 DataParallel里為什么會顯存不均勻以及如何解決
DataParallel里為什么會顯存不均勻以及如何解決
鑒于網上此類教程有不少模糊不清,對原理不得其法,代碼也難跑通,故而花了幾天細究了一下相關原理和實現,歡迎批評指正!
關于此部分的代碼,可以去https://github.com/sherlcok314159/dl-tools查看
「在開始前,我需要特別致謝一下一位摯友,他送了我雙顯卡的機器來贊助我做個人研究,否則多卡的相關實驗就得付費在云平臺上跑了,感謝好朋友一路以來的支持,這份恩情值得一輩子銘記!這篇文章作為禮物贈與摯友。」
Why Parallel
我們在兩種情況下進行并行化訓練[1]:
「模型一張卡放不下」:我們需要將模型不同的結構放置到不同的GPU上運行,這種情況叫ModelParallel(MP)
「一張卡的batch size(bs)過小」:有些時候數據的最大長度調的比較高(e.g., 512),可用的bs就很小,較小的bs會導致收斂不穩定,因而將數據分發到多個GPU上進行并行訓練,這種情況叫DataParallel(DP)。當然,DP肯定還可以加速訓練,常見于大模型的訓練中
這里只講一下DP在pytorch中的原理和相關實現,即DataParallel和DistributedParallel
Data Parallel
實現原理
實現就是循環往復一個過程:數據分發,模型復制,各自前向傳播,匯聚輸出,計算損失,梯度回傳,梯度匯聚更新,可以參見下圖[2]:
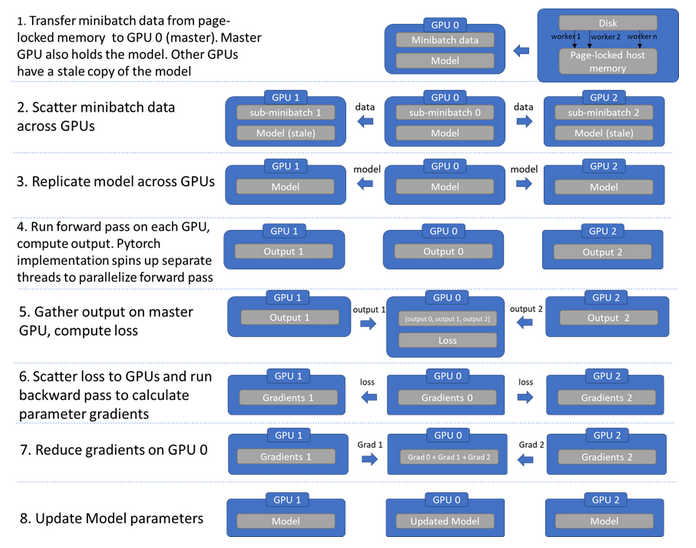
pytorch中部分關鍵源碼[3]截取如下:
defdata_parallel( module, input, device_ids, output_device=None ): ifnotdevice_ids: returnmodule(input) ifoutput_deviceisNone: output_device=device_ids[0] #復制模型 replicas=nn.parallel.replicate(module,device_ids) #拆分數據 inputs=nn.parallel.scatter(input,device_ids) replicas=replicas[:len(inputs)] #各自前向傳播 outputs=nn.parallel.parallel_apply(replicas,inputs) #匯聚輸出 returnnn.parallel.gather(outputs,output_device)
代碼使用
因為運行時會將數據平均拆分到GPU上,所以我們準備數據的時候, batch size = per_gpu_batch_size * n_gpus
同時,需要注意主GPU需要進行匯聚等操作,因而需要比單卡運行時多留出一些空間
importtorch.nnasnn #device_ids默認所有可使用的設備 #output_device默認cuda:0 net=nn.DataParallel(model,device_ids=[0,1,2], output_device=None,dim=0) #input_varcanbeonanydevice,includingCPU output=net(input_var)
接下來看個更詳細的例子[4],需要注意的是被DP包裹之后涉及到模型相關的,需要調用DP.module,比如加載模型
classModel(nn.Module): #Ourmodel def__init__(self,input_size,output_size): super(Model,self).__init__() #forconvenience self.fc=nn.Linear(input_size,output_size) defforward(self,input): output=self.fc(input) print(" InModel:inputsize",input.size(), "outputsize",output.size()) returnoutput bs,input_size,output_size=6,8,10 #defineinputs inputs=torch.randn((bs,input_size)).cuda() model=Model(input_size,output_size) iftorch.cuda.device_count()>1: print("Let'suse",torch.cuda.device_count(),"GPUs!") #dim=0[6,xxx]->[2,...],[2,...],[2,...]on3GPUs model=nn.DataParallel(model) #先DataParallel,再cuda model=model.cuda() outputs=model(inputs) print("Outside:inputsize",inputs.size(), "output_size",outputs.size()) #assume2GPUSareavailable #Let'suse2GPUs! #InModel:inputsizetorch.Size([3,8])outputsizetorch.Size([3,10]) #InModel:inputsizetorch.Size([3,8])outputsizetorch.Size([3,10]) #Outside:inputsizetorch.Size([6,8])output_sizetorch.Size([6,10]) #savethemodel torch.save(model.module.state_dict(),PATH) #loadagain model.module.load_state_dict(torch.load(PATH)) #doanythingyouwant
如果經常使用huggingface,這里有兩個誤區需要小心:
#dataparallelobjecthasnosave_pretrained model=xxx.from_pretrained(PATH) model=nn.DataParallel(model).cuda() model.save_pretrained(NEW_PATH)#error #因為model被DPwrap了,得先取出模型# model.module.save_pretrained(NEW_PATH)
#HF實現貌似是返回N個loss(N為GPU數量) #然后對N個loss取mean outputs=model(**inputs) loss,logits=outputs.loss,outputs.logits loss=loss.mean() loss.backward() #返回的logits是匯聚后的 #HF實現和我們手動算loss有細微差異 #手動算略好于HF loss2=loss_fct(logits,labels) assertloss!=loss2 True
顯存不均勻
了解前面的原理后,就會明白為什么會顯存不均勻。因為GPU0比其他GPU多了匯聚的工作,得留一些顯存,而其他GPU顯然是不需要的。那么,解決方案就是讓其他GPU的batch size開大點,GPU0維持原狀,即不按照默認實現的平分數據
首先我們繼承原來的DataParallel(此處參考[5])),這里我們給定第一個GPU的bs就可以,這個是實際的bs而不是乘上梯度后的。假如你想要總的bs為64,梯度累積為2,一共2張GPU,而一張最多只能18,那么保險一點GPU0設置為14,GPU1是18,也就是說你DataLoader每個batch大小是32,gpu0_bsz=14
classBalancedDataParallel(DataParallel): def__init__(self,gpu0_bsz,*args,**kwargs): self.gpu0_bsz=gpu0_bsz super().__init__(*args,**kwargs)
核心代碼就在于我們重新分配chunk_sizes,實現思路就是將總的減去第一個GPU的再除以剩下的設備,源碼的話有些死板,用的時候不妨參考我的[6]
defscatter(self,inputs,kwargs,device_ids):
#不同于源碼,獲取batchsize更加靈活
#支持只有kwargs的情況,如model(**inputs)
iflen(inputs)>0:
bsz=inputs[0].size(self.dim)
elifkwargs:
bsz=list(kwargs.values())[0].size(self.dim)
else:
raiseValueError("Youmustpassinputstothemodel!")
num_dev=len(self.device_ids)
gpu0_bsz=self.gpu0_bsz
#除第一塊之外每塊GPU的bsz
bsz_unit=(bsz-gpu0_bsz)//(num_dev-1)
ifgpu0_bszbsz_0=16,bsz_1=bsz_2=18
#總的=53=>bsz_0=16,bsz_1=19,bsz_2=18
foriinrange(delta):
chunk_sizes[i+1]+=1
ifgpu0_bsz==0:
chunk_sizes=chunk_sizes[1:]
else:
returnsuper().scatter(inputs,kwargs,device_ids)
returnscatter_kwargs(inputs,kwargs,device_ids,chunk_sizes,dim=self.dim)
優缺點
優點:便于操作,理解簡單
缺點:GPU分配不均勻;每次更新完都得銷毀「線程」(運行程序后會有一個進程,一個進程可以有很多個線程)重新復制模型,因而速度慢
審核編輯:湯梓紅
-
gpu
+關注
關注
28文章
4741瀏覽量
128963 -
顯卡
+關注
關注
16文章
2434瀏覽量
67639 -
pytorch
+關注
關注
2文章
808瀏覽量
13231
原文標題:DataParallel里為什么會顯存不均勻以及如何解決
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
不均勻性的定義 PPT學習資料
矩陣式LED的顯示亮度不均勻
在同步設計中使用占空比不均勻的時鐘是否可行
VHDL小源程序平均頻率輸出不均勻
基于不均勻密度的自動聚類算法
照度不均勻圖像的自動Gamma灰度校正
為什么數碼管亮度不均勻?
錫膏點膠時拉絲不均勻,如何解決?






 工商網監
工商網監
評論