 多波束相控陣接收機混合波束成形功率優勢的定量分析
多波束相控陣接收機混合波束成形功率優勢的定量分析
本文重點比較了模擬、數字和混合波束成形架構的功率效率。為接收相控陣開發了三種架構功耗的詳細基于方程的模型。該模型清楚地說明了各種組件對總功耗的貢獻,以及功率如何隨各種陣列參數而縮放。比較不同陣列架構的每波束帶寬乘積功耗,表明混合方法適用于具有大量晶片的毫米波相控陣的優勢。
介紹
在本文中,比較了不同的波束成形方法,特別關注創建多個同時波束的能力和功率效率。相控陣在現代雷達和通信系統中發揮著越來越重要的作用,這重新引起了人們對提高系統性能和效率的興趣。數字波束成形(DBF)及其與傳統模擬方法相比的優勢已經眾所周知數十年,但與數字信號處理相關的各種挑戰阻礙了其采用。隨著特征尺寸的不斷縮小和計算能力的指數級增長,我們現在看到了對采用數字相控陣的廣泛興趣。雖然DBF具有許多吸引人的特性,但功耗和成本的增加仍然是一個問題。由于具有卓越的功率效率,波束成形的混合方法可能適用于許多應用。
模擬與數字波束成形
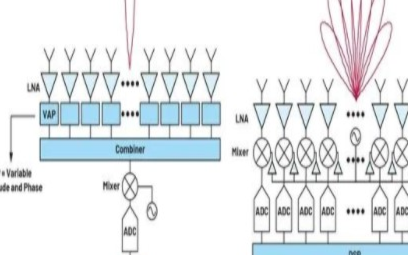
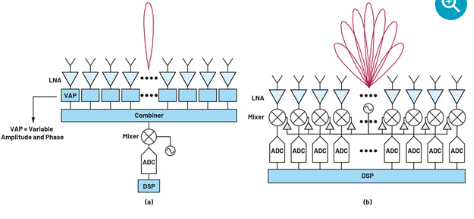
波束成形的核心是一種延遲和求和運算,可以在模擬域或數字域中進行。模擬波束成形也可以根據延遲或相移在信號鏈中的哪個位置進行分類。在本文中,僅考慮RF波束成形。如圖1a所示,來自天線元件的信號經過加權和組合以形成波束,然后由混頻器和信號鏈的其余部分進行處理。這就是傳統上相控陣的實施方式。
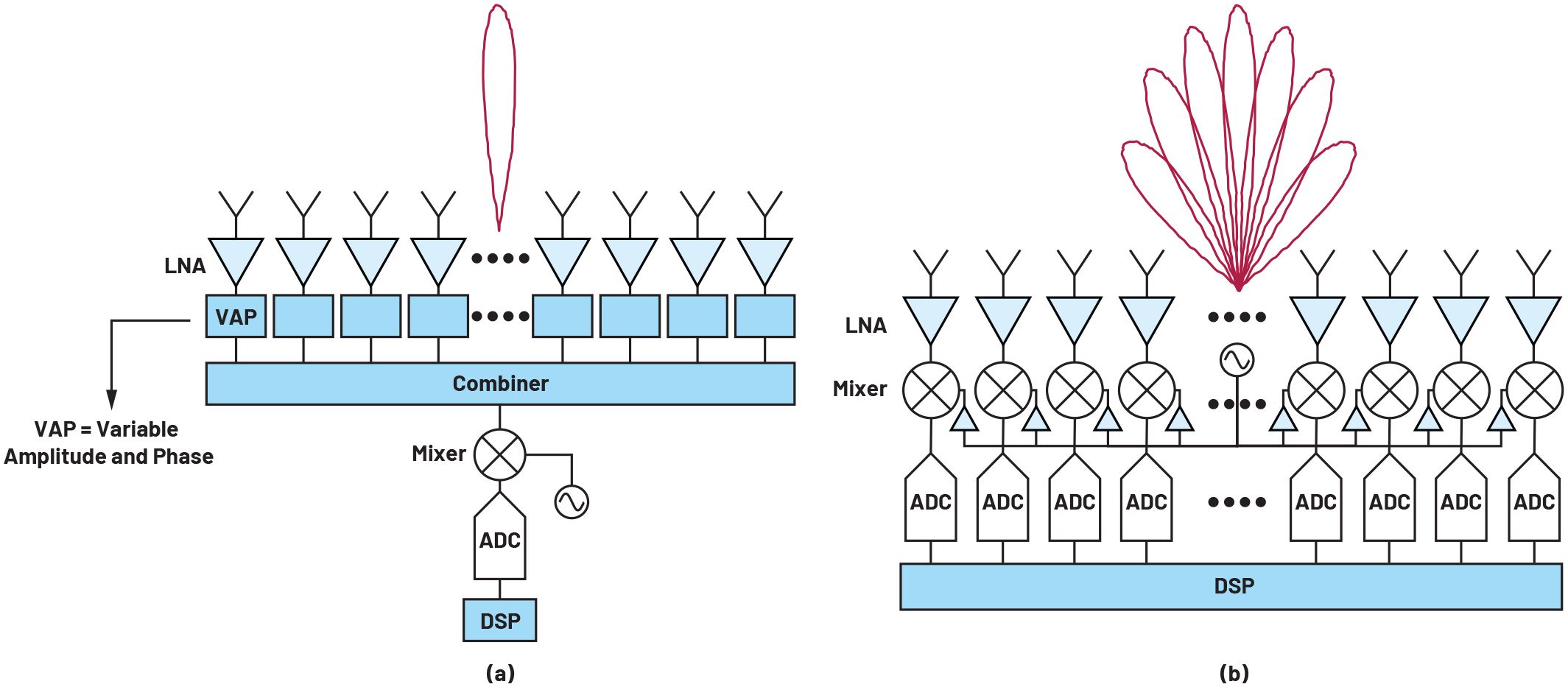
圖1.(a) 模擬和 (b) 數字波束成形架構的比較。
這種架構的缺點之一是難以創建大量同步波束。現在,為了創建多個波束,每個元件的信號需要在延遲和獨立求和之前被分割。執行此操作所需的可變振幅和相位(VAP)塊的數量與元件數量和光束數量成正比。VAP模塊以及網絡的分割和組合占用了大量面積,除了幾個波束之外,分割和組合網絡的面積要求和復雜性不斷提高,使得實現多個同步模擬波束變得不切實際。對于平面陣列,面積的增加也使得難以將電子元件安裝在由元件間距決定的網格內。此外,更根本的是,每次分頻時,信噪比(SNR)都會降低,并且本底噪聲限制了信號在被掩埋在本底噪聲之前可以分離的次數。
另一方面,使用DBF,創建多個同時光束相對容易。如圖1b所示,每個元件的信號被獨立數字化,然后在數字域中進行波束成形操作。一旦進入數字領域,就可以創建信號的副本,而不會損失任何保真度。然后,可以將信號的新副本延遲并相加以創建新的波束。理論上,這可以根據需要重復多次,從而產生無限數量的光束。實際上,數字信號處理的限制以及相關的功率和成本將限制波束數量或波束帶寬積。此外,DBF中的波束數量可以即時重新配置,這是模擬技術無法實現的。DBF還承諾更好的校準和自適應調零。所有這些優勢使DBF在通信和雷達系統中的各種相控陣應用中具有吸引力。但所有這些好處都是以增加成本和功耗為代價的。基帶上的DBF需要為每個元件提供一個ADC和一個混頻器,而對于模擬波束成形,每個波束需要一個ADC和一個混頻器。組件數量的增加顯著增加了功耗和成本,特別是對于大型陣列。此外,由于DBF中的波束成形發生在基帶上,混頻器和ADC受到每個元件寬視場中存在的任何信號的影響,因此需要具有足夠的動態范圍才能處理可能的干擾源。對于RF波束成形,混頻器和ADC享有空間濾波的優勢,因此可以放寬動態范圍要求。在保持相位相干性的同時分配高頻LO信號也是DBF實現的一個挑戰,并增加了功耗。
數字波束成形的計算要求是影響整體功耗的重要因素。DSP必須處理的數據量與元件數量、波束數量和信號的瞬時帶寬成正比。
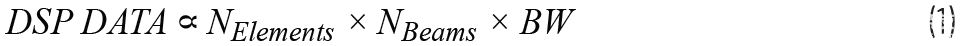
對于以毫米波頻率工作的大型陣列,信號帶寬通常很大,數據負載可能非常高。例如,對于具有500 MHz帶寬和8位ADC的1024元件陣列,DSP每個波束每秒需要處理約8 Tb的數據。移動和處理如此大量的數據需要大量的電力。就計算負載而言,這將轉化為大約 4×1012每個波束的每秒乘法運算數。對于全信號帶寬下的多波束,所需的計算能力超出了當今DSP硬件的能力范圍。在典型實現中,波束帶寬積保持恒定,因此對于不斷增加的波束數量,總帶寬在波束之間分配。數字信號處理通常以分布式方式完成,以便能夠處理大量數據。但這通常需要在波束成形靈活性、功耗、延遲等方面進行各種權衡。除了處理能力外,各種DSP模塊的高速輸入/輸出數據接口也會消耗大量功率。
混合波束成形
混合波束成形,顧名思義,結合了模擬和數字波束成形技術,在兩者之間提供了一個中間地帶。一種方法是將陣列劃分為較小的子陣列,并在子陣列內執行模擬波束成形。如果子陣列中的晶片數量相對較小,則產生的光束相對較寬,如圖2所示。每個子陣列都可以被認為是一個具有某種方向輻射圖的超元素。然后使用來自子陣列的信號執行數字波束成形,從而產生對應于陣列全孔徑的高增益窄波束。與全數字波束成形相比,使用這種方法,混頻器和ADC的數量以及數據處理負載的大小會減少子陣列的大小。這大大節省了成本和功耗。對于 32×32 晶片陣列,2×2 的子陣列大小會產生 256 個子陣列,半功率波束寬度 (HPBW) 為 50.8° 或 0.61 個球面度。使用來自 256 個子陣列的信號,使用 DBF 可以創建盡可能多的波束。對應于全孔徑的HPBW為3.2°或0.0024 sr。然后可以在每個子陣列的波束內創建大約254個數字波束,而不會彼此重疊。與全DBF相比,這種方法的一個局限性是所有數字波束都將包含在子陣列圖案的視場內。子陣列模擬波束當然也可以轉向,但在單個時間點,模擬波束寬度對最終波束的指向位置施加了限制。
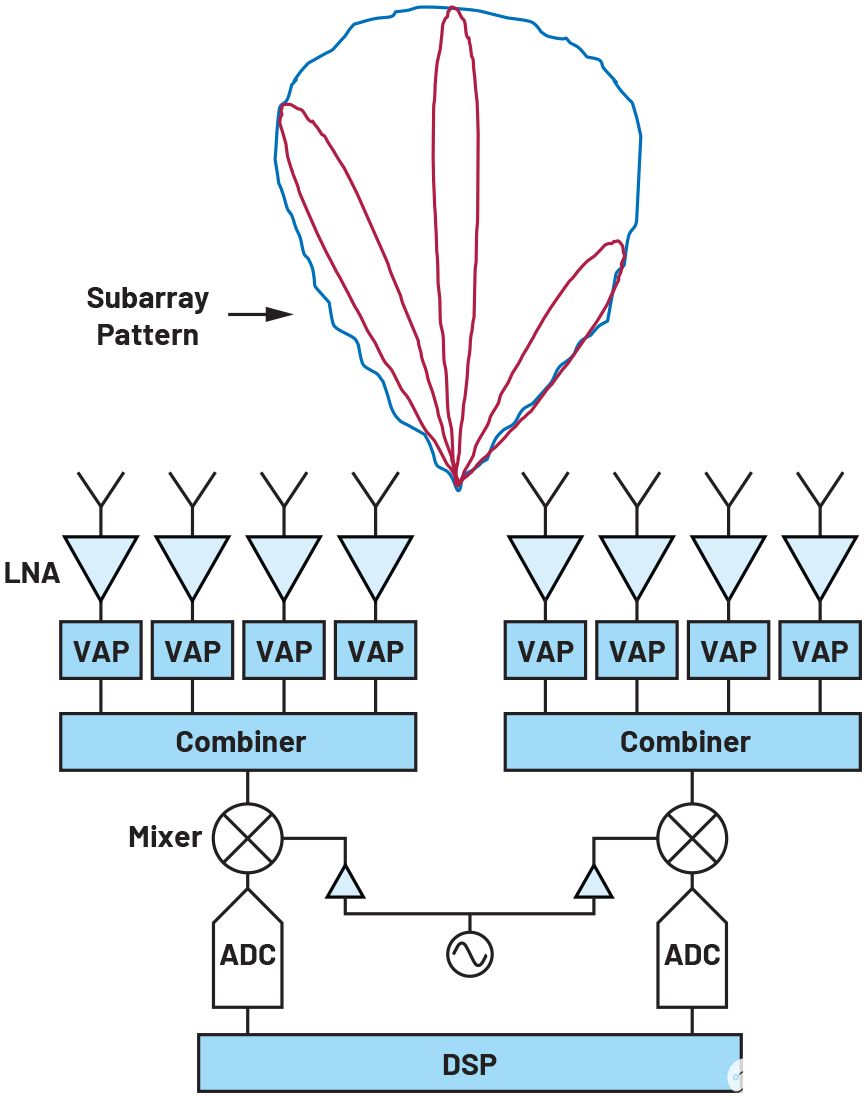
圖2.混合波束成形。
由于子陣列模式通常很寬泛,因此對于許多應用來說,這可能是一個可以接受的權衡。對于需要更大靈活性的其他設備,可以創建多個獨立的模擬波束來解決此問題。這將需要在RF前端增加VAP模塊,但與全DBF相比,仍然可以減少ADC和混頻器的數量。如圖3所示,可以創建兩個模擬波束以實現更大的覆蓋范圍,同時仍將混頻器、ADC和產生的數據流的數量減少兩倍。
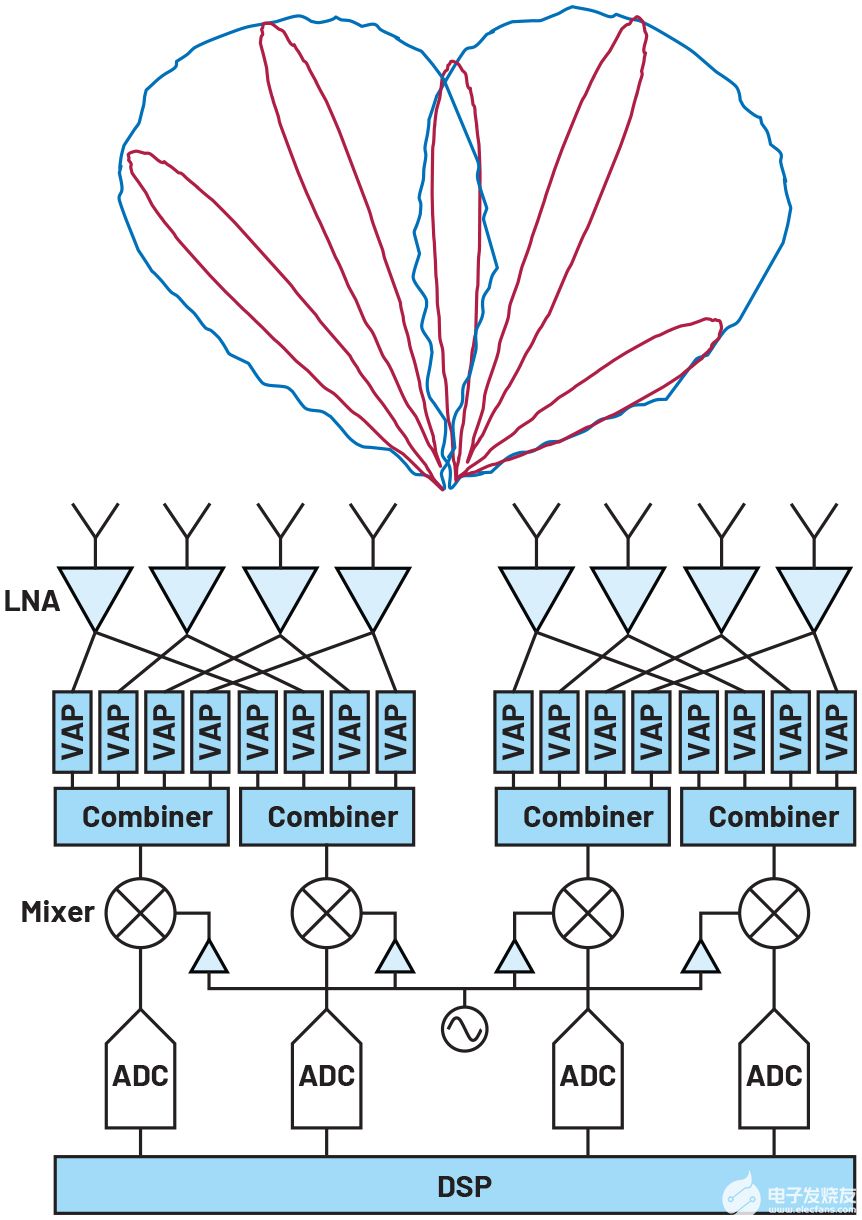
圖3.具有多個模擬波束的混合波束成形。
與DBF相比,混合波束成形也會導致旁瓣退化。當數字波束被掃描到遠離模擬波束中心的地方時,由于相位控制的混合性質,會引入相位誤差。子陣列內晶片之間的相位增量由模擬聲束控制確定,并且無論數字掃描角度如何,它都保持固定。對于給定的掃描角度,數字控制只能將適當的相位應用于子陣列的中心,并且當我們從中心向子陣列的邊緣移動時,相位誤差會增加。這會導致整個陣列出現周期性相位誤差,從而降低波束增益并產生準旁瓣和光柵瓣。這些效應隨著掃描角度的增加而增加,與純模擬或數字架構相比,這是混合波束成形的一個缺點。通過使誤差不周期性,可以改善旁瓣和光柵瓣的退化,這可以通過混合子陣列大小、方向和位置來實現。
電源效率
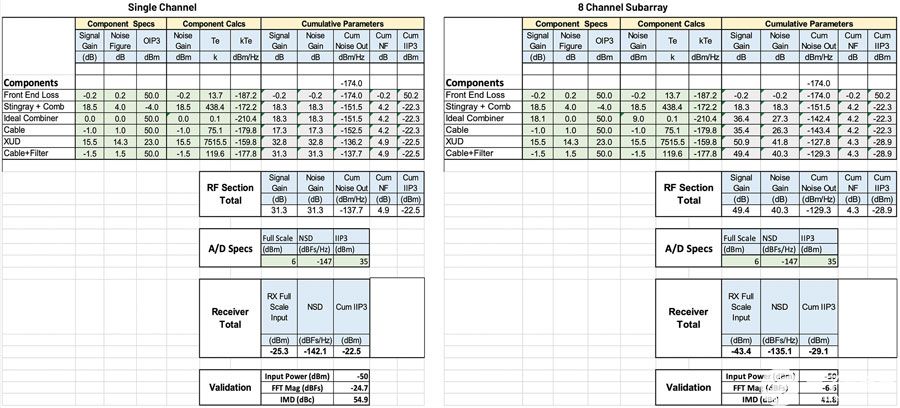
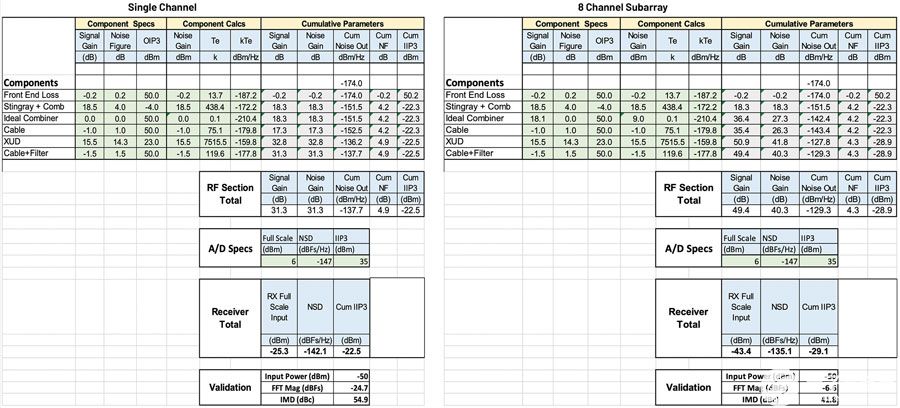
本節從接收相控陣的角度比較了模擬、數字和混合波束成形的功率效率。模擬、數字和混合波束成形的功耗模型分別在公式2、3和4中給出。表1給出了各種符號的含義及其后續分析的假定值。
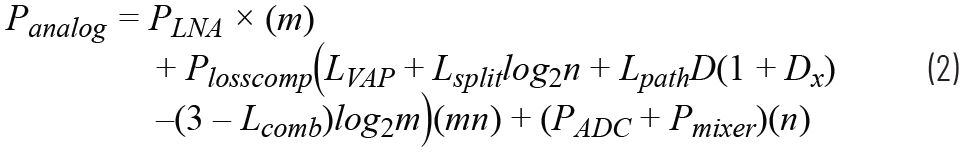
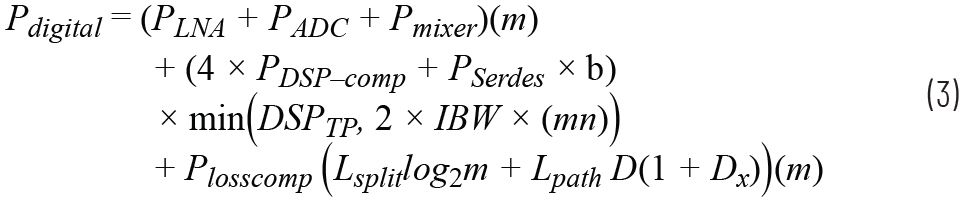
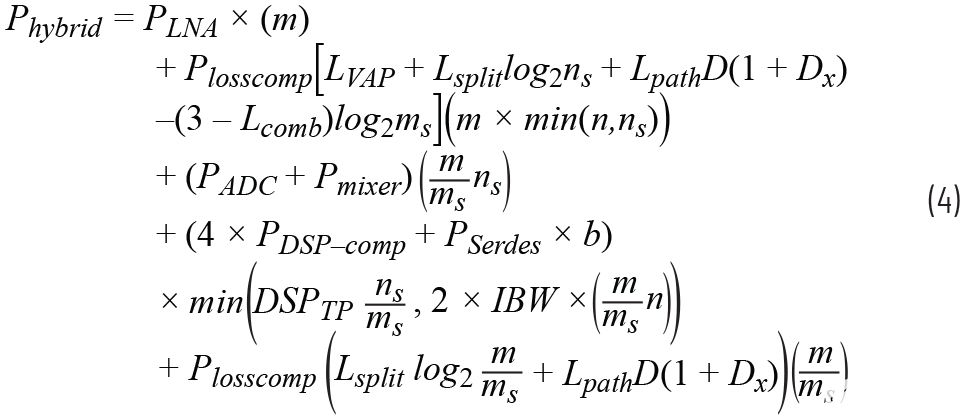
| 象征 | 意義 | 價值 | 裁判 |
|
P液化天然氣 |
液化鈉功耗 |
15 mW/實例 |
1 |
|
P損失補償 |
補償RF/LO路徑中各種損耗的功率 |
1.5毫瓦/分貝 | 1 |
|
P攪拌機 |
混頻器/LO放大器功耗 |
40 mW/實例 | 2 |
|
P模數轉換器 |
模數轉換器功耗;8 位,1 GSPS |
5 mW/實例 | 3, 4 |
|
b |
模數轉換器位數 | 8 | |
|
PDSP-comp |
用于波束成形計算的 DSP 功率 |
1.25 毫瓦/公威速 | 5 |
| P塞爾德斯 |
用于 I/O 的 DSP 電源 |
10 毫瓦/每秒 | 6 |
|
L電子煙 |
無源增益和相位控制引起的損耗 | 10分貝 | 7 |
|
L分裂 |
ABF 的功率分配器丟失 | 4分貝 | |
|
L梳 |
ABF 功率組合器中的損耗 |
1分貝 |
|
|
L路徑 |
單位長度的射頻/LO路由損耗 | 0.05分貝/毫米 | 8 |
| D | 數組的長度/寬度 | 155 毫米 | |
|
Ds |
子陣列的長度/寬度 |
15 毫米 | |
|
Dx |
用于路由和組合射頻信號的附加長度系數 | 0.25 | |
| m |
元素數量 |
1024 | |
|
ms |
子數組中的元素數 | 16 | |
|
n |
梁數 |
— |
|
|
ns |
混合波束成形中的模擬波束數量 |
4 | |
|
網新 |
信號的瞬時帶寬 | 500兆赫 | |
|
數字信號處理器衛生紙 |
DBF 的 DSP 的最大吞吐量 | 8 茶匙 |
關于功耗模型的一些關鍵點是:
假設所有三種波束成形架構的混頻器RF信號功率相同。
在一些已發表的文獻中,有人認為,對于DBF,由于ADC的量化噪聲對SNR的影響會降低陣列因子,因此與模擬波束成形相比,可以減少所需的位數。然而,在DBF中,ADC還需要具有更高的動態范圍,因為它們不享受空間濾波的優勢,并且需要處理每個元件輻射方向圖視場中存在的所有干擾源。考慮到這一點,假設ADC的位數對于該模型中的所有情況都是相同的。
對于DBF,波束帶寬積受DSP處理能力的限制,可變DSP會考慮這一點。衛生紙.對于混合情況,最大處理能力與功耗的降低成正比。
DBF 的 DSP 電源有兩個組件 — 計算和 I/O。每個復雜的乘法都需要四個實乘和累加(MAC)運算,并基于“評估信號處理應用的每瓦性能趨勢”。5MAC操作的功耗計算為每個GMAC約為1.25 mW。在這種情況下,I/O 消耗大部分 DSP 功率,基于“在 16nm FinFET 中使用 32 路時間交錯 SAR ADC 的 56-Gb/s PAM4 有線收發器”,估計為 10 mW/Gbps。6對于需要更密集計算的更復雜的波束成形方法,功率比的偏差較小,但總DSP功率會增加。此外,此模型中的 I/O 功耗假定數據傳輸最少。根據DBF架構,I/O中的功耗可能會更高。
ADC和DSP計算的功耗呈指數級增長,取決于位數。因此,可以通過減少位數來大幅降低這些功率數。另一方面,DSP I/O功耗是最大的貢獻者,其隨位數的擴展幅度較小。
路由損耗 (L路徑) 通過組合硅 IC 和低損耗 PCB 上的 GCPW 傳輸線損耗來計算。對于片上傳輸線,假設損耗為0.4 dB/mm,對于PCB走線8,損耗為0.025 dB/mm。據估計,5%的線路將在芯片上,其余的將在PCB上。對于模擬波束成形,考慮了RF合并所需的路由損耗,而對于數字波束成形,則考慮了LO分配網絡的損耗。
對于混合模型,假設每個光束對應于陣列的完整孔徑。
功耗對光束數量的依賴性如圖4所示。對于模擬情況,改變光束數量需要更改設計,而在DBF中,光束數量可以使用相同的設計即時更改。對于混合情況,具有固定數量的模擬光束(ns) 被考慮。還假設,當光束數小于ns,則未使用路徑中的放大器將斷電。
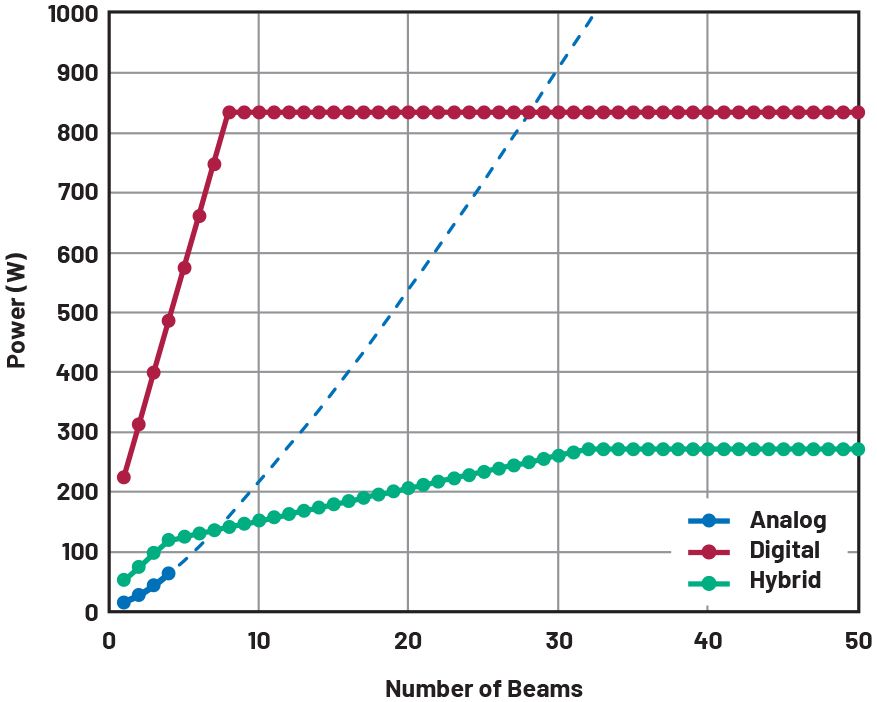
圖4.模擬、數字和混合(具有四個模擬波束)波束成形架構的功耗與波束數量。對于模擬情況,該線顯示為四個波束以上的虛線,以表示使用模擬技術實現更多波束的難度。對于數字和混合情況,一旦達到DSP的容量,功率和波束帶寬積就會變得恒定。
對于單波束,由于額外的混頻器、LO放大器和ADC的開銷,數字實現會消耗更多的功率。功率增加的速率取決于數字外殼的聚合數據速率的增加;對于模擬情況,它與補償分裂和額外VAP模塊損耗所需的功率有關。由于上述分離和組合網絡的復雜性,使用模擬波束成形實現大量波束是不切實際的,并且四個以上波束的虛線反映了這一事實。對于DBF,一旦達到最大DSP容量,功耗就不會再增加。超過該點,每個波束的帶寬會隨著波束數量的增加而降低。DBF在功耗方面確實與ABF收支平衡,并且對于大量光束消耗的功率更少。與DBF相比,混合方法顯著降低了功率開銷和斜率,并更快地實現了盈虧平衡點。
圖5比較了三種情況下波束形成的功率效率,其中繪制了每個波束帶寬乘積的功耗。在這種情況下,模擬波束成形始終保持更高效。混合方法從兩個極端之間的某個地方開始,可以與大量光束的模擬情況相媲美。
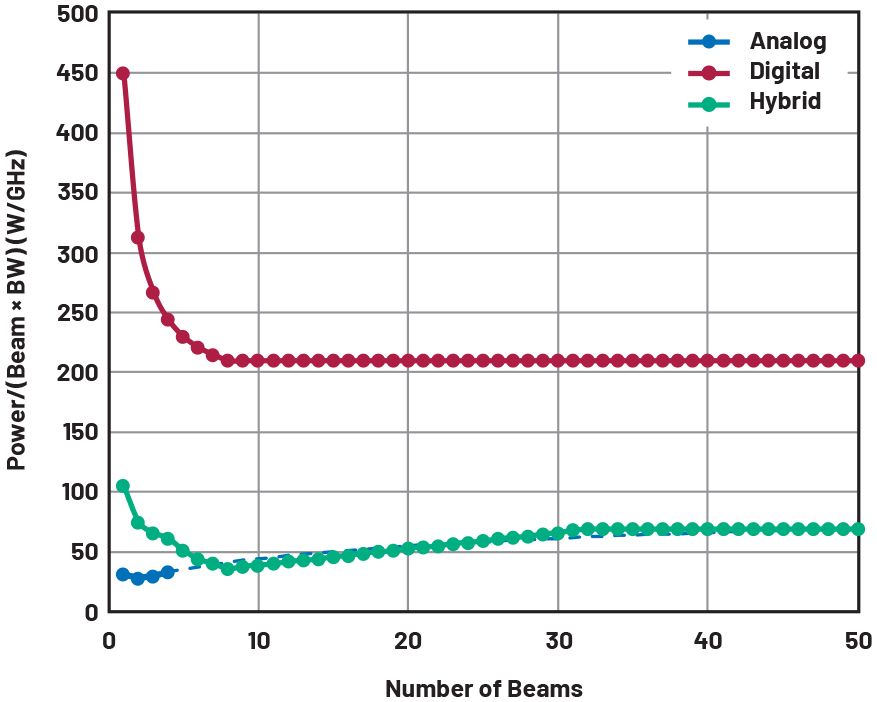
圖5.比較模擬、數字和混合波束成形架構的功率效率。
結論
本文介紹的比較和功耗模型僅適用于接收(Rx)相控陣。對于傳輸情況,一些基本假設將發生變化,完整DBF架構的功耗損失可能不那么嚴重。即使對于接收情況,三種架構之間的差異也在很大程度上取決于公式2至4中概述的參數。對于表 1 中給出的參數值以外的參數值,圖形之間的差異將發生變化。但可以肯定地說,混合方法將為許多應用節省大量功耗,同時保留數字波束成形的大部分優勢。如前所述,采用混合路線也有缺點,但對于許多應用來說,這些權衡可能值得節省功耗。
審核編輯:郭婷
-
接收機
+關注
關注
8文章
1181瀏覽量
53478 -
adc
+關注
關注
98文章
6498瀏覽量
544662 -
混頻器
+關注
關注
10文章
679瀏覽量
45691 -
SNR
+關注
關注
3文章
195瀏覽量
24416
發布評論請先 登錄
相關推薦
毫米波波束成形和天線設計
雷達模擬波束成形和數字波束成形的區別
【模擬對話】相控陣波束成形IC簡化天線設計
無線網絡中功率分配的安全波束成形
波束成形的類型及其在RF PCB中的用途
毫米波波束成形和天線技術的實例說明
解析相控陣三種波束成型架構
具有1.5dB NF LNA的Rx波束成形解決方案

混合波束成形接收機動態范圍理論實踐
混合波束成形接收機動態范圍理論實踐
多波束相控陣接收機混合波束成型功耗優勢的定量分析
如何實現毫米波波束成形和大規模MiMo?







 工商網監
工商網監
評論