") 玩嗨OpenHarmony:基于OpenHarmony的自閉癥早期篩查聲紋特征濾波識別系統(tǒng)
玩嗨OpenHarmony:基于OpenHarmony的自閉癥早期篩查聲紋特征濾波識別系統(tǒng)
1. 項目背景
根據(jù)《孤獨癥教育康復行業(yè)發(fā)展狀況報告》,在全世界范圍內(nèi)每 54 個兒童就有一個兒童患有自閉癥譜系障礙,目前中國的自閉癥譜系障礙患者已經(jīng)超過了 1300萬,并且這個數(shù)量以每年近20萬的速度增長。

我們通過調(diào)研發(fā)現(xiàn)我國關于自閉癥譜系障礙方面的確診缺乏統(tǒng)一的診斷標準,各大醫(yī)院與醫(yī)療機構的主流診斷方案還是依托于量表等工具,誤診率高。但目前在確診方面缺乏科學精準的檢測儀器,導致被確診為自閉癥的患者平均年齡為4到5歲,遠遠滯后于18到24個月的最佳早期篩查診斷時機,使得患兒錯過最佳康復治療期。
我們團隊基于以上痛點,以兒童說話聲音作為原始數(shù)據(jù),利用深度學習訓練出的高精度模型對比分析自閉癥譜系障礙兒童和正常兒童在聲學特征上的差異,使用音頻分析技術提取聲學特征參數(shù)進行分析,基于潤和大禹DAYU200從聲學角度指導醫(yī)生對待測兒童進行早期篩查,可將自閉癥患者實際篩查確診年齡提前至1到2歲,讓自閉癥譜系障礙兒童能極早地得到確診,從而能夠盡早進行干預治療,最大限度地減少天生發(fā)育障礙對患者及整個家庭的影響。
2. 我們是誰?守望星光團隊于2021年6月在鄭州輕工業(yè)大學梅科爾工作室成立,是一家專注于自閉癥譜系障礙診斷技術研發(fā)的在校創(chuàng)新創(chuàng)業(yè)團隊。梅科爾工作室的老師和同學們還必須在極為有限的條件下讓價值最大化,工作室在老齡化、老年人康復、特殊人群關愛方向的漫漫征途。從拿著一封封介紹信去醫(yī)院聯(lián)系合作,一點點走訪患者開始。如今,梅科爾工作室總計參與到60余個醫(yī)療項目的聯(lián)合創(chuàng)新開發(fā)中,其中40多個是特殊人群關愛類項目。在腦卒中、自閉癥和帕金森等領域完成了超過2000人次的病患數(shù)據(jù)樣本收集,沉淀出300多個可用醫(yī)療案例。

本項目通過神經(jīng)網(wǎng)絡和音頻分析技術提取自閉癥譜系障礙兒童的聲學特征參數(shù)進行分析,篩選出最具有代表性的聲學特征和分類識別性能最優(yōu)的模型,從聲學角度輔助醫(yī)生對自閉癥譜系障礙兒童進行早期診斷,并設計機器學習模型進行分類。構建模型,最終網(wǎng)絡的準確性達到 93.8%。醫(yī)生可在DAYU200端、網(wǎng)頁Web端、桌面exe程序端、手機端鴻蒙APP查看結果,預測出自閉癥譜系障礙準確率超過 70%,推薦可能患有自閉癥譜系障礙孩子接受干預訓練,避免錯過最佳干預期。
3.1 開發(fā)技術設計框架
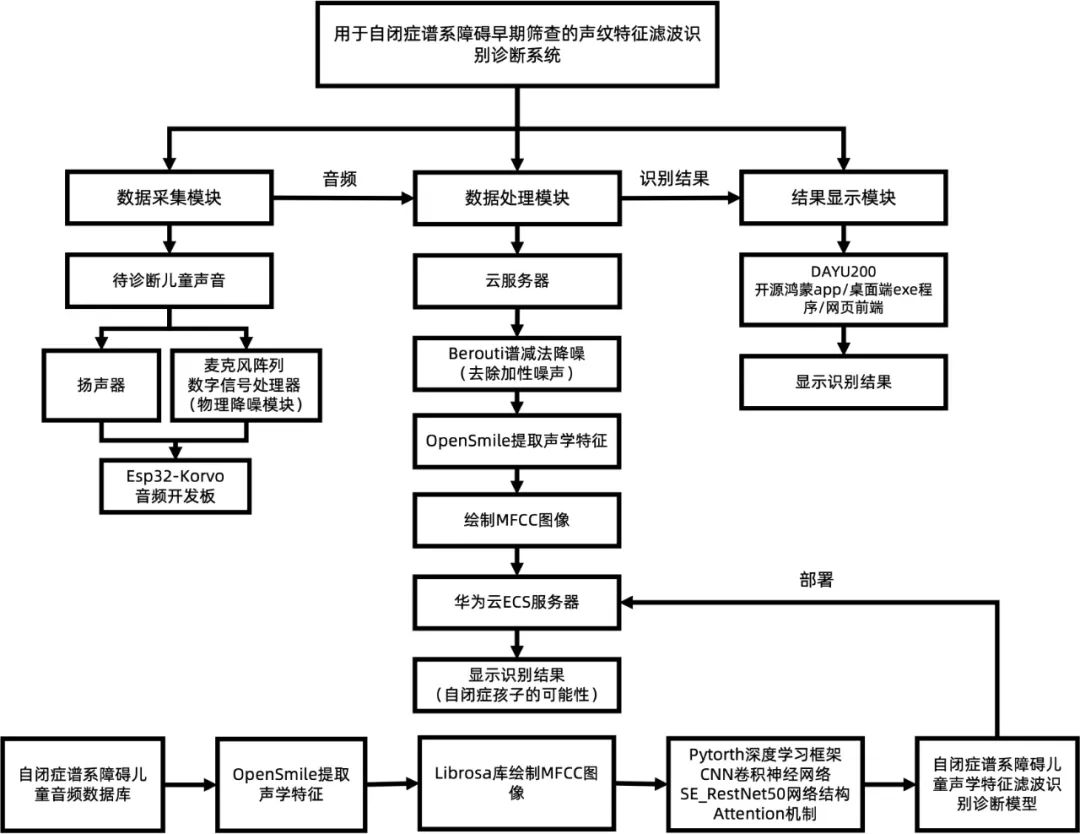
3.2音頻數(shù)據(jù)采集
項目的音頻數(shù)據(jù)采集模塊主要由三部分組成,分別是揚聲器、三麥克風陣列數(shù)字信號處理器和Esp32-Korvo音頻開發(fā)板。并通過回聲消除算法、語音增強算法、降噪算法和音頻自動增益算法收集音頻數(shù)據(jù),以此來保證受測者的音頻數(shù)據(jù)質(zhì)量。并通過藍牙或WLAN傳輸音頻數(shù)據(jù)至云服務器進行下一步處理。在內(nèi)部布局上,通過精確測量開發(fā)板、揚聲器、可充電電池的尺寸,合理規(guī)劃設計了內(nèi)部零件的位置,精準建模預留內(nèi)部空間。效果圖如下:

3.3音頻數(shù)據(jù)預處理
我們將數(shù)據(jù)采集模塊得到的音頻數(shù)據(jù)上傳至我們的華為云服務器上,利用利用我們自主開發(fā)的降噪算法對收集到的聲音進行二次降噪,除去高斯噪聲、白噪聲等等的一 些噪音,然后利用 OpenSmile 提取聲學特征,得到的處理過后的數(shù)據(jù)會進行 Librosa 庫繪制MFCC 圖像。
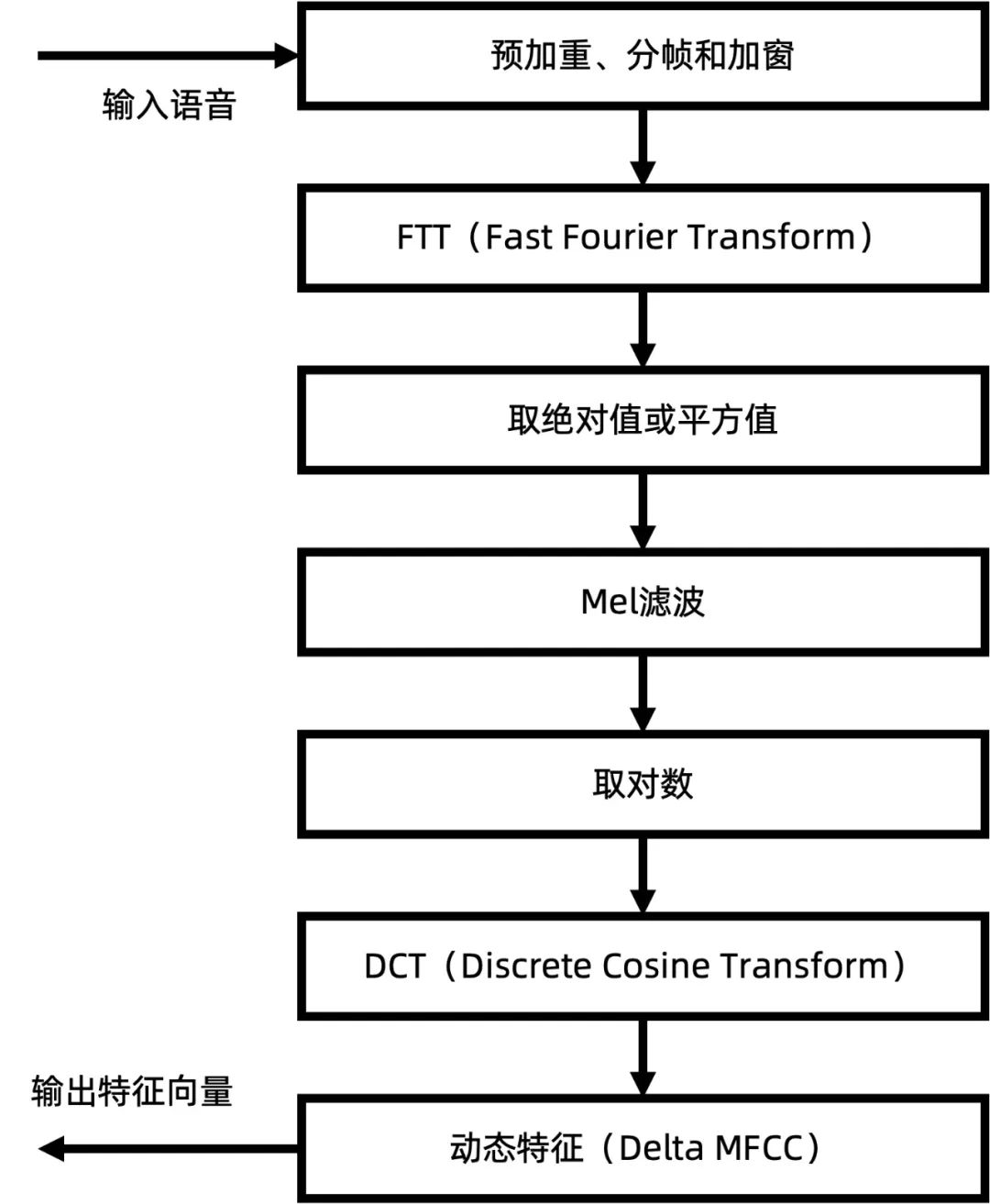
首先在音頻轉圖像之前,通過 Berouti 譜減法對采樣的自閉癥患者語音中自帶的加性噪聲(背景噪聲)得到噪聲的頻譜信息,并將其從頻率空間中減去。同時為了避免提取困難,采用預加重技術將預加重濾波器加在原始音頻上,強化高頻部分,再通過分幀加窗使分析對象的信號變化不會突然消失。接著將連續(xù)的模擬信號轉化為數(shù)字信號,通過快速傅里葉變化對分幀加窗后的各幀信號進行快速傅里葉變換得到各幀的頻譜。并對語音信號的頻譜取模平方得到語音信號的功率譜。接著利用三角帶通濾波器對頻譜進行平滑化,并消除諧波的作用,突顯原先語音的共振峰。因此一段語音的音調(diào)或音高,是不會呈現(xiàn)在梅爾倒譜系數(shù)內(nèi)。換言之,以梅爾倒譜系數(shù)為特征的聲學特征濾波識別診斷系統(tǒng),并不會受到輸入語音的音調(diào)不同而有所影響。此外,還可以降低運算量。
最后,經(jīng)離散余弦變換(DCT)得到 MFCC 系數(shù)。
音頻轉圖像具體流程展示圖如下:
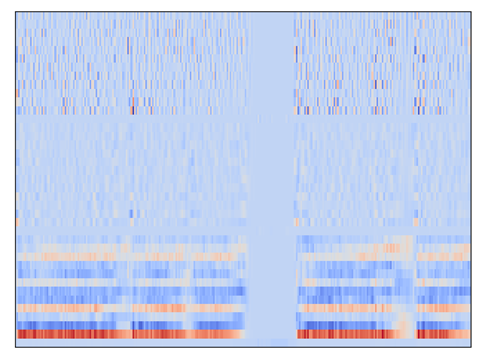
提取聲學特征并繪制出的 MFCC 圖像如下:
3.4圖像數(shù)據(jù)分析
在深度學習模型預測程序中預測待測者自閉癥譜系障礙的患病概率,采用CNN卷積神經(jīng)網(wǎng)絡來進行圖像識別,包含4個卷積層和3個全連接層,每個卷積層后面有一個LeakyRelu (激活函數(shù))增強非線性,每兩個卷積層分別緊跟一個最大值池化層縮小特征圖組成一個卷積組模塊,卷積層的輸出通道數(shù)按順序分別是64, 32, 128, 64,卷積層的輸出特征圖進入全連接層前平鋪成向量,然后進入三個線性變換層逐層降低向量的維度,每個線性變換緊跟一個Dropout層防止過擬合,線性變換的輸出長度分別是128, 64, 1,最后輸出的一維向量用于二分類,輸出自閉癥譜系障礙兒童的概率和正常兒童的概率。基于深度神經(jīng)網(wǎng)絡的算法,通過計算機較強的學習能力來學習自閉癥患者與正常人的聲學特征,以此達到對自閉癥患者語音數(shù)據(jù)的有效識別。
4. 方案效果



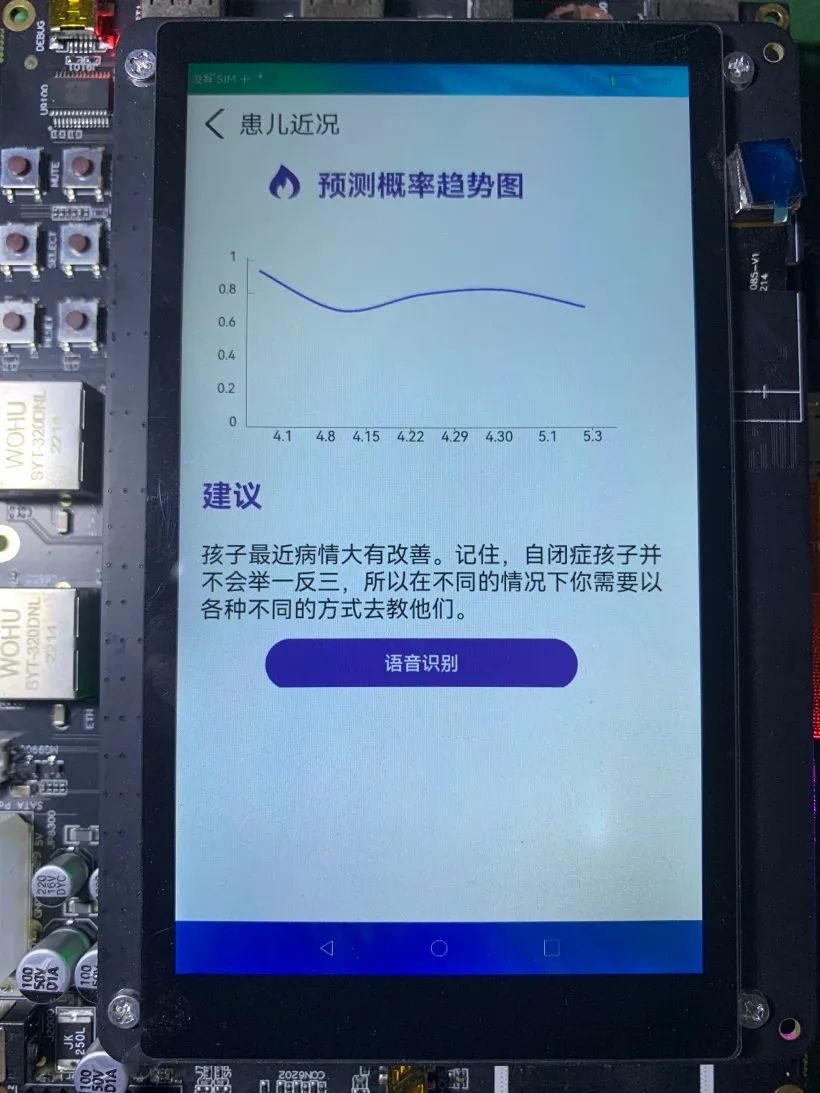
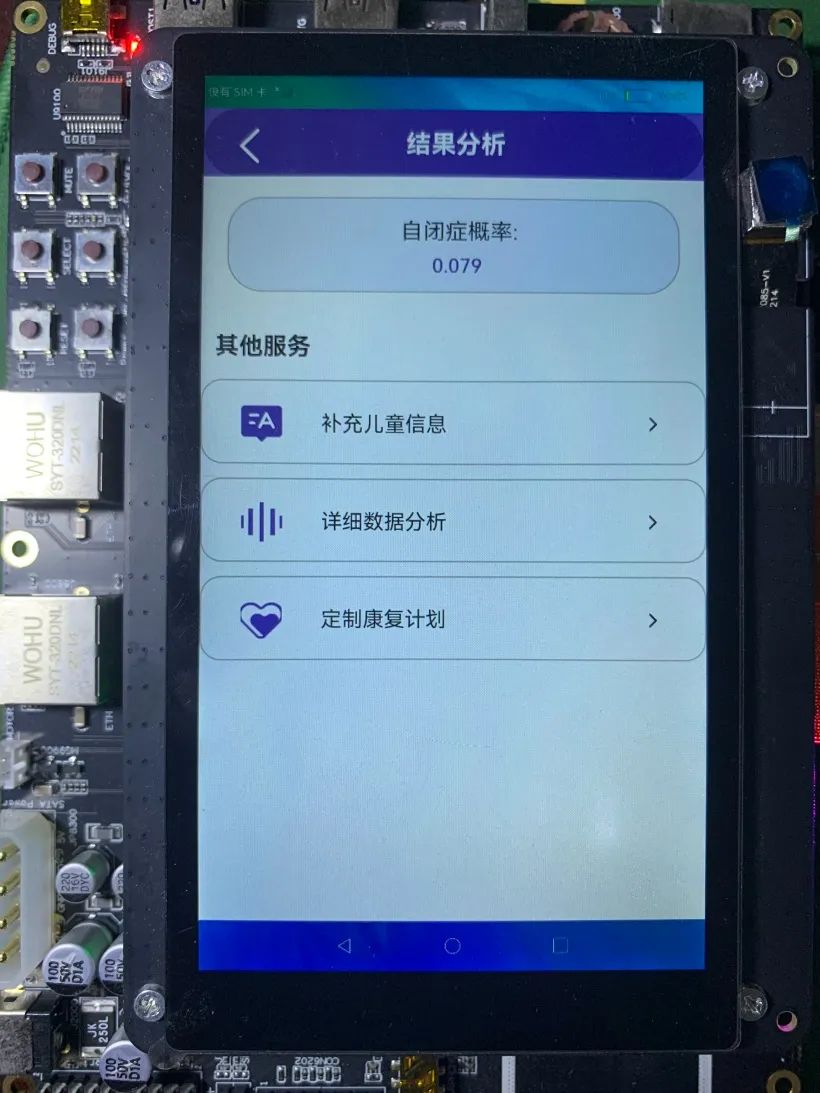
-
DevEco Studio for OpenHarmony3.0.0.900
-
OpenHarmony版本:3.1_Release
-
開發(fā)板:DAYU200

 本文完寫在最后我們最近正帶著大家玩嗨OpenHarmony。如果你有好玩的東東,歡迎投稿,讓我們一起嗨起來!有點子,有想法,有Demo,立刻聯(lián)系我們:合作郵箱:zzliang@atomsource.org
本文完寫在最后我們最近正帶著大家玩嗨OpenHarmony。如果你有好玩的東東,歡迎投稿,讓我們一起嗨起來!有點子,有想法,有Demo,立刻聯(lián)系我們:合作郵箱:zzliang@atomsource.org
 |




















原文標題:玩嗨OpenHarmony:基于OpenHarmony的自閉癥早期篩查聲紋特征濾波識別系統(tǒng)
文章出處:【微信公眾號:開源技術服務中心】歡迎添加關注!文章轉載請注明出處。
-
開源技術
+關注
關注
0文章
389瀏覽量
7946 -
OpenHarmony
+關注
關注
25文章
3724瀏覽量
16350
原文標題:玩嗨OpenHarmony:基于OpenHarmony的自閉癥早期篩查聲紋特征濾波識別系統(tǒng)
文章出處:【微信號:開源技術服務中心,微信公眾號:共熵服務中心】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
RFID識別系統(tǒng)
可穿戴壓電傳感器在肌少癥篩查的應用
第三屆OpenHarmony技術大會星光璀璨、致謝OpenHarmony社區(qū)貢獻者
基于ArkTS語言的OpenHarmony APP應用開發(fā):HelloOpenharmony

【開源鴻蒙】使用QEMU運行OpenHarmony輕量系統(tǒng)
多目標智能識別系統(tǒng)
開源鴻蒙 編譯OpenHarmony輕量系統(tǒng)QEMU RISC-V版本
OpenHarmony之開機優(yōu)化
OpenHarmony 成功亮相國際學術會議 ASPLOS 2024

OpenHarmony南向能力征集令
OpenHarmony內(nèi)核編程實戰(zhàn)

【OpenHarmony鴻蒙實戰(zhàn)】在RK3399開發(fā)板實現(xiàn)智能門禁人臉識別

介紹一種OpenAtom OpenHarmony輕量系統(tǒng)適配方案

淺談兼容 OpenHarmony 的 Flutter
廈門大學OpenHarmony技術俱樂部正式揭牌成立






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論