 在NGC上玩轉飛槳自然語言處理模型庫PaddleNLP!信息抽取、文本分類、文檔智能、語義檢索、智能問答等產業方
在NGC上玩轉飛槳自然語言處理模型庫PaddleNLP!信息抽取、文本分類、文檔智能、語義檢索、智能問答等產業方
飛槳自然語言處理模型庫 PaddleNLP,聚合眾多百度自然語言處理領域自研 SOTA 算法以及社區開源模型,并憑借飛槳核心框架底層能力,不斷開源適合產業界應用的模型、場景、預測加速與部署能力,得到學術界與產業界的廣泛關注。今年,PaddleNLP 帶來重大升級,覆蓋信息抽取、文本分類、情感分析、語義檢索、智能問答等自然語言處理領域核心任務。歡迎廣大開發者使用 NVIDIA 與飛槳聯合深度適配的 NGC 飛槳容器,在 NVIDIA GPU 上進行體驗!
PaddleNLP 開源首個面向通用信息抽取的產業級技術方案 UIE,零樣本、小樣本效果領先
通用信息抽取技術 UIE(Universal Information Extraction)大一統諸多任務,在實體、關系、事件和情感等 4 個信息抽取任務、13 個數據集的全監督、低資源和少樣本設置下,取得了 SOTA 性能,這項成果發表在 ACL 2022。PaddleNLP 結合文心大模型中的知識增強 NLP 大模型 ERNIE 3.0,發揮了 UIE 在中文任務上的強大潛力,開源了首個面向通用信息抽取的產業級技術方案 UIE,其多任務統一建模特性大幅降低了模型開發成本和部署的機器成本,基于 Prompt 的零樣本抽取和少樣本遷移能力更是驚艷!
通過調用paddlenlp.TaskflowAPI即可實現零樣本(zero-shot)抽取多種類型的信息,以實體抽取為例:
from pprint import pprint
from paddlenlp import Taskflow
schema = ['時間', '選手', '賽事名稱'] # Define the schema for entity extraction
ie = Taskflow('information_extraction', schema=schema)
pprint(ie("2月8日上午北京冬奧會自由式滑雪女子大跳臺決賽中中國選手谷愛凌以188.25分獲得金牌!")) # Better print results using pprint
[{'時間': [{'end': 6, 'probability': 0.9857378532924486, 'start': 0, 'text': '2月8日上午'}],
'賽事名稱': [{'end': 23,'probability': 0.8503089953268272,'start': 6,'text': '北京冬奧會自由式滑雪女子大跳臺決賽'}],
'選手':[{'end':31,'probability':0.8981548639781138,'start':28,'text':'谷愛凌'}]}]
對于復雜目標,可以標注少量數據(Few-shot)進行模型訓練,以進一步提升效果。PaddleNLP 打通了從數據標注-訓練-部署全流程,方便大家進行定制化訓練。以金融領域事件抽取任務為例,僅僅標注 5 條樣本,F1 值就提升了 25 個點!
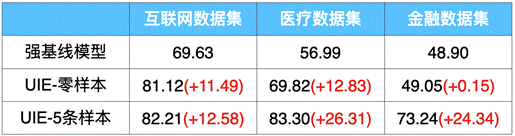
表 1:UIE 在信息抽取數據集上零樣本和小樣本效果(F1-score)
GitHub 地址:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie開源文心 ERNIE-Layout,文檔智能不再難
(1)文心 ERNIE-Layout 多語言版跨模態布局增強文檔預訓練大模型
文心 ERNIE-Layout 依托文心 ERNIE,基于布局知識增強技術,融合文本、圖像、布局等信息進行聯合建模,能夠對多模態文檔(如文檔圖片、PDF 文件、掃描件等)進行深度理解與分析,刷新了五類 11 項文檔智能任務效果,為各類上層應用提供 SOTA 模型底座。
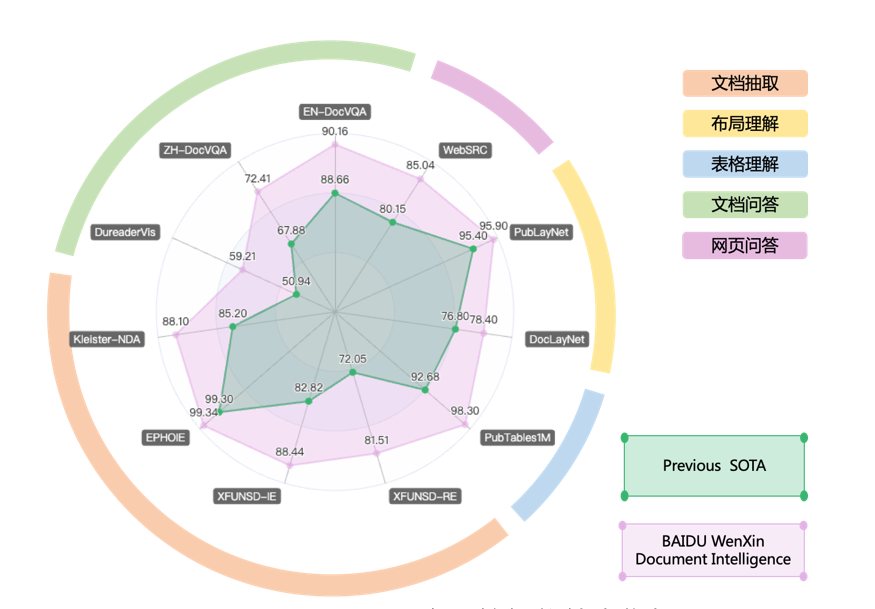
圖 1:百度文檔智能技術指標
(2)DocPrompt 開放文檔抽取問答模型(基于 ERNIE-Layout)
DocPrompt 以 ERNIE-Layout 為底座,可精準理解圖文信息,推理學習附加知識,準確捕捉圖片、PDF 等多模態文檔中的每個細節。通過PaddleNLP Taskflow,僅用三行Python代碼即可快速體驗DocPrompt功能。

DocPrompt 零樣本效果非常強悍!能夠推理學習空間位置語義,準確捕捉跨模態文檔信息,輕松應對各類復雜文檔:
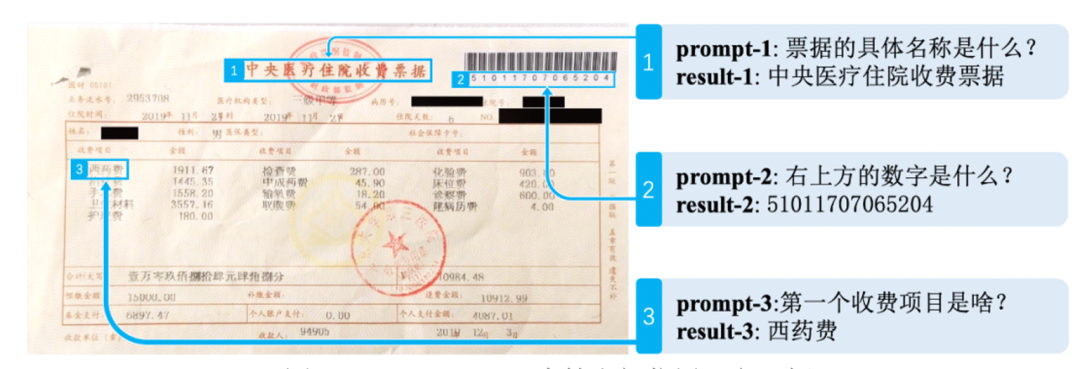
圖 2:DocPrompt 可支持空間位置語義理解

圖 3:DocPrompt 支持多維度無框線表格問答

GitHub 地址:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layoutPaddleNLP 發布 NLP 流水線系統Pipelines,
10 分鐘搭建檢索、問答等復雜系統
Pipelines 將各個 NLP 復雜系統的通用模塊抽象封裝為標準組件,支持開發者通過配置文件對標準組件進行組合,僅需幾分鐘即可定制化構建智能系統,讓解決 NLP 任務像搭積木一樣便捷、靈活、高效。同時,Pipelines 中預置了前沿的預訓練模型和算法,在研發效率、模型效果和性能方面提供多重保障。
Pipelines 中集成 PaddleNLP 中豐富的預訓練模型和領先技術。例如針對檢索、問答等任務,Pipelines 預置了領先的召回模型和排序模型,其依托國際領先的端到端問答技術 RocketQA 和首個人工標注的百萬級問答數據集 DuReader。
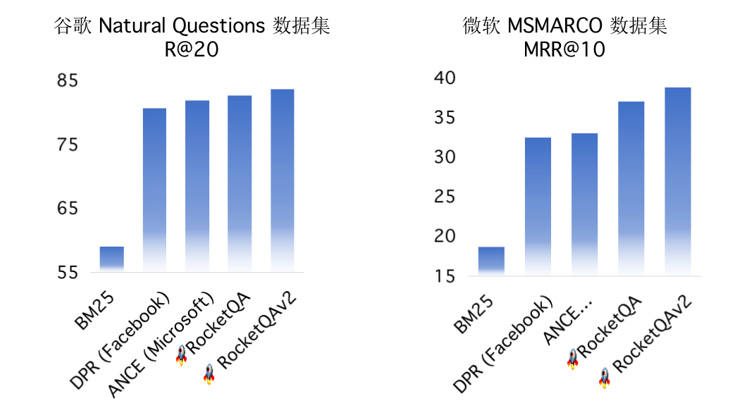
圖 5:RocketQA 問答技術領先
為了進一步降低開發門檻,提供最優效果,PaddleNLP Pipelines 針對高頻場景內置了產業級端到端系統。目前已開源語義檢索、MRC(閱讀理解)問答、FAQ 問答、跨模態文檔問答等多個應用。以檢索系統為例,Pipelines 內置的語義檢索系統包括文檔解析(支持 PDF、WORD、圖片等解析)、海量文檔建庫、模型組網訓練、服務化部署、前端 Demo 界面(便于效果分析)等全流程功能。

圖 6:檢索系統流水線示意圖

圖 7:檢索系統前端 Demo
GitHub 地址:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines發布多場景文本分類方案,新增數據增強策略,可信增強技術
文本分類任務是 NLP 領域最常見、最基礎的任務之一,顧名思義,就是對給定的一個句子或一段文本進行分類。PaddleNLP 基于多分類、多標簽、層次分類等高頻分類場景,提供了預訓練模型微調、提示學習、語義索引三種端到端全流程分類方案。
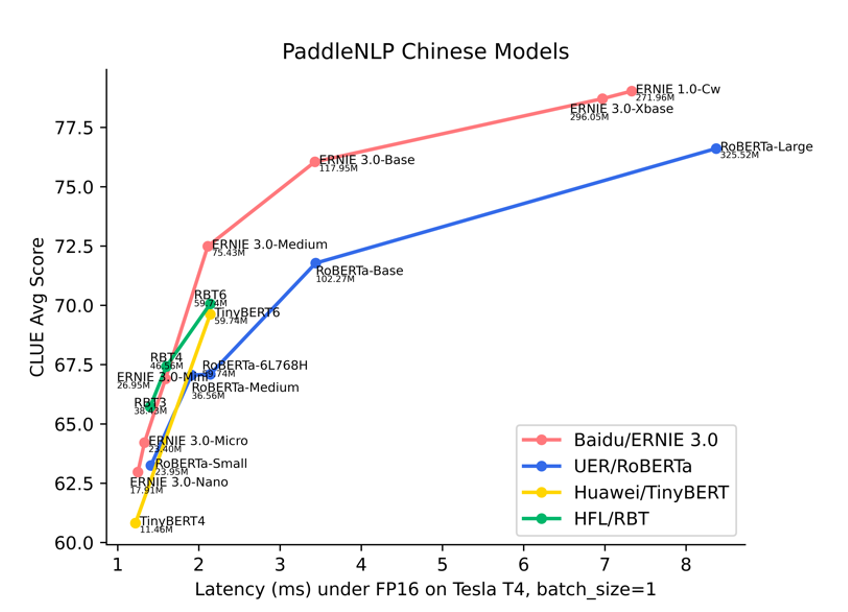
圖 8:模型精度-時延圖
以上方案均離不開預訓練模型,在預訓練模型選擇上,ERNIE 系列模型在精度和性能上的綜合表現已全面領先于 UER/RoBERTa、Huawei/TinyBERT、HFL/RBT、RoBERTa-wwm-ext-large 等中文模型。PaddleNLP 開源了如下多種尺寸的 ERNIE 系列預訓練模型,滿足多樣化的精度、性能需求:
-
ERNIE 1.0-Large-zh-CW(24L1024H)
-
ERNIE 3.0-Xbase-zh(20L1024H)
-
ERNIE 2.0-Base-zh (12L768H)
-
ERNIE 3.0-Base(12L768H)
-
ERNIE 3.0-Medium(6L768H)
-
ERNIE 3.0-Mini(6L384H)
-
ERNIE 3.0-Micro(4L384H)
-
ERNIE 3.0-Nano(4L312H)
… …
除中文模型外,PaddleNLP 也提供 ERNIE 2.0 英文版、以及基于 96 種語言(涵蓋法語、日語、韓語、德語、西班牙語等幾乎所有常見語言)預訓練的多語言模型 ERNIE-M,滿足不同語言的文本分類任務需求。
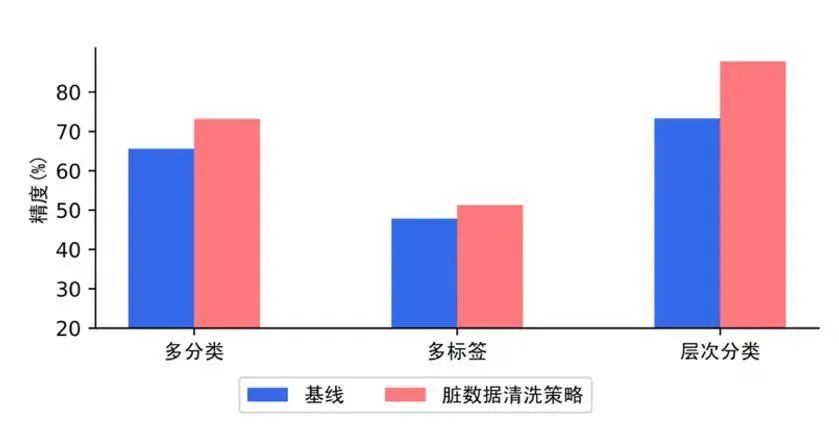
此外,PaddleNLP 文本分類方案依托TrustAI 可信增強能力和數據增強 API開源了模型分析模塊,針對標注數據質量不高、訓練數據覆蓋不足、樣本數量少等文本分類常見數據痛點,提供稀疏數據篩選、臟數據清洗、數據增強三種數據優化策略,解決訓練數據缺陷問題,用低成本方式獲得大幅度的效果提升。例如,使用 TrustAI 進行臟數據清洗后,文本分類精度有明顯提升。
新增 AutoPrompt 自動化提示功能,輕松上手 Prompt Learning,解決小樣本難題
通過配置自動化運行的提示學習框架 AutoPrompt,開發者可以以最低學習成本上手提示學習。AutoPrompt 借鑒了 OpenPrompt 對 Template、Verbalizer 等概念的抽象和設計,并在此基礎上擴展了更多特性,包括更靈活的提示設計,更便捷的算法切換,通過配置即可運行選擇最優模型。
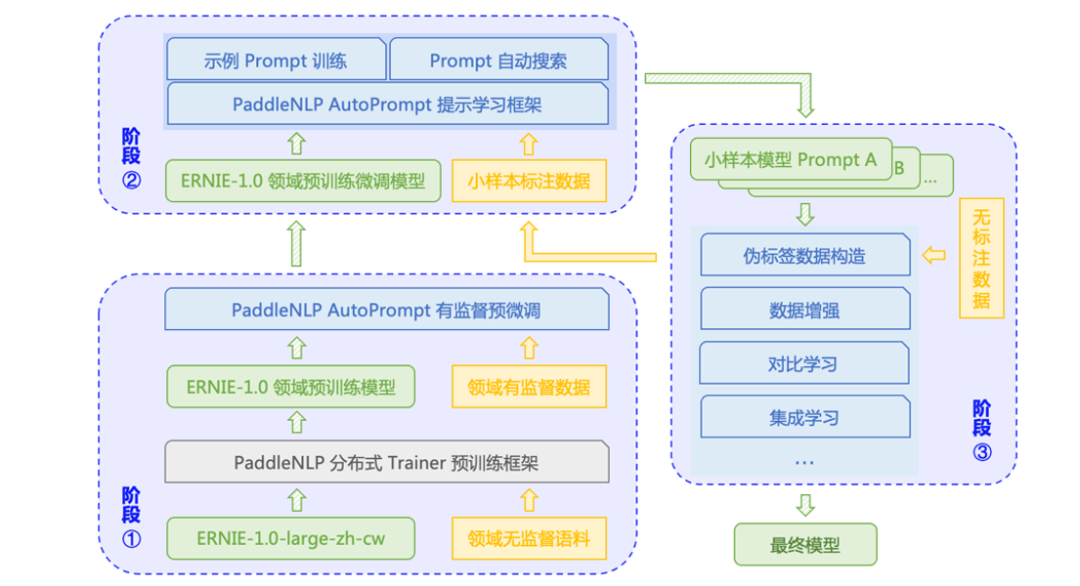
圖 10:AutoPrompt 整體流程方案
AutoPrompt 使用文檔:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/advanced_guide/prompt.md以上是 PaddleNLP 近期新發功能介紹,歡迎前往官方地址了解更多詳情。喜歡的小伙伴歡迎star支持哦~您的支持是我們不斷進取的最大動力!也歡迎加入 PaddleNLP 官方交流群,探討前沿技術與產業實踐經驗。
PaddleNLP 地址:
https://github.com/PaddlePaddle/PaddleNLP
NGC 飛槳容器介紹
如果您希望體驗 PaddleNLP 的新特性,歡迎使用 NGC 飛槳容器。NVIDIA 與百度飛槳聯合開發了 NGC 飛槳容器,將最新版本的飛槳與最新的 NVIDIA 的軟件棧(如 CUDA)進行了無縫的集成與性能優化,最大程度的釋放飛槳框架在 NVIDIA 最新硬件上的計算能力。這樣,用戶不僅可以快速開啟 AI 應用,專注于創新和應用本身,還能夠在 AI 訓練和推理任務上獲得飛槳+NVIDIA 帶來的飛速體驗。
最佳的開發環境搭建工具 - 容器技術。
-
容器其實是一個開箱即用的服務器。極大降低了深度學習開發環境的搭建難度。例如你的開發環境中包含其他依賴進程(redis,MySQL,Ngnix,selenium-hub等等),或者你需要進行跨操作系統級別的遷移。
-
容器鏡像方便了開發者的版本化管理
-
容器鏡像是一種易于復現的開發環境載體
-
容器技術支持多容器同時運行
最好的 PaddlePaddle 容器
NGC 飛槳容器針對 NVIDIA GPU 加速進行了優化,并包含一組經過驗證的庫,可啟用和優化 NVIDIA GPU 性能。此容器還可能包含對 PaddlePaddle 源代碼的修改,以最大限度地提高性能和兼容性。此容器還包含用于加速 ETL(DALI, RAPIDS)、訓練(cuDNN, NCCL)和推理(TensorRT)工作負載的軟件。
PaddlePaddle 容器具有以下優點:
-
適配最新版本的 NVIDIA 軟件棧(例如最新版本 CUDA),更多功能,更高性能。
-
更新的 Ubuntu 操作系統,更好的軟件兼容性
-
按月更新
-
滿足 NVIDIA NGC 開發及驗證規范,質量管理
通過飛槳官網快速獲取
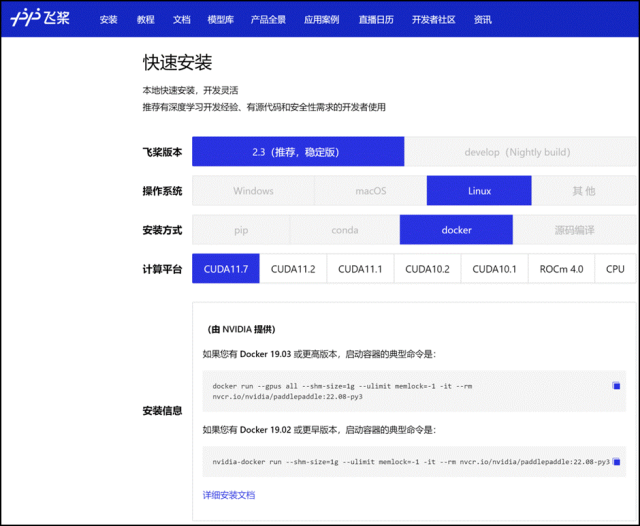
環境準備
使用 NGC 飛槳容器需要主機系統(Linux)安裝以下內容:
-
Docker 引擎
-
NVIDIA GPU 驅動程序
-
NVIDIA 容器工具包
有關支持的版本,請參閱NVIDIA 框架容器支持矩陣和NVIDIA 容器工具包文檔。
不需要其他安裝、編譯或依賴管理。無需安裝 NVIDIA CUDA Toolkit。
NGC 飛槳容器正式安裝:
要運行容器,請按照 NVIDIA Containers For Deep Learning Frameworks User’s Guide 中Running A Container一章中的說明發出適當的命令,并指定注冊表、存儲庫和標簽。有關使用 NGC 的更多信息,請參閱 NGC 容器用戶指南。如果您有 Docker 19.03 或更高版本,啟動容器的典型命令是:

*詳細安裝介紹 《NGC 飛槳容器安裝指南》
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/install_NGC_PaddlePaddle_ch.html【飛槳開發者說|NGC 飛槳容器全新上線 NVIDIA 產品專家全面解讀】
https://www.bilibili.com/video/BV16B4y1V7ue?share_source=copy_web&vd_source=266ac44430b3656de0c2f4e58b4daf82
飛槳與 NVIDIA NGC 合作介紹
NVIDIA 非常重視中國市場,特別關注中國的生態伙伴,而當前飛槳擁有超過 470 萬的開發者。在過去五年里我們緊密合作,深度融合,做了大量適配工作,如下圖所示。

今年,我們將飛槳列為 NVIDIA 全球前三的深度學習框架合作伙伴。我們在中國已經設立了專門的工程團隊支持,賦能飛槳生態。
為了讓更多的開發者能用上基于 NVIDIA 最新的高性能硬件和軟件棧。當前,我們正在進行全新一代 NVIDIA GPU H100 的適配工作,以及提高飛槳對 CUDA Operation API 的使用率,讓飛槳的開發者擁有優秀的用戶體驗及極致性能。
以上的各種適配,僅僅是讓飛槳的開發者擁有高性能的推理訓練成為可能。但是,這些離行業開發者還很遠,門檻還很高,難度還很大。
為此,我們將剛剛這些集成和優化工作,整合到三大產品線中。其中 NGC 飛槳容器最為閃亮。
NVIDIA NGC Container – 最佳的飛槳開發環境,集成最新的 NVIDIA 工具包(例如 CUDA)

點擊查看往期精彩內容
六:在 NGC 上玩轉圖像分割!NeurIPS 頂會模型、智能標注 10 倍速神器、人像分割 SOTA 方案、3D 醫療影像分割利器應有盡有!
五:在 NVIDIA NGC 上搞定模型自動壓縮,YOLOv7 部署加速比 5.90,BERT 部署加速比 6.22
四:在 NVIDIA NGC 上體驗輕量級圖像識別系統
三:在 NVIDIA NGC 上體驗一鍵 PDF 轉 Word
二:PaddleDetection 發新,歡迎在 NVIDIA NGC 飛槳容器中體驗最新特性!
一:NVIDIA Deep Learning Examples飛槳ResNet50模型上線訓練速度超PyTorch ResNet50
原文標題:在NGC上玩轉飛槳自然語言處理模型庫PaddleNLP!信息抽取、文本分類、文檔智能、語義檢索、智能問答等產業方案應有盡有!
文章出處:【微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3778瀏覽量
91176
原文標題:在NGC上玩轉飛槳自然語言處理模型庫PaddleNLP!信息抽取、文本分類、文檔智能、語義檢索、智能問答等產業方案應有盡有!
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是LLM?LLM在自然語言處理中的應用
ASR與自然語言處理的結合
使用LLM進行自然語言處理的優缺點
AI大模型在自然語言處理中的應用
AI智能化問答:自然語言處理技術的重要應用






 工商網監
工商網監
評論