 能否在邊緣進行訓練(on-device training),使設備不斷的自我學習?
能否在邊緣進行訓練(on-device training),使設備不斷的自我學習?
該研究提出了第一個在單片機上實現訓練的解決方案,并且系統協同設計(System-Algorithm Co-design)大大減少了訓練所需內存。
說到神經網絡訓練,大家的第一印象都是 GPU + 服務器 + 云平臺。傳統的訓練由于其巨大的內存開銷,往往是云端進行訓練而邊緣平臺僅負責推理。然而,這樣的設計使得 AI 模型很難適應新的數據:畢竟現實世界是一個動態的,變化的,發展的場景,一次訓練怎么能覆蓋所有場景呢?
為了使得模型能夠不斷的適應新數據,我們能否在邊緣進行訓練(on-device training),使設備不斷的自我學習?在這項工作中,我們僅用了不到 256KB 內存就實現了設備上的訓練,開銷不到 PyTorch 的 1/1000,同時在視覺喚醒詞任務上 (VWW) 達到了云端訓練的準確率。該項技術使得模型能夠適應新傳感器數據。用戶在享受定制的服務的同時而無需將數據上傳到云端,從而保護隱私。

網站:https://tinytraining.mit.edu/
論文:https://arxiv.org/abs/2206.15472
Demo: https://www.bilibili.com/video/BV1qv4y1d7MV
代碼: https://github.com/mit-han-lab/tiny-training
背景
設備上的訓練(On-device Training)允許預訓練的模型在部署后適應新環境。通過在移動端進行本地訓練和適應,模型可以不斷改進其結果并為用戶定制模型。例如,微調語言模型讓其能從輸入歷史中學習;調整視覺模型使得智能相機能夠不斷識別新的物體。通過讓訓練更接近終端而不是云端,我們能有效在提升模型質量的同時保護用戶隱私,尤其是在處理醫療數據、輸入歷史記錄這類隱私信息時。
然而,在小型的 IoT 設備進行訓練與云訓練有著本質的區別,非常具有挑戰性,首先, AIoT 設備(MCU)的 SRAM 大小通常有限(256KB)。這種級別的內存做推理都十分勉強,更不用說訓練了。再者,現有的低成本高效轉移學習算法,例如只訓練最后一層分類器 (last FC),只進行學習 bias 項,往往準確率都不盡如人意,無法用于實踐,更不用說現有的深度學習框架無法將這些算法的理論數字轉化為實測的節省。最后,現代深度訓練框架(PyTorch,TensorFlow)通常是為云服務器設計的,即便把 batch-size 設置為 1,訓練小模型 (MobileNetV2-w0.35) 也需要大量的內存占用。因此,我們需要協同設計算法和系統,以實現智能終端設備上的訓練。

方法與結果
我們發現設備上訓練有兩個獨特的挑戰:(1)模型在邊緣設備上是量化的。一個真正的量化圖(如下圖所示)由于低精度的張量和缺乏批量歸一化層而難以優化;(2)小型硬件的有限硬件資源(內存和計算)不允許完全反向傳播,其內存用量很容易超過微控制器的 SRAM 的限制(一個數量級以上),但如果只更新最后一層,最后的精度又難免差強人意。
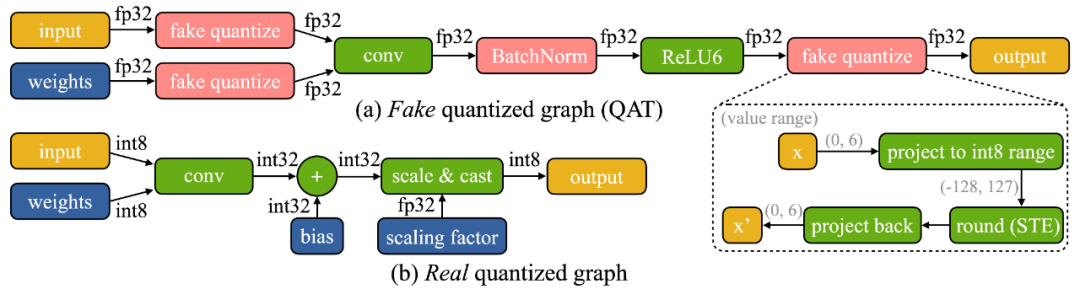
為了應對優化的困難,我們提出了 Quantization-Aware Scaling (QAS) 來自動縮放不同位精度的張量的梯度(如下左圖所示)。QAS 在不需要額外超參數的同時,可以自動匹配梯度和參數 scale 并穩定訓練。在 8 個數據集上,QAS 均可以達到與浮點訓練一致的性能(如下右圖)。

為了減少反向傳播所需要的內存占用,我們提出了 Sparse Update,以跳過不太重要的層和子張的梯度計算。我們開發了一種基于貢獻分析的自動方法來尋找最佳更新方案。對比以往的 bias-only, last-k layers update, 我們搜索到的 sparse update 方案擁有 4.5 倍到 7.5 倍的內存節省,在 8 個下游數據集上的平均精度甚至更高。
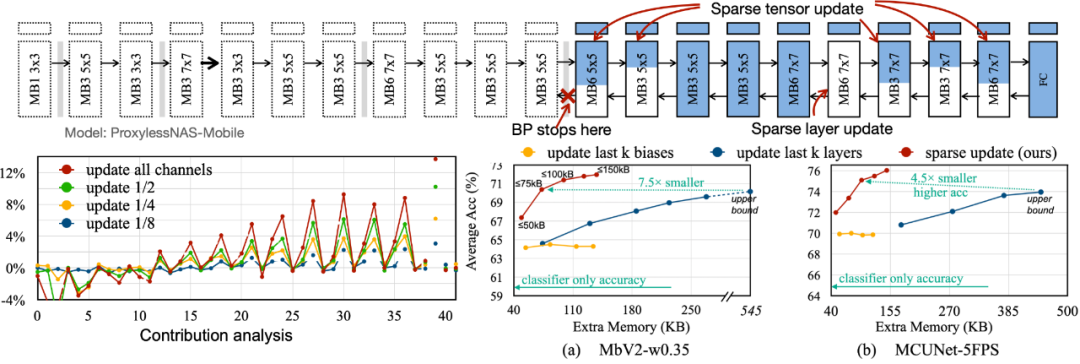
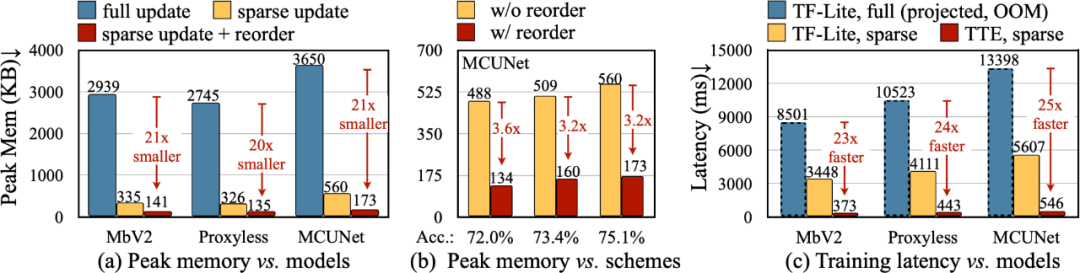
為了將算法中的理論減少轉換為實際數值,我們設計了 Tiny Training Engine(TTE):它將自動微分的工作轉到編譯時,并使用 codegen 來減少運行時開銷。它還支持 graph pruning 和 reordering,以實現真正的節省與加速。與 Full Update 相比,Sparse Update 有效地減少了 7-9 倍的峰值內存,并且可以通過 reorder 進一步提升至 20-21 倍的總內存節省。相比于 TF-Lite,TTE 里經過優化的內核和 sparse update 使整體訓練速度提高了 23-25 倍。

結論
本文中,我們提出了第一個在單片機上實現訓練的解決方案(僅用 256KB 內存和 1MB 閃存)。我們的算法系統協同設計(System-Algorithm Co-design)大大減少了訓練所需內存(1000 倍 vs PyTorch)和訓練耗時(20 倍 vs TF-Lite),并在下游任務上達到較高的準確率。Tiny Training 可以賦能許多有趣的應用,例如手機可以根據用戶的郵件 / 輸入歷史來定制語言模型,智能相機可以不斷地識別新的面孔 / 物體,一些無法聯網的 AI 場景也能持續學習(例如農業,海洋,工業流水線)。通過我們的工作,小型終端設備不僅可以進行推理,還可以進行訓練。在這過程中個人數據永遠不會上傳到云端,從而沒有隱私風險,同時 AI 模型也可以不斷自我學習,以適應一個動態變化的世界
審核編輯 :李倩
-
內存
+關注
關注
8文章
3037瀏覽量
74148 -
IOT
+關注
關注
187文章
4217瀏覽量
197071
原文標題:用少于256KB內存實現邊緣訓練,開銷不到PyTorch千分之一
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
在邊緣設備上設計和部署深度神經網絡的實用框架
邊緣學習:降本增效,開啟物流新未來
AI模型部署邊緣設備的奇妙之旅:如何實現手寫數字識別
LLM和傳統機器學習的區別

邊緣計算與邊緣設備的關系
FPGA做深度學習能走多遠?
如何使物聯網邊緣設備高效節能?





 工商網監
工商網監
評論