 如何借助TigerGraph機器學習工作臺加速企業BI
如何借助TigerGraph機器學習工作臺加速企業BI
什么是圖數據庫,為什么要關心圖?
做出正確的商業決策需要了解任何一個行動或交易之間的關系,因為它們彼此相關。許多企業、數據分析公司和數據科學家正在尋找新的方法來探索連接和關系,看看我們的數據能給我們帶來什么額外的見解。
借助圖分析,我們認識到,所有的數據其實都代表了現實世界中的一些東西,而現實世界中的幾乎所有東西都以某種方式聯系在一起。從關系中找到這些新的模式,可以用來為電子商務網站打造更好的產品推薦,使銀行在欺詐發生之前找到潛在欺詐者,或者讓制造企業找到提高供應鏈效率的方法。
TigerGraph Cloud是業界首個也是唯一一個分布式原生圖數據庫即服務,使用戶能夠更容易地加速采用圖,實時處理分析和事務性工作負載。通過最新的3.8版本,你還可以在TigerGraph Cloud上配置你的ML Workbench Jupyter notebook,為你的圖數據庫和圖機器學習開發環境提供一站式體驗。
案例:圖增強的ML模型檢測欺詐行為
世界各地的公司正在投資于圖,將其作為一種競爭優勢。圖算法和機器學習領域的研究表明,通過將數據構建在一個固有的捕捉上下文和關系的圖結構中,可以大大改善預測模型的質量。特別是在欺詐領域,圖增強的機器學習模型可以學習欺詐交易和行為人之間的潛在關系模式,而傳統的ML方法(如XGBoost模型)則無法捕捉。
在這篇博客中,我們將探討如何應用圖算法和圖特征來解決欺詐檢測問題。我們將展示如何用TigerGraph構建你的圖數據集,然后我們將通過一個Jupyter notebook的例子,用GNN模型構建一個端到端的欺詐檢測應用程序,使用Ethereum數據集,其中包含賬戶(有正面和負面標簽)和它們之間的交易。下面是schema的樣子:
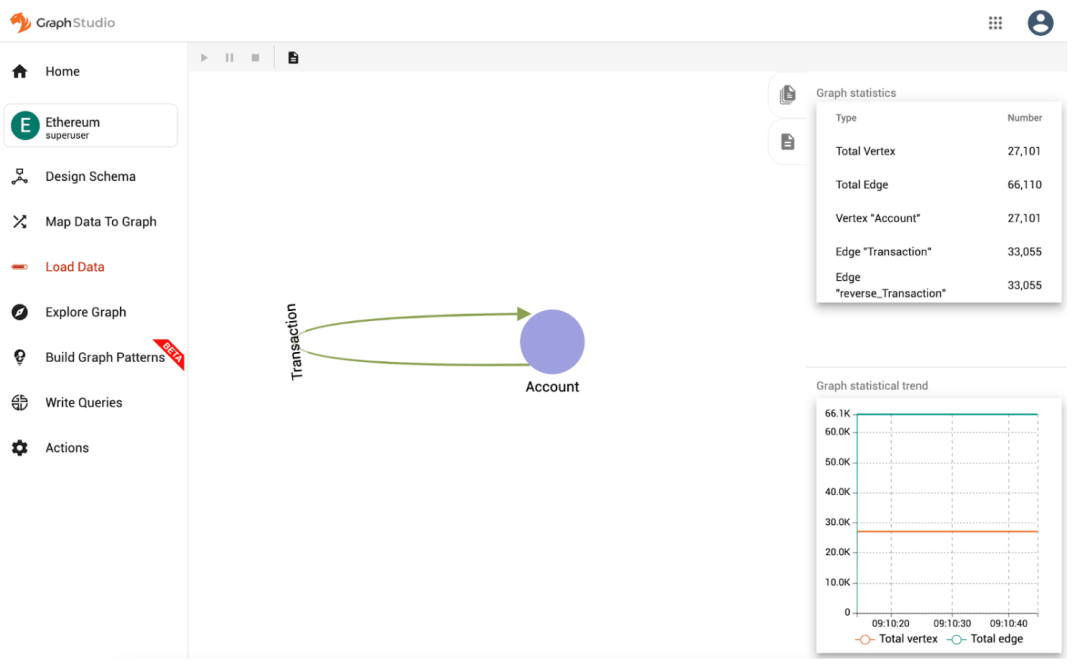
在TigerGraph Cloud上構建你的圖
在任何模型開發之前,我們首先需要構建你的圖。在這個例子中,我們將使用TigerGraph Cloud的免費版本,這是業界第一個也是唯一一個原生并行圖數據庫即服務。
要開始使用TigerGraph數據庫集群,你只需要通過選擇硬件配置來完成集群配置過程。
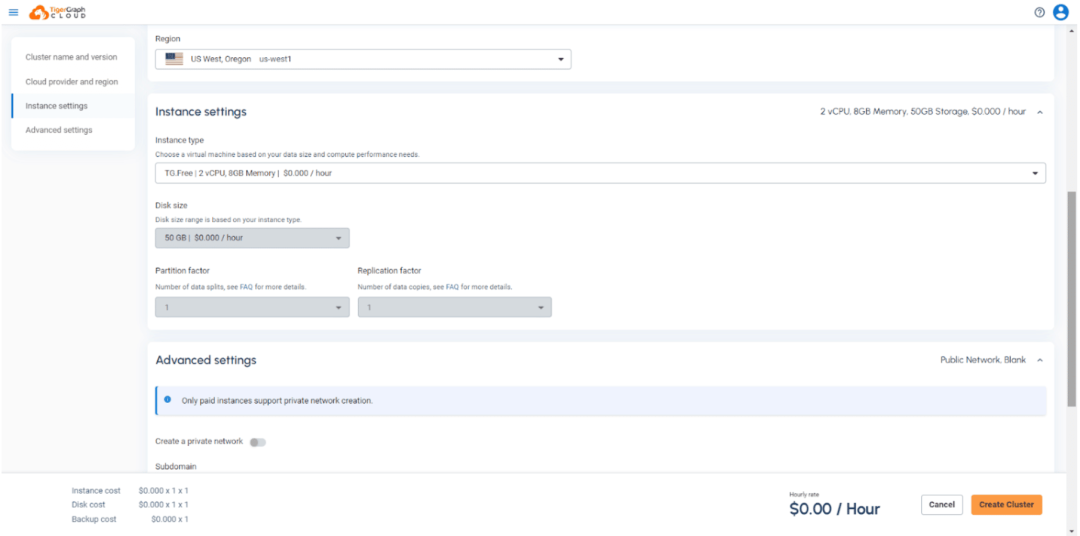
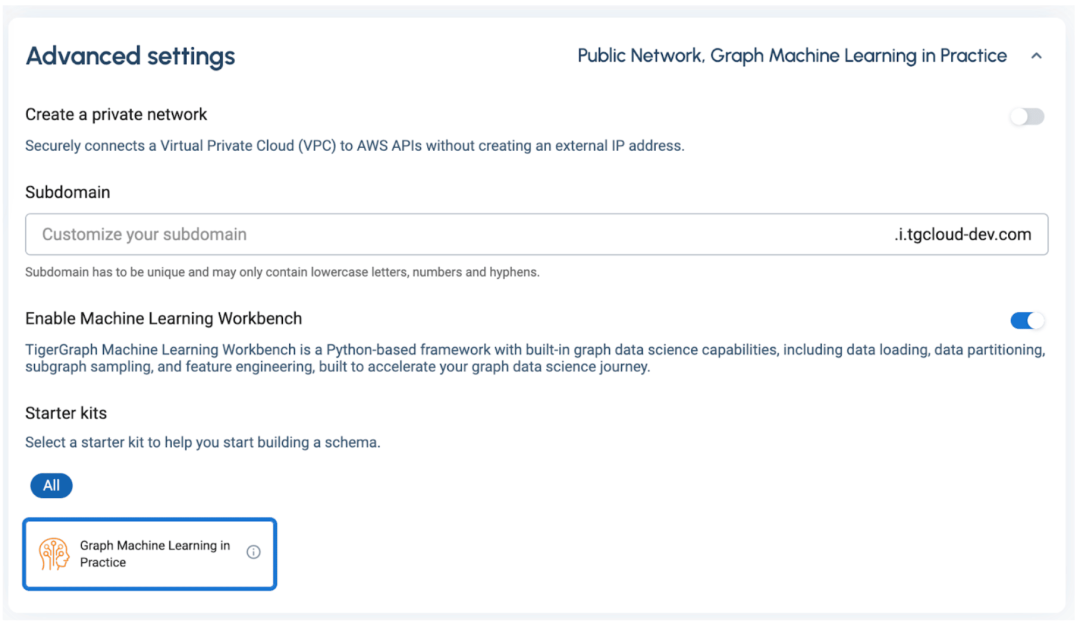
在高級設置部分,確保啟用機器學習工作臺,然后在入門套件中選擇圖機器學習,這樣它就包括在你的配置集群中。(注意:對于這個版本,我們將只支持單服務器配置,即分區因子=1)
TigerGraph云上的機器學習工作臺
TigerGraph云上的機器學習工作臺
一旦你的圖數據庫被配置好了,你將需要添加一個用戶和密碼,以便用機器學習工作臺連接到數據庫。只需從左邊的 “Clusters “選項卡上點擊你剛剛配置的集群的 Access Management”,然后用你的憑證點擊 “Add User”。
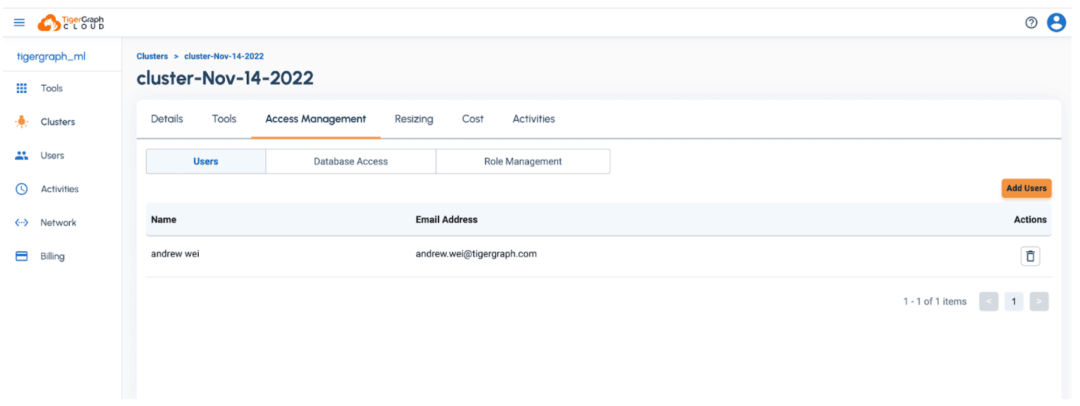
一旦你添加了一個用戶,你現在可以直接利用機器學習工作臺,點擊左側面板上的集群,然后點擊”Tools” 》 “Machine Learning Workbench”。
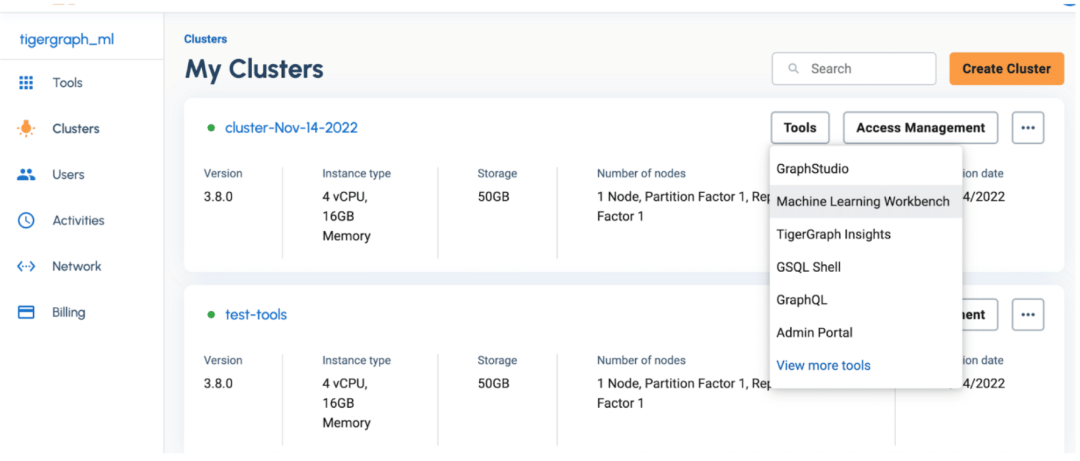
一個新的瀏覽器窗口將被打開,你將登陸到機器學習工作臺的Jupyter服務器。
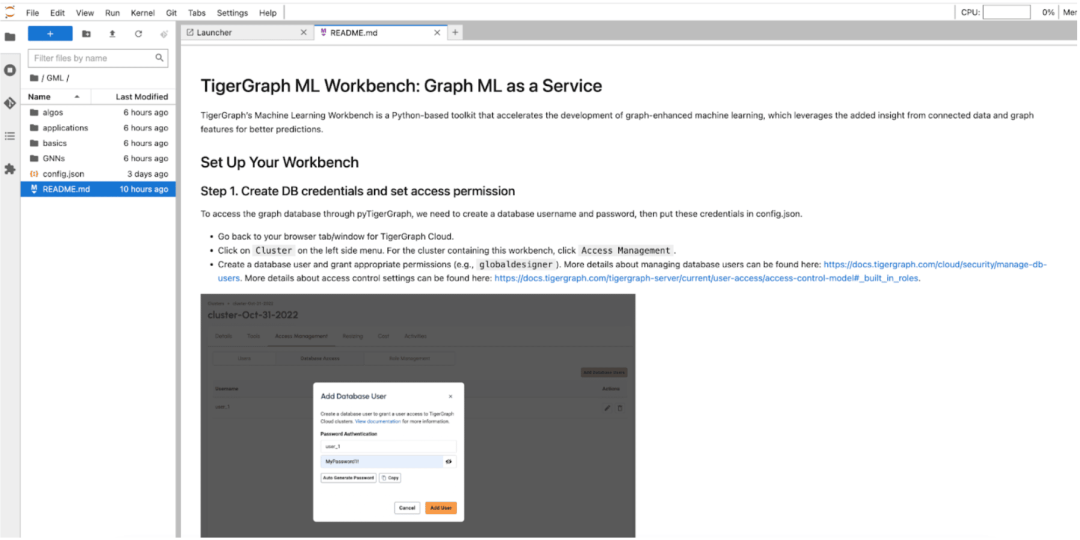
TigerGraph 機器學習工作臺有很多很好的教程,包括如何使用pyTigerGraph使用我們的ML功能的例子,運行我們圖數據科學庫的算法,以及端到端的應用。
你可能已經聽說了最近在人工智能/ML方面的圖譜神經網絡的突破。在這篇博客中,我們將展示利用我們內置的python功能(如圖數據分區、數據導出/批處理和圖特征工程)建立一個GNN模型是多么容易。該notebook 可以在下面路徑找到:GML→ Applications → Fraud_Detection → Fraud_Detection.ipynb.
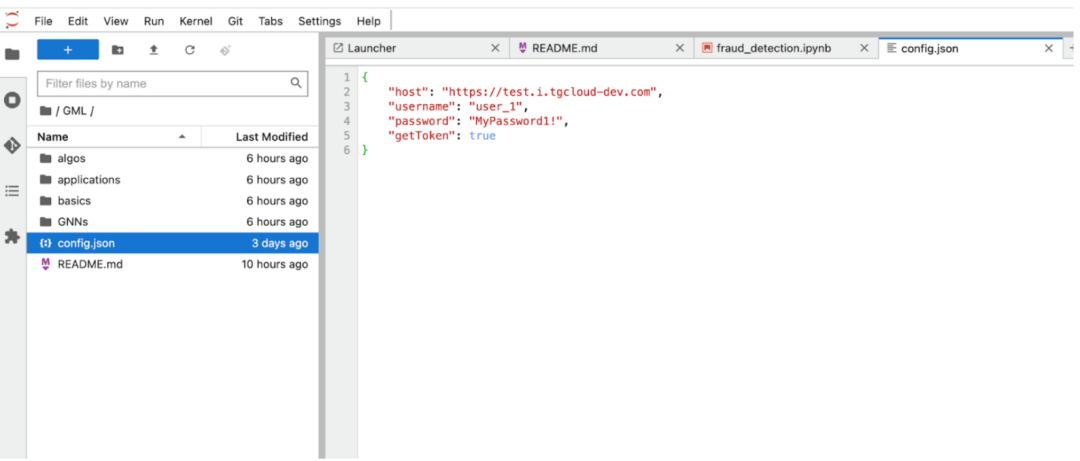
在運行任何代碼之前,你首先需要確保config.json中的用戶名和密碼(在Jupyter服務器的root文件夾中)被相應地更新為你剛剛從tgcloud.io創建的新用戶。
準備你的圖數據集
現在,我們已經準備好與TigerGraph云數據庫實例建立連接,只需運行以下代碼,并將Ethereum 數據集導入到你的實例。
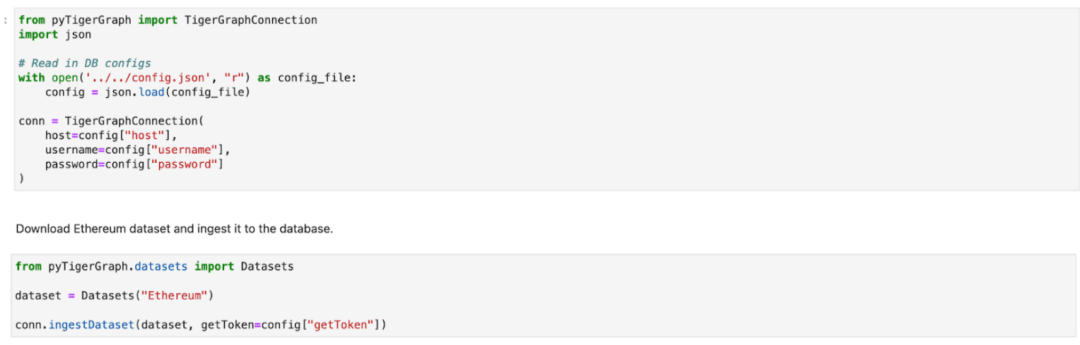
圖特征工程
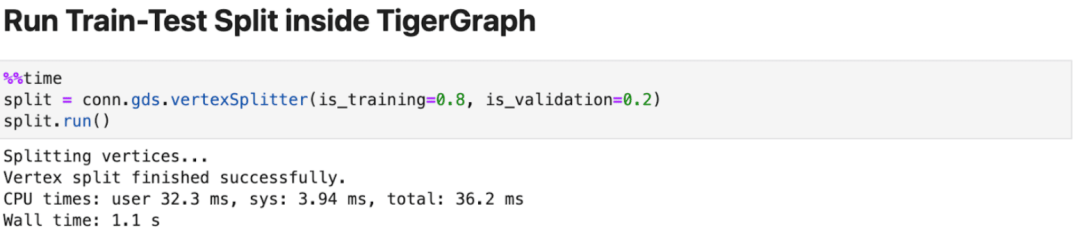
像任何其他監督下的機器學習模型一樣,GNN需要訓練、驗證和測試集來開發模型。ML Workbench通過一個簡單的命令使數據分區變得簡單。我們將對你的圖數據進行分區,同時保留你的數據集的關系。
ML workbench 包括TIgerGraph的圖數據科學庫中的相當多的圖算法來進行特征工程。這個notebook 所強調的關鍵功能是:
listAlgorithm():如果你輸入算法的類別(如中心性),它將打印指定類別的可用算法;否則它將打印所有可用的算法類別。
installAlgorithm():獲取算法的名稱作為輸入,如果該算法尚未安裝,則安裝該算法。
runAlgorithm():獲取算法名稱和參數以運行該算法。如果該算法尚未安裝,并且存在于TigerGraph的圖數據科學庫中,該算法將自動安裝查詢語句,并在圖中創建必要的schema屬性。
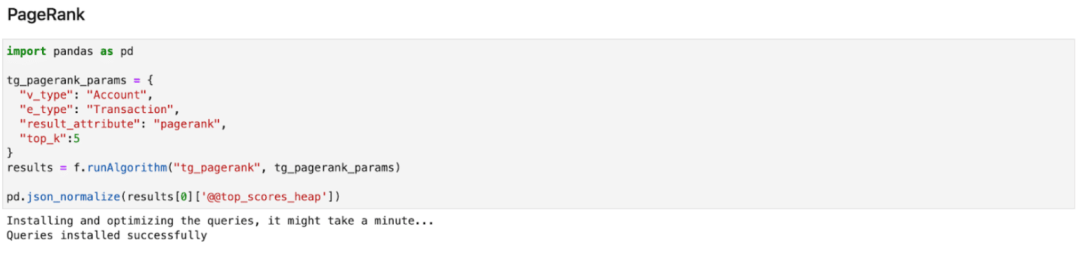
下面的代碼顯示了如何使用Featurizer來獲得PageRank作為一個特征。你也可以通過運行你自己的GSQL查詢語句,并通過Featurizer運行它,來定義你自己的自定義特征。
現在我們已經完成了特征工程,下一步是使用我們的Neighbor Loader函數導出你的訓練、驗證和測試數據集。你可以用我們的Neighbor Loader函數定義你的采樣策略,如批次大小、跳數和鄰居數。

訓練你的GNN模型
現在,我們已經完成了圖特征工程,并將所有的數據導出到你的機器學習工作臺環境,以訓練機器學習模型。
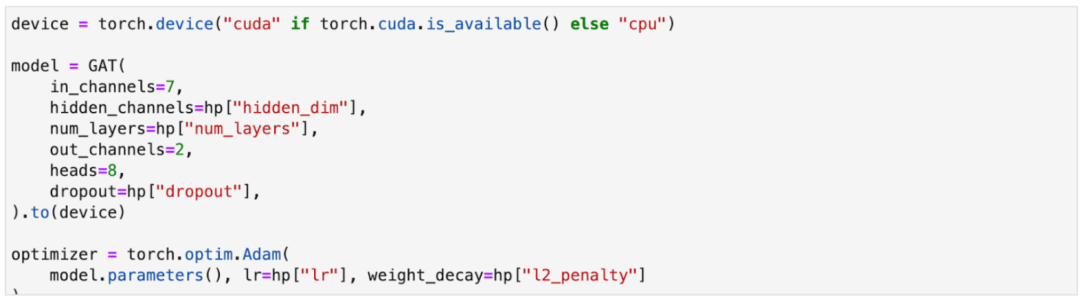
我們擁護開源社區,這就是為什么我們把TigerGraph ML Workbench與一些最流行的深度學習框架兼容,如PyTorch Geometric和Tensorflow。注意在上面的代碼中,我們直接將你的關聯數據以output_format參數中指定的PyG格式導出,你將能夠直接利用PyG來訓練一個GNN模型,比如Graph Attention Network( (GATs)算法。請看下面的例子:
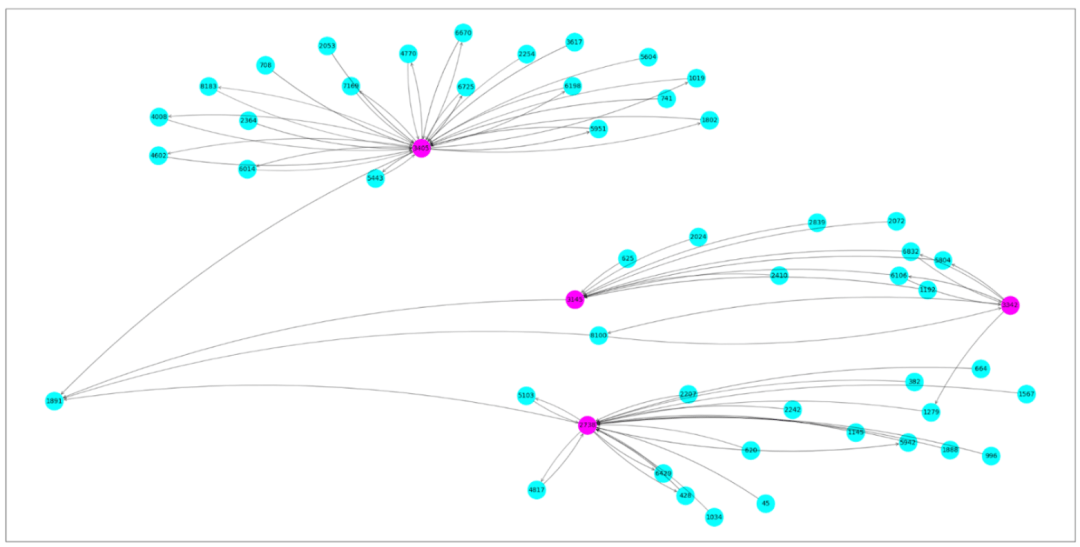
一旦你的模型訓練完成,你就可以對你的模型進行推理,看看一個欺詐者是如何通過其網絡移動交易的。為了更好地解釋預測行為,我們可以將與預測頂點相關的子圖可視化。
用子圖可視化你的模型預測
在這個例子中,頂點#1891被預測為一個欺詐賬戶。粉紅色的頂點是已知的欺詐賬戶,用藍色標識的頂點是未知賬戶。看起來頂點1891是一個欺詐者網絡的幕后策劃者,一直在從無辜的用戶那里拿錢!
下一步
如果你覺得這篇文章很有趣,并想建立自己的GNN應用程序,請免費試用我們的TigerGraph Cloud和TigerGraph ML Workbench。請從我們的Github(https://github.com/tigergraph/graph-ml-notebooks)上查看我們的教程。你也可以在這篇博文中找到我們所用到的notebook例子的鏈接。
審核編輯 :李倩
-
數據庫
+關注
關注
7文章
3816瀏覽量
64465 -
機器學習
+關注
關注
66文章
8422瀏覽量
132738
原文標題:如何借助TigerGraph機器學習工作臺加速企業BI
文章出處:【微信號:TigerGraph,微信公眾號:TigerGraph】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何選擇云原生機器學習平臺
適用于MSP430 MCUs的IAR嵌入式工作臺IDE版本7+

日本企業借助NVIDIA產品加速AI創新
NPU與機器學習算法的關系
FPGA加速深度學習模型的案例
AI引擎機器學習陣列指南

Cloudera推出機器學習項目加速器 (AMP) 的全新套件
虹軟PhotoStudio AI正式入駐阿里巴巴集團旗下的千牛商家工作臺
工作臺激光焊接機X, Y, Z,三軸功能的區別與作用

三軸工作臺激光焊接機:實現高精度、高效率焊接的新選擇

NVIDIA Isaac機器人平臺升級,加速AI機器人技術革新
數據中臺:如何構建企業核心競爭力








 工商網監
工商網監
評論