 如何利用StarRocks特性開啟數據湖的極速分析體驗
如何利用StarRocks特性開啟數據湖的極速分析體驗
隨著開源數據湖技術的快速發展以及湖倉一體全新架構的提出,傳統數據湖在事務處理、流式計算以及數據科學場景的限制逐漸得以優化解決。 為了滿足用戶對數據湖探索分析的需求,StarRocks 在 2.5 版本開始發布了諸多數據湖相關的重磅特性,為用戶提供更加開箱即用的極速湖分析體驗。
本文為您揭秘如何利用 StarRocks 特性開啟數據湖的極速分析體驗,同時展示用戶真實場景中的落地案例以及性能測試結果,最后對 StarRocks DLA (Data Lake Analytics)未來的產品規劃做一些分享。
#01
站在Warehouse的當下,思考Lakehouse的未來
—
整個大數據架構逐步經歷了這么幾個典型的發展階段:
Schema-on-Write 架構:通過嚴格的建模范式約束,來支撐 BI 場景下的查詢負載,但在以存算一體為主流系統架構的歷史背景下,數據量膨脹帶給用戶高昂維護成本,同時對異構數據缺乏維護能力。
Scheme-on-Read 架構:以 HDFS 為統一存儲層,并提供基礎的文件 API 來與查詢層進行交互。這種架構模式雖然一定程度上保證了 TCO 和文件格式開放性,但由于應用讀時才能感知數據質量,也將數據治理問題帶來的成本轉嫁給了下游應用。
云上數據湖架構:云上對象存儲逐步代替 HDFS,并逐步演化成:以對象存儲作為統一離線存儲, 以 Warehouse 作查詢加速雙層架構。雖然這種雙層架構同時保障了冷數據的存儲成本和熱數據的查詢性能,但伴隨而來的是多輪跨系統 ETL,也就引入了 Pipeline 構建時的工程復雜度。
伴隨數據湖架構的現代化革新,用戶除了維護一個 Apache Iceberg(以下簡稱 Iceberg)/Apache Hudi(以下簡稱 Hudi)湖存儲,更亟需一款高性能的查詢組件來滿足業務團隊的分析需求,快速從數據中獲得“見解”驅動業務增長。傳統的查詢引擎,例如 Apache Spark(以下簡稱 Spark)/Presto/Apache Impala(以下簡稱 Impala)等組件能夠支撐的數據湖上查詢負載性能有限。部分高并發低延時的在線分析場景依舊需要用戶維護一套 MPP 架構的數倉組件,多套組件伴隨而來的自然是系統復雜度和高昂的運維代價。所以我們一直在暢想:有沒有可能使用 StarRocks 來幫助用戶搞定所有的分析場景?以“幫助用戶屏蔽復雜度,把簡單留給用戶”為愿景,那我們可以做些什么?
其實 StarRocks 早在 2.2 版本起,就引入了 Apache Hive(以下簡稱 Hive)/Iceberg/Hudi 外部表等特性,并在離線報表、即席查詢等場景積累了成熟的用戶案例。從一條 SQL 的生命周期來說,StarRocks 除了在查詢規劃階段 FE 節點對 Hive metastore 發起元數據請求,以及執行查詢計劃時 BE 掃描對象存儲以外,其他階段可以實現高度的復用。這意味,一方面,得益于 CBO 和向量化執行引擎帶來的特性,StarRocks 數據湖分析在內存計算階段有明顯的優勢;另一方面,我們也意識到,元數據服務請求和 DFS/對象存儲之上 Scan 等環節,在整個 SQL 生命周期里可能會成為影響用戶查詢體驗的關鍵。
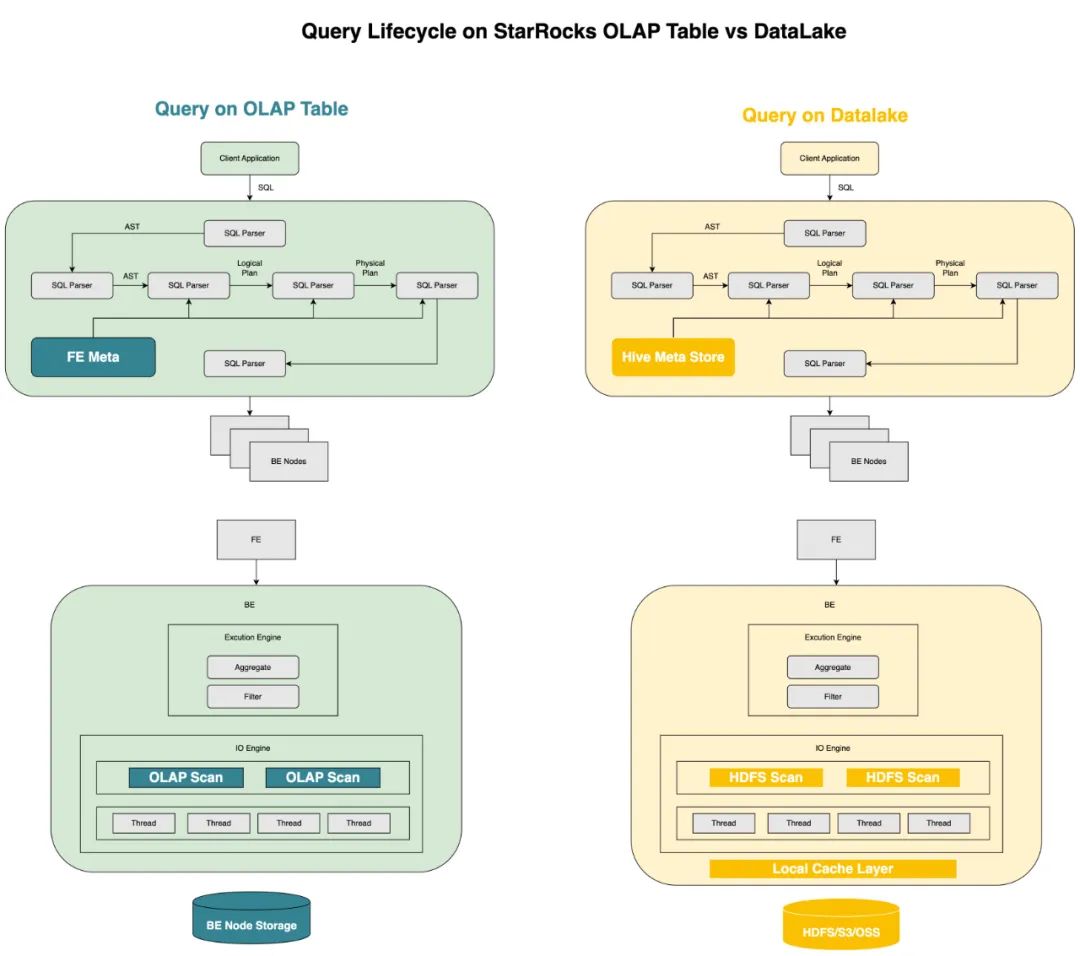
從工程效率來說,數據湖分析的前置工作,本質是便捷高效地完成元數據服務和存儲的訪問接入和同步工作。在這一場景里,2.2 版本之前的外部表要求用戶逐個手動完成表結構的配置,和 Presto/Trino 等產品相比,在易用性上還有一定差距。 從數據治理的角度來說,構架分析鏈路的關鍵環節之一就是,讓查詢層在接入時能夠遵循企業的數據安全規范,無論是元數據可見性還是表文件可訪問性。如何構建可信的數據安全屏障,打消架構師在技術選型時的顧慮,也是 StarRocks 在大規模生產用例中進行落地應用的基礎前提。 將當下面臨的問題抽絲剝繭之后,StarRocks 數據湖分析便有了更加清晰的產品目標:
Extreme performance:用極致查詢性能賦能數據驅動的業務團隊,讓用戶快速獲得對數據的見解
Out-of-box:需要提供更加開箱即用的數據接入體驗,以及更加安全合規的數據接入模式
Cost effective:為用戶提供具有性價比的資源持有方案,成為 Price-performance 維度的技術選型最優解
Uniformed platform:StarRocks 是帶有自管數據的現代架構 MPP 數據庫。當用戶分析內部數據和外部數據時,如何帶來一致的數據管理體驗,也是致力于現代湖倉架構的 StarRocks 面臨的核心挑戰之一。
#02全新的場景與挑戰—1查詢性能的挑戰
我們第一階段目標是對標主流的查詢引擎產品(例如 Presto/Trino),為數據湖上的查詢負載帶來 3-5 倍的性能提升。在團隊向這一目標推進過程中,我們的產品也遭遇了場景差異性帶來的挑戰。不同于查詢內表場景,對元數據服務以及分布式文件存儲的響應波動的魯棒性直接決定了用戶側的查詢體驗是否平穩。
在這里,我們以一條 Query on Hive 的生命周期來舉例,說明不同階段我們遇到的問題:
查詢規劃階段:若用戶查詢歷史明細數據,單條 Query 可能會同步觸發大量 Table Partition 的元數據請求,Metastore 的抖動又會導致 CBO 等待超時,最終引發查詢失敗。這是一個 Adhoc 場景中最典型的案例。在查詢規劃階段,如何在元信息拉取的全面性和時效性上做出體驗最好的權衡?
資源調度階段:Adhoc 場景下的系統負載有明顯的峰谷差異,從資源成本角度出發,彈性擴縮容自然是一個查詢組件在公有云場景需要具備的基礎特性。而在 StarRocks 存算一體的架構里,BE 節點擴縮容過程伴隨著數據重分布的代價。因此,如何才能為用戶提供容器化部署以及水平伸縮的可能性?另一方面,在大規模用例里經常會出現多業務部門共享集群的場景,如何為運行在數據湖上的查詢負載提供很好的隔離性,降低業務之間的影響?
查詢計劃生成階段:查詢數據湖時,目標數據的文件分布決定了 Scan 過程的 IO 開銷,而文件分布一般又取決于上游寫入習慣與文件合并策略。對于上游 CDC 入湖過程中里的大量小文件,如何設計靈活 Scan Policy 才能緩解 IO 帶來的查詢性能瓶頸?
查詢執行階段:我們都知道在生產環境中,HDFS 本身由于抖動帶來訪問延遲是很常見的現象,而這類抖動就直接給查詢速度造成波動,很影響業務用戶的分析體感。同時,Adhoc 場景本身的查詢習慣(例如針對全量歷史數據的一次聚合計算)決定了瓶頸并不在內存計算而是在 IO 上。如何讓 Query 再快一點?想在外部存儲上直接優化 IO 的問題,最直接的想法就是針對局部性較強的查詢場景,提供針對遠端存儲的數據文件 Cache 能力。
2數據管理的挑戰 借助 StarRocks 已有的全面向量化執行引擎、全新的 CBO 優化器等,這些能力能夠極大地提升我們在單表以及多表層面的性能表現。在這個基礎之上,針對數據湖分析的場景,我們也增加了新的優化規則。
相信關注 StarRocks 的讀者中很大一部分是基礎架構領域的從業人員。但凡和業務團隊打過交道,都會感同身受:推動業務部門升級基礎技術組件,成本非常的高。對公司 IT 治理來說,在每一次技術選型里,能否全面 cover 舊方案的基礎用例、把控業務遷移里的 bad case 同樣會影響選型成敗。此時 StarRocks 就更需要站在工程師朋友的視角上,全面審視湖分析場景中“水桶的短板”到底在哪里。
數據安全:數據湖作為維護企業核心數據資產的基礎設施,一般在企業內都會為其維護成熟的訪問控制策略,例如,在傳統 Hadoop 生態中基于 Kerberos 來定制統一認證,用 Ranger 做統一 ACL 管理;或者是接入云廠商托管的 IAM 服務。這些不同場景下數據治理的事實標準,均是考量數據湖分析產品成熟度的重要參考。
業務遷移:在嘗試用 StarRocks 來幫助用戶替換存量的 Presto/SparkSQL 查詢負載的過程中,用戶需要同步遷移原有的業務 SQL,甚至是 UDF。系統之間的語法糖差異越大,用戶在遷移過程里進行 SQL 重寫的成本就越高昂。面對引擎之間的語法差異,如何盡可能給用戶帶來平滑的遷移體感?
元數據管理:StarRocks 作為具有自管數據的 OLAP 系統,如果同時接入外部湖上的數據,意味著需要統籌管理系統內部/外部的元數據,并通過 StarRocks 展示統一視圖。系統外部元數據同步的數據一致性和開箱即用如何權衡?
3社區協作的挑戰 Eric S. Raymond 在《大教堂和集市》中說,一個項目若想成功,“要將用戶當做合作者”。開源產品的成功,從來不止步于完成一個特性的開發這么簡單。
歷史上,Hive 在大數據生態中并不是產品力最出眾的,正是其對計算引擎的包容普適性逐步造就了其不可替代的位置。StarRocks 站在 OLAP 查詢層的角度也希望為社區用戶構建一種普適性:于湖分析場景來說,任意數據源的接入需求,社區開發者都能夠快速流暢地完成接入開發。優雅高度抽象的代碼框架,理想中可以帶來一種雙贏的協作模式:用戶的需求能夠以社區互助的方式得到敏捷響應,產品能力也可以像滾雪球一樣愈加豐滿,伴隨社區生態不斷成長。
在這個愿景下,如何在起步階段定義出一個好的代碼框架,讓后續各類數據源對接的開發工作對社區的工程師同學盡可能友好,又能平滑兼容各類外部數據系統的差異性,則是數據湖研發團隊一個重點需要思考的問題。
#03
思考和關鍵行動
—
1數據湖生態全面完善
支持 Hudi 的 MOR 表(2.5.0 發布)
StarRocks 在 2.4 版本就通過 Catalog 提供了 Hudi 數據的接入能力。在即將發布的 2.5.0 版本,StarRocks 將會支持以 Snapshot query 和 Read optimized query 兩種查詢模式來支持 Hudi 的 MOR 表。
借助該特性,在數據實時入湖場景(例如上游 Flink CDC 到 Hudi),StarRocks 就可以更好支持用戶對實時落盤數據的分析需求。
支持 Delta Lake Catalog(2.5.0 發布)
在 2.5.0 版本中,StarRocks 將正式通過 Catalog 支持分析 Delta lake。目前支持以 Hive metastore 作為元數據服務,即將支持 AWS Glue。未來還將計劃逐步對接 Databricks 原生的元數據存儲。
通過這種方式,在 Spark 生態里批處理完成的數據,用戶就可以無需重復拷貝,直接在 StarRock 進行交互式分析。
支持 Iceberg V2 表(在 2.5.X 即將發布)
StarRocks 在 2.4 版本就通過 Catalog 提供了 Iceberg V1 數據的接入能力。在未來的 2.5 小版本中,我們即將正式支持對接 Iceberg V2 格式,全面打通 Iceberg 與 StarRocks 的數據生態。
支持 Parquet/ORC 文件外表
在部分場景下,用戶的數據文件直接由 Spark Job 或者其他方式寫入 DFS 生成,并不具備一個存儲在 Metastore 中的完整 Schema 信息。用戶如果希望直接分析這些文件,按照以往只能全量導入 StarRocks 后再進行分析。在一些臨時的數據分析場景下,這種全量導入的模式操作代價比較昂貴。
從 2.5.0 版本起,StarRocks 提供了文件外表的功能,用戶無需借助 Metastore 也可以直接對 DFS/對象存儲的文件直接進行分析,更可以借助 INSERT INTO 能力對目標文件進行導入前的結構變換和預處理。對于上游以原始文件作為數據源的分析場景,這種模式更靈活友好。2開箱即用的元數據接入方案
Multi-catalog (2.3.0已發布)
StarRocks 在 2.3 版本中發布了 Catalog 特性,同時提供了 Internal Catalog 和 External Catalog 來對 StarRocks 內部自有格式的數據以及外部數據湖中的數據進行統一管理。
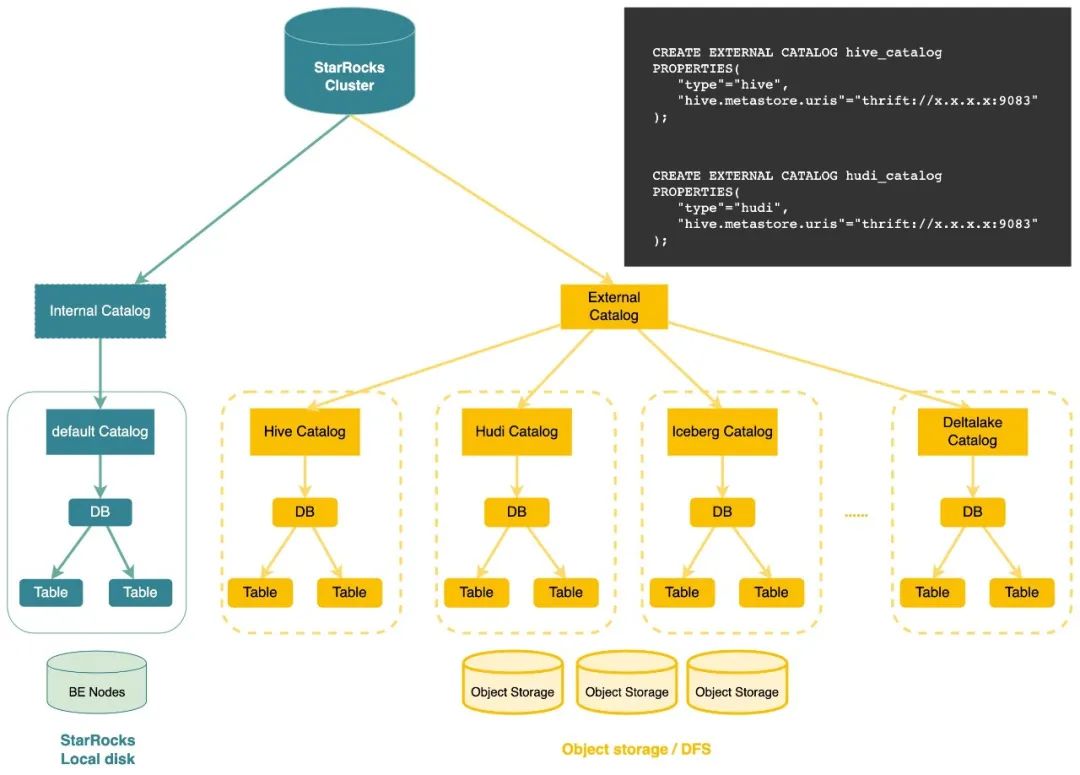
借助 External Catalog,用戶無需創建外部表即可對湖中的數據進行分析,維護 StarRocks 的平臺團隊也無需維護兩個系統之間的元數據一致性。
開箱即用的 Meta Cache policy(2.5.0發布)在 2.5 之前版本的 Hive catalog 里,元數據同步存在較多問題。一旦 Hive 表發生了分區的新增或是分區內數據發生了修改,往往需要用戶找到指定分區,并在 StarRocks 里手動執行 REFRESH PARTITION 才行。這對業務側的用戶帶來了較大困擾,因為業務分析師團隊往往無法感知具體哪個分區發生了數據變更。 在 2.5 版本,我們優化了這個系統行為,對于 Hive 追加分區,StarRocks 會在查詢時感知最新分區狀態;對于 Hive 分區中的數據更新,我們提供了REFRESH EXTERNAL TABLE 的方式來刷新最新的元數據狀態。 通過這種方式,Adhoc 場景里的業務團隊無需關心具體的分區數據更新,也可以在 StarRocks 訪問到具有正確性保證的數據結果。3完備的分析用例支持湖分析支持 Map&Struct(2.5.0發布)完整支持分析 Parquet/ORC 文件格式中的 Map 和 Struct 數據類型:

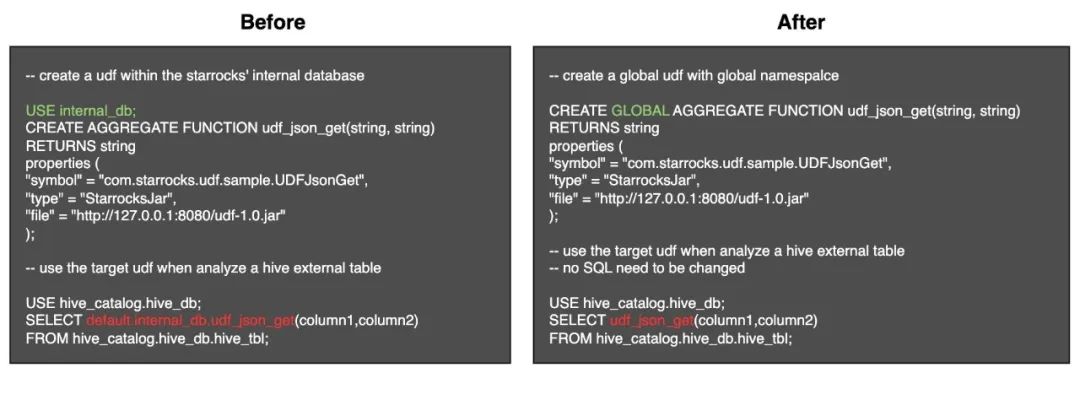
Global namespace 的 UDF(2.5.x 即將發布)在之前的 OLAP 場景中,StarRocks 的 UDF 是掛載在某個 database 下進行管理,Namespace 是 Database-level。這種模式在湖分析場景給用戶帶來一定的困擾,因為用戶無法直接通過 Function_name 來引用目標函數,而是通過
4極致性能體驗Blockcache(2.5.0發布)
為了優化重 IO 場景下的查詢場景,一方面降低熱數據查詢場景下,相同原始數據反復讀取的 IO 代價,另一方面緩解 DFS 本身波動對查詢性能帶來的波動,StarRocks 在 2.5.0 即將正式發布 Block cache 特性。
在 StarRocks 里,Block 是對 DFS/對象存儲中原始文件按照一定策略切分后的數據對象,也是 StarRocks 對原始數據文件進行緩存時的最小數據單元。當查詢命中 DFS/對象存儲中文件后,StarRocks 會對命中的 Block 進行本地緩存,支持內存+本地磁盤的混合存儲介質方式,并分別配置 Cache 對內存和本地磁盤的占用空間上限。基于 LRU 策略對遠端對象存儲上的 Block 進行載入和淘汰。
通過這種方式,大幅度優化了 HDFS 本身抖動的問題,無需頻繁訪問 HDFS;同時對于熱點數據上的交互式探查場景,大大提升了遠端對象存儲的數據拉取效率,用戶分析體驗得到極大提升。更重要的是,整個緩存機制沒有引入任何的外部依賴,通過配置文件即可開啟。
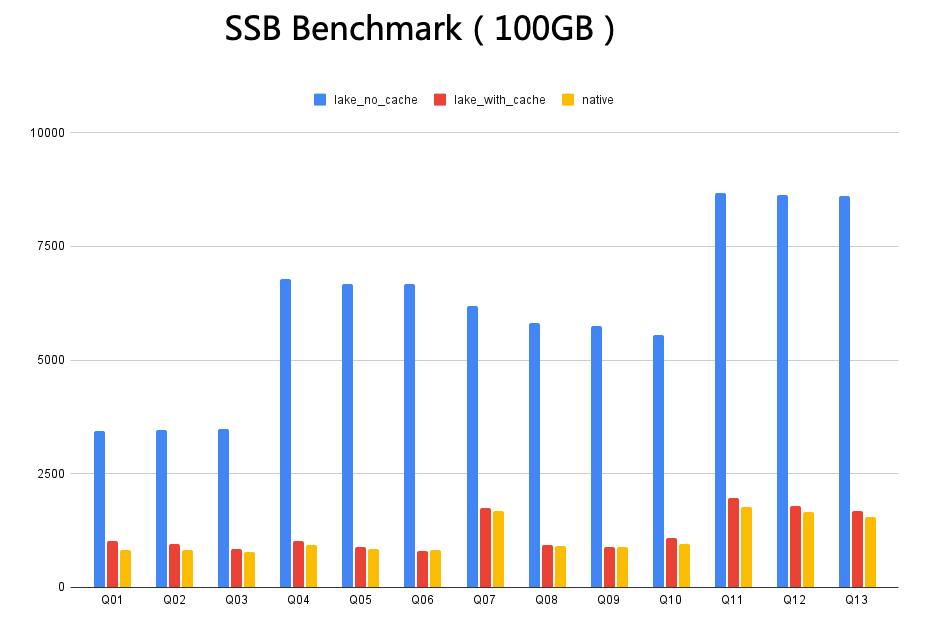
如下圖所示,以 100GB 的 SSB Benchmark 為例,實驗中以使用純內存作為緩存介質,以阿里云 OSS 作為對象存儲。其中 lake_with_cache 是緩存命中率 100% 情況下的查詢性能,Native 是指數據導入 StarRocks 后的查詢性能,lake_with_cache 是無緩存直接訪問 OSS 的查詢性能。從圖中可以觀測到:在緩存完全命中的前提下,cache 后的數據查詢性能基本追平將數據導入 StarRocks 的性能。這意味著在部分簡單場景下,借助 Blockcache 的能力,StarRocks 在已經能夠支撐部分延遲要求更加苛刻的 SQL 負載。
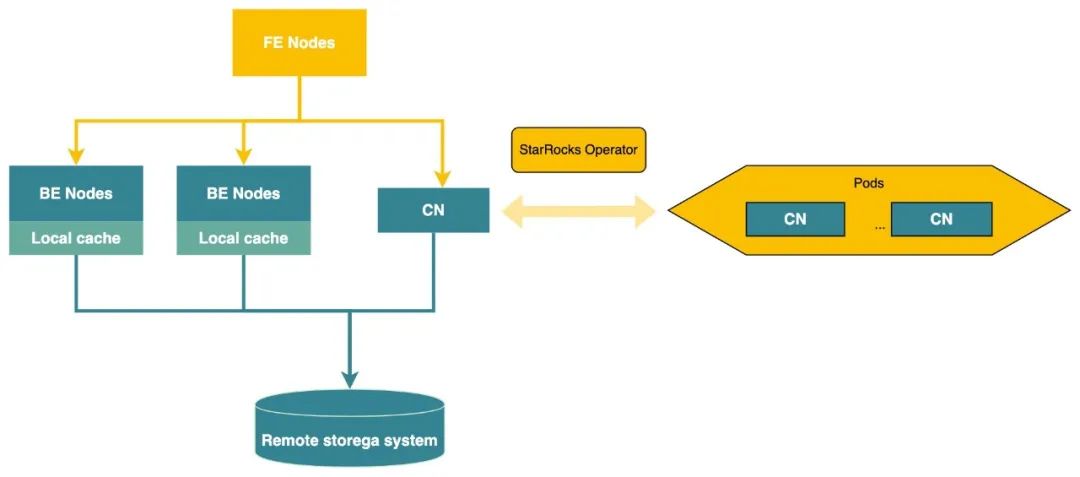
5更加靈活的資源管理模式StarRocksonK8S(2.5.0即將發布)在 StarRocks 存算一體的背景下,為了加節點提升集群整體查詢負載的同時又不帶來數據重分布代價,社區開發者們經過長達 3 個月的研發為社區貢獻了基于 K8S 的存算分離能力。具體來說,從 2.4.0 版本起,通過在 BE 節點的基礎之上,就已經重新抽象了一種無狀態的計算節點(Compute Node,簡稱CN)。 在數據湖分析場景,CN 可以承擔從 Scan 到 Shuffle 到聚合全生命周期的計算流程。CN 除了支持用戶進行免數據遷移的在線增減節點以外,還能夠通過容器化來進行部署。在此基礎上,社區官方還提供了全新的 StarRocks Operator,能夠在實際業務場景中后端流量&日志量激增時,實時感知分析平臺的負載激增,并快速地自動創建 Compute Node。同時,通過 Kubernetes 的 HPA 功能完成 Compute Node 的彈性擴縮容(該特性已經在 2.4 版本發布)。內核級別的靈活彈性,一方面,大大優化了數據湖場景下用戶維護 StarRocks 的 TCO,另一方面也給基于 StarRocks 構建 Serverless 形態的湖分析產品提供了無限想象空間。
從 2.5.0 版本起,StarRocks 的 FE/BE 也基本完成了容器化部署的兼容。不久,社區官方 Operator 也即將發布,屆時將會大大提升運維效率和生產力。
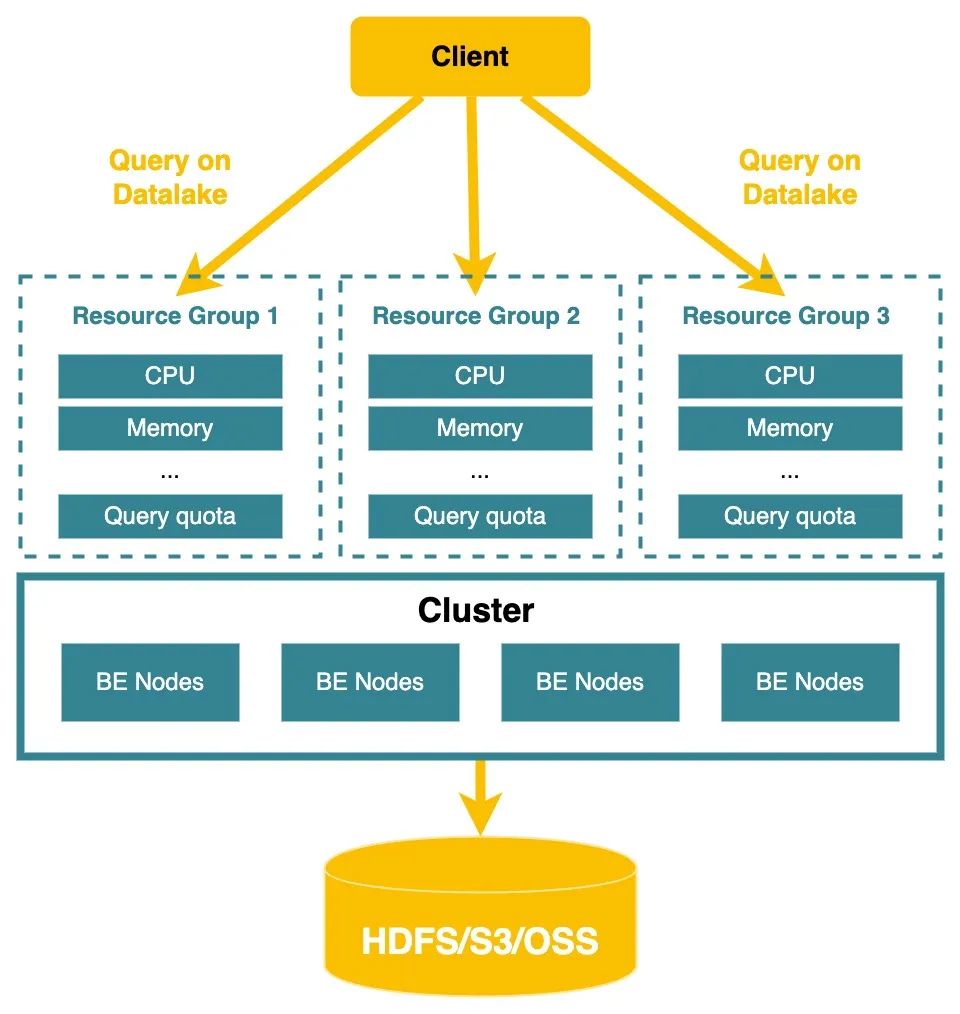
利用Resource group對湖上的分析負載進行軟隔離(2.3.0已發布)
StarRocks 在 2.2 版本發布了資源隔離能力。在 2.3 版本支持了通過資源組來對數據湖上的查詢負載進行隔離。通過這種軟隔離的資源劃分機制,能夠讓這些 Adhoc query 運行時在特定的 CPU 核數/內存范圍之下,用戶的大規模集群在同時支持多個部門的固定報表分析業務和 Adhoc 業務時,能夠具有更好的隔離性,湖上的大查詢相互之間可以優先保障穩定。
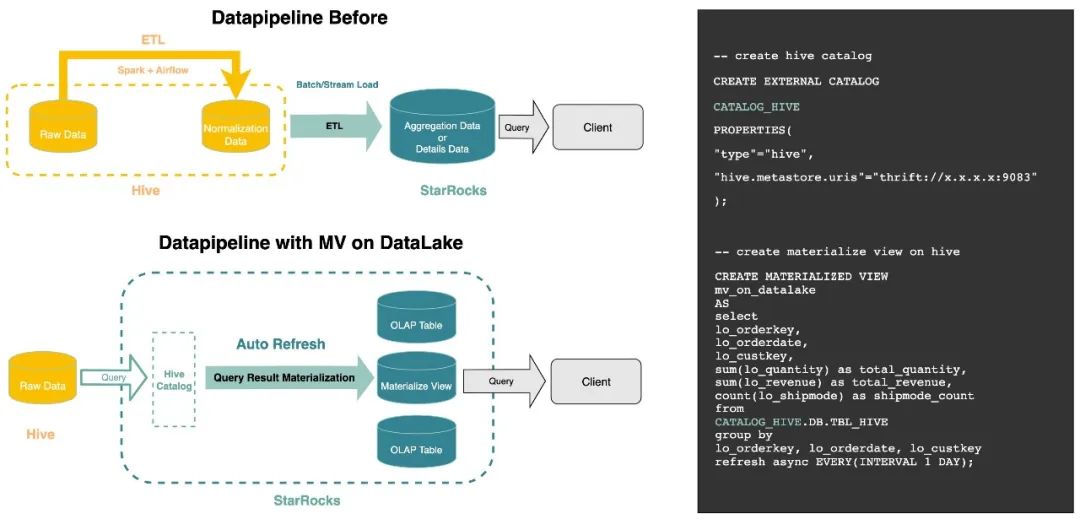
6湖倉深度融合支持在數據湖上構建自動刷新的物化視圖(2.5.0發布)物化視圖是數據庫技術中的一種經典查詢加速手段,主要給用戶帶來兩大價值點:查詢加速和數據建模。在 2.4 版本中,我們發布了全新的物化視圖,該物化視圖在語義上是一張用戶可感知并獨立查詢的表,具備將復雜查詢結果進行物化并自動刷新的能力。 從 2.5 版本開始,StarRocks 支持直接在數據湖上構建物化視圖,用戶只需要在創建物化視圖時,基于 INSERT INTO SELECT 定義好數據加工處理的邏輯以及自動刷新的時間周期(例如 1 天),物化視圖便會自動將湖上數據進行處理,并把結果落盤在 StarRocks 的本地存儲上。同時考慮到 ODS 層全表掃描的代價比較重,例行執行這類查詢會給內存帶來大量不必要開銷。對于 Hive 分區表場景,V2.5.0 的物化視圖還支持在創建時掃描最近 K 個分區數量,從而搭配分區裁剪來控制例行掃描的數據量。 參考下圖,我們可以看到前后對比:對于一些常見的 ETL 任務及其調度場景,我們無需再依賴外部系統,跨系統間的 ETL 鏈路也得到了縮短。對于平臺團隊來說,大大節約了運維成本。 在 V2.5.X 的后續小版本,我們還即將針對數據湖上的查詢提供自動路由能力。通過后臺查詢改寫技術(Query rewrite),當用戶的 SQL 查詢 Hive 時,系統會基于匹配程度將 Query 自動路由到物化視圖上,直接返回提前聚合處理好的數據結果。對于物化視圖和源表數據存在不一致的場景,系統也會提供默認兜底策略來優先保證查詢結果的正確性。真正意義上實現統一一份元數據的前提下,盡可能給數據湖上的查詢負載帶來 MPP 數據倉庫的查詢并發和分析體驗。
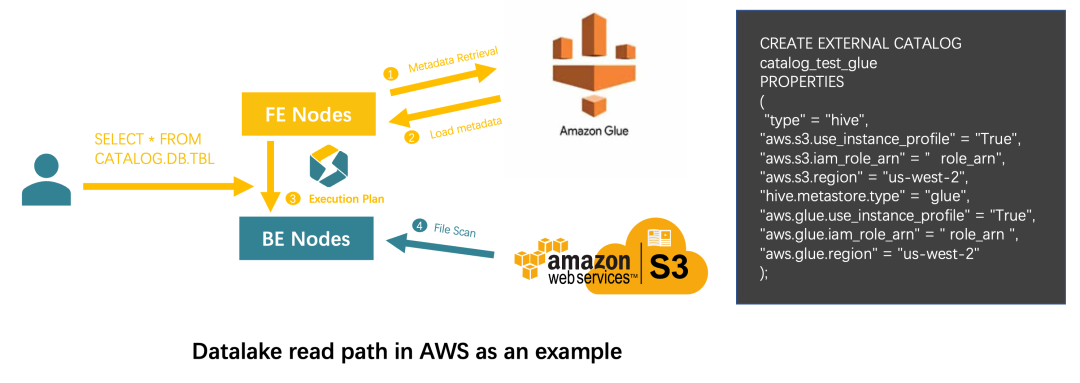
7公有云生態打通集成AWS Glue作為湖分析的Metastore,對云上數據資產進行統一分析(2.5.0發布)根據 AWS 官方文檔介紹,AWS Glue 作為完全兼容 Hive metastore 的統一目錄服務,為用戶 Region 內的數據資產提供了統一視圖,并能夠在 EMR 中作為云原生的 Metastore 一鍵開啟。這給公有云用戶在 EMR 上提供了開箱即用的數據管理體驗。同時,其內置的 Crawlers 功能還可以輕松的幫助 S3 文件批量生成表 Schema,賦予其 Hive table 的語義,從而對各類查詢引擎的分析負載將會更加靈活友好。 StarRocks 為了給公有云用戶帶來更加云原生和一體化的數據分析體驗,早在 2.3 版本就支持了阿里云的 Datalake formation 的集成,從 2.5.0 版本開始正式支持以 AWS Glue 作為湖分析時的 Metastore。 借助這一特性,AWS 上的 StarRocks 用戶可以在 AWS Glue 里控制元數據的訪問權限;也可以通過 StarRocks 湖分析能力,借助更高效的查詢性能,使用 SQL 按需分析對象存儲文件,同時保證了安全和數據分析效率。
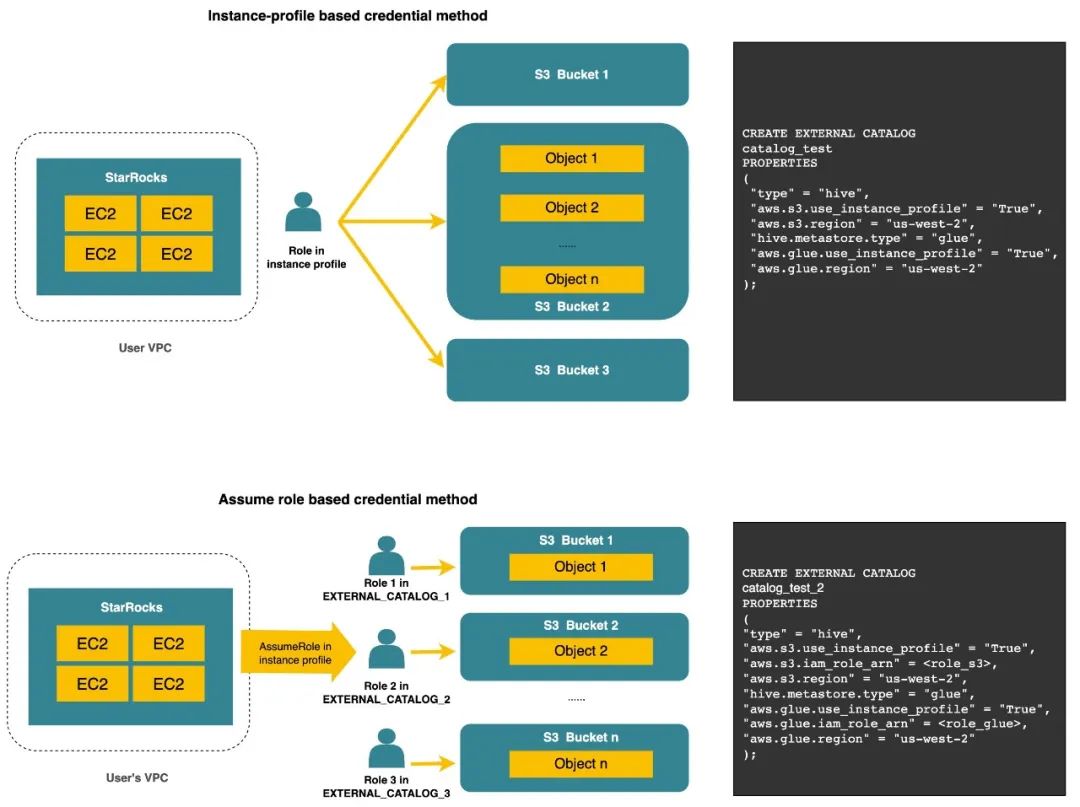
深度集成AWS IAM,支持Secret key&IAM Role等多種認證方式(在2.5.X即將發布)除了性能維度,數據安全從來都是數據湖分析場景里做技術選型的重中之重。在過往積累的海內外用戶案例里,我們注意到云廠商給對象存儲等云資源提供了完整的認證和訪問管理機制(IAM),而我們的用戶也會根據不同云廠商的 IAM 產品邏輯來定義符合企業安全需求的數據訪問規范。以 Amazon Cloud Service 為例,這些用戶常用的云資源訪問管理策略包括但不限于:
通過統一的 Access key/Secret key 來進行用戶身份進行認證和鑒權
通過 IAM Role 搭配角色代理的機制,來實現不同角色身份的動態切換
借助 AWS EC2 的 Instance profile 中自帶的身份信息進行認證
在未來的 V2.5.X 小版本里,StarRocks 數據湖分析將會對上述幾種公有云場景用戶常用的認證方式進行完備的兼容。未來 StarRocks 在公有云上的數據訪問管理將會更加省心省力,數據安全不再成為企業云上 OLAP 技術選型的顧慮。
#04
Benchmark驗證
—1StarRocks vs Presto(Trino)
SSB Flat on Hive
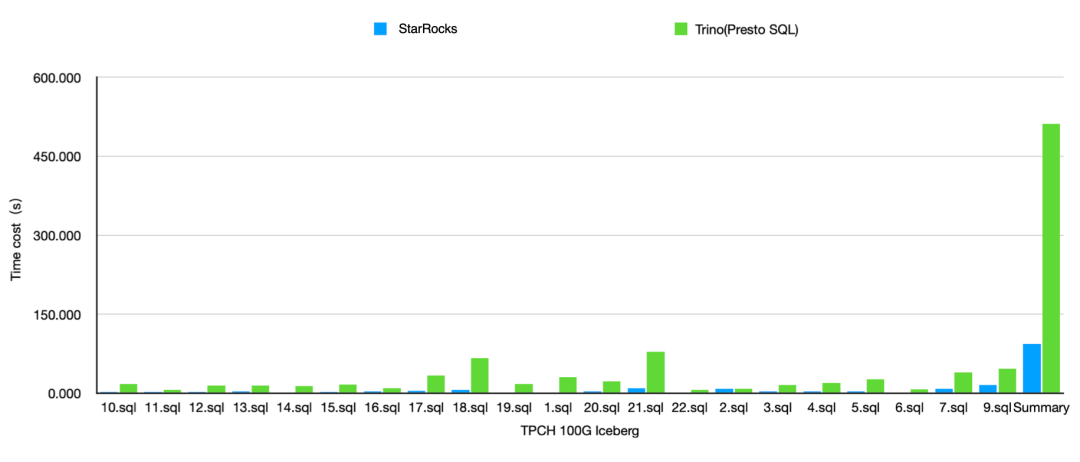
以 2.5 最新版本為基準,StarRocks 和業界最主流的湖分析引擎 Trino 367 在 100GB 的 SSBFlat 測試集(HDFS)上分別進行了查詢 Hive 的性能測試對比。并行度均為 8,Cache 均未開啟。
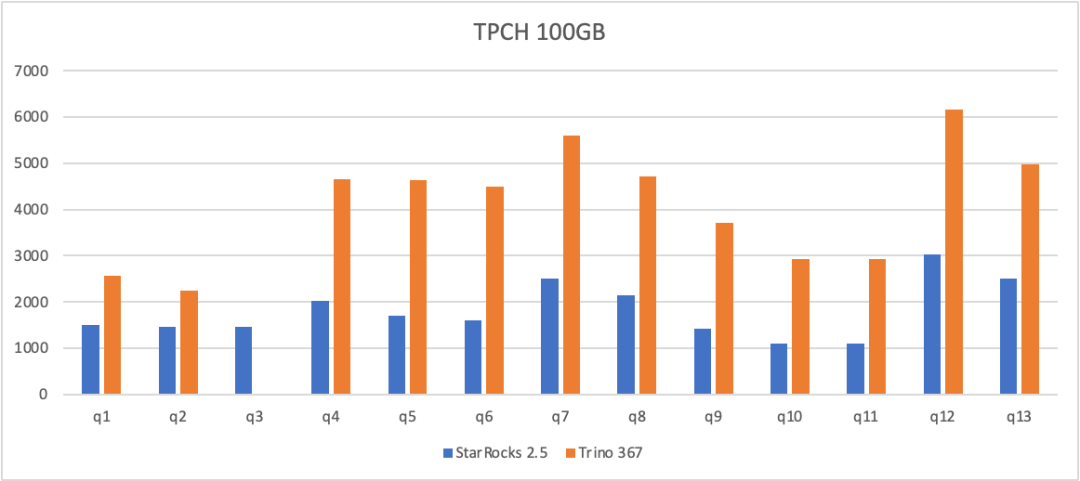
在大寬表場景下,相比 Trino,StarRocks 在 Hive 上有 2-3 倍的性能提升。
TPCH on Hudi
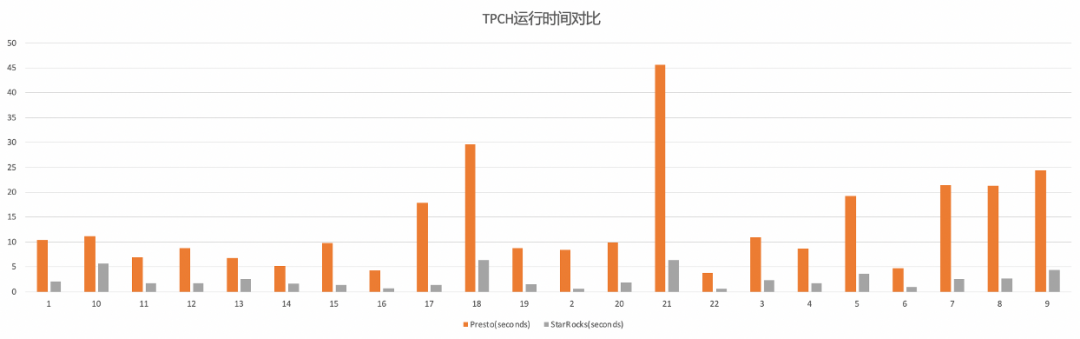
在 100GB 的 TPCH 場景下,我們還和 Presto 對比了在 COW 表上的查詢性能。從圖中可以看見,在 COW 表上,相比 Presto,StarRocks 的查詢性能有 3-5 倍不等的穩定性能提升。
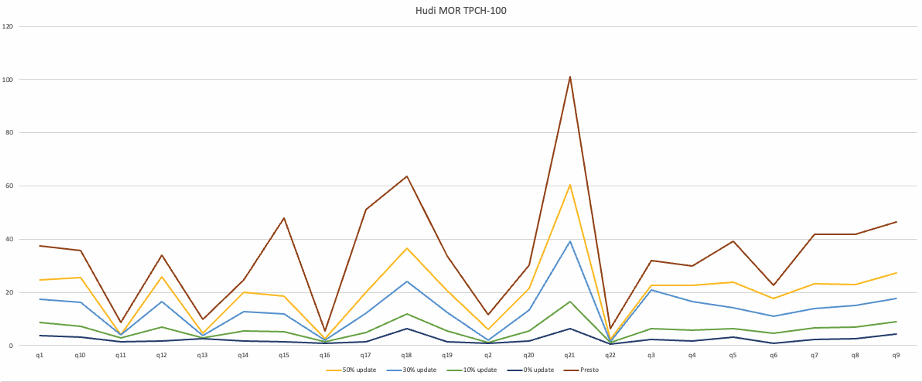
另外,我們還針對了 MOR 存在的更新場景,和 Presto 進行了一個對比實驗。下圖中,Presto 的場景最簡單,無數據更新;而 StarRocks 查詢 MOR 時候分別對比了無更新和有數據更新的場景(查詢模式均為 Snapshot query)。可以觀察到,面對無更新的 MOR 表,StarRocks(下圖深藍線) 整體性能能夠穩定的提升 3-5 倍。在數據更新占比分別為 10%(下圖綠色線)、30%(下圖淺藍線)、50%(下圖黃色線)的場景中,StarRocks 在承擔文件讀時合并開銷的前提下,查詢性能依舊大幅超越 Presto(下圖深紅線)。
TPCH on Iceberg
在 100GB 的 TPCH 場景下,我們也和 Presto 在 Iceberg v1 format 上做了性能對比。可以觀測到,平均性能整體上有 3-5 倍不等的提升。
除了在標準測試集進行的驗證,StarRocks 的湖分析特性也在各類企業用戶的生產環境中得到了大規模驗證,幫助用戶在分析效能和數據加工成本上獲得了提升:
華米科技基于 StarRocks 構建了 Hive 分析平臺,對接了企業內的 Superset 等 BI 工具。并維護專用 StarRocks 集群用來承接 Hive 上的查詢負載,相比于原 SparkSQL,給業務分析團隊極大的提升了取數分析的效率。后續關于 GlobalUDF 等特性也將助力更多的業務 SQL 平滑遷移到 StarRocks 上面來。
在汽車之家的自助分析平臺場景,內部的多引擎融合分析平臺選擇集成了 StarRocks 來作為 Hive 的統一查詢層。用真實線上業務 SQL 測試后對比 Presto 集群,根據觀測結果顯示,80% 的真實業務 SQL 負載有了 3 倍不等的性能提升。后續伴隨關于 Map&Struct 數據類型的新特性上線,也將進一步提升 StarRocks 對業務 SQL 查詢負載支持的完備程度。
騰訊游戲基于 StarRocks 在 Iceberg 數據湖上構建了存算分離的 Serverless 數據分析架構,支撐了單表 TB 級別的湖分析場景,并落地了性能和成本均衡的云原生架構方案。
理想汽車基于 StarRocks 的 Hive 外表替換了 Impala。一方面通過外表 Join 等特性縮短了數據加工的鏈路,同時也緩解了原 Hadoop 集群的運維壓力。
#05
未來規劃
—
1Table Sink in Datalake 從 2.5 版本開始,我們就會陸續強化 StarRocks 針對 Iceberg/Hudi 等主流數據湖的 Table sink 能力。借助這一能力,對于用戶通過 StarRocks 探查分析得到的結果集,隨時都可以通過 CREATE TABLE AS SELECT ... 的方式回寫到數據湖當中,使得這些數據資產能夠基于數據湖本身的 Open table format 在不同的引擎/服務之間實現自由共享,告別反復的遷移復制。2跨引擎語法兼容
不同查詢引擎之間有各自的語法糖。一旦業務團隊的分析行為依賴這些語法糖,那么使用 StarRocks 對 Presto/Trino 等存量系統的替換過程就變得更加繁瑣。因為這涉及到業務 SQL 改寫,給用戶也帶來了額外的困擾和成本。
為了幫助用戶更加省心地實現統一湖倉分析,StarRocks 計劃在系統內分階段提供針對多種查詢引擎的 Parser 插件,并幫助用戶自動跨引擎的語法樹自動轉換。借助這個能力,用戶通過 Client 連接 StarRocks 時,只需要手動指定當前會話生效的 Parser 類型,即可將其他引擎的原生 SQL 直接運行在 StarRocks 的 MPP 架構之上。既避免了 SQL 遷移改寫,又可以直接享受到 StarRocks 的極速分析性能。3Azure/Google Cloud Platform集成 StarRocks 這兩年產品力的進步有目共睹,國內各大云廠商也陸陸續續在 EMR 上為用戶提供了 StarRocks 的托管式服務,這正是社區用戶廣泛呼聲的最強論證。作為一個無國界、開放包容的開源社區,StarRocks 也有計劃在全球公有云的復雜場景中繼續深度打磨和成長。目前,StarRocks 已經和 Amazon Web Service 完成了主要的生態組件集成,并陸陸續續開始承載全球公有云用戶的一些核心分析業務。未來還計劃全面支持 Google Cloud Platform 和 Azure Cloud。4在物化視圖上拓展增量查詢語義,構建增量數據Pipeline
物化視圖是連接數據湖和數據倉庫的一個天然樞紐。在 Hadoop 時代,MapReduce 計算框架和 Hive format 還沒有能力去識別和處理增量數據,因此整個 ETL Pipeline 還是在分區級別Scan的查詢語義上構建的,這帶來了時效性和計算效率低下的瓶頸。
在基于 StarRocks 構建湖倉一體架構的時候,我們就在思考:既然主流的數據湖 Table format 均能夠支持訪問增量數據,而物化視圖又能夠自動完成湖倉之間的 ETL,為什么我們不直接讓整個 Pipeline 基于增量的查詢語義來構建?對于增量實時入湖的場景,增量 Pipeline 既能夠節約重復掃描歷史數據的開銷。借助增量微批的計算模型把每次計算的代價降低,從而使湖倉之間的同步和建模計算可以更加頻繁,獲得更高的時效性。
因此,在數據湖上拓展增量查詢的語義,未來也會是物化視圖支撐湖倉一體化融合的一個重要思路。5批處理能力強化 批處理能力是建模場景的基礎能力,而這也正是 StarRocks 需要持續強化的地方。之前用戶傾向于將數據建模好后導入 StarRocks 承接查詢負載。在數據湖場景里,我們需要支撐用戶能夠將 ODS 層的明細數據按需進行靈活加工和處理,并寫入 StarRocks 或者直接將查詢結果處理后回寫到湖中,批處理能力是對 MPP 架構的一個重大挑戰,也是未來我們重點強化的場景之一。6外部數據細粒度權限管理 目前我們對外部數據的權限管理還停留在 Catalog 級別,這種看似簡單的數據訪問方式也帶來了數據權限放大的隱患。在 3.0 版本后,我們將會給用戶提供全新的 RBAC 權限管理模型,其中也會提供幫助用戶實現 Database 和 External table 級別訪問管理的全新能力。
#06
寫在最后
—
自 Databricks 的論文面世,Lakehouse 成了大數據從業者津津樂道的行業藍圖。但這套架構是否能替代 Warehouse 支持當下的所有主流場景用例,顯然現在下結論也許為時過早,每一個新技術在上升期過后也多多少少都會面臨“跨越鴻溝”的挑戰。成為一款最適合湖分析場景的產品,也遠遠不是做好一個 feature 這么簡單。
順著 Lakehouse 這個方向望向前方,依舊有很多的全新的挑戰在等待 StarRocks。實時數倉與流式引擎的關系,表格式讀取接口的開放與封閉,元數據如何實現更靈活的訪問共享,這些都是我們未來需要思考和解決的問題。
從 2.1 版本開始,StarRocks 花費了大量精力來思考和探索:在數據湖時代我們能給用戶帶來的價值在哪里?企業工程師和社區開發者需要理解一個邏輯:采用新式數據湖架構,并不意味著我們需要徹底拋棄 MPP 數倉架構的諸多特性。如何利用 StarRocks 在優化器/計算引擎/存儲引擎等諸多能力優勢,幫助用戶進一步釋放湖上數據分析的無限想象空間,正是 StarRocks DLA 這個項目的核心價值所在。
StarRock V2.5 對 DLA 來說是一個重要轉折點,我們在湖分析場景里的思路也愈加清晰。如何利用 StarRocks 更好地支持湖分析場景,助力用戶完成 OLAP 層統一?敬請關注我們的社區動態和 Release Plan。
審核編輯 :李倩
-
數據
+關注
關注
8文章
7085瀏覽量
89203 -
API
+關注
關注
2文章
1505瀏覽量
62174 -
SQL
+關注
關注
1文章
768瀏覽量
44177
原文標題:當打造一款極速湖分析產品時,我們在想些什么
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

吉時利2450數字源表如何分析信號的頻譜特性

StarRocks 與 AWS 合作持續深入,為全球245個國家企業用戶提供輕量化云服務
STM32F407讀取掛在FSMC上的外部ADC數據,開啟DMA的Mem to Mem模式時只能讀取一次FSMC數據,為什么?
阻抗分析儀的原理與特性
什么是數據湖?數據湖和數據倉庫有什么區別?
巡湖護河聯合執法 解決通信是關鍵

rc電路移相特性的觀察與分析
華為推出全新數據湖解決方案及全閃存新品
工業物聯網系統推動持續復蘇河湖生態環境
揭秘湖倉一體:大數據演進的未來趨勢與影響






 工商網監
工商網監
評論