 英偉達:5nm實驗芯片用INT4達到INT8的精度
英偉達:5nm實驗芯片用INT4達到INT8的精度
IEEE計算機運算研討會。
32位與16位格式的混合精度訓練,正是當前深度學習的主流。
最新的英偉達核彈GPU H100,剛剛添加上對8位浮點數格式FP8的支持。
英偉達首席科學家Bill Dally現在又表示,他們還有一個“秘密武器”:
在IEEE計算機運算研討會上,他介紹了一種實驗性5nm芯片,可以混合使用8位與4位格式,并且在4位上得到近似8位的精度。
目前這種芯片還在開發中,主要用于深度學習推理所用的INT4和INT8格式,對于如何應用在訓練中也在研究了。
相關論文已發表在2022 IEEE Symposium on VLSI Technology上。

新的量化技術
降低數字格式而不造成重大精度損失,要歸功于按矢量縮放量化(per-vector scaled quantization,VSQ)的技術。
具體來說,一個INT4數字只能精確表示從-8到7的16個整數。
其他數字都會四舍五入到這16個值上,中間產生的精度損失被稱為量化噪聲。
傳統的量化方法給每個矩陣添加一個縮放因子來減少噪聲,VSQ則在這基礎之上給每個向量都添加縮放因子,進一步減少噪聲。
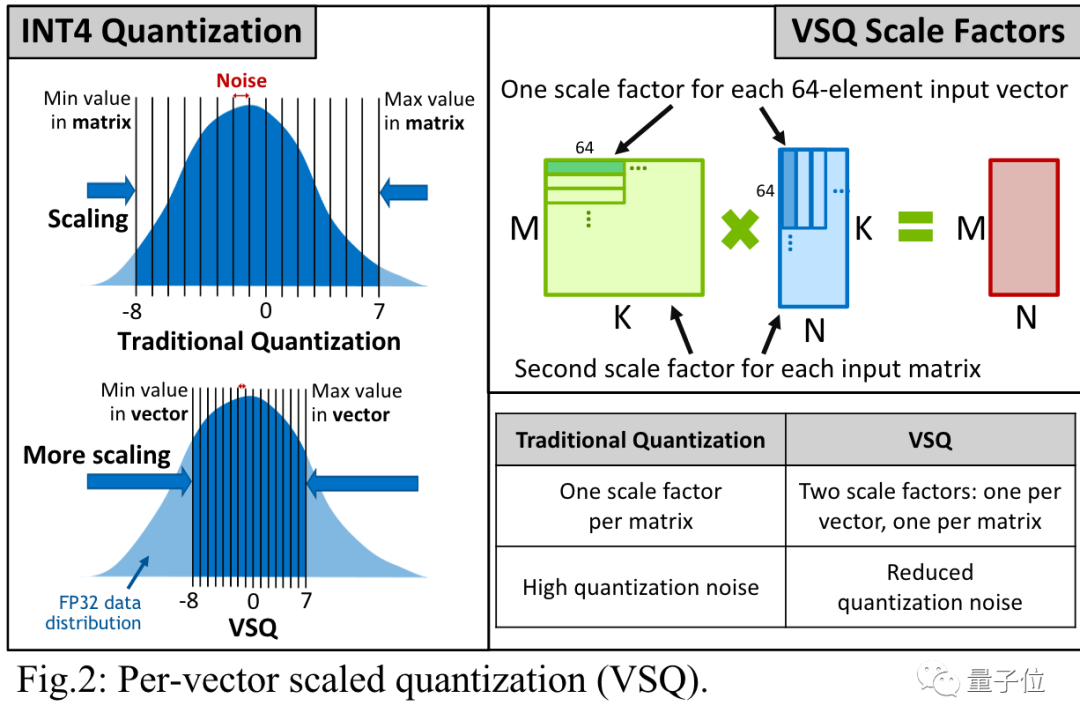
關鍵之處在于,縮放因子的值要匹配在神經網絡中實際需要表示的數字范圍。
英偉達研究人員發現,每64個數字為一組賦予獨立調整過的縮放因子可以最小化量化誤差。
計算縮放因子的開銷可以忽略不計,從INT8降為INT4則讓能量效率增加了一倍。
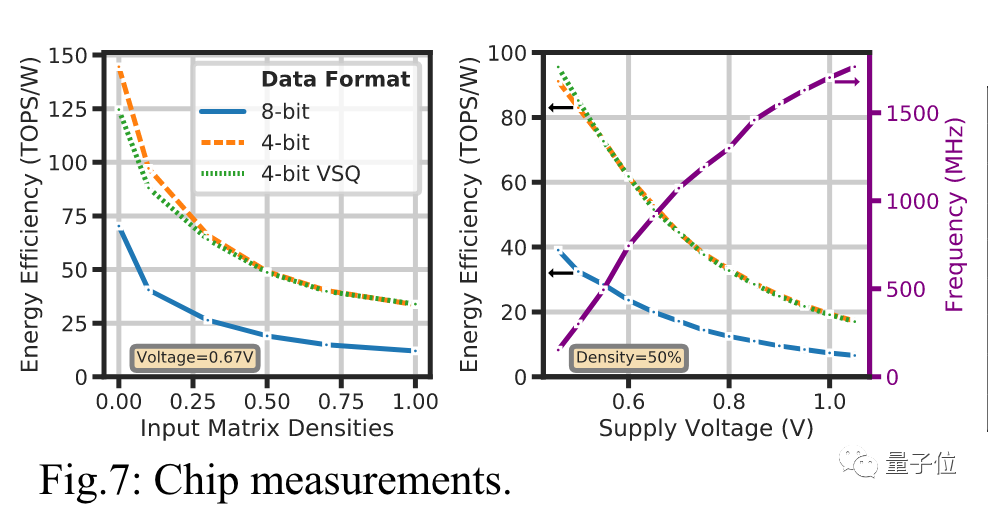
Bill Dally認為,結合上INT4計算、VSQ技術和其他優化方法后,新型芯片可以達到Hopper架構每瓦運算速度的10倍。
還有哪些降低計算量的努力
除了英偉達之外,業界還有更多降低計算量的工作也在這次IEEE研討會上亮相。
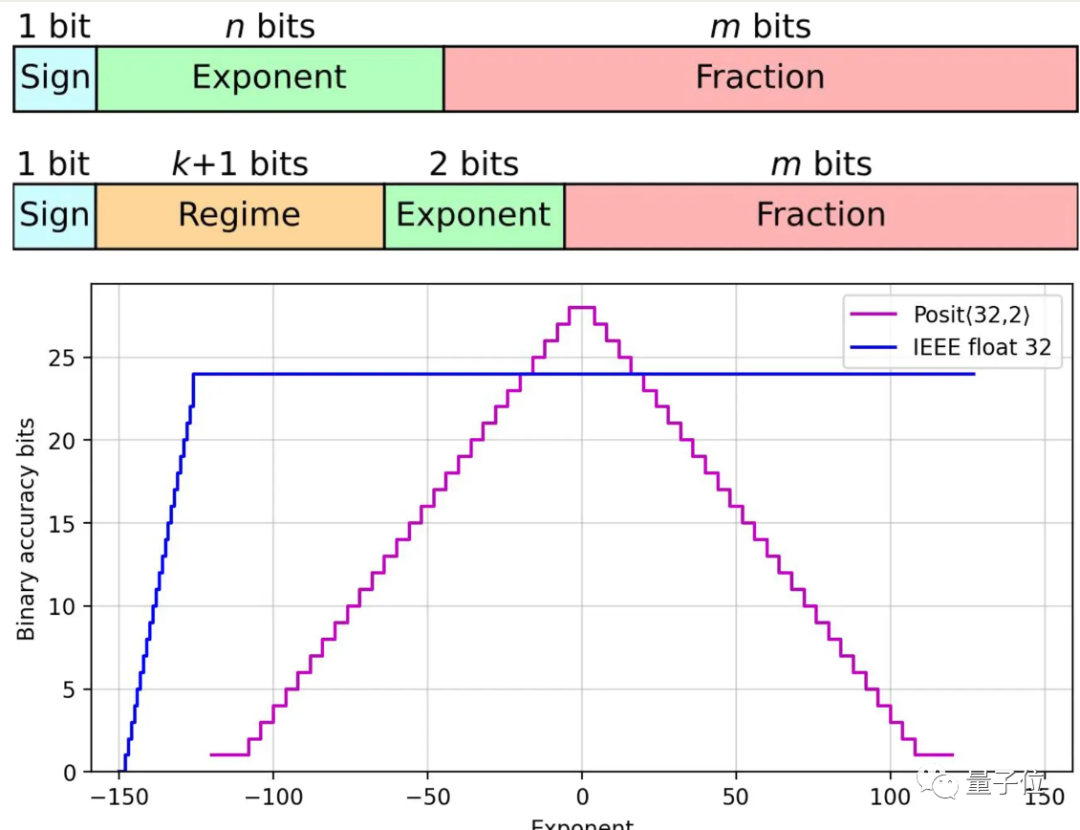
馬德里康普頓斯大學的一組研究人員設計出基于Posits格式的處理器核心,與Float浮點數相比準確性提高了多達4個數量級。
Posits與Float相比,增加了一個可變長度的Regime區域,用來表示指數的指數。
對于0附近的較小數字只需要占用兩個位,而這類數字正是在神經網絡中大量使用的。
適用Posits格式的新硬件基于FPGA開發,研究人員發現可以用芯片的面積和功耗來提高精度,而不用增加計算時間。
ETH Zurich一個團隊的研究基于RISC-V,他們把兩次混合精度的積和熔加計算(fused multiply-add,FMA)放在一起平行計算。
這樣可以防止兩次計算之間的精度損失,還可以提高內存利用率。
FMA指的是d = a * b + c這樣的操作,一般情況下輸入中的a和b會使用較低精度,而c和輸出的d使用較高精度。
研究人員模擬了新方法可以使計算時間減少幾乎一半,同時輸出精度有所提高,特別是對于大矢量的計算。
相應的硬件實現正在開發中。

巴塞羅那超算中心和英特爾團隊的研究也和FMA相關,致力于神經網絡訓練可以完全使用BF16格式完成。
BF16格式已在DALL·E 2等大型網絡訓練中得到應用,不過還需要與更高精度的FP32結合,并且在兩者之間來回轉換。
這是因為神經網絡訓練中只有一部分計算不會因BF16而降低精度。
最新解決辦法開發了一個擴展的格式BF16-N,將幾個BF16數字組合起來表示一個數,可以在不顯著犧牲精度的情況下更有效進行FMA計算
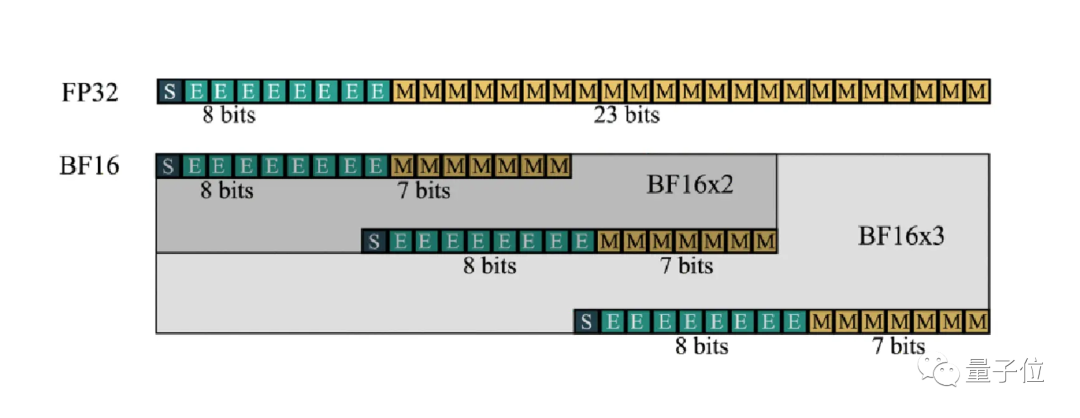
關鍵之處在于,FMA計算單元的面積只受尾數位影響。
比如FP32有23個尾數位,需要576個單位的面積,而BF16-2只需要192個,減少了2/3。
另外這項工作的論文題目也很有意思,BF16 is All You Need。

審核編輯 :李倩
-
芯片
+關注
關注
456文章
51154瀏覽量
426276 -
英偉達
+關注
關注
22文章
3842瀏覽量
91687
原文標題:英偉達首席科學家:5nm實驗芯片用INT4達到INT8的精度
文章出處:【微信號:ICViews,微信公眾號:半導體產業縱橫】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
解鎖NVIDIA TensorRT-LLM的卓越性能

臺積電產能爆棚:3nm與5nm工藝供不應求
英偉達超越蘋果成為市值最高 英偉達取代英特爾加入道指
英偉達加速Rubin平臺AI芯片推出,SK海力士提前交付HBM4存儲器
英偉達Blackwell芯片量產加速,Q4預計出貨達45萬片
AI芯片巨頭英偉達漲超4% 英偉達市值暴增7500億
esp-dl int8量化模型數據集評估精度下降的疑問求解?
觸覺智能EVB3588實測運行大模型,效果nice!

進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
基于RK3576開發的Banana Pi BPI-M5 Pro 開發板
Banana Pi 推出采用瑞芯微 RK3576芯片設計開源硬件:BPI-M5 Pro,比樹莓派5性能強大
iTOP-3588開發板快速測試手冊Android12系統功能測試






 工商網監
工商網監
評論