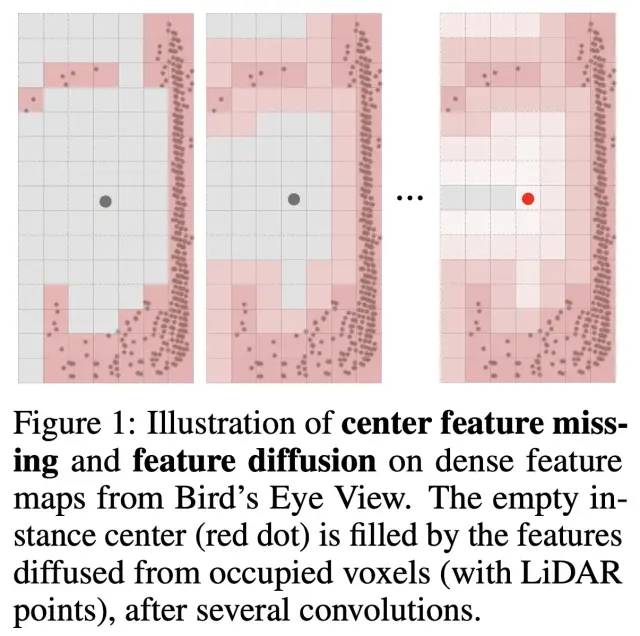
為了解決在全稀疏結構下中心特征缺失的問題,我們有一個基本想法:
既然中心特征缺失了,那么就不依靠中心特征做預測,而是依靠物體整體的有效特征做預測。
二、方法
順著上面的基本想法,一個具體的思路就是先把物體分割出來,再將物體當作一個整體,并用稀疏的方式提取特征。第一步的分割在全稀疏的結構下很好實現,接下來物體特征的提取也可以通過眾多成熟的point-based方法實現。那么我們的方法就呼之欲出了:
sparse voxel encoder作為backbone和segmentor來分割物體并預測每個點所對應的物體中心
對預測出來的眾多中心點進行聚類,得到一個一個的instance。這一步類似VoteNet,但我們采用了connected component labeling的方式來聚類,這一點其實對大物體性能挺重要的。
對于每一個instance用稀疏的方式提取整體特征,并進行該instance外接框的reasoning。
前兩步都很簡單直接,但第三步稍有麻煩。對instance提取特征最常用的選擇就是在instance內部做point-based operation, 但是之前提到這類方法效率較低。因此我們試圖規避其中諸如neighborhood query和FPS這種比較耗時的操作。我們的想法是,既然已經得到了一個個instance,何不直接將instance作為一個一個獨立neighborhood group,扔掉進一步的ball query或者KNN操作。
這樣做實質上是把instance當成了“voxel”來處理,因為instance和voxel本質上都屬于對整個點云的一種non-overlapping劃分。那么我們就可以直接套用提取單個體素特征那一套方案來提取instance特征,比如Dynamic VFE。具體而言,就是對instance內的每個點做MLP,再做instance-wise的pooling得到instance feature。instance feature又可以重新assign到instance內部的每個point上,這一過程可以不斷重復。這本質上是多個簡單的PointNet疊加,也可以換成其他更強力的操作。值得強調的是,由于3D空間里instance之間天然不會重疊(正如同voxel),以上的pooling操作可以通過torch中scatter operation來高效地動態實現(無需對每個組進行padding或者設置點數上限)。
得到最終的instance feature之后,直接預測對應instance的外接框和類別即可,我們將整個對instance進行處理的模塊稱之為 Sparse Instance Recognition (SIR)。
方法總體框架如下圖所示:
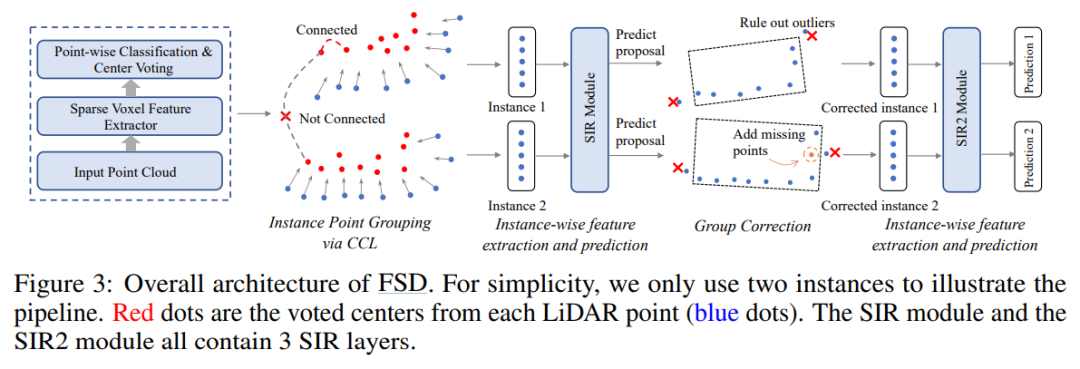
Overall Pipeline
這其中還包含著一些后續操作,比如對重新分割出比聚類得到的更準確的instance,感興趣的讀者可以查看原文。
三、結果
提出的方法在Waymo的單幀單模型標準賽道上達到了SOTA的性能
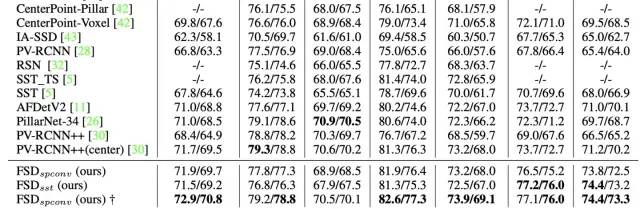
Waymo validation 上的性能,截圖不全,感興趣的讀者可查看原論文
同時也在新出的Argoverse 2數據集上超越了主流的CenterPoint(雖然還沒幾個人刷。。)。
值得多提一嘴的是我們的方法在長距離檢測上有巨大的效率優勢,如下圖所示
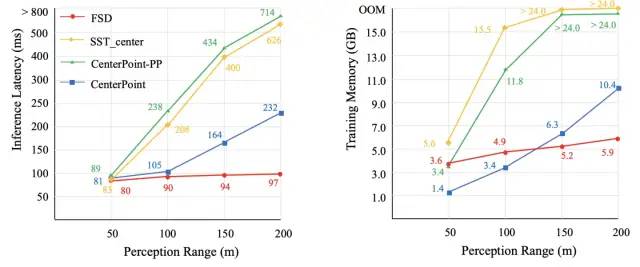
這是用SST backbone測的,用SparseConv的backbone效果更佳
四、一些特性
我們的方法不受sparse backbone的類型限制,比如文中我們就使用了sparse transformer和sparse conv兩種結構。這一點使得FSD可以作為sparse backbone方面研究的一個strong baseline。
該方法雖然暫時聚焦在檢測任務,但已經有了multi task的影子,可以把segmentation和detection一體化。
前向速度很快,再加上收斂也極快,Waymo上訓練6個epoch就可以達到準sota水平。這在8 x 3090上只需要不到半天時間,其他方法達到相同性能可能需要至少2天的訓練時間。這應該會給大家的快速實驗迭代提供很大便利。
我們相信稀疏化是將來的一個趨勢。在很多場景下,sparse feature都比相比笨重的dense feature map具有更高的可操作性和靈活性,歡迎大家試用我們的模型。
審核編輯 :李倩
-
檢測器
+關注
關注
1文章
868瀏覽量
47736 -
激光雷達
+關注
關注
968文章
4003瀏覽量
190158
原文標題:NeurIPS 2022 | 中科院&圖森未來提出FSD:全稀疏的3D目標檢測器
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
禾賽科技CES 2025發布迷你型超半球3D激光雷達JT系列
禾賽科技推出面向機器人領域的迷你3D激光雷達
全場景適用!TS Spectrum高速數字化儀在激光雷達系統中的應用

激光雷達技術或可助力防御無人機

激光雷達在SLAM算法中的應用綜述
產品介紹 滿足功能安全認證要求:SIL 2安全防護型激光雷達GS1-5
激光雷達技術的基于深度學習的進步
TS高速數字化儀在激光雷達系統中的應用

晶振在激光雷達系統中的作用有哪些
Hokuyo Automatic發布新款3D激光雷達(LiDAR)傳感器YLM-10LX
機載單光子激光雷達系統用于實現高分辨率3D成像
LG Innotek發布高性能激光雷達,可檢測250米外物體
大陸集團的3D Flash激光雷達有何優勢?

激光雷達LIDAR基本工作原理






 工商網監
工商網監
評論