") 全球首個(gè)面向遙感任務(wù)設(shè)計(jì)的億級(jí)視覺Transformer大模型
全球首個(gè)面向遙感任務(wù)設(shè)計(jì)的億級(jí)視覺Transformer大模型
大規(guī)模視覺基礎(chǔ)模型在基于自然圖像的視覺任務(wù)中取得了重大進(jìn)展。得益于良好的可擴(kuò)展性和表征能力,基于視覺Transformer (Vision Transformer, ViT) 的大規(guī)模視覺基礎(chǔ)模型吸引了研究社區(qū)的廣泛關(guān)注,并在多種視覺感知任務(wù)中廣泛應(yīng)用。然而,在遙感圖像感知領(lǐng)域,大規(guī)模視覺模型的潛力尚未得到充分的探索。為此,我們首次提出面向遙感任務(wù)設(shè)計(jì)的大規(guī)模視覺基礎(chǔ)模型[1],針對(duì)具有1億參數(shù)的一般結(jié)構(gòu)的ViT (Plain ViT),設(shè)計(jì)符合遙感圖像特點(diǎn)的新型注意力機(jī)制,并據(jù)此研究大模型在遙感圖像理解任務(wù)上的性能,包括圖像分類、目標(biāo)檢測(cè)、語義分割等。
簡(jiǎn)單來說,為了更好地應(yīng)對(duì)遙感圖像所具有的大尺寸特性以及圖像中的目標(biāo)物體的朝向任意性,我們提出了一種新的旋轉(zhuǎn)可變尺寸窗口的注意力(Rotated Varied-Size Window Attention, RVSA)來代替Transformer中的原始完全注意力(Vanilla Full Self-Attention),它可以從生成的不同窗口中提取豐富的上下文信息來學(xué)習(xí)更好的目標(biāo)表征,并顯著降低計(jì)算成本和內(nèi)存占用。
實(shí)驗(yàn)表明,在檢測(cè)任務(wù)上,我們提出的模型優(yōu)于目前為止所有最先進(jìn)的模型,其在DOTA-V1.0數(shù)據(jù)集上取得了81.24% mAP的最高精度。在下游分類和分割任務(wù)上,所提出的模型與現(xiàn)有先進(jìn)方法相比性能具有很好的競(jìng)爭(zhēng)力。進(jìn)一步的分析實(shí)驗(yàn)表明該模型在計(jì)算復(fù)雜度、遷移學(xué)習(xí)的樣本效率、可解釋性等方面具有明顯優(yōu)勢(shì)。
本工作由京東探索研究院、武漢大學(xué)以及悉尼大學(xué)聯(lián)合完成,已被IEEE TGRS接收。

01
研究背景
在遙感圖像感知領(lǐng)域中,卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network, CNN)是提取多尺度視覺特征最常用的模型。然而,卷積操作的感受野受限,這使得CNN很難關(guān)注長距離像素并提取全局上下文信息。為了解決這一問題,研究者提出使用自注意力(Self-Attention, SA)機(jī)制,通過計(jì)算圖像中任意像素(特征)之間的相似性來靈活地建模特征之間的長距依賴關(guān)系。這一技術(shù)在計(jì)算機(jī)視覺領(lǐng)域的諸多任務(wù)上取得了良好的表現(xiàn)。其中,視覺Transformer模型采用了多頭自注意力(Multi-Head Self-Attention, MHSA)的設(shè)計(jì),在多個(gè)投影子空間中同時(shí)計(jì)算自注意力,使得提取的上下文信息更加多樣化,從而進(jìn)一步提高了特征的表征能力。
最早提出的視覺Transformer模型ViT [2]的結(jié)構(gòu)采用了非層次化的一般結(jié)構(gòu)設(shè)計(jì),即在特征嵌入層之后重復(fù)堆疊Transformer編碼器模塊,其中每個(gè)模塊輸出的空間尺度、特征維度均相同。為了更好地使ViT適應(yīng)下游任務(wù),研究人員借用了CNN中的分層設(shè)計(jì)思想,并相應(yīng)地設(shè)計(jì)了層次化視覺Transformer[3, 4]。這些模型通常使用大規(guī)模數(shù)據(jù)集并以有監(jiān)督的方式進(jìn)行預(yù)訓(xùn)練,然后再在下游任務(wù)的訓(xùn)練集上進(jìn)行微調(diào)。最近,探索研究院通過比較不同的預(yù)訓(xùn)練方法和模型,將層次化視覺Transformer應(yīng)用于遙感圖像上并對(duì)其性能進(jìn)行了詳細(xì)的實(shí)證研究[5],驗(yàn)證了層次化視覺Transformer相比于CNN的優(yōu)勢(shì)以及使用大規(guī)模遙感場(chǎng)景標(biāo)注數(shù)據(jù)集進(jìn)行預(yù)訓(xùn)練的有效性。然而,是否一定要采用層次化結(jié)構(gòu)的模型才能在遙感圖像上獲得較好性能呢?在本項(xiàng)研究中,我們首次嘗試采用非層次化結(jié)構(gòu)的模型并驗(yàn)證了其在一系列遙感圖像感知任務(wù)上的優(yōu)勢(shì)和潛力。
具體來說,我們首先使用具有約一億參數(shù)的Plain ViT模型和研究院最近提出的更先進(jìn)的ViTAE 模型[6],并采用掩碼圖像建模算法MAE [7]在大規(guī)模遙感數(shù)據(jù)集MillionAID [8]上對(duì)其進(jìn)行預(yù)訓(xùn)練,從而得到很好的初始化參數(shù)。
在預(yù)訓(xùn)練完成后,我們通過在下游任務(wù)相關(guān)數(shù)據(jù)集上進(jìn)行微調(diào),從而完成相應(yīng)任務(wù)。由于下游任務(wù)的圖像分辨率較大,為了降低視覺Transformer在下游任務(wù)上的計(jì)算成本和內(nèi)存占用,研究者通常采用窗口注意力(Window-based Attention)機(jī)制來代替原始的完全注意力機(jī)制。然而,窗口注意力采用的固定窗口大小和位置會(huì)限制模型提取上下文信息的范圍以及跨窗信息交互,從而影響模型的表征能力。
為此,探索研究院提出了一種名為可變大小窗口的注意力機(jī)制(Varied-Size Window Attention, VSA) [9]。它通過學(xué)習(xí)窗口的縮放和偏移因子,以使窗口的大小、形狀和位置適應(yīng)不同的圖像內(nèi)容,從而提高特征的表征能力,在多個(gè)視覺感知任務(wù)中獲得了更好的性能。不同于自然圖像中目標(biāo)主要呈現(xiàn)上下方向的特點(diǎn),遙感圖像中的目標(biāo)具有任意朝向,如圖1所示。為了處理這種差異,我們進(jìn)一步引入了一種可學(xué)習(xí)的旋轉(zhuǎn)框機(jī)制,從而獲得具有不同角度、大小、形狀和位置的窗口,實(shí)現(xiàn)了提取更豐富的上下文新型的目標(biāo)。

圖1:兩種常見類別(橋梁和飛機(jī))的自然圖像(a)與遙感圖像(b)的區(qū)別
基于ViT和ViTAE模型,我們將上述自注意力方法應(yīng)用于三種遙感感知任務(wù)(場(chǎng)景分類、語義分割和目標(biāo)檢測(cè)),并開展了詳細(xì)的實(shí)驗(yàn)評(píng)估,取得了很好的效果。我們希望這項(xiàng)研究能夠填補(bǔ)遙感大模型領(lǐng)域的空白,并為遙感社區(qū)發(fā)展更大規(guī)模的Plain ViT模型提供有益的參考。
02
方法介紹
2.1 MillionAID
MillionAID [8]是一個(gè)具有遙感場(chǎng)景圖像和標(biāo)簽的大型數(shù)據(jù)集。它包含1,000,848個(gè)RGB格式的非重疊遙感場(chǎng)景,非常適合用于深度神經(jīng)網(wǎng)絡(luò)模型預(yù)訓(xùn)練。該數(shù)據(jù)集包含51類,每類有大約2,000-45,000個(gè)圖像。該數(shù)據(jù)集中的圖片是從包含各種傳感器和不同分辨率數(shù)據(jù)的谷歌地球上收集得到的。圖像尺寸分布廣泛,覆蓋了110*110到31,672*31,672個(gè)像素的多種情況。應(yīng)該注意的是,盡管該數(shù)據(jù)集同時(shí)包含圖像和標(biāo)簽,但在本項(xiàng)研究中,我們只采用圖像數(shù)據(jù)進(jìn)行無監(jiān)督預(yù)訓(xùn)練。
2.2 MAE
MAE [7]是一種生成式自監(jiān)督預(yù)訓(xùn)練方法,采用了非對(duì)稱的網(wǎng)絡(luò)結(jié)構(gòu)提取非掩碼區(qū)域的圖像特征并預(yù)測(cè)掩碼區(qū)域的圖像內(nèi)容,具有很高的計(jì)算效率。它首先將圖像分割成不重疊的圖像塊,然后通過特征嵌入層將每個(gè)圖像塊映射為視覺Token。按照一定掩碼比率,一些Token被刪除并被作為要預(yù)測(cè)的掩碼區(qū)域。剩余的Token被饋送到Transformer編碼器網(wǎng)絡(luò)進(jìn)行特征提取。然后,解碼器部分利用編碼器提取到的可見區(qū)域Token的特征和可學(xué)習(xí)的掩碼區(qū)域的Token來恢復(fù)掩碼區(qū)域圖像內(nèi)容。在訓(xùn)練過程中,通過最小化像素空間或特征空間中掩碼區(qū)域的預(yù)測(cè)和圖像真值之間的差異來訓(xùn)練模型。我們遵循原始MAE文獻(xiàn)中的設(shè)置并在歸一化像素空間中計(jì)算訓(xùn)練損失。
2.3 MAE無監(jiān)督預(yù)訓(xùn)練
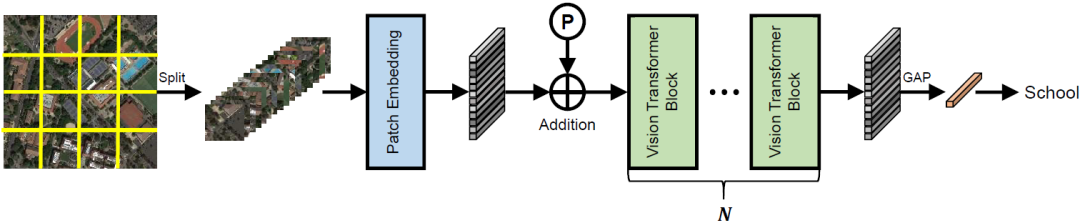
圖2:預(yù)訓(xùn)練階段的視覺Transformer的網(wǎng)絡(luò)結(jié)構(gòu)
圖2展示了所采用的Plain ViT模型的基本結(jié)構(gòu)。具體來說,我們采用兩種骨干網(wǎng)絡(luò)ViT和ViTAE進(jìn)行預(yù)訓(xùn)練。前者由具有完全自注意力的Plain ViT編碼器組成。這種簡(jiǎn)單的結(jié)構(gòu)能夠使其無縫地采用MAE方法進(jìn)行預(yù)訓(xùn)練。相比之下,ViTAE引入了卷積結(jié)構(gòu)從而讓網(wǎng)絡(luò)獲取局部性歸納偏置,即采用與MHSA并列的平行卷積分支PCM。在預(yù)訓(xùn)練時(shí),因?yàn)镸AE中的隨機(jī)掩蔽策略破壞了空間關(guān)系,我們將PCM的卷積和從3*3改為1*1,以避免其學(xué)習(xí)到錯(cuò)誤的空間特征。然后,在對(duì)特定的下游任務(wù)進(jìn)行微調(diào)時(shí),我們將卷積核重新填充為3*3大小。假設(shè)第i卷積層的預(yù)訓(xùn)練中的權(quán)重為(忽略通道維),填充內(nèi)核如下
其中是MAE預(yù)訓(xùn)練學(xué)習(xí)到的值,初始化為0。此外,我們?cè)赩iTAE模型中采用一種淺層PCM的設(shè)計(jì),其依次為卷積層、批歸一化層、SiLU層和卷積層,以節(jié)省內(nèi)存占用。圖3顯示了用于MAE預(yù)訓(xùn)練的ViT和ViTAE網(wǎng)絡(luò)中的基本模塊。
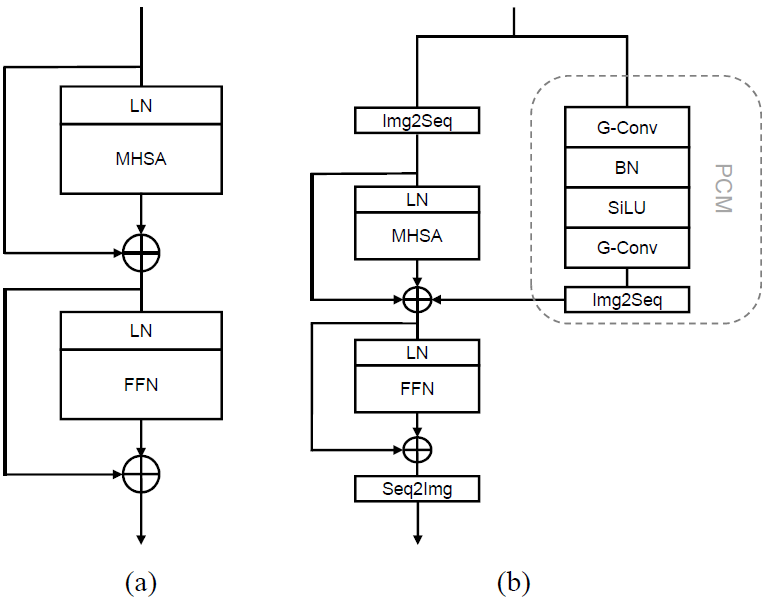
圖3:MAE編碼器中采用的塊結(jié)構(gòu)
(a) ViT的基本模塊,(b) 改進(jìn)后的ViTAE Normal Cell
我們使用“Base”版本的ViT和ViTAE,它們都具有約一億參數(shù)。這兩種網(wǎng)絡(luò)被分別表示為“ViT-B”和“ViTAE-B”。其詳細(xì)結(jié)構(gòu)見表1,其中“Patch Size”表示特征嵌入層的圖像塊尺寸,“Embedding Dim”表示Token的維度,“Head”表示MHSA中SA的個(gè)數(shù),“Group”表示PCM中分組卷積的組數(shù),“Ratio”指FFN的特征維膨脹率, “Depth”表示兩種網(wǎng)絡(luò)中堆積模塊的數(shù)量。
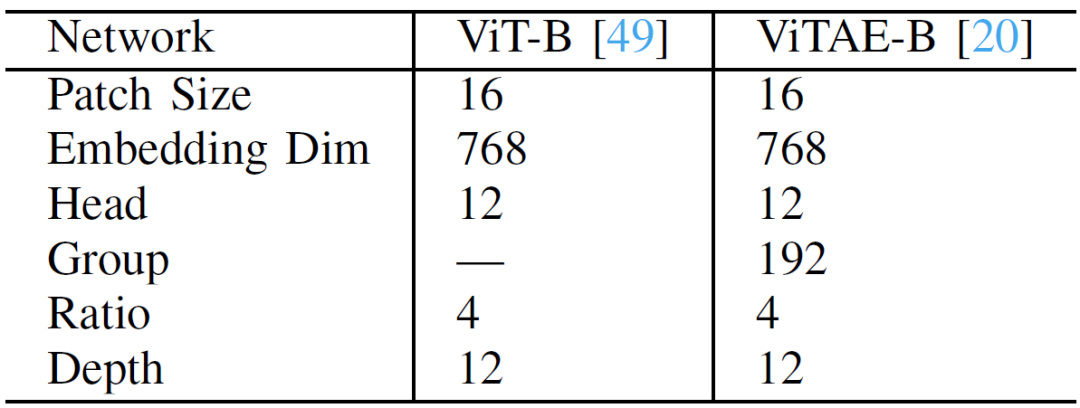
表1 :ViT-B和ViTAE-B的超參數(shù)設(shè)置
2.4 采用RVSA進(jìn)行微調(diào)
與自然圖像相比,遙感圖像通常尺寸更大。由于完全自注意力具有和圖片分辨率呈平方關(guān)系的計(jì)算復(fù)雜度,直接將采用完全自注意力的預(yù)訓(xùn)練模型應(yīng)用于下游任務(wù)時(shí)會(huì)顯著增加訓(xùn)練成本。為此,我們?cè)谖⒄{(diào)階段采用窗口自注意力替換原始的完全自注意力,這將計(jì)算代價(jià)降低到與圖像大小線性相關(guān)的復(fù)雜度。因?yàn)檫@種替換只改變了參與自注意力計(jì)算的Token范圍,而不引入新的參數(shù),因此可以在預(yù)訓(xùn)練-微調(diào)范式中直接轉(zhuǎn)換。然而,原始的窗口自注意力在固定水平和垂直方向上采用固定大小的窗口,這與遙感圖像中目標(biāo)的任意朝向特點(diǎn)不符,導(dǎo)致使用固定方向固定大小的窗口可能并非最優(yōu)。為此,我們?cè)O(shè)計(jì)了RVSA。
具體來說,我們引入了一系列變換參數(shù)來學(xué)習(xí)可變方向、大小和位置的窗口,包括相對(duì)參考窗口的偏移量、尺度縮放因子以及旋轉(zhuǎn)角度。具體地,給定輸入特征,首先將其劃分為幾個(gè)不重疊的參考窗口,即每個(gè)窗口的特征為(其中表示窗口大小),總共得到個(gè)窗口。然后,我們通過三個(gè)線性層去獲得查詢特征,初始的鍵特征和值特征。我們用去預(yù)測(cè)目標(biāo)窗口在水平和豎直方向上的偏移和縮放,以及旋轉(zhuǎn)角度
GAP是全局平均池化操作的縮寫。以窗口的角點(diǎn)為例
上式中,表示初始窗口左上角和右下角的坐標(biāo),表示窗口的中心坐標(biāo),分別是角點(diǎn)與中心在水平和垂直方向上的距離。我們用估計(jì)到的參數(shù)來對(duì)窗口進(jìn)行變換,
是變換后窗口的角點(diǎn)坐標(biāo)。然后,從變換后的窗口中采樣鍵特征,從而和查詢特征一起計(jì)算自注意力。采樣的鍵特征和值特征中Token的數(shù)量與查詢特征中Token的數(shù)量相同,從而保證RVSA與原始窗口自注意力機(jī)制具有相同的計(jì)算復(fù)雜度。
這里,是一個(gè)窗口中一個(gè)SA的輸出特征,,是SA的個(gè)數(shù)。然后,沿著通道維度連接來自不同SA的特征,并且沿著空間維度連接來自不同窗口的特征,以恢復(fù)輸入特征的形狀,最終獲得RVSA的輸出特征,圖4展示了RVSA的示意圖。
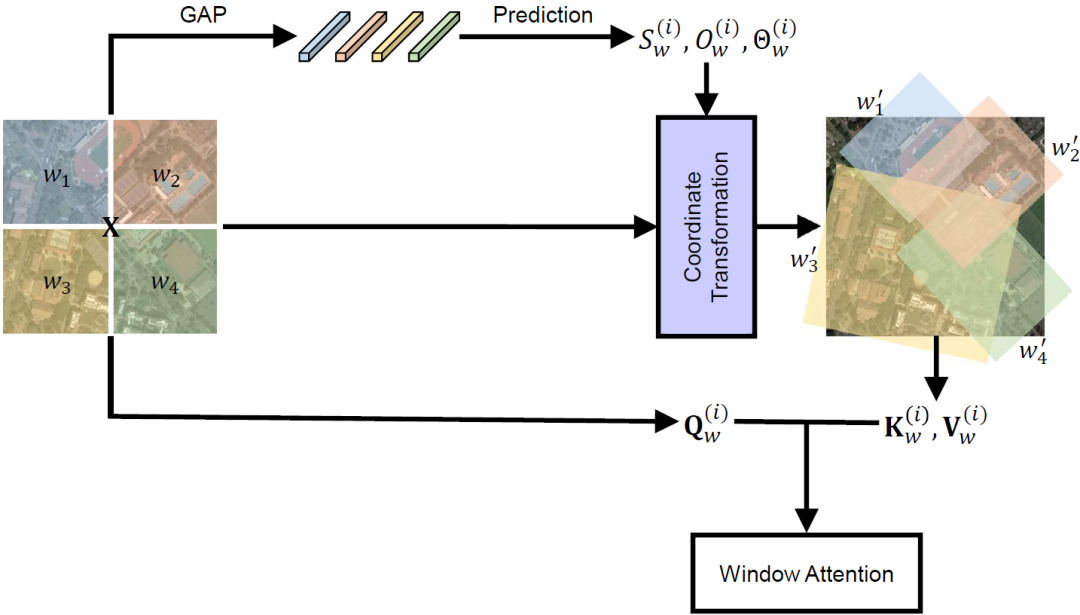
圖4:第個(gè)SA上所提出RVSA的完整流程
RVSA的變體:我們還提出了RVSA的一種變體,此時(shí)鍵特征和值特征可以來自不同窗口,即我們分別預(yù)測(cè)鍵特征和值特征窗口的偏移,縮放和旋轉(zhuǎn)因子
這個(gè)更靈活的架構(gòu)被稱為RVSA。
為了使MAE預(yù)訓(xùn)練模型適應(yīng)遙感下游任務(wù),我們將原始Plain ViT中的MHSA模塊替換為RVSA。按照ViTDet [10]中的策略,我們?cè)诿?/4個(gè)深度層采用完全自注意力。由于ViT-B 和 ViTAE-B有12 層,因此我們?cè)诘?、6、9和12層使用完全自注意力,并在所有其他層采用RVSA。修改后的網(wǎng)絡(luò)分別表示為“ViT-B + RVSA”和“ViTAE-B + RVSA”。圖5展示了 ViT-B + RVSA和ViTAE-B + RVSA中替換注意力后模塊的結(jié)構(gòu)。我們也對(duì)比了采用普通窗口自注意力、VSA和RVSA的變體。它們被分別表示為“ViT-B-Win”、“ViT-B + VSA”、 “ViT-B + RVSA”、“ViTAE-B-Win”、“ViTAE-B + VSA”和“ViTAE-B + RVSA”。
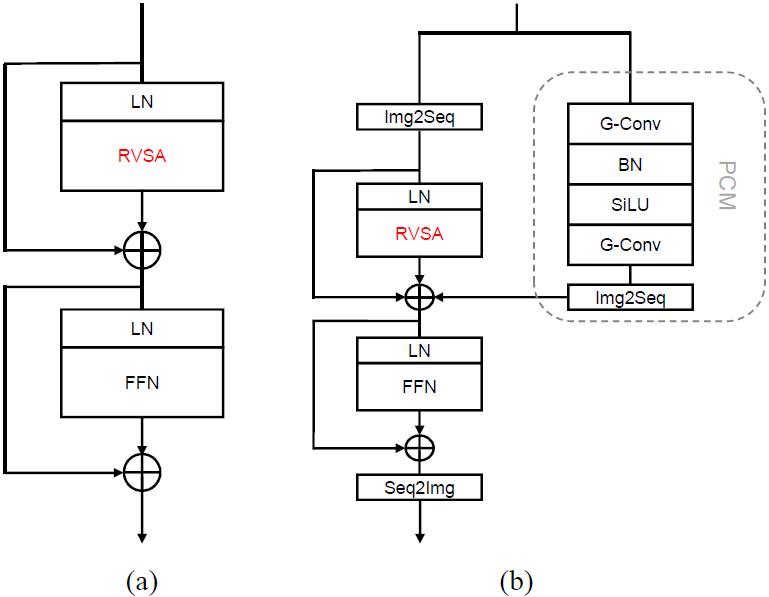
圖5:修改注意力后模塊的結(jié)構(gòu)(a)ViT-B+RVSA。(b)ViTAE-B+RVSA
最后,我們?cè)趫D6中展示了上述預(yù)訓(xùn)練和微調(diào)過程的完整框架,以便于讀者理解所提出的方法。
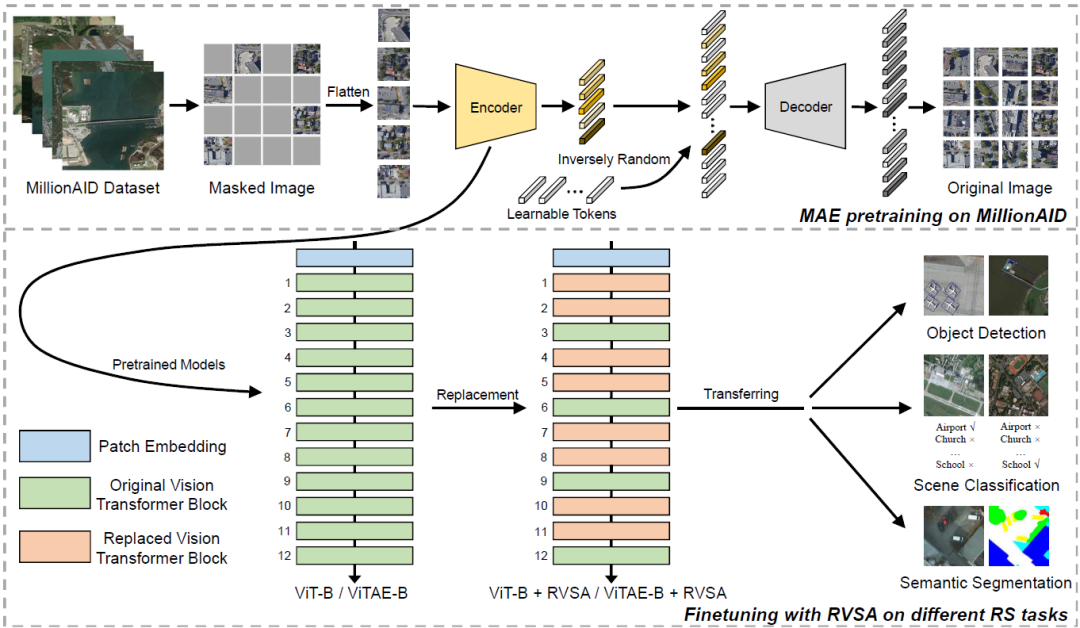
圖6:預(yù)訓(xùn)練和微調(diào)的流程(以RVSA為例)
03
實(shí)驗(yàn)結(jié)果
我們將所提出的模型在包括場(chǎng)景分類、對(duì)象檢測(cè)和語義分割等多個(gè)遙感任務(wù)上進(jìn)行實(shí)驗(yàn),并且還進(jìn)一步展示了其在計(jì)算復(fù)雜度、遷移學(xué)習(xí)的數(shù)據(jù)效率以及可解釋性等方面的優(yōu)勢(shì)。
3.1 目標(biāo)檢測(cè)
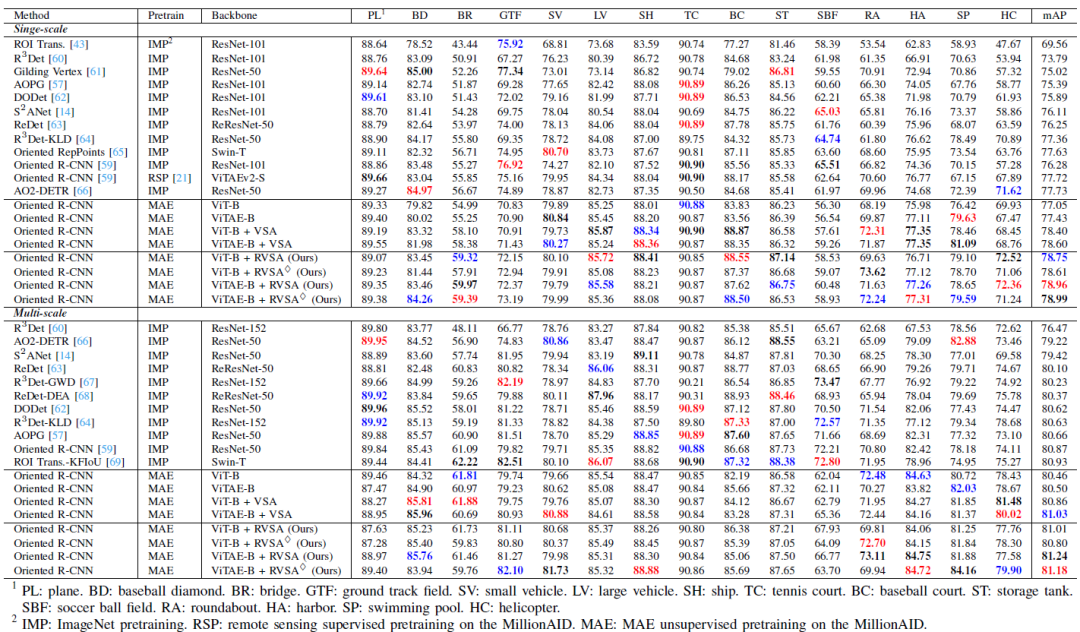
表2:不同先進(jìn)方法在DOTA-V1.0數(shù)據(jù)集上的精度。

表3:不同先進(jìn)方法在DIOR-R數(shù)據(jù)集上的精度
我們將所提出的方法與迄今為止最先進(jìn)的一些方法進(jìn)行了比較,結(jié)果列于表2和表3中。每列精度前三分別用粗體,紅色和藍(lán)色標(biāo)記。在DOTA-V1.0數(shù)據(jù)集上,我們分別列出了單尺度訓(xùn)練和多尺度訓(xùn)練的結(jié)果。在單尺度訓(xùn)練設(shè)置上,我們的模型在五個(gè)類中表現(xiàn)最好,超過了以前的最佳方法約1%的mAP。在競(jìng)爭(zhēng)更激烈的多尺度訓(xùn)練中,我們的模型在總共四個(gè)類別中獲得第一。特別的,我們的方法在一些具有挑戰(zhàn)性的類別(如環(huán)島和港口)中的檢測(cè)結(jié)果顯著優(yōu)于之前的方法,從而在DOTA-V1.0上取得了新的精度記錄,即81.24%的mAP。在更具挑戰(zhàn)性的DIOR-R數(shù)據(jù)集上,我們的模型在11個(gè)類別中表現(xiàn)最好。與現(xiàn)有方法相比,其檢測(cè)性能提高了10%以上,并以5% mAP的優(yōu)勢(shì)顯著超過第二名。值得注意的是,我們成功地證明了建立強(qiáng)大的Plain ViT基線的可能性:事實(shí)上,ViT-B+VSA和ViTAE-B+VSA在DOTA-V.1.0和DIOR-R數(shù)據(jù)集上已經(jīng)超過了之前的方法并取得了很好的檢測(cè)性能。當(dāng)進(jìn)一步引入旋轉(zhuǎn)機(jī)制后,它們的性能仍然能被進(jìn)一步提高。
3.2 場(chǎng)景分類
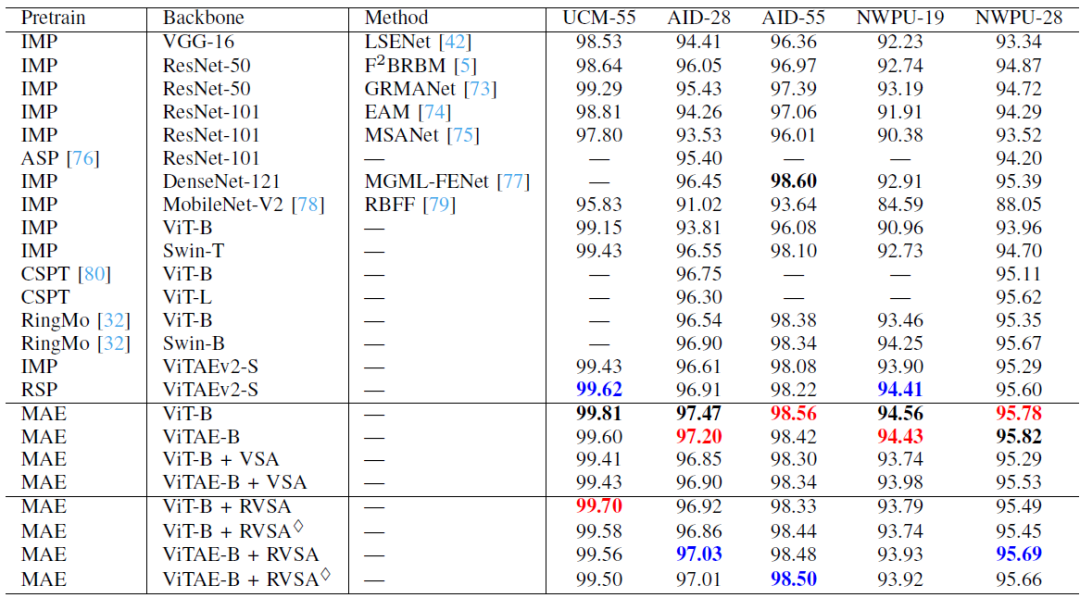
表4:不同方法在場(chǎng)景分類任務(wù)上的精度
表4展示了不同模型在場(chǎng)景分類任務(wù)上的結(jié)果。在此任務(wù)中,MAE 預(yù)訓(xùn)練的ViT-B在大多數(shù)設(shè)置上獲得最佳效果,因?yàn)樗蠺oken都參加了MHSA計(jì)算 ,這種方式提取的全局上下信息有利于場(chǎng)景識(shí)別。我們的 RVSA 模型在三個(gè)設(shè)置(包括 UCM-55、AID-28 和 NWPU-28)中優(yōu)于以前的方法。而在其他設(shè)置中,我們的模型可以與探索研究院先前提出的當(dāng)前最先進(jìn)的模型:即在 MillionAID上采用有監(jiān)督預(yù)訓(xùn)練的層次化模型RSP-ViTAEv2-S [5]相媲美。與VSA 方法相比,我們所提出的模型主要在NWPU-19設(shè)置中表現(xiàn)較差。這是因?yàn)橄啾萔SA,RVSA 需要相對(duì)更多的訓(xùn)練數(shù)據(jù)來學(xué)習(xí)最佳窗口配置,而NWPU-19 的訓(xùn)練數(shù)據(jù)規(guī)模相對(duì)較小。當(dāng)采用較大規(guī)模數(shù)據(jù)集,如NWPU-28 的設(shè)置時(shí),我們的模型超越了ViT-B + VSA,ViTAE-B + VSA和RSP-ViTAEv2-S等先進(jìn)模型。
3.3 語義分割
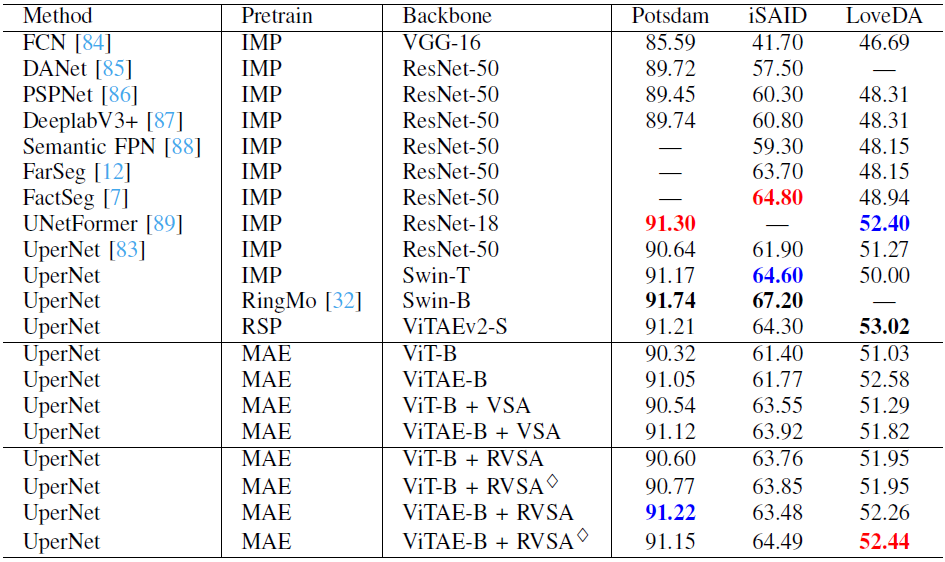
表5:不同方法在語義分割任務(wù)上的精度
表5顯示了不同分割方法的結(jié)果。我們的模型獲得了與當(dāng)前最佳方法相當(dāng)?shù)男阅堋1M管如此, 我們也必須承認(rèn)其在分割任務(wù)上的性能不如在檢測(cè)和場(chǎng)景分類任務(wù)上令人印象深刻。我們認(rèn)為這有兩個(gè)原因。首先,我們使用經(jīng)典但簡(jiǎn)單的分割框架 UperNet,它不能有效地將高級(jí)語義信息傳播到高分辨率特征圖上。另一個(gè)原因是我們采用的視覺Transformer 骨干網(wǎng)絡(luò)直接通過的圖像塊來嵌入編碼網(wǎng)絡(luò)特征,并且特征圖分辨率始終保持輸入大小的1/16,這可能會(huì)丟失細(xì)節(jié),不利于像素級(jí)語義分割任務(wù)。盡管如此,我們提出的RVSA仍然可以提升Plain ViT的性能并達(dá)到與層次化模型RSP-ViTAEv2-S相當(dāng)?shù)男阅埽覂?yōu)于ViT-B、ViTAE-B 和 VSA等模型,證明了其從可變窗口中學(xué)習(xí)有用上下文信息的強(qiáng)大能力。
3.4 計(jì)算復(fù)雜度
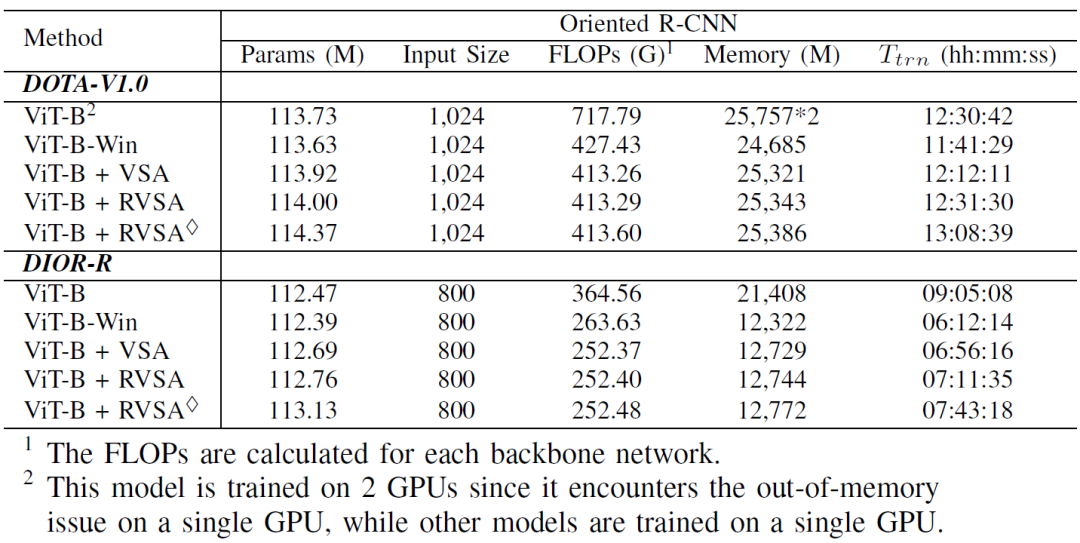
表6:不同模型的復(fù)雜度和訓(xùn)練代價(jià)
我們以ViT為例,在DIOR-R檢測(cè)數(shù)據(jù)集上比較了不同模型的復(fù)雜度和訓(xùn)練代價(jià)。表6列出了包括參數(shù)數(shù)量 (Params)、計(jì)算量 (FLOPs)、GPU 內(nèi)存在內(nèi)的多種評(píng)估指標(biāo),所有模型參數(shù)量均超過1億。由于完全自注意力的二次復(fù)雜度,ViT-B具有最大的內(nèi)存占用,最大的FLOPs以及最長的訓(xùn)練時(shí)間,因此需要使用兩個(gè)GPU才能在相當(dāng)?shù)臅r(shí)間完成訓(xùn)練。ViT-B-Win通過采用窗口自注意力緩解了這些問題。需要注意的是,ViT-B + VSA的FLOP比ViT-B-Win小,這是因?yàn)樘畛洌╬adding)操作是在生成查詢特征、鍵特征和值特征之后實(shí)現(xiàn)的。由于可學(xué)習(xí)的縮放和偏移因子,ViT-B + VSA比ViT-B-Win略多一些內(nèi)存占用。與ViT-B+VSA相比,ViT-B+RVSA具有相似的復(fù)雜度,而ViT-B+RVSA略微增加了參數(shù)和計(jì)算開銷,因?yàn)樗鼘?duì)鍵特征和值特征分別預(yù)測(cè)窗口。與ViT-B相比,所提出的ViT-B + RVSA和ViT-B + RVSA可以節(jié)省大約一半的內(nèi)存并加快訓(xùn)練速度,同時(shí)還具有更好的性能。
3.5 遷移學(xué)習(xí)的訓(xùn)練數(shù)據(jù)效率
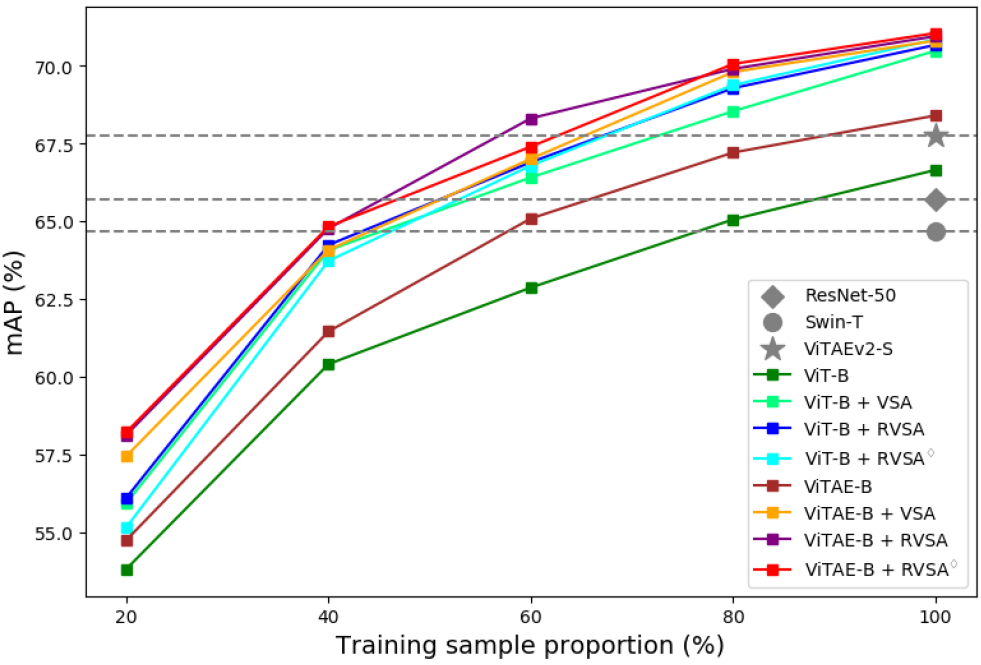
圖7:不同的模型在DIOR-R數(shù)據(jù)集上采用不同比例的訓(xùn)練集進(jìn)行訓(xùn)練的結(jié)果
遷移學(xué)習(xí)的訓(xùn)練數(shù)據(jù)效率是衡量基礎(chǔ)模型的一項(xiàng)重要能力。在這里,我們?cè)贒IOR-R 數(shù)據(jù)集上,使用不同數(shù)量的訓(xùn)練數(shù)據(jù)進(jìn)行實(shí)驗(yàn)。我們通過分別隨機(jī)選擇原始訓(xùn)練集的 20%、40%、60% 和 80% 的圖像來獲得一系列較小的訓(xùn)練集。然后,我們分別在這些數(shù)據(jù)集上微調(diào)預(yù)訓(xùn)練模型,并在原始測(cè)試集上對(duì)其進(jìn)行評(píng)估。為了便于比較,我們也訓(xùn)練了一些小規(guī)模模型,例如 RSP-ResNet-50、RSP-Swin-T和RSP-ViTAEv2-S,它們采用訓(xùn)練集中所有的數(shù)據(jù)進(jìn)行訓(xùn)練。圖7顯示了相關(guān)結(jié)果。可以看出,無論訓(xùn)練樣本的數(shù)量如何,所提出的模型都優(yōu)于相應(yīng)的ViT-B和ViTAE-B基線模型。由于我們考慮了遙感圖像中任意方向的對(duì)象,所提出的具有可學(xué)習(xí)旋轉(zhuǎn)機(jī)制的RVSA在大多數(shù)情況下都可以超越VSA。此外,它們僅使用40%的訓(xùn)練樣本就達(dá)到了與Swin-T相當(dāng)?shù)男阅埽?dāng)使用60%的訓(xùn)練樣本時(shí),它們的性能優(yōu)于ResNet-50和Swin-T。當(dāng)采用80%的訓(xùn)練樣本時(shí),它們超過了強(qiáng)大的骨干網(wǎng)絡(luò)ViTAEv2-S。上述結(jié)果表明我們的模型在遷移學(xué)習(xí)時(shí)具有良好的訓(xùn)練數(shù)據(jù)效率。
3.6 窗口可視化
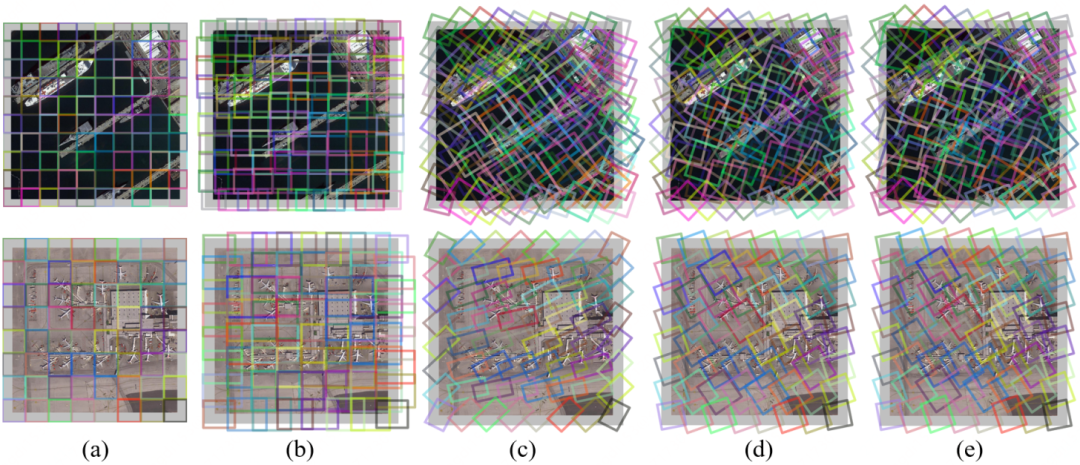
圖8:不同注意力方法生成窗口的可視化。(a) 窗口自注意力。(b) VSA。(c) RVSA。(d)和(e)分別是RVSA為鍵特征和值特征生成的窗口
以ViT為例,圖8 可視化了不同的網(wǎng)絡(luò)在倒數(shù)第二個(gè)模塊中的注意力層生成的窗口。可以看出,VSA生成的窗口可以縮放和移動(dòng)以匹配不同的對(duì)象。然而,VSA 無法有效處理遙感圖像中任意方向的目標(biāo),例如圖8第二行中傾斜的飛機(jī)。相比之下,我們的RVSA引入了旋轉(zhuǎn)因子來解決這個(gè)問題,獲得更多樣化的窗口并有利于提取更豐富的上下文信息。同樣值得注意的是,每個(gè)頭可以產(chǎn)生不同方向和位置的窗口,并來覆蓋特定角度和位置的飛機(jī)。因此,通過使用多頭注意力的方式,圖片中不同方向的飛機(jī)可以被不同頭的窗口覆蓋,這意味著RVSA可以更好地處理任意方向的物體。與RVSA相比, RVSA進(jìn)一步提高了生成窗口的靈活性。通過將 (d) 和 (e) 與 (c) 進(jìn)行比較,我們可以發(fā)現(xiàn)鍵特征和值特征的窗口形狀略有變化,這在擁有大量可用的訓(xùn)練數(shù)據(jù)和處理具有挑戰(zhàn)性的樣本時(shí)比較有用。通過將學(xué)習(xí)到的窗口進(jìn)行可視化,我們提供了一種分析所提出的模型的工作機(jī)制的手段,可以增強(qiáng)其學(xué)習(xí)過程和學(xué)習(xí)結(jié)果的可解釋性。
04
總結(jié)
本工作提出了全球首個(gè)面向遙感任務(wù)設(shè)計(jì)的億級(jí)視覺Transformer大模型。具體來說,我們首先基于具有代表性的無監(jiān)督掩碼圖像建模方法MAE對(duì)網(wǎng)絡(luò)進(jìn)行預(yù)訓(xùn)練來研究Plain ViT作為基礎(chǔ)模型的潛力。我們提出了一種新穎的旋轉(zhuǎn)可變大小窗口注意力方法來提高Plain ViT的性能。它可以生成具有不同角度、大小、形狀和位置的窗口,以適應(yīng)遙感圖像中任意方向、任意大小的目標(biāo),并能夠從生成的窗口中提取豐富的上下文信息,從而學(xué)習(xí)到更好的物體表征。我們?cè)诘湫偷倪b感任務(wù)上對(duì)所提出的模型進(jìn)行實(shí)驗(yàn),結(jié)果證明了Plain ViT作為遙感基礎(chǔ)模型方面的優(yōu)越性和有效性。我們希望這項(xiàng)研究可以為社區(qū)提供有價(jià)值的見解,并激發(fā)未來對(duì)開發(fā)遙感基礎(chǔ)模型的探索,尤其是基于Plain ViT的研究。
審核編輯 :李倩
-
視覺
+關(guān)注
關(guān)注
1文章
147瀏覽量
23993 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1209瀏覽量
24789 -
Transformer
+關(guān)注
關(guān)注
0文章
145瀏覽量
6030 -
大模型
+關(guān)注
關(guān)注
2文章
2533瀏覽量
3005
原文標(biāo)題:全球首個(gè)面向遙感任務(wù)設(shè)計(jì)的億級(jí)視覺Transformer大模型
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Transformer模型的具體應(yīng)用

全球首個(gè)芯片設(shè)計(jì)開源大模型SemiKong正式發(fā)布
Transformer語言模型簡(jiǎn)介與實(shí)現(xiàn)過程
llm模型有哪些格式
使用PyTorch搭建Transformer模型
百度發(fā)布全球首個(gè)L4級(jí)自動(dòng)駕駛大模型

通義千問開源千億級(jí)參數(shù)模型
通義千問推出1100億參數(shù)開源模型
【大語言模型:原理與工程實(shí)踐】大語言模型的基礎(chǔ)技術(shù)
商湯科技聯(lián)合海通證券發(fā)布業(yè)內(nèi)首個(gè)面向金融行業(yè)的多模態(tài)全棧式大模型

視覺Transformer基本原理及目標(biāo)檢測(cè)應(yīng)用
螞蟻集團(tuán)推出20億參數(shù)多模態(tài)遙感基礎(chǔ)模型SkySense
螞蟻推出20億參數(shù)多模態(tài)遙感模型SkySense
基于Transformer模型的壓縮方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論