 基于視覺transformer的高效時空特征學習算法
基于視覺transformer的高效時空特征學習算法
二、背景
高效的時空建模(Spatiotemporal modeling)是視頻理解和動作識別的核心問題。相較于圖像的Transformer網絡,視頻由于增加了時間維度,如果將Transformer中的自注意力機制(Self-Attention)簡單擴展到時空維度,將會導致時空自注意力高昂的計算復雜度和空間復雜度。許多工作嘗試對時空自注意力進行分解,例如ViViT和Timesformer。這些方法雖然減小了計算復雜度,但會引入額外的參數量。本文提出了一種簡單高效的時空自注意力Transformer,在對比2D Transformer網絡不增加計算量和參數量情況下,實現了時空自注意力機制。并且在Sthv1&Sthv2, Kinetics400, Diving48取得了很好的性能。
三、方法
視覺Transofrmer通常將圖像分割為不重疊的塊(patch),patch之間通過自注意力機制(Self-Attention)進行特征聚合,patch內部通過全連接層(FFN)進行特征映射。每個Transformer block中,包含Self-Attention和FFN,通過堆疊Transformer block的方式達到學習圖像特征的目的。
在視頻動作識別領域,輸入的數據是連續采樣的多幀圖像(常用8幀、16幀、32幀等)學習視頻的時空特征,不僅要學習單幀圖像的空間視覺特征,更要建模幀之間的時域特征。本文提出一種基于視覺transformer的高效時空特征學習算法,具體來說,我們通過將patch按照一定的規則進行移動(patch shift),把當前幀中的一部分patch移動到其他幀,同時其他幀也會有一部分patch移動到當前幀。經過patch移動之后,對每一幀圖像的patch分別做Self-Attention,這一步學習的特征就同時包含了時空特征。具體思想可以由下圖所示:
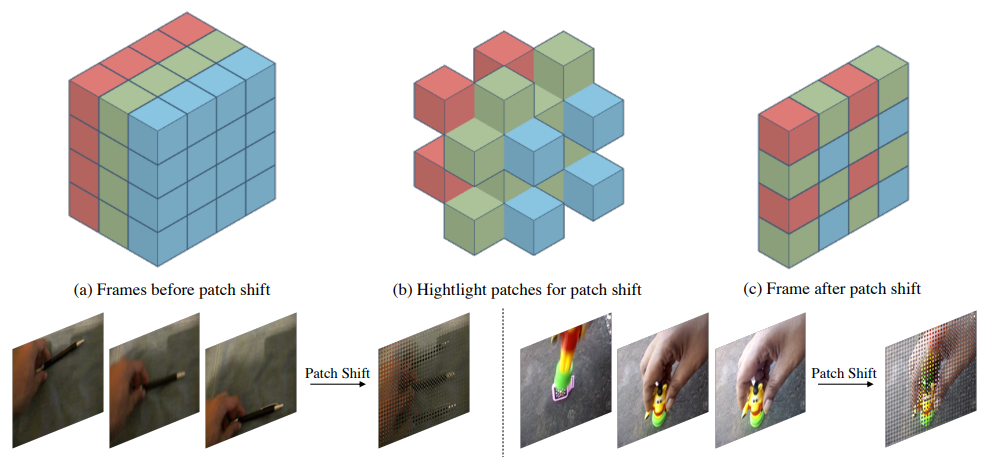
在常用的2D圖像視覺Transformer網絡結構上,將上述patch shift操作插入到self-attention操作之前即可,無需額外操作,下圖是patch shift transformer block,相比其他視頻transformer的結構,我們的操作不增加額外的計算量,僅需進行內存數據移動操作即可。對于patch shift的移動規則,我們提出幾種設計原則:1. 不同幀的塊盡可能均勻地分布。2.合適的時域感受野。3.保持一定的移動塊比例。具體的分析,讀者可以參考正文。
我們對通道移動(Channel shift) 與 塊移動(patch shift)進行了詳盡的分析和討論,這兩種方法的可視化如下:

通道移動(Channel shift) 與 塊移動(patch shift)都使用了shift操作,但channel shift是通過移動所有patch的部分channel的特征來實現時域特征的建模,而patch shift是通過移動部分patch的全部channel與Self-attention來實現時域特征的學習。可以認為channel shift的時空建模在空域是稠密的,但在channel上是稀疏的。而patch shift在空域稀疏,在channel上是稠密的。因此兩種方法具有一定的互補性。基于此,我們提出交替循環使用 patchshift和channel shift。網絡結構如下圖所示:

四、實驗結果
1. 消融實驗

2. 與SOTA方法進行對比



3. 運行速度
可以看到,PST的實際推理速度和2D的Swin網絡接近,但具有時空建模能力,性能顯著優于2D Swin。和Video-Swin網絡相比,則具有明顯的速度和顯存優勢。

4. 可視化結果
圖中從上到下依次為Kinetics400, Diving48, Sthv1的可視化效果。PST通過學習關聯區域的相關性,并且特征圖能夠反映出視頻當中動作的軌跡。
審核編輯:郭婷
-
內存
+關注
關注
8文章
3034瀏覽量
74136
原文標題:ECCV 2022 | 阿里提出:快速動作識別的時空自注意力模型
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
地平線ViG基于視覺Mamba的通用視覺主干網絡
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
opencv圖像識別有什么算法
Transformer能代替圖神經網絡嗎
深度學習在工業機器視覺檢測中的應用
機器學習算法原理詳解
機器學習的經典算法與應用

通過強化學習策略進行特征選擇
視覺Transformer基本原理及目標檢測應用
基于Transformer模型的壓縮方法

一文詳解Transformer神經網絡模型

分析 丨AI算法愈加復雜,但是機器視覺的開發門檻在降低

計算機視覺的十大算法
基于Transformer的多模態BEV融合方案





 工商網監
工商網監
評論