 總線級數據中心網絡技術
總線級數據中心網絡技術
據Hyperion Research 公司按照系統驗收的時間估算,2021至2026年期間,全球將建成28~38臺E級或接近 E 級的超級計算機。
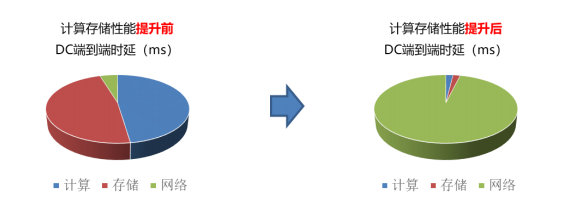
在原先傳統數據中心內,計算存儲性能未提升前,端到端的時延主要在端側,即計算和存儲所消耗的時延占比較大,而當計算存儲器件性能大幅提升后,網絡成為了數據中心內端到端的性能瓶頸。下圖顯示了計算存儲性能提升前后,端到端時延的占比變化。
01RDMA 技術實現業務加速
但制式種類繁多
存儲和計算性能提升后,數據中心內二者的訪問時延已經從 10ms優化達到了 20us 的水平量級,相比原來有了近千倍的提升。而此時,如若仍舊采用基于 TCP 協議的網絡傳輸機制,由于 TCP 的丟包重傳機制,其網絡時延仍舊維持在 ms 級水平,無法滿足高性能計算存儲對于時延的要求。此時,RDMA 技術的出現,為網絡性能的提升提供了新的技術思路。
RDMA 是一種概念,在兩個或者多個計算機進行通訊的時候使用 DMA, 從一個主機的內存直接訪問另一個主機的內存。傳統的 TCP/IP 技術在數據包處理過程中,要經過操作系統及其他軟件層,需要占用大量的服務器資源和內存總線帶寬,數據在系統內存、處理器緩存和網絡控制器緩存之間來回進行復制移動,給服務器的 CPU 和內存造成了沉重負擔。尤其是網絡帶寬、處理器速度與內存帶寬三者的嚴重“不匹配性”,更加劇了網絡延遲效應。
RDMA 是一種新的直接內存訪問技術,RDMA 讓計算機可以直接存取其他計算機的內存,而不需要經過處理器的處理。RDMA 將數據從一個系統快速移動到遠程系統的內存中,而不對操作系統造成任何影響。
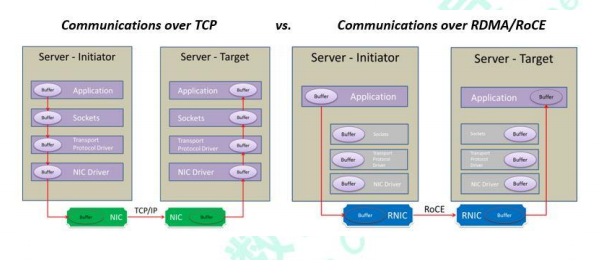
在實現上,RDMA 實際上是一種智能網卡與軟件架構充分優化的遠端內存直接高速訪問技術,通過將 RDMA 協議固化于硬件(即網卡)上,以及支持 Zero-copy和 Kernel bypass 這兩種途徑來達到其高性能的遠程直接數據存取的目標。下圖為 RDMA 工作的原理圖,其通信過程使得用戶在使用 RDMA 時具備如下優勢:
?零拷貝(Zero-copy) - 應用程序能夠直接執行數據傳輸,在不涉及到網絡軟件棧的情況下。數據能夠被直接發送到緩沖區或者能夠直接從緩沖區里接收,而不需要被復制到網絡層。
?內核旁路(Kernel bypass) - 應用程序可以直接在用戶態執行數據傳輸,不需要在內核態與用戶態之間做上下文切換。
?不需要 CPU 干預(No CPU involvement) - 應用程序可以訪問遠程主機內存而不消耗遠程主機中的任何 CPU。遠程主機內存能夠被讀取而不需要遠程主機上的進程(或 CPU)參與。遠程主機的 CPU 的緩存(cache)不會被訪問的內存內容所填充。
?消息基于事務(Message based transactions) - 數據被處理為離散消息而不是流,消除了應用程序將流切割為不同消息/事務的需求。
?支持分散/聚合條目(Scatter/gather entries support) - RDMA 原生態支持分散/聚合。也就是說,讀取多個內存緩沖區然后作為一個流發出去或者接收一個流然后寫入到多個內存緩沖區里去。
目前,RDMA 技術在超算、AI 訓練、存儲等多個高性能場景大量部署,已形成廣泛應用。但是 RDMA 技術路線也有很多,用戶及各家廠商對于 RDMA 技術路線的選擇也不盡相同。
在三種主流的 RDMA 技術中,可以劃分為兩大陣營。一個是 IB 技術, 另一個是支持 RDMA 的以太網技術(RoCE 和 iWARP)。其中,IBTA 主要聚焦 IB 和 RoCE 技術,而 iWARP 則是在 IEEE/IETF 標準化的技術。在存儲領域,支持 RDMA 的技術早就存在,比如SRP(SCSI RDMA Protocol)和iSER(iSCSI Extensions for RDMA)。如今興起的 NVMe over Fabrics 如果使用的不是 FC 網絡的話,本質上就是 NVMe over RDMA。換句話說,NVMe over InfiniBand, NVMe over RoCE 和 NVMe over iWARP 都是 NVMe over RDMA。
02RoCE 成為主流
但仍難以滿足業務需求
以太網自面世以來,其生態開放多元、速率高速增長、成本優勢明顯,因此業界應用十分廣泛。在 RDMA 的多種技術路線中,RoCE 技術的應用最為廣泛。在全球著名高性能計算榜單 Top500 中,以太互聯技術占比超過一半。
然而受限于傳統以太網絡的性能瓶頸,一般的 RoCE 應用在高性能業務中,仍然存在擁塞丟包、延遲抖動等性能損失,難以滿足高性能計算和存儲的需求。
在高性能存儲集群中,FC 網絡具備連接保持技術,網絡升級&進程故障業務不感知,同時 FC 協議長幀頭具備傳輸功能保障,協議開銷小,網絡無丟包,數據幀按序傳送,網絡可靠、時延低。相比 FC,傳統以太網容易出現擁塞丟包現象,丟包重傳容易產生數據亂序,網絡抖動較大,并且以太網采用的存儲轉發模式,查找流程較為復雜導致轉發時延較高,多打一場景會導致隊列積壓加劇,隊列時延不可忽視。在 HPC 應用中,傳統以太消息封裝能力較弱,查表流程復雜導致轉發時延較高,網絡的傳輸損失會造成處理器空閑等待數據,進而拖累整體并行計算性能,根據 2017 年 ODCC 組織的測試結果,傳統以太和專網相比,在超算集群應用下,性能最高相差 30%。
03總線級數據中心網絡
DCN全以太超融合發展
高性能計算在金融、證券、教育、工業、航天、氣象等行業廣泛應用,而時延是關鍵性能指標之一。由于以太網丟包、傳輸轉發機制等諸多原因,基于傳統以太的數據中心網絡時延大多處于毫秒級水平,無法支撐高性能計算業務。要使得 DC as a Computer 成為可能,數據中心網絡時延需要向總線級看齊。
04總線級數據中心網絡內涵
傳統以太時延較高,無法滿足以高性能計算的性能要求。更為嚴峻的是,當前我國高性能存儲和高性能計算所采用的高端網絡互聯設備,均被國外廠商壟斷,價格昂貴、專網設備互通性差,并存在關鍵供貨被卡脖子的風險。
由于以太網的丟包、傳輸、轉發等諸多原因,傳統的數據中心網絡時延大多處于 ms 級水平,無法支撐高性能計算業務。隨著高性能業務的飛速發展,計算設備已由原先以 CPU 為代表的通用器件,轉而發展為以 GPU 為主的高性能器件,器件的性能大幅提升,這對以太網絡的性能提出了更高的要求。網絡時延由四部分組成:
動態時延:主要由排隊時延產生,受端口擁塞影響;
靜態時延:主要包括網絡轉發(查表)時延和轉發接口時延,一般為固定值,當前以太交換靜態時延遠高于超算專網;
網絡跳數:指消息在網絡中所經歷的設備數;
入網次數:指消息進入網絡的次數。總線級數據中心網絡在動態時延、靜態時延、網絡跳數以及入網次數幾個方面均作出了系統性的優化,大幅優化了網絡性能,已滿足高性能計算場景的實際訴求。
05極低靜態轉發時延技術,
轉發時延從us降至百ns
傳統的以太交換機在轉發層面,因需要考慮兼容性、支持眾多協議,導致轉發流程復雜,轉發時延較大。與此同時,以太查表算法復雜、查表時延大,導致整體轉發處理時延長。目前業界主流商用以太交換機的靜態轉發時延大約在600ns-1us 左右。面向大數據存儲和高性能計算業務,若要以太網做到低時延,必須優化轉發流程,降低數據轉發時延。
總線級數據中心網絡技術提出了一種極簡低時延以太轉發機制,利用虛擬短地址,實現了快速線性表轉發。基于虛擬地址路由轉發技術,解決了傳統二層環路和鏈路利用率的問題,同時保證了規模部署和擴展靈活性。
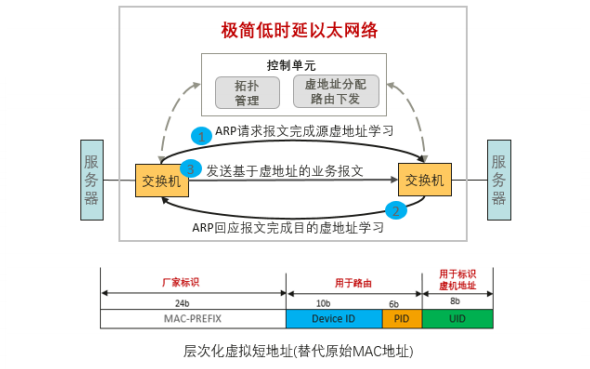
根據應用實測,目前低時延機制轉發機制能實現 30ns 以太芯片報文處理,實現 100ns 左右端到端單跳轉發靜態時延。該時延相比于業界主流歐美廠商的以太芯片轉發時延,提升了 6-10 倍。
06Bufferless 無阻塞流控技術,
亞us級動態時延
網絡擁塞會引起數據包在網絡設備中排隊甚至導致隊列溢出而丟棄,是導致網絡高動態時延的主要原因。
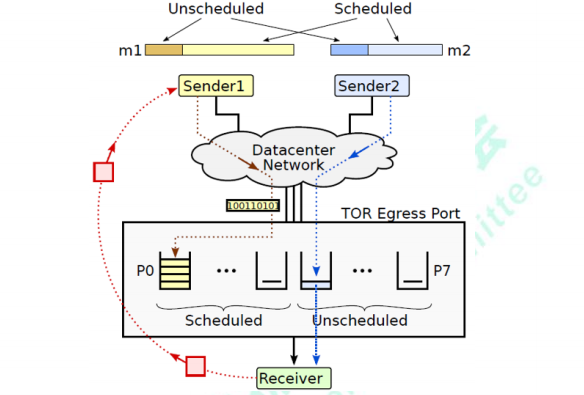
總線級數據中心網絡技術創新提出了收發混合驅動的網絡擁塞控制機制。數據報文分為無調度(Unscheduled)和有調度(Scheduled)兩類:無調度報文在端口級有限窗口控制下直接發送,快速啟動,保證高吞吐;有調度報文由接收端分配令牌報文(Token)后繼續發送,限制流量注入,提供(近似)零隊列,支撐更大的網絡規模。對兩類報文進行協同調度,進一步保證高吞吐低隊列。收發混合驅動的網絡擁塞控制機制實現了數據中心網絡高吞吐和近似零隊列,支撐大規模網絡動態實時無阻塞。
最大吞吐保證:僅優先發送部分報文,同樣提供最大吞吐保證。
極低平均隊列時延:通過接收端調度,嚴格控制網絡注入流量,保證接近于0的平均隊列時延。
極低最大隊列時延:對于不由接收端調度的報文,通過窗口限制注入流量,不會出現大幅震蕩,保證最大隊列時延極低。
07DCI 長距無損技術動態時延,
100KM內長距無損
在高性能存儲業務使用環境中,數據中心交換機之間涉及到遠端設備之間的擁塞問題。傳統的鏈路層流控技術采用粗暴的“停等”機制,當下游設備發現接收能力小于上游設備的發送能力時,會主動發 Pause 幀給上游設備,要求暫停流量的發送。若采用傳統的流控機制,數據中心網絡遠端設備之間的流控會導致極高時延,以 100km 舉例,100Gbps 傳輸速率為例,基于傳統的 PFC 機制的設備間流控機制會產生將近 2ms 的時延,無法滿足高性能應用的性能要求。
針對這個問題,總線級數據中心網絡提出了“點剎”式長距互聯的流控機制。采用細粒度的周期性掃描方式進行流控;每個周期檢測入口 buffer 的變化速率,通過創新算法計算要求上游停止發送時間;構造反壓幀,發送給上游設備,包含了要求上游停止發送的時間。
08網絡新拓撲架構路由技術,
大規模組網實現跳數下降20%
針對高性能計算場景,數據中心的流量特征關注靜態時延,需要支持超大規模,傳統的 CLOS 架構作為主流的網絡架構,其主要關注通用性,但是犧牲了時延和性價比。業界針對該問題開展了多樣的架構研究和新拓撲的設計。
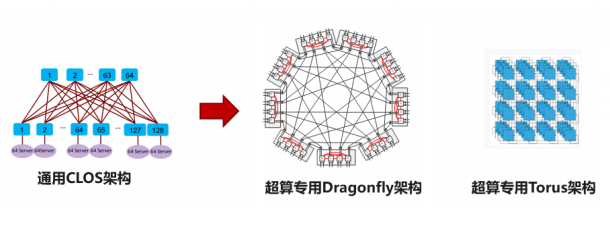
當前數據中心網絡架構設計大多基于工程經驗,不同搭建方式之間難以選擇,缺乏理論指導,缺乏統一性設計語言。另外網絡拓撲性能指標繁多,不同指標之間相互制約,指標失衡很難避免。
09網算一體技術,
減少入網次數提升通信效率
隨著分布式集群規模的增大,以及單節點算力的增長,分布式集群系統已經逐漸從計算約束轉換為網絡通信約束。一方面,在過去 5 年,GPU 算力增長了近90 倍,而網絡帶寬僅增長了 10 倍;另一方面,當前的集群系統中,當 GPU 集群達到一定規模以后,即使增加計算節點數,但由于分布式集群節點之間通信代價的增加,仍可能導致集群每秒訓練的圖片數量不增反減。
10總結與展望
數據中心集合了極其豐富的軟硬件資源,從芯片到服務器,從存儲設備到網絡設施,從平臺軟件到應用軟件,不一而足。要構建強大算力,各類資源需要高度協同,深度融合。超融合正在成為下一代數據中心網絡架構的內涵與精髓,政府、金融、運營商、互聯網等行業存在巨大的融合需求。
可以預見,未來超融合數據中心網絡與垂直行業的結合將會更加緊密。在這個長期的探索過程中,超融合數據中心網絡邁出了堅實的一步。基于總線級數據中心網絡技術的超融合數據中心打破了異構協議間的屏障,提升數據跨資源的流通和處理效率,提高算力能效比。在全國一體化大數據中心建設的今天,必將為數據中心新基建的發展提供網絡性能的堅實保障。
審核編輯 :李倩
-
總線
+關注
關注
10文章
2900瀏覽量
88317 -
數據中心
+關注
關注
16文章
4855瀏覽量
72341 -
RDMA
+關注
關注
0文章
78瀏覽量
8972
原文標題:總線級數據中心網絡技術
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NIDA發布《智算數據中心網絡建設技術要求》
Meta AI數據中心網絡用了哪家的芯片
當今數據中心新技術趨勢

戴爾科技如何幫助巴克利改造升級數據中心
云數據中心、智算中心、超算中心,有何區別?

數據中心液冷需求、技術及實際應用
CXL技術:全面升級數據中心架構










 工商網監
工商網監
評論