") 人工智能需要新的范式和理論
人工智能需要新的范式和理論
馮 · 諾伊曼的《計算機和人腦》是人類歷史上第一部將計算機和人腦相提并論的著作。這位科學巨人希望比較計算機和人腦的計算機制,為未來建立統(tǒng)一的計算理論打下基礎。事實上,建立計算機和人腦的統(tǒng)一計算理論是馮 · 諾伊曼晚年研究的主要課題。他所關注的統(tǒng)一計算理論應該也是人工智能領域的核心問題。站在人工智能的角度,人腦是智能系統(tǒng)的代表,應該從人腦的計算機制得到啟發(fā),開發(fā)出未來的智能計算理論和方法。
本文首先通過字節(jié)跳動人工智能實驗室的一些研究成果介紹最前沿的人工智能技術,總結這一兩年來人工智能領域的研究發(fā)展動態(tài)。之后分享我們對人工智能領域長期發(fā)展的看法。主張人工智能的未來需要新的計算范式和新的計算理論。具體地,腦啟發(fā)計算(brain-inspired computing)應是重要的探索方向;從信息、數(shù)據(jù)、模型角度的學習理論研究至關重要。
人工智能的最新動態(tài)
這一兩年來人工智能特別是深度學習的研究又有了令人矚目的進展。主要體現(xiàn)在幾個方面。Transformer 模型及其變種被廣泛應用到各個領域,包括語言、語音、圖像。人工智能各個子領域的差異更多地體現(xiàn)在數(shù)據(jù)和應用問題上,使用的模型和算法趨于相同。基于大數(shù)據(jù)的模型預訓練或自監(jiān)督學習被廣泛使用,成為各個領域學習和推理的基礎。深度學習實現(xiàn)的是類推推理,如何實現(xiàn)邏輯推理也成為研究的重要課題。人工智能技術被廣泛應用到各個領域,在實際應用中的可信賴 AI 問題也成為關注的焦點,包括深度學習的可解釋性,公平性等。深度學習技術也被推廣應用到其他領域,典型的是科學智能(AI for Science),即用深度學習技術解決物理、化學、生物、醫(yī)藥學問題的新方向。總結趨勢如下。
Transformer 模型一統(tǒng)天下
視覺、聽覺、語言處理的區(qū)別更多在于數(shù)據(jù)
預訓練、自監(jiān)督學習越加重要
從類推推理到邏輯推理
可信賴的 AI 廣受關注
擴展到科學智能等新領域
字節(jié)跳動人工智能實驗室在進行自然語言處理、語音處理、計算機視覺、科學智能、機器人,機器學習公平性等各個領域的技術研究和開發(fā)。這里介紹幾個今年發(fā)表的工作,以展示人工智能最近的發(fā)展動向。具體概述非自回歸模型 DA-Transformer,端到端語音到文本翻譯模型 ConST,多顆粒度的視覺語言模型 X-VLM,圖片和文本統(tǒng)一生成模型 DaVinci,語言理解模型 Neural Symbolic Processor。
更快的 Transformer 模型
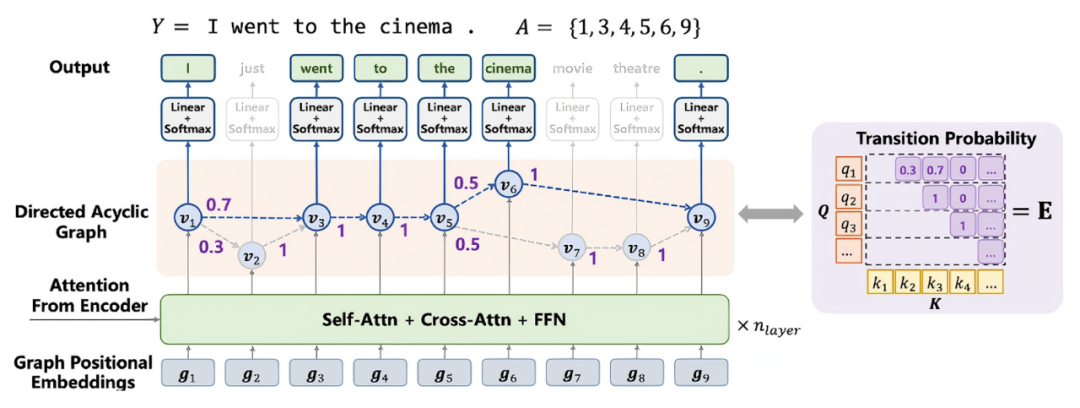
圖 1 DA-Transformer 的架構
Transformer 最初作為機器翻譯模型被提出,后來被廣泛應用于人工智能各個領域。Transformer 的一個大問題是解碼基于自回歸,計算需要一環(huán)扣一環(huán)地進行,速度比較慢。為解決這個問題,非自回歸模型成為最近研究的一個熱點。目前為止提出的非自回歸模型在機器翻譯的精度上沒有能夠與原始的 Transformer 匹敵。我們提出的 DA-Transformer 在機器翻譯上首次達到了 Transformer 同樣的精度,而處理的速度提高了 7~14 倍[1]。DA-Transformer 不僅可以用于機器翻譯,而且可以用于任意的序列到序列任務。
DA-Transformer (Directed Acyclic Graph Transformer)的核心想法是在解碼層的最后一層構建有向無環(huán)圖,如圖 1 所示。有向無環(huán)圖的結點表示生成翻譯(目標語言句子)的狀態(tài),邊表示狀態(tài)之間的轉移。邊上有狀態(tài)轉移概率,結點上有表示向量,生成目標語言單詞。解碼器的輸入是目標語言單詞的位置的索引。有向無環(huán)圖的結點對應著解碼器的輸入,有向邊只能是從前面的位置指向后面的位置。有向無環(huán)圖的從起始位置到終止位置的一條路徑,對應著一個翻譯狀態(tài)的序列,在一條路徑上可以產生目標語言句子(單詞的序列)。其他部分的結構與 Transformer 相同。
DA-Transformer 的解碼是基于并行處理的。在解碼器輸入的各個位置上進行并行計算,得到解碼器最后一層的有向無環(huán)圖的結點上的表示向量。在此基礎上計算各個邊上的轉移概率,從每個位置出發(fā)到達其之后位置的轉移概率是歸一的。這個過程的計算速度非常快。DA-Transformer 的訓練也是基于翻譯數(shù)據(jù)進行極大似然估計。這時一個翻譯(目標語言句子)可以由有向無環(huán)圖的多條路徑產生,翻譯的生成概率要對所有的路徑求和。使用動態(tài)規(guī)劃可以高效地完成一個翻譯概率(似然函數(shù))的計算。DA-Transformer 的推理可以使用多個算法。最簡單的貪心算法從起始位置開始從左到右動態(tài)遞歸地計算到每個位置概率最大的翻譯,直到生成句子終止符為止。
語言和語音的融合ConST
傳統(tǒng)的語音到文本的翻譯是通過語音識別和文本機器翻譯的串聯(lián)實現(xiàn)。這個方法的缺點是推理過程中的錯誤會累加。ConST 可以直接將英語的語音翻譯成中文的文本,而且在語音到文本的翻譯中,達到了 SOTA(state of the art)的效果[2]。
ConST 的架構由 Transformer 的編碼器和解碼器組成(見圖 2)。編碼器既可以接受語音輸入又可以接受文本輸入。輸入是語音時有特殊的前處理模塊,使用 wave2vec2 和 CNN。輸入是文本時處理跟一般的 Transformer 相同。用同一個系統(tǒng)實現(xiàn)語音到文本的語音識別,文本到文本的機器翻譯,語音到文本的語音翻譯。訓練時進行語音識別、文本翻譯、語音翻譯的多任務學習。ConST 的最大特點是,使用對比學習將語義相同的語音輸入的表示和文本輸入的表示拉近。可以理解為對表示學習進行了正則化。圖 2 的下圖左邊直觀說明沒有使用對比學習的表示,右邊直觀說明使用了對比學習之后的表示。
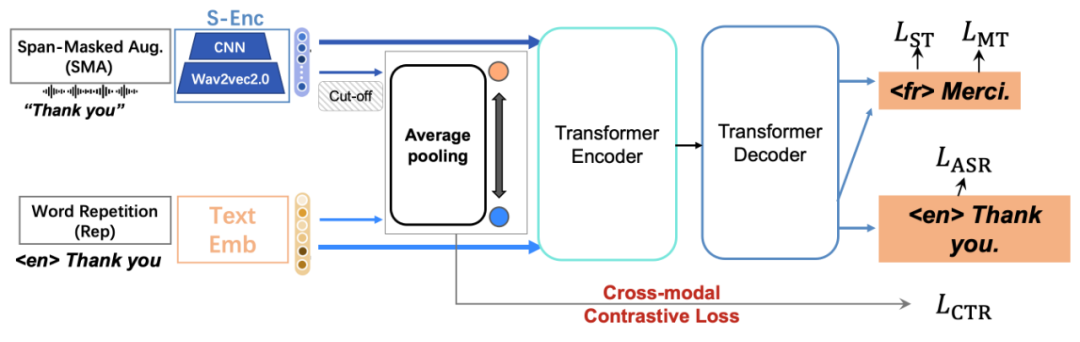
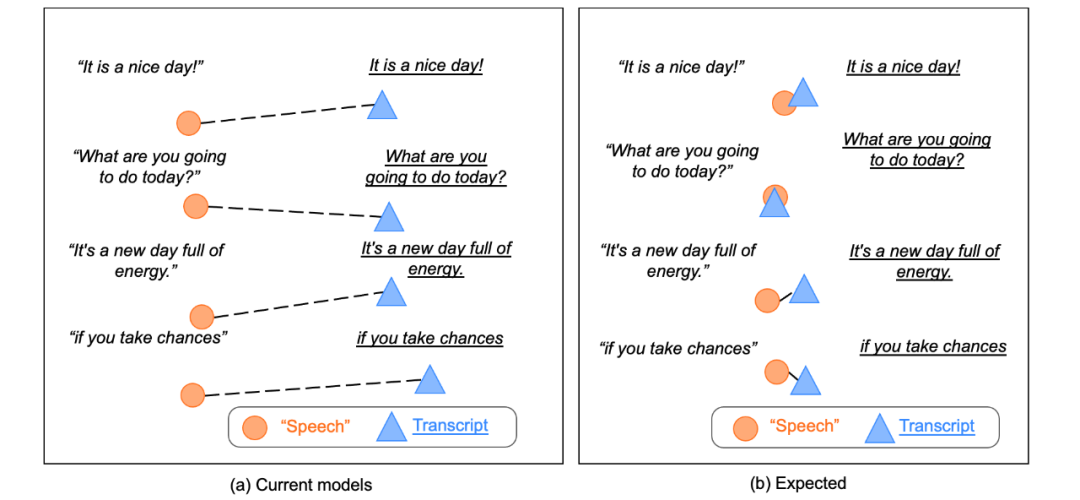
圖 2 ConST 的架構與語義空間
視覺語言預訓練模型X-VLM
X-VLM 是以 Transformer 為基礎,以文本 - 圖片對數(shù)據(jù)作為輸入進行預訓練得到的視覺語言模型,可以用多種跨模態(tài)的下游任務(見圖 3)[3]。具有多模態(tài)處理能力的視覺語言模型是最近研究的熱點。我們這里假設文本和圖片對的內容是強關聯(lián)的,文本描述圖片內容,但描述是多顆粒度的。文本可能描述圖片整體、區(qū)域或物體,如圖 3 所示。這種基礎模型對 visual question answering 和 visual grounding 等任務等更加適用,也可以用于其他任務。X-VLM 是目前視覺語言各種任務的 SOTA。
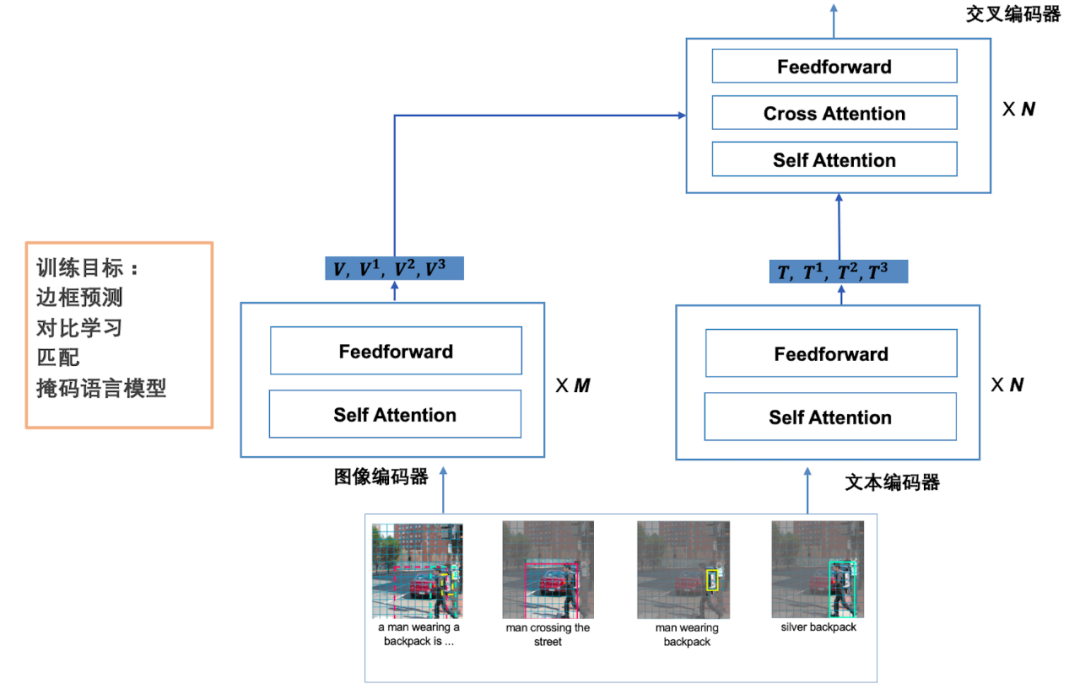
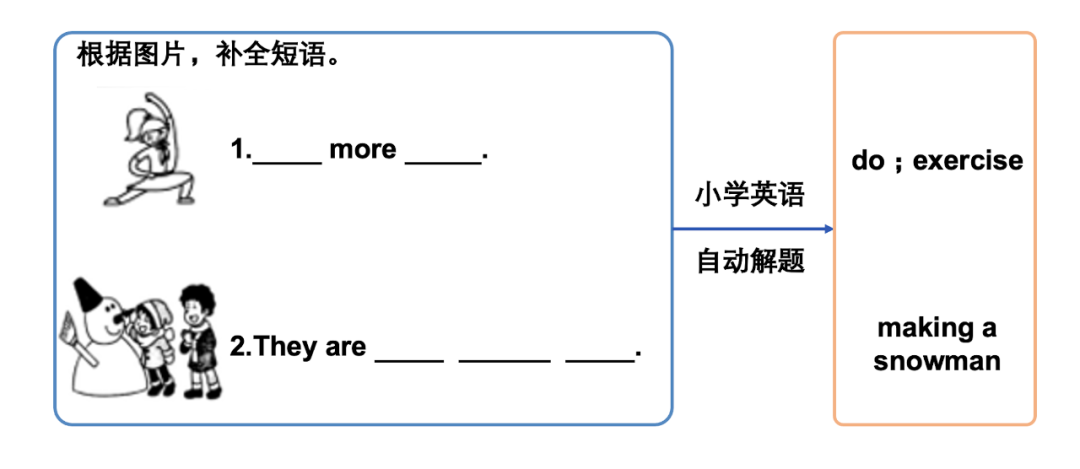
圖 3 X-VLM 的架構和英語解題例
之前的方法都是在訓練之前或訓練之中使用物體檢測,而 X-VLM 完全不使用。從已有數(shù)據(jù)中導出不同顆粒度的文本 - 圖片對數(shù)據(jù),包括物體的名稱和圖像中框出的物體的對應數(shù)據(jù)。模型由文本編碼器、圖像編碼器、交叉編碼器組成。文本編碼器和圖像編碼器是 Transformer 的編碼器,交叉編碼器有從文本到圖像的注意力計算,文本表示作為 query。訓練有四個目標,包括邊框預測、掩碼語言模型、匹配、對比學習。邊框預測是掩蓋物體的邊框,從文本 - 圖片對數(shù)據(jù)中還原邊框,掩碼語言模型掩蓋一些 token 再從文本 - 圖片對數(shù)據(jù)中還原,匹配判斷文本 - 圖片數(shù)據(jù)的匹配程度,對比學習進一步在 batch 數(shù)據(jù)中拉進語義相近的文本和圖片的表示。X-VLM 已經用于多個實際應用,比如圖 3 下的小學英語解題。輸入帶圖的英語填空題,系統(tǒng)可以自動完成填空,這個任務之前是非常困難的。
最近的 X^2-VLM 將 X-VLM 擴展,也可以處理視頻和多語言。實驗結果顯示在 base 和 large 的規(guī)模上 X^2-VLM 是語言視覺任務的最新 SOTA[4]。
DaVinci
Davinci 是更偏文本和圖片生成的多樣化視覺語言處理模型[5]。文本 - 圖片對數(shù)據(jù)作為輸入,假設文本 - 圖片是強關聯(lián)的,文本描述圖片內容。DaVinci 一個模型,完成從文本到圖片生成,從圖片到文本生成,甚至其他的理解和生成等許多任務,在這些任務上達到或接近 SOTA 結果。
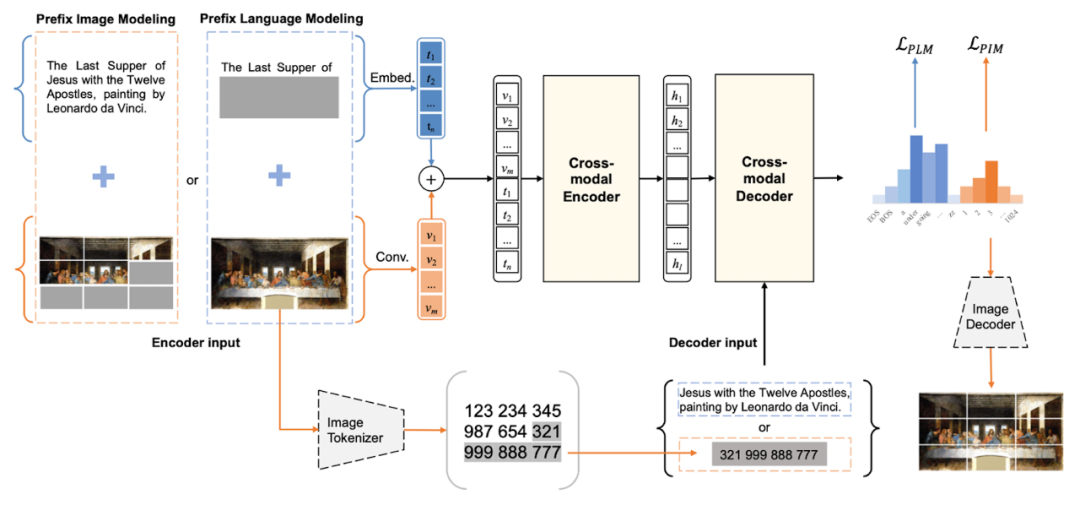

圖 4 DaVinci 的架構和圖片生成例
DaVinci 的模型是 Transformer,如圖 4 上圖所示,預訓練采用 prefix language modeling 的方法。預訓練時,輸入是文本 - 圖片對,將其中的部分文本或部分圖片掩蓋,然后讓數(shù)據(jù)通過 Transformer 的編碼器和解碼器,將被掩蓋的內容還原。事先對圖片進行 image tokenizing 處理,每個圖片的 token 由一個離散的編碼表示,進行了圖像的離散化。還原實際是生成被掩蓋部分的圖片 token,這時沒有被掩蓋的上下文(可能是文本或圖片)幫助生成。沒有被掩蓋的部分就是 prefix。DaVinci 的模型雖然簡單,但可以做高質量的文本和圖片生成。比如,圖 4 中的下圖是給定文本 DaVinci 自動生成的圖片的例子。DaVinci 論證了使用同一個模型是能夠同時學習“寫”(基于圖片的文本生成)和“畫”(基于文本的圖像生成),并且這兩種能力能夠互相促進。
深度學習加邏輯推理Neural Symbolic Processor
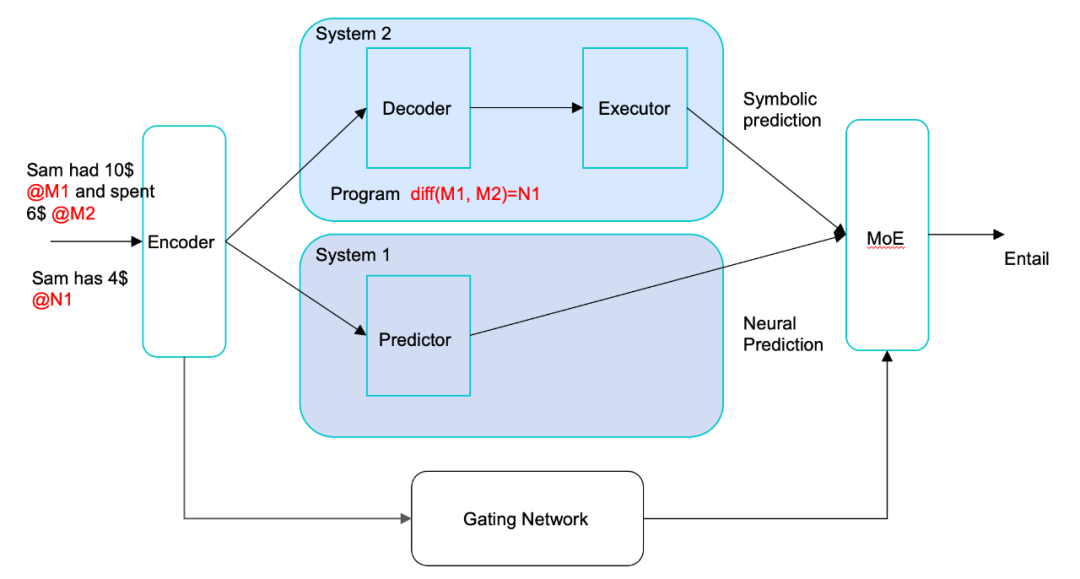
圖 5. NSP 的架構,由系統(tǒng) 1 和系統(tǒng) 2 組成
這里考慮自然語言理解的問題,具體的文本蘊含任務。比如 "Sam 有 10 美元,他花了 6 美元" 這句話和 "Sam 有 4 美元" 這句話存在蘊含關系。傳統(tǒng)的深度學習方法用預訓練語言模型 BERT 判斷,可以達到一定的準確率,但是有很多蘊含關系的判斷需要邏輯推理,包括數(shù)字推理。純深度學習的方法并不能保證做得很好。推測人分別使用系統(tǒng) 1 和系統(tǒng) 2 進行類推推理和邏輯推理,然后進行綜合判斷。
NSP(neural symbolic processing)是模仿人的自然語言理解系統(tǒng),也包含系統(tǒng) 1 和系統(tǒng) 2(見圖 5)[6]。核心想法是將輸入的文本,通過兩路處理分別進行類推推理和邏輯推理。先將輸入通過編碼器轉換成基于向量的內部表示。之后,在系統(tǒng) 1 里基于內部表示進行預測,與基于 BERT 的傳統(tǒng)深度學習方法相似。在系統(tǒng) 2 里將內部表示進行解碼,產生基于符號的內部表示,稱之為程序,接著執(zhí)行程序;可以認為對輸入文本進行了翻譯,轉換成程序。最后,將兩路的處理結果進行集成,產生最終的結果,集成使用 MoE 模型。編碼器和解碼器都基于預訓練語言模型 BART。比如,針對上面的例子,系統(tǒng) 2 產生并執(zhí)行程序,也就是將第 1 個數(shù)字減去第 2 個數(shù)字等于第 3 個數(shù)字(M1-M2=N1)。這樣的機制可以保證無論數(shù)字具體是多少,都可以進行同樣的推理。系統(tǒng) 1 同時進行基于深度模型(編碼器)的預測。兩者的判斷又通過 MoE 得到最終集成結果。NSP 在需要邏輯推理的語言理解任務上比傳統(tǒng)的方法在準確率上有大幅度的提升。
人工智能需要怎樣的計算范式
深度學習雖然取得了很大的進展,但相比人腦的學習和推理能力還相差甚遠,主要體現(xiàn)以下幾個方面。深度學習善于類推推理,但需要邏輯推理時往往無能為力。深度學習依然需要依賴于大模型、大數(shù)據(jù)和大算力,數(shù)據(jù)效率和能源效率要比人低很多。更重要的是,學習和推理往往只能針對具體的任務進行,而不像人腦那樣擁有通用的學習和推理能力。
展望未來,在很長一段時間里機器學習,特別是深度學習仍將是人工智能的主體技術。另一方面,人工智能需要更大的突破,有必要研究和開發(fā)下一代的智能計算技術。我們認為,腦啟發(fā)計算應該是未來發(fā)展的主要方向。最近 Bengio、LeCun 等也提出了類似的主張[7]。這里說的腦啟發(fā)計算并不是簡單地模仿人腦,而是根據(jù)計算機的實際特點參考人腦的機制,構建機器的學習和推理智能系統(tǒng),主體可能還是深度學習,但與深度學習又有本質的不同,屬于新的范式。腦科學家馬爾將計算分為三個層面,分別是功能、算法和實現(xiàn)。腦啟發(fā)計算更多的應該是從功能層面借鑒人腦的機制。希望能解決樣本效率、能源效率、邏輯推理等方面的問題,為領域帶來更大的突破。下面通過幾個例子說明我們所說的腦啟發(fā)計算。
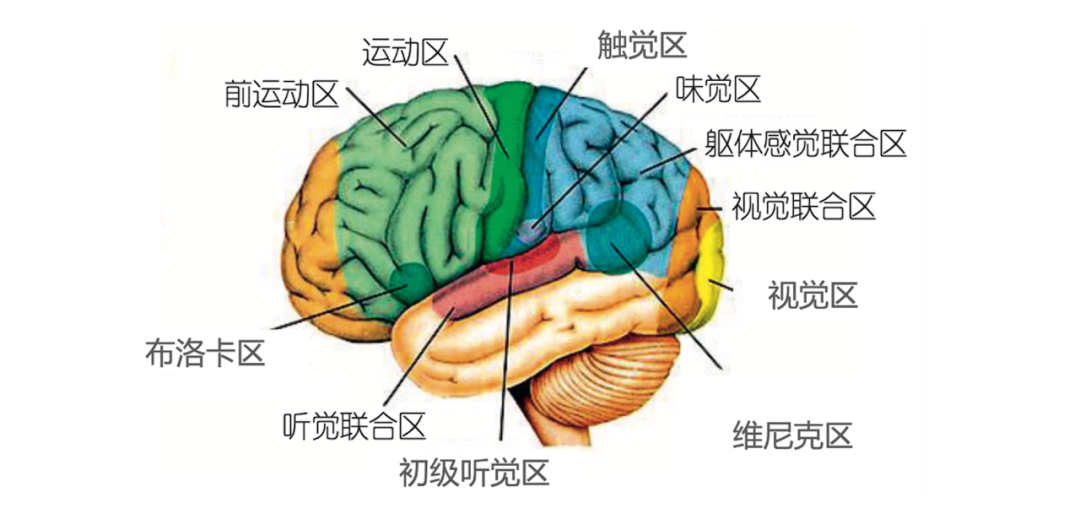
圖 6. 大腦皮層中的主要腦區(qū)
人腦的信息處理分多個腦區(qū)。各個腦區(qū)相對獨立,又相互關聯(lián)(見圖 6)。比如,對自己祖母的記憶,包括視覺、聽覺、語言等方面的信息,分別存儲在不同的腦區(qū)。腦啟發(fā)計算可以參考人腦的分區(qū)處理機制。深度學習中的 MoE(mixture of experts)技術有一定的相關性。
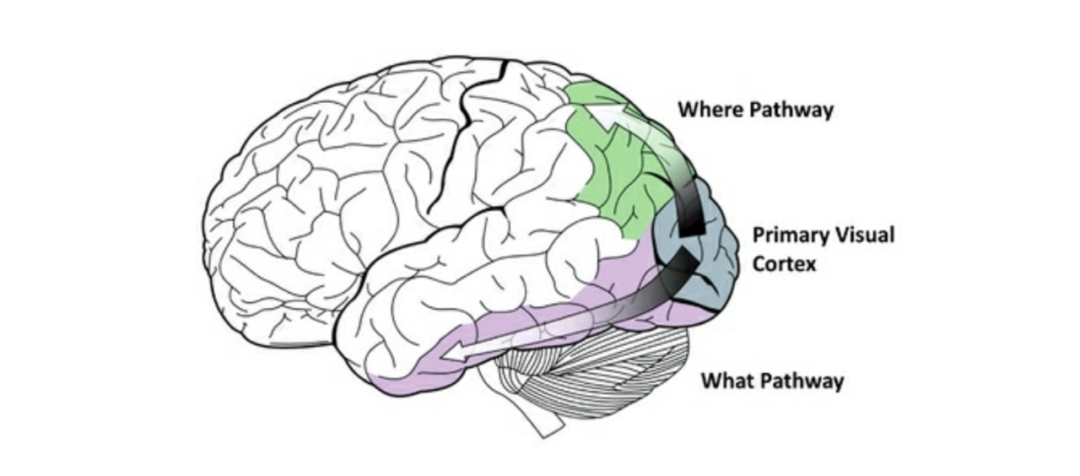
圖 7. 視覺處理的 What 通道和 Where 通道
人腦的視覺處理是分兩個通道進行的,分別是 What 通道和 Where 通道(見圖 7)。What 通道負責識別物體的大小,形狀,顏色,而 Where 通道負責識別物體的空間位置。基于深度學習的圖像識別不將兩者的信息加以區(qū)分。這就可能導致了學習效率的降低。比如,在卷積神經網絡網絡的學習中需要通過數(shù)據(jù)增強的方法,增加樣本訓練模型,以應對圖像中物體的尺度不變性、旋轉不變性。
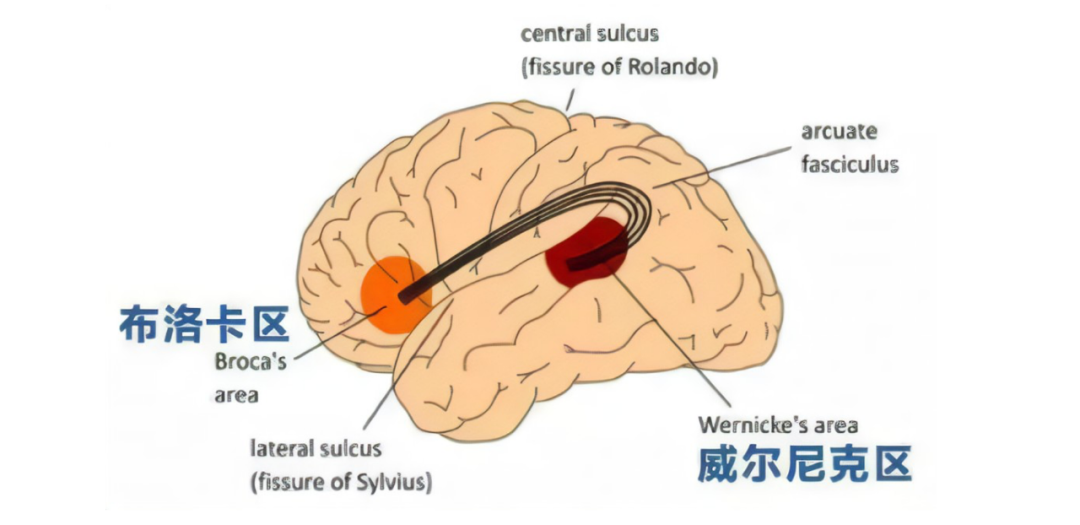
圖 8 語言處理的布洛卡區(qū)和韋尼克區(qū)
人腦的語言處理在布洛卡區(qū)和韋尼克區(qū)同時進行,分別負責語法和詞匯(見圖 8)。人的語言理解和生成是在兩個腦區(qū)并行進行的。而現(xiàn)在基于 Transformer 的語言處理模型都沒有將兩者分開,可能導致訓練需要更多的樣本。
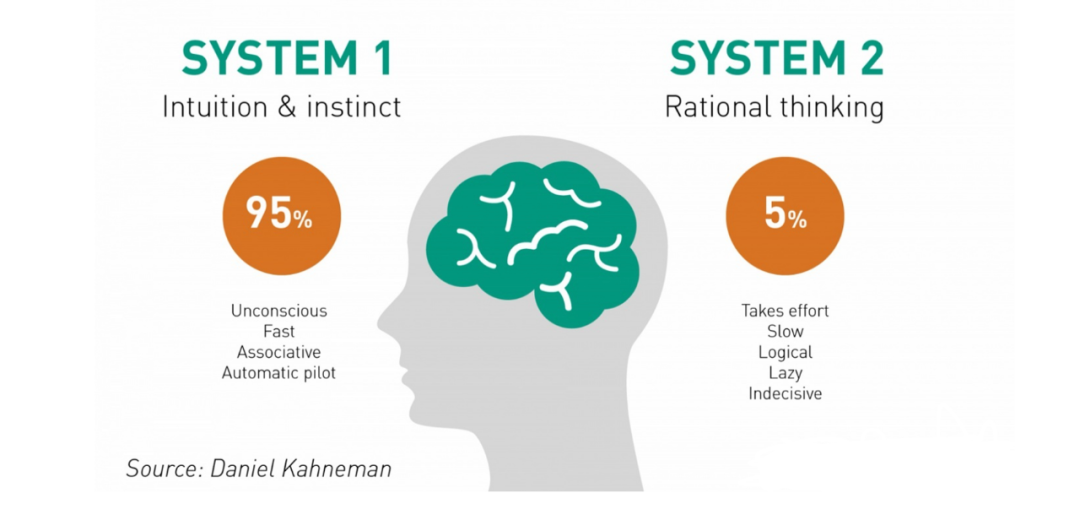
圖 9 人腦信息處理的系統(tǒng) 1 和系統(tǒng) 2
如上所述,人腦的信息處理由系統(tǒng) 1 和系統(tǒng) 2 組成(見圖 9)。如何實現(xiàn)包含系統(tǒng) 1 和系統(tǒng) 2 的智能系統(tǒng),是人工智能的一大課題。Neural Symbolic Processor 等采用的神經符號處理是一條路徑,面向這個方向邁出了一小步。
人的許多感知和認知能力是生來具有的,包括對物理法則、數(shù)量、概率等概念的認識,以及語言的習得和使用。當前的預訓練、自監(jiān)督學習從大量的無監(jiān)督數(shù)據(jù)中自動學習基礎模型,也可以認為學習到的對應著人生來具有的能力。沒有必要假設人工智能系統(tǒng)需要將所有的能力都通過數(shù)據(jù)驅動,機器學習的方法獲取。比如,知識圖譜是一種高質量的結構化數(shù)據(jù),可以直接提供給智能系統(tǒng)作為一種 “生來具有的” 資源使用。
人工智能需要怎樣的計算理論
人工智能的未來發(fā)展同時也需要更強大的機器學習理論指導。用傳統(tǒng)的泛化上界解釋深度學習現(xiàn)象已經明顯遇到了困難。深度學習及腦啟發(fā)計算的現(xiàn)象通常是非常復雜的。我們認為,應該從信息、數(shù)據(jù)、模型等幾個角度出發(fā)建立新的深度學習及腦啟發(fā)計算理論。
具體地應該考慮以下問題。學習和推理過程中信息是如何流動的?數(shù)據(jù)中存在怎樣的內在結構?模型有怎樣的函數(shù)表示能力?最近的一些研究在這些方向取得了一定成果,值得大家關注。這里進行一個簡單總結,也期待出現(xiàn)更完整全面的理論。也建議閱讀馬毅等最近的文章[8]。
信息瓶頸理論
機器學習和數(shù)據(jù)壓縮是一枚硬幣的兩面。無監(jiān)督學習的目標是給定數(shù)據(jù) X 發(fā)現(xiàn)其內在結構 X'。數(shù)據(jù)壓縮是將數(shù)據(jù) X 進行壓縮得到表示 X',并且能從表示 X'還原原始數(shù)據(jù) X。兩者是相互對應的,可以認為數(shù)據(jù)壓縮得到的表示 X'就是無監(jiān)督學習要得到的內在結構 X'。監(jiān)督學習的目標是學習從輸入數(shù)據(jù) X 到輸出 Y 的映射。Tishby 等提出的信息瓶頸理論從數(shù)據(jù)壓縮的角度解釋監(jiān)督學習。將數(shù)據(jù) X 進行充分的壓縮得到表示 X',使得表示 X'對輸出 Y 有充分準確的預測,將兩者分別用互信息表示,進行以下優(yōu)化,最小化 X 和 X'之間的互信息,同時最大化 Y 和 X'之間的互信息,就對應著監(jiān)督學習。這時表示 X'是對預測有用的特征,稱作信息瓶頸。
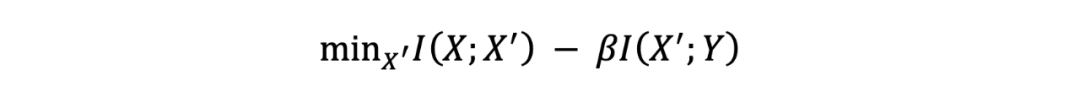
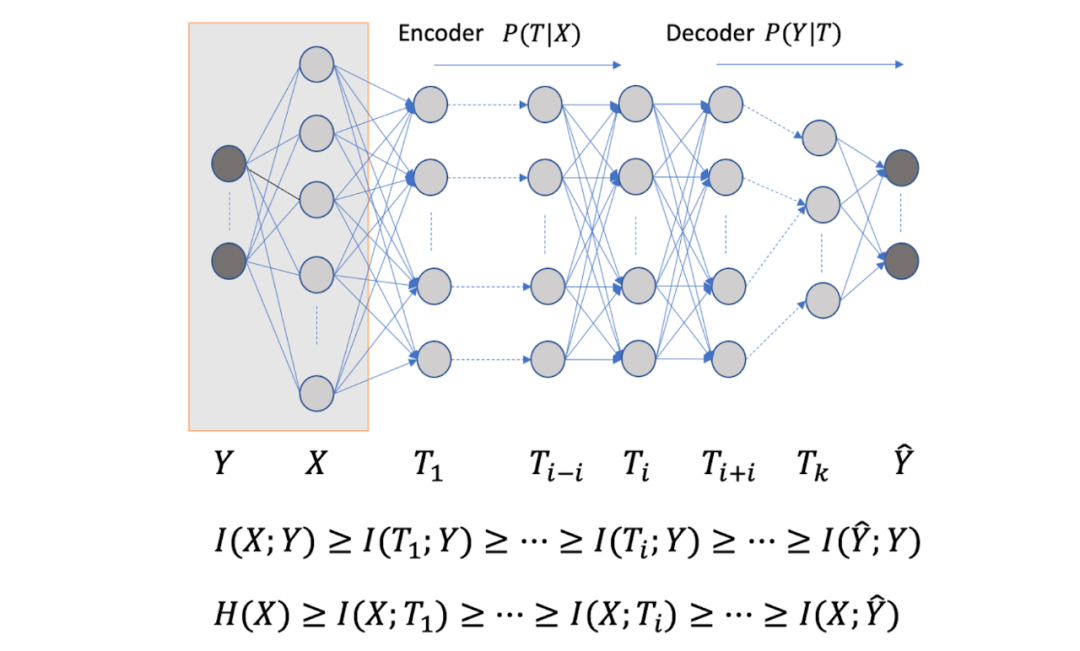
圖 11 信息瓶頸理論解釋神經網絡學習
Tishby 等使用信息瓶頸理論對神經網絡學習的過程進行了分析,得到了一些有意思的分析結果[9]。考慮前饋神經網絡的學習和推理中的信息流動。假設輸入 X 和理想的輸出 Y 的聯(lián)合概率分布已知(理論上假設是已知的,對學習算法來說是未知的)。前饋神經網絡的輸入是 X,輸出是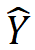 。前饋神經網絡每層由一個隨機變量
。前饋神經網絡每層由一個隨機變量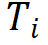 表示。如圖 11 所示,從輸入層 X 到隱層,再從隱層到輸出層
表示。如圖 11 所示,從輸入層 X 到隱層,再從隱層到輸出層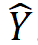 ,構成一個馬爾可夫鏈,可以由有向圖表示。輸入 X 和理想輸出 Y 之間的關系由無向圖表示。前饋神經網絡預測時要保留輸入 X 的信息,互信息?
,構成一個馬爾可夫鏈,可以由有向圖表示。輸入 X 和理想輸出 Y 之間的關系由無向圖表示。前饋神經網絡預測時要保留輸入 X 的信息,互信息?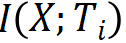 ?減少或不變。滿足數(shù)據(jù)處理不等式,當且僅當處理后是充分統(tǒng)計量時互信息不變。同時要對理想輸出 Y 有預測能力,使得互信息
?減少或不變。滿足數(shù)據(jù)處理不等式,當且僅當處理后是充分統(tǒng)計量時互信息不變。同時要對理想輸出 Y 有預測能力,使得互信息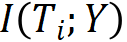 盡量保持不變。信息瓶頸理論,認為學習的過程就是對輸入 X 互信息減少,對理想輸出 Y 互信息保持不變的神經網路參數(shù)調節(jié)過程。每一層兼顧對輸入的壓縮和對輸出的預測作用,認為每一層存在著對輸入的 encoder 和對輸出的 decoder。
盡量保持不變。信息瓶頸理論,認為學習的過程就是對輸入 X 互信息減少,對理想輸出 Y 互信息保持不變的神經網路參數(shù)調節(jié)過程。每一層兼顧對輸入的壓縮和對輸出的預測作用,認為每一層存在著對輸入的 encoder 和對輸出的 decoder。
在模擬實驗中(假設輸入 X 和輸出 Y 已知),用交叉熵和 SGD 訓練一個 5 層的前饋神經網絡,得到學習過程中神經網絡每一層的兩個互信息的值,將其畫在圖 12 中,得到信息平面。橫軸和縱軸分別表示互信息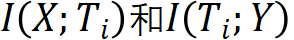 。圖中將學習過程中得到的各個神經網絡的每一層的互信息連成一條線。理想情況學習結束時得到的神經網絡,各層的縱軸表示的互信息不變,各層橫軸表示的互信息隨著層級的增加而減少。就是圖中最上面的一條線。模擬實驗發(fā)現(xiàn),神經網絡的學習分兩階段,前 300 左右的 epoch 在學如何預測(初步的預測),學習比較快,之后到 10000epoch 的學習在學習如何壓縮,學習比較慢,大部分時間學壓縮。
。圖中將學習過程中得到的各個神經網絡的每一層的互信息連成一條線。理想情況學習結束時得到的神經網絡,各層的縱軸表示的互信息不變,各層橫軸表示的互信息隨著層級的增加而減少。就是圖中最上面的一條線。模擬實驗發(fā)現(xiàn),神經網絡的學習分兩階段,前 300 左右的 epoch 在學如何預測(初步的預測),學習比較快,之后到 10000epoch 的學習在學習如何壓縮,學習比較慢,大部分時間學壓縮。
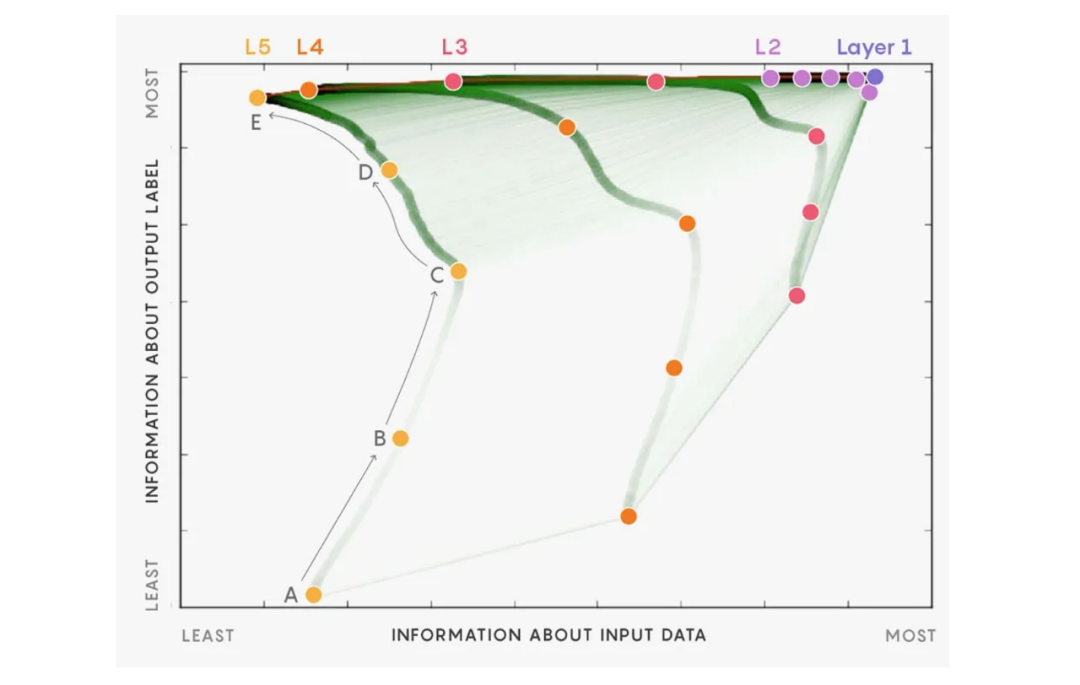
圖 12 信息平面分析神經網絡學習過程
數(shù)據(jù)流形假說
學習中的數(shù)據(jù)的內在結構也是需要考慮的。馬毅等的工作中,假設高維數(shù)據(jù)存在于低維空間的流形上,更具體地,多個流形的混合體[10]。認為聚類和分類學習是對數(shù)據(jù)通過深度神經網絡的非線性變換進行壓縮。將流形混合體上的數(shù)據(jù)從高維空間映射到低維線性空間,在低維線性空間進行聚類或分類。低維線性空間中,類內樣本相近,類外樣本相遠(見圖 13)。
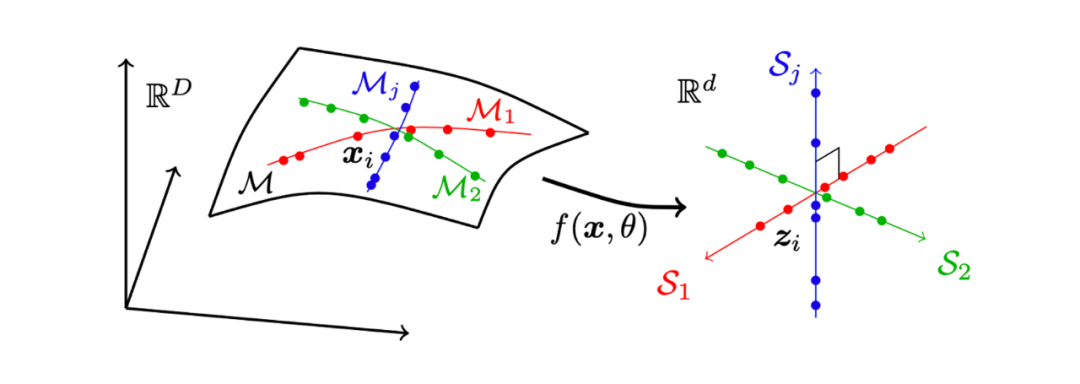
圖13數(shù)據(jù)處在高維空間的流形上,學習是對數(shù)據(jù)的壓縮
馬毅等提出了機器學習的壓縮比最大原理 MCR2(maximal coding rate reduction)[10]。
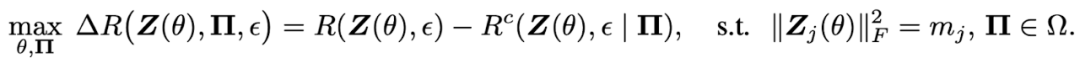
考慮分類問題,假設輸入數(shù)據(jù) X 中的同類樣本在同一個流形上。輸入數(shù)據(jù) X 通過神經網絡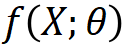 被影射為表示?Z。R 是樣本表示?Z?的(平均)編碼長度,
被影射為表示?Z。R 是樣本表示?Z?的(平均)編碼長度, 是樣本表示?Z?在一個劃分
是樣本表示?Z?在一個劃分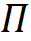 下分類后的(平均)編碼長度,
下分類后的(平均)編碼長度,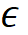 是編碼精度。壓縮比最大原理,認為壓縮比越大,即編碼長度減少越大,分類的結果就越好。學習就是要找到壓縮比最大的神經網絡。理論證明,在一定條件下,壓縮比最大的分類是將同類樣本放到同一個子空間里的分類,而且同類樣本在子空間均質(isotropic)分布,各個類的子空間正交。MCR2 是學習的指導原理,也可以用于解釋學習的現(xiàn)象。學習理論不僅需要考慮數(shù)據(jù)壓縮,而且需要考慮數(shù)據(jù)內在結構,MCR2 是一個很好的例子。
是編碼精度。壓縮比最大原理,認為壓縮比越大,即編碼長度減少越大,分類的結果就越好。學習就是要找到壓縮比最大的神經網絡。理論證明,在一定條件下,壓縮比最大的分類是將同類樣本放到同一個子空間里的分類,而且同類樣本在子空間均質(isotropic)分布,各個類的子空間正交。MCR2 是學習的指導原理,也可以用于解釋學習的現(xiàn)象。學習理論不僅需要考慮數(shù)據(jù)壓縮,而且需要考慮數(shù)據(jù)內在結構,MCR2 是一個很好的例子。
Transformer 的模型
最近對 Transformer 模型的表示能力分析有一些重要的結論。Transformer 模型有幾個重要構成要素,首先通過注意力包括自注意力機制實現(xiàn)輸入表示的組合。文本、圖像、語音數(shù)據(jù)都是具有組合性的,也就是說,整體的表示由局部的表示組合而成。注意力的計算實際是一種查詢,是 key-value store 符號查詢在向量查詢上的擴展。向量是 one-hot vector 時注意力就等價于 key-value store 查詢。這樣做的一個優(yōu)點是,用固定的參數(shù)量處理可變的輸入。人的類推推理也可以認為是一種相似度計算,注意力機制是類推推理的一個合理且有效的實現(xiàn)。注意力本質是線性變換(不考慮其中的 softmax 計算),在其基礎上的 FFN 又實現(xiàn)了非線性變換。
最近 Dong 等的理論研究發(fā)現(xiàn),Transformer 中的殘差連接實際起著非常重要的作用[11]。殘差連接實現(xiàn)了深度不同的各種注意力網絡加上非線性變換的集成(見圖 14)。理論證明,如果只有注意力,而沒有殘差連接或者前饋神經網絡,Transformer 學到的表示就會變成是秩為 1 的矩陣,也就是每個輸入 token 的表示趨于相同。以往的實驗也證明 position embedding 如果沒有殘差連接也不能傳到 Transformer 的高層。
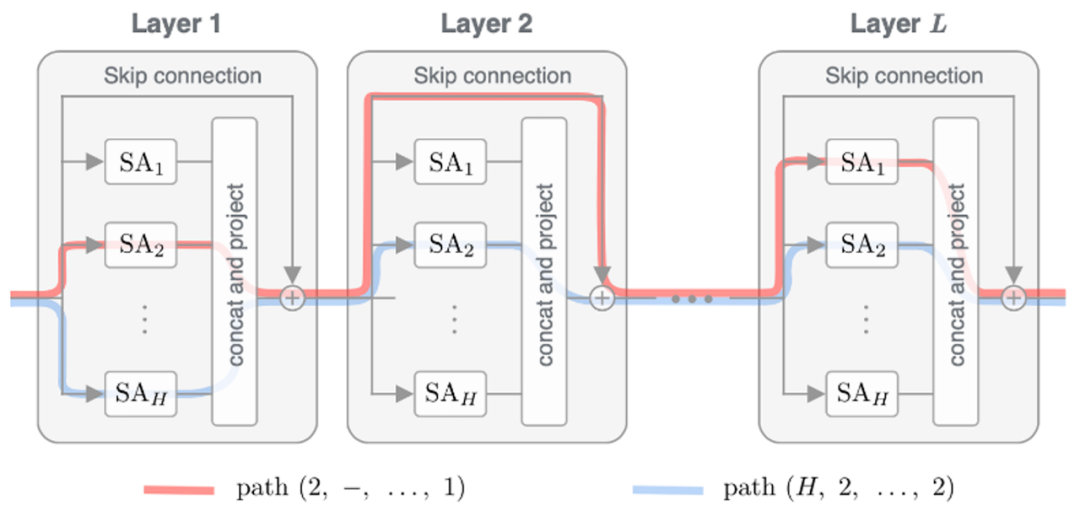
圖 14 Transformer 實際是自注意力網絡的集成,自注意力網絡中通過殘差連接形成了許多路徑
總結
本文的主要觀點如下。
深度學習的大模型、大數(shù)據(jù)和大算力模式繼續(xù)取得成果,沿著這個方向還有很大的發(fā)展空間。
字節(jié)跳動人工智能實驗室在進行創(chuàng)新工作,推動領域的發(fā)展,在深度學習和應用方面做出了業(yè)界領先的成果。
另一方面深度學習的局限也已凸顯,樣本效率和能源效率低下,邏輯推理能力缺乏。整體缺少理論指導。
下一代的人工智能更應該是從人腦計算得到啟發(fā)的,腦啟發(fā)計算是未來的發(fā)展方向。
腦啟發(fā)計算是指以現(xiàn)在的深度學習等機器學習為主體,在其基礎上(主要在功能層面)借鑒人腦的計算機制,構成的全新的智能計算范式。
腦啟發(fā)計算、深度學習需要強大的理論支撐,從信息流動、數(shù)據(jù)內在結構、模型表示能力等多方面的研究非常重要。
馮 · 諾伊曼對人腦和計算機研究的一個假設是智能可以還原為計算。人腦的計算機制是極其復雜的。所以,人工智能需要借鑒人腦,才能構建像人一樣智能的計算機系統(tǒng)。本文所說的腦啟發(fā)計算應該是邁向人工智能理想的一個新的范式。在這個過程中,也需要有對應的智能計算理論作為基礎。
審核編輯 :李倩
-
算法
+關注
關注
23文章
4626瀏覽量
93149 -
人工智能
+關注
關注
1793文章
47559瀏覽量
239404 -
計算機視覺
+關注
關注
8文章
1699瀏覽量
46057
原文標題:人工智能需要新的范式和理論
文章出處:【微信號:AI智勝未來,微信公眾號:AI智勝未來】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦





 工商網監(jiān)
工商網監(jiān)
評論