 為什么NGINX的reload命令不是熱加載?
為什么NGINX的reload命令不是熱加載?
作者 劉維
這段時間在 Reddit 看到一個討論,為什么 NGINX 不支持熱加載?乍看之下很反常識,作為世界第一大 Web 服務器,不支持熱加載?難道大家都在使用的 nginx -s reload 命令都用錯了?帶著這個疑問,讓我們開始這次探索之旅,一起聊聊熱加載和 NGINX 的故事。
NGINX 相關介紹
NGINX 是一個跨平臺的開源 Web 服務器,使用 C 語言開發。據統計,全世界流量最高的前 1000 名網站中,有超過 40% 的網站都在使用 NGINX 處理海量請求。
NGINX 有什么優勢,導致它從眾多的 Web 服務器中脫穎而出,并一直保持高使用量呢?
我覺得核心原因在于,NGINX 天生善于處理高并發,能在高并發請求的同時保持高效的服務。相比于同時代的其他競爭對手例如 Apache、Tomcat 等,其領先的事件驅動型設計和全異步的網絡 I/O 處理機制,以及極致的內存分配管理等眾多優秀設計,將服務器硬件資源壓縮到了極致。使得 NGINX 成為高性能 Web 服務器的代名詞。
當然,除此之外還有一些其他原因,比如:
高度模塊化的設計,使得 NGINX 擁有無數個功能豐富的官方模塊和第三方拓展模塊。
最自由的 BSD 許可協議,使得無數開發者愿意為 NGINX 貢獻自己的想法。
支持熱加載,能保證 NGINX 提供 7x24h 不間斷的服務。
關于熱加載
大家期望的熱加載功能是什么樣的?我個人認為,首先應該是用戶端無感知的,在保證用戶請求正常和連接不斷的情況下,實現服務端或上游的動態更新。
那什么情況下需要熱加載?在如今云原生時代下,微服務架構盛行,越來越多的應用場景有了更加頻繁的服務變更需求。包括反向代理域名上下線、上游地址變更、IP 黑白名單更新等,這些都和熱加載息息相關。
那么 NGINX 是如何實現熱加載的?
NGINX 熱加載的原理
執行 nginx -s reload 熱加載命令,就等同于向 NGINX 的 master 進程發送 HUP 信號。在 master 進程收到 HUP 信號后,會依次打開新的監聽端口,然后啟動新的 worker 進程。
此時會存在新舊兩套 worker 進程,在新的 worker 進程起來后,master 會向老的 worker 進程發送 QUIT 信號進行優雅關閉。老的 worker 進程收到 QUIT 信號后,會首先關閉監聽句柄,此時新的連接就只會流進到新的 worker 進程中,老的 worker 進程處理完當前連接后就會結束進程。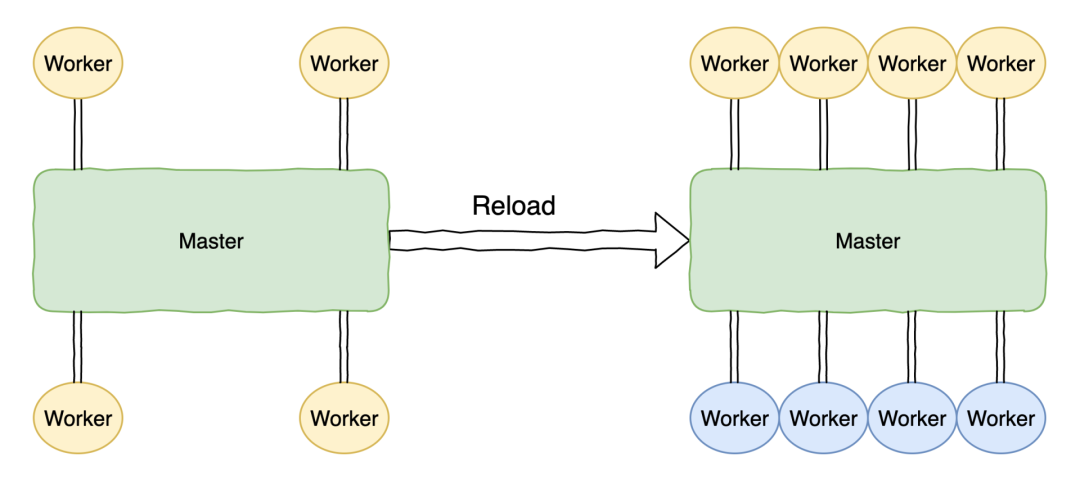
從原理上看,NGINX 的熱加載能很好地滿足我們的需求嗎?答案很可能是否定的,讓我們來看下 NGINX 的熱加載存在哪些問題。
NGINX 熱加載的缺陷
首先,NGINX 頻繁熱加載會造成連接不穩定,增加丟失業務的可能性。
NGINX 在執行 reload 指令時,會在舊的 worker 進程上處理已經存在的連接,處理完連接上的當前請求后,會主動斷開連接。此時如果客戶端沒處理好,就可能會丟失業務,這對于客戶端來說明顯就不是無感知的了。
其次,在某些場景下,舊進程回收時間長,進而影響正常業務。
比如代理 WebSocket 協議時,由于 NGINX 不解析通訊幀,所以無法知道該請求是否為已處理完畢狀態。即使 worker 進程收到來自 master 的退出指令,它也無法立刻退出,而是需要等到這些連接出現異常、超時或者某一端主動斷開后,才能正常退出。
再比如 NGINX 做 TCP 層和 UDP 層的反向代理時,它也沒法知道一個請求究竟要經過多少次請求才算真正地結束。
這就導致舊 worker 進程的回收時間特別長,尤其是在直播、新聞媒體活語音識別等行業。舊 worker 進程的回收時間通常能達到半小時甚至更長,這時如果再頻繁 reload,將會導致 shutting down 進程持續增加,最終甚至會導致 NGINX OOM,嚴重影響業務。
# 一直存在舊 worker 進程: nobody 6246 6241 0 10:51 ? 0000 nginx: worker process nobody 6247 6241 0 10:51 ? 0000 nginx: worker process nobody 6247 6241 0 10:51 ? 0000 nginx: worker process nobody 6248 6241 0 10:51 ? 0000 nginx: worker process nobody 6249 6241 0 10:51 ? 0000 nginx: worker process nobody 7995 10419 0 10:30 ? 0037 nginx: worker process is shutting down <= here nobody 7995 10419 0 10:30 ? 0037 nginx: worker process is shutting down nobody 7996 10419 0 10:30 ? 0037 nginx: worker process is shutting down
從上述內容可以看到,通過nginx -s reload方式支持的“熱加載”,雖然在以往的技術場景中夠用,但是在微服務和云原生迅速發展的今天,它已經捉襟見肘且不合時宜。
如果你的業務變更頻率是每周或者每天,那么 NGINX 這種 reload 還是滿足你的需求的。但如果變更頻率是每小時、每分鐘呢?假設你有 100 個 NGINX 服務,每小時 reload 一次的話,就要 reload 2400 次;如果每分鐘 reload 一次,就是 864 萬次。這顯然是無法接受的。
因此,我們需要一個不需要進程替換的 reload 方案,在現有 NGINX 進程內可以直接完成內容的更新和實時生效。
在內存中直接生效的熱加載方案
在 Apache APISIX 誕生之初,就是希望來解決 NGINX 熱加載這個問題的。
Apache APISIX 是基于 NGINX + Lua 的技術棧,以 ETCD 作為配置中心實現的云原生、高性能、全動態的微服務 API 網關,提供負載均衡、動態上游、灰度發布、精細化路由、限流限速、服務降級、服務熔斷、身份認證、可觀測性等數百項功能。
使用 APISIX 你不需要重啟服務就可以更新配置,這意味著修改上游、路由、插件時都不用重啟。既然是基于 NGINX,APISIX 又是如何擺脫 NGINX 的限制實現完美熱更新?我們先看下 APISIX 的架構。
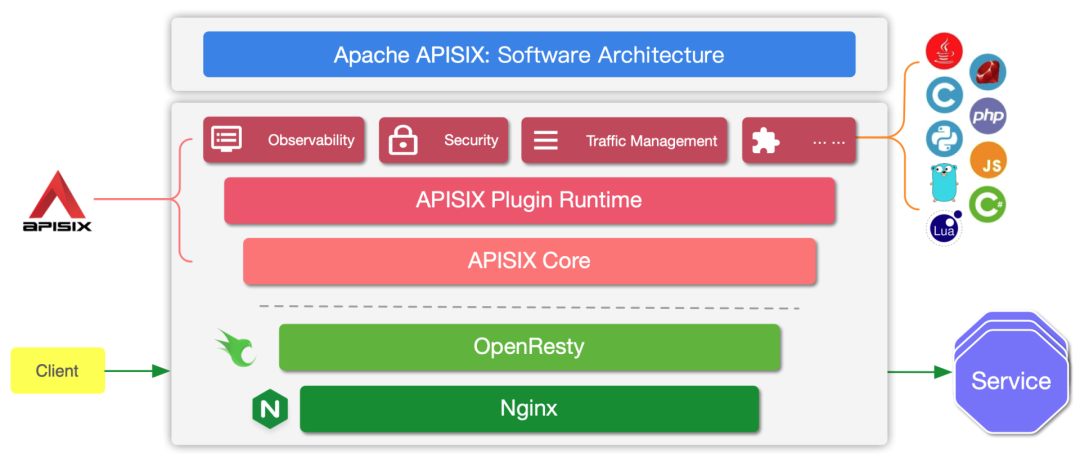
通過上述架構圖可以看到,之所以 APISIX 能擺脫 NGINX 的限制是因為它把上游等配置全部放到 APISIX Core 和 Plugin Runtime 中動態指定。
以路由為例,NGINX 需要在配置文件內進行配置,每次更改都需要 reload 之后才能生效。而為了實現路由動態配置,Apache APISIX 在 NGINX 配置文件內配置了單個 server,這個 server 中只有一個 location。我們把這個 location 作為主入口,所有的請求都會經過這個 location,再由 APISIX Core 動態指定具體上游。因此 Apache APISIX 的路由模塊支持在運行時增減、修改和刪除路由,實現了動態加載。所有的這些變化,對客戶端都零感知,沒有任何影響。
再來幾個典型場景的描述。
比如增加某個新域名的反向代理,在 APISIX 中只需創建上游,并添加新的路由即可,整個過程中不需要 NGINX 進程有任何重啟。再比如插件系統,APISIX 可以通過 ip-restriction 插件實現 IP 黑白名單功能,這些能力的更新也是動態方式,同樣不需要重啟服務。借助架構內的 ETCD,配置策略以增量方式實時推送,最終讓所有規則實時、動態的生效,為用戶帶來極致體驗。
總結
NGINX 的熱加載在某些場景下會長時間存在新舊兩套進程,導致額外消耗資源,同時頻繁熱加載也會導致小概率業務丟失。面對當下云原生和微服務的技術趨勢下, 服務變化更加的頻繁,控制 API 的策略也發生了變化,導致我們對熱加載的需求提出了新需求,NGINX 的熱加載已經不能滿足實際業務需求。
現在是時候切換到更貼合云原生時代并且更完善的熱加載策略、性能表現卓越的 API 網關——Apache APISIX,從而享受動態、統一管理等特性帶來的管理效率上的極大提升。
審核編輯:湯梓紅
-
Web
+關注
關注
2文章
1263瀏覽量
69483 -
服務器
+關注
關注
12文章
9160瀏覽量
85428 -
命令
+關注
關注
5文章
684瀏覽量
22027 -
nginx
+關注
關注
0文章
149瀏覽量
12176
原文標題:為什么NGINX的reload命令不是熱加載?
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
nginx+lua+redis實現灰度發布
Nginx日常運維方法Linux版

「服務器」Nginx Proxy Manager申請cloudflare泛域名

確保網站無縫運行:Keepalived高可用與Nginx集成實戰
使用lsof實現對linux文件的誤刪除恢復練習
nginx隱藏版本號與WEB服務器信息
nginx負載均衡配置介紹
nginx中的正則表達式和location路徑匹配指南
Jtti:美國VPS開啟nginx狀態監控,查看web服務器的并發連接數
nginx重啟命令linux步驟是什么?
nginx重啟命令linux步驟是什么?
Apache服務器和Nginx服務器
【愛芯派?Pro?開發板試用體驗】實現簡單視頻直播系統
Nginx在Windows/docker中的使用





 工商網監
工商網監
評論