") 超融合數(shù)據(jù)中心網(wǎng)絡(luò)架構(gòu)的典型特征與價(jià)值
超融合數(shù)據(jù)中心網(wǎng)絡(luò)架構(gòu)的典型特征與價(jià)值
介紹了數(shù)據(jù)中心網(wǎng)絡(luò)對于算力的意義,歸納出影響數(shù)據(jù)中心全以太化演進(jìn)的因素,以及超融合數(shù)據(jù)中心網(wǎng)絡(luò)架構(gòu)的典型特征與價(jià)值。
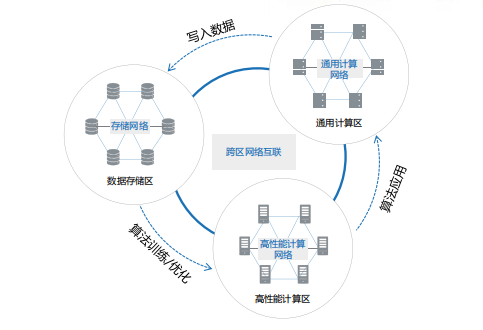
結(jié)合業(yè)界在超融合數(shù)據(jù)中心網(wǎng)絡(luò)技術(shù)中的實(shí)踐與探索,對超融合數(shù)據(jù)中心網(wǎng)絡(luò)架構(gòu)的未來發(fā)展進(jìn)行了展望。數(shù)據(jù)中心內(nèi)數(shù)據(jù)處理包括數(shù)據(jù)的存儲(chǔ)、計(jì)算和應(yīng)用三個(gè)環(huán)節(jié),分別對應(yīng)三大資源區(qū):
數(shù)據(jù)存儲(chǔ)區(qū):存儲(chǔ)服務(wù)器內(nèi)置不同的存儲(chǔ)介質(zhì),如機(jī)械硬盤、閃存盤(SSD)、藍(lán)光等,對于數(shù)據(jù)進(jìn)行存儲(chǔ)、讀寫與備份,存儲(chǔ)節(jié)點(diǎn)間通過存儲(chǔ)網(wǎng)絡(luò)互聯(lián)。
高性能計(jì)算區(qū):服務(wù)器較少虛擬化,配置CPU、GPU 等計(jì)算單元進(jìn)行高性能計(jì)算或 AI 訓(xùn)練,服務(wù)器節(jié)點(diǎn)間通過高性能計(jì)算網(wǎng)絡(luò)互聯(lián)。
通用計(jì)算區(qū):服務(wù)器大量使用 VM或容器等虛擬化技術(shù),通過通用計(jì)算網(wǎng)絡(luò)(又稱為應(yīng)用網(wǎng)絡(luò)、業(yè)務(wù)網(wǎng)絡(luò)、前端網(wǎng)絡(luò)),與外部用戶終端對接提供服務(wù)。
在這個(gè)持續(xù)循環(huán)的過程中,網(wǎng)絡(luò)就像聯(lián)接計(jì)算和存儲(chǔ)資源的中樞神經(jīng),貫穿數(shù)據(jù)處理的全生命周期。數(shù)據(jù)中心算力水平不僅取決于計(jì)算服務(wù)器和存儲(chǔ)服務(wù)器的性能,很大程度上也受到網(wǎng)絡(luò)性能的影響。如果網(wǎng)絡(luò)算力水平無法滿足要求,則會(huì)引發(fā)“木桶效應(yīng)”拉低整個(gè)數(shù)據(jù)中心的實(shí)際算力水平。
數(shù)據(jù)中心算力是數(shù)據(jù)中心的服務(wù)器通過對數(shù)據(jù)進(jìn)行處理后實(shí)現(xiàn)結(jié)果輸出的一種能力。在服務(wù)器主板上,數(shù)據(jù)傳輸?shù)捻樞蛞来螢?CPU、內(nèi)存、硬盤和網(wǎng)卡,若針對圖形則需要 GPU。所以,從廣義上講,數(shù)據(jù)中心算力是一個(gè)包含計(jì)算、存儲(chǔ)、傳輸(網(wǎng)絡(luò))等多個(gè)內(nèi)涵的綜合概念,是衡量數(shù)據(jù)中心計(jì)算能力的一個(gè)綜合指標(biāo)。
提升網(wǎng)絡(luò)性能可顯著改進(jìn)數(shù)據(jù)中心算力能效比
定 義 數(shù) 據(jù) 中 心 算 效(CE,Computational Efficiency)為數(shù)據(jù)中心算力與所有 IT 設(shè)備功耗的比值,即“數(shù)據(jù)中心 IT 設(shè)備每瓦功耗所產(chǎn)生的算力”(單位:FLOPS/W):

在服務(wù)器規(guī)模不變的情況下,提升網(wǎng)絡(luò)能力可顯著改善數(shù)據(jù)中心單位能耗下的算力水平。ODCC2019 年針對基于以太的網(wǎng)算一體交換機(jī)的測試數(shù)據(jù)表明,在 HPC場景同等服務(wù)器規(guī)模下,相對于傳統(tǒng) RoCE(基于融合以太的遠(yuǎn)程內(nèi)存直接訪問協(xié)議)網(wǎng)絡(luò),網(wǎng)算一體技術(shù)可大幅度降低HPC 的任務(wù)完成時(shí)間,平均降幅超過 20%。即:單位時(shí)間提供的算力提升 20%,同等算力下能耗成本降低 20%。
在存儲(chǔ)網(wǎng)絡(luò)場景,采用基于 NVMeover Fabric 的無損以太網(wǎng)絡(luò),可實(shí)現(xiàn)同等服務(wù)器規(guī)模 下, 存 儲(chǔ) IOPS性能相對于傳統(tǒng) FC網(wǎng)絡(luò)最高可提升87%,這也將大幅減少業(yè)務(wù)端到端運(yùn)行時(shí)長。由此可見,重構(gòu)數(shù)據(jù)中心網(wǎng)絡(luò)可以實(shí)現(xiàn)在單位ICT 能耗下對算力的極大提升,更好滿足綠色節(jié)能數(shù)據(jù)中心的建設(shè)要求。在大算力需求持續(xù)高漲的情況下,為企業(yè)帶來更加直接的價(jià)值。
存儲(chǔ)全閃存化驅(qū)動(dòng) RoCE 產(chǎn)業(yè)生態(tài)發(fā)展
相比 HDD,SSD 介質(zhì)在短時(shí)間內(nèi)將存儲(chǔ)性能提升了近 100 倍,實(shí)現(xiàn)了跨越式的發(fā)展,而 FC 網(wǎng)絡(luò)技術(shù)無論是從帶寬或時(shí)延已成為存儲(chǔ)網(wǎng)絡(luò)場景的系統(tǒng)瓶頸,存儲(chǔ)業(yè)務(wù)開始呼喚更快、更高質(zhì)量的網(wǎng)絡(luò)。為此,存儲(chǔ)與網(wǎng)絡(luò)從架構(gòu)和協(xié)議層進(jìn)行了深度重構(gòu),NVMeoverFabric 應(yīng)運(yùn)而生。
在新一代存儲(chǔ)網(wǎng)絡(luò)技術(shù)的選擇上,業(yè)界存在NVMeoverFC、NVMeoverRoCE等多條路徑。然而,F(xiàn)C 網(wǎng)絡(luò)始終無法突破三大挑戰(zhàn):
第一、FC 網(wǎng)絡(luò)技術(shù)及互通性相對封閉,整體產(chǎn)業(yè)生態(tài)與連續(xù)性面臨著很大挑戰(zhàn);
第二、由于產(chǎn)業(yè)規(guī)模受限,F(xiàn)C 技術(shù)的發(fā)展相對遲緩,目前最大帶寬只有 32G 且已長達(dá) 6 年沒有出現(xiàn)跨代式技術(shù);
第三、同樣由于產(chǎn)業(yè)規(guī)模受限,F(xiàn)C 網(wǎng)絡(luò)運(yùn)維人員稀缺,能夠運(yùn)維 FC 網(wǎng)絡(luò)的技術(shù)人員不足以太網(wǎng)絡(luò)維護(hù)人員的 1/10。這造成 FC網(wǎng)絡(luò)運(yùn)維成本居高不下,故障解決效率低下。
相比FC網(wǎng)絡(luò),NVMeoverRoCE 技術(shù)無論從產(chǎn)業(yè)規(guī)模、技術(shù)活躍度、架構(gòu)擴(kuò)展性、開放生態(tài)、和多年 SDN(Software-DefinedNetwork,軟件定義網(wǎng)絡(luò))管理運(yùn)維能力積累上都具有明顯的優(yōu)勢,已成為下一代存儲(chǔ)網(wǎng)絡(luò)技術(shù)的最優(yōu)選擇。
CPU/GPU 去PCIe化,直出以太以獲取極致性能
隨著人工智能技術(shù)的快速發(fā)展,PCIe 總線瓶頸凸顯。PCIe 是英特爾在 2001 年提出的高速串行計(jì)算機(jī)擴(kuò)展總線標(biāo)準(zhǔn),接口速度決定了 CPU 間的通信速度,而接口數(shù)量則決定了主板的擴(kuò)展性。
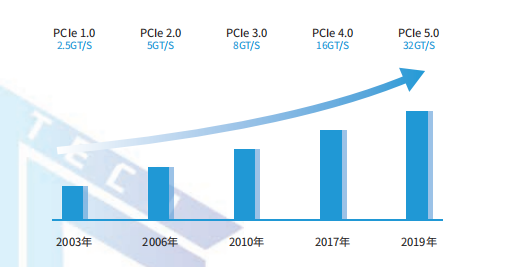
當(dāng)前,占據(jù)數(shù)據(jù)中心服務(wù)器 CPU 市場絕對地位的 Intelx86 架構(gòu)普遍使用 PCIe3.0,PCIe3.0 單通道僅支持 8GT/s 的傳輸速率,且通道擴(kuò)展數(shù)量有限。在 AI 超算服務(wù)器已經(jīng)全面邁入 100GE 網(wǎng)卡的時(shí)代,PCIe3.0 架構(gòu)速率成為大吞吐高性能計(jì)算場景下的性能瓶頸。
為此,業(yè)界開始探索計(jì)算單元去 PCIe 之路。2019 年,Habana 公司發(fā)布了在 AI 芯片處理器片內(nèi)集成 RoCE 以太端口的處理器 Gaudi,Gaudi 將10 個(gè)基于融合以太網(wǎng)的 RoCE-RDMA100GE 端口集成到處理器芯片中,每個(gè)以太網(wǎng)端口均支持 RoCE功能,從而讓 AI 系統(tǒng)通過標(biāo)準(zhǔn)以太網(wǎng),在速度和端口數(shù)方面獲得了幾乎無限的可擴(kuò)展性,提供了過去的芯片無法實(shí)現(xiàn)的可擴(kuò)展能力。同年,華為的達(dá)芬奇芯片昇騰 910 集成了 RoCE 接口,通過片內(nèi)RoCE 實(shí)現(xiàn)節(jié)點(diǎn)間直接互聯(lián),為構(gòu)建橫向擴(kuò)展(ScaleOut)和縱向擴(kuò)展(ScaleUp)系統(tǒng)提供了靈活高效的方法。
IPv6 大規(guī)模部署,產(chǎn)業(yè)政策加速以太化進(jìn)程
IPv6 即互聯(lián)網(wǎng)協(xié)議第6版,是互聯(lián)網(wǎng)工程任務(wù)組設(shè)計(jì)的用于替代 IPv4 的下一代 IP 協(xié)議。IPv6 不僅能解決網(wǎng)絡(luò)地址資源數(shù)量的問題,而且還解決了多種接入設(shè)備連入互聯(lián)網(wǎng)的障礙問題,具有更大的地址空間和更高的安全性。從人人互聯(lián)到萬物智聯(lián),網(wǎng)絡(luò)對 IP 地址的需求量指數(shù)級增加;數(shù)據(jù)中心作為智能世界的算力中樞,IPv6 成為互聯(lián)的基礎(chǔ)訴求。
超融合數(shù)據(jù)中心網(wǎng)絡(luò)架構(gòu)與核心特征
下一代超融合數(shù)據(jù)中心網(wǎng)絡(luò)需具備如下特征,實(shí)現(xiàn)三個(gè)層面的融合:
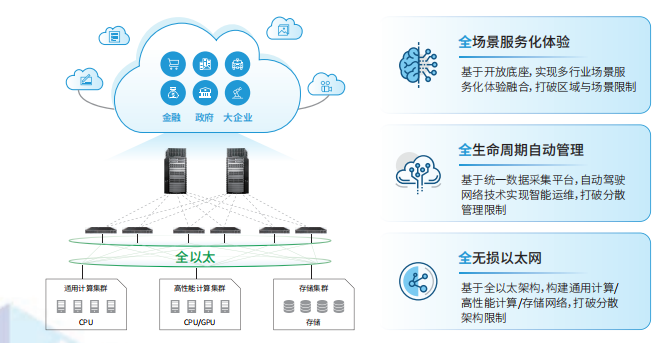
? 全無損以太網(wǎng)絡(luò),實(shí)現(xiàn)流量承載融合:通用計(jì)算、存儲(chǔ)、高性能計(jì)算網(wǎng)絡(luò)統(tǒng)一承載在 0 丟包以太網(wǎng)技術(shù)棧上,實(shí)現(xiàn)大規(guī)模組網(wǎng)協(xié)議統(tǒng)一,TCP、RoCE 數(shù)據(jù)混流運(yùn)行,打破傳統(tǒng)分散架構(gòu)限制;
? 全生命周期自動(dòng)管理,實(shí)現(xiàn)管控析融合:基于統(tǒng)一網(wǎng)絡(luò)數(shù)字孿生底座,加以大數(shù)據(jù)及 AI 手段,實(shí)現(xiàn)規(guī)劃、建設(shè)、維護(hù)、優(yōu)化全生命周期自動(dòng)化,代替人工處理大量重復(fù)性、復(fù)雜性的操作,并可基于海量數(shù)據(jù)提升網(wǎng)絡(luò)預(yù)測和預(yù)防能力,打破多工具多平臺(tái)分散管理限制;
? 全場景服務(wù)化能力,實(shí)現(xiàn)全場景融合:抽象數(shù)據(jù)中心網(wǎng)絡(luò)“物理網(wǎng)絡(luò)服務(wù)”、“邏輯網(wǎng)絡(luò)服務(wù)”、“應(yīng)用服務(wù)”、“互聯(lián)服務(wù)”、“網(wǎng)絡(luò)安全服務(wù)”、“分析服務(wù)”等核心服務(wù)能力,基于開放服務(wù)化架構(gòu)實(shí)現(xiàn)多廠家、離線與在線數(shù)據(jù)的靈活接入。滿足多私有云、多公有云、混合云、以及豐富行業(yè)場景下的網(wǎng)絡(luò)統(tǒng)一編排需求,支持算力跨云靈活智能調(diào)度,打破區(qū)域與場景限制。
超融合數(shù)據(jù)中心網(wǎng)絡(luò)技術(shù)最佳實(shí)踐
基于全無損以太的超融合數(shù)據(jù)中心網(wǎng)絡(luò)技術(shù)正在迅猛發(fā)展,在存儲(chǔ)、高性能計(jì)算、通用計(jì)算等場景得到了較好地商業(yè)實(shí)踐。
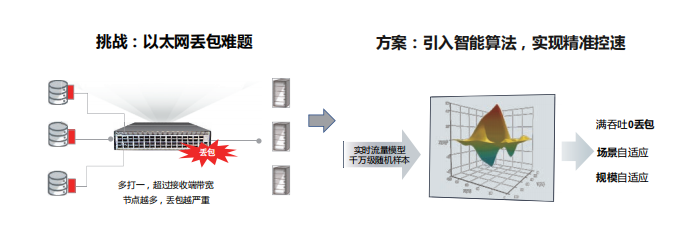
在無損網(wǎng)絡(luò)方向,標(biāo)準(zhǔn)以太網(wǎng)絡(luò)雖然有 QoS 以及流量控制能力,但執(zhí)行機(jī)制簡單粗暴,通常通過靜態(tài)水線控制。靜態(tài)水線無法適應(yīng)千變?nèi)f化的存儲(chǔ)業(yè)務(wù)流量,設(shè)置過高可能引發(fā)丟包,設(shè)置過低則無法充分釋放存儲(chǔ)的 IOPS 性能。為了解決這個(gè)難題,業(yè)界將 AI 機(jī)制引入到交換機(jī)中,一方面交換機(jī)可毫秒級感知流量變化,另一方面基于海量存儲(chǔ)流量樣本持續(xù)訓(xùn)練獲得的 AI 算法可通過智能動(dòng)態(tài)調(diào)整隊(duì)列水線實(shí)現(xiàn)亞秒級流量精準(zhǔn)控制,最大程度釋放存儲(chǔ)性能。
在可靠性方面,業(yè)界正在推動(dòng)網(wǎng)絡(luò)與存儲(chǔ)在故障場景下的聯(lián)動(dòng)標(biāo)準(zhǔn)化方案。通過交換機(jī)毫秒級主動(dòng)通告故障,并聯(lián)動(dòng)存儲(chǔ)協(xié)同倒換,可支持亞秒級的網(wǎng)絡(luò)故障倒換,真正實(shí)現(xiàn)網(wǎng)絡(luò)單點(diǎn)故障存儲(chǔ)業(yè)務(wù)無感知。
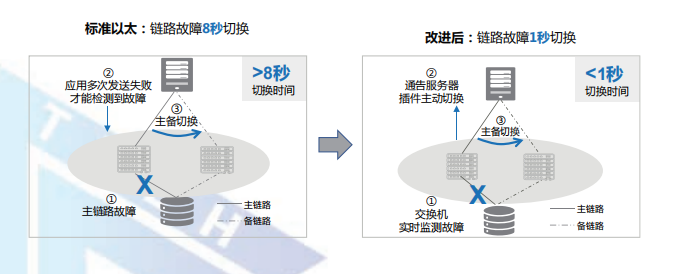
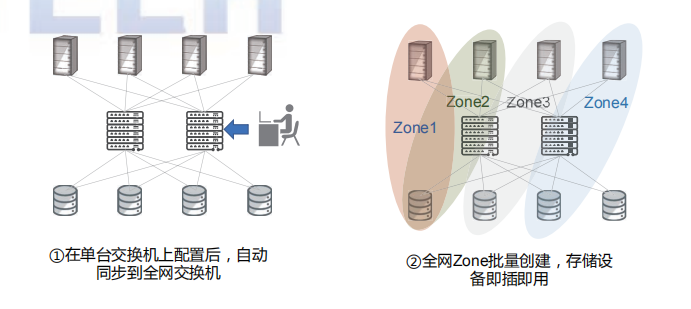
在網(wǎng)絡(luò)易用性與運(yùn)維方面,業(yè)界發(fā)布了以太網(wǎng)絡(luò)環(huán)境下的存儲(chǔ)即插即用最佳實(shí)踐,相比傳統(tǒng)以太逐節(jié)點(diǎn)、逐 ZONE 手工配置方式,可以做到業(yè)務(wù)單點(diǎn)配置、全網(wǎng)同步,實(shí)現(xiàn)存儲(chǔ)設(shè)備的即插即用。
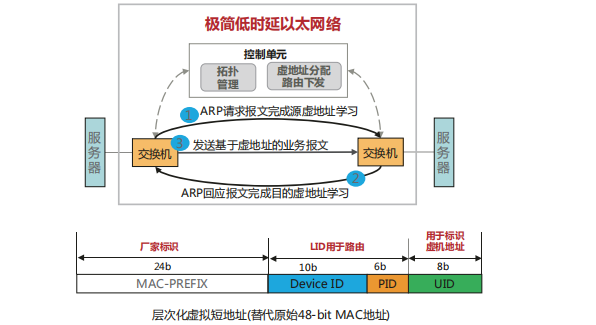
由于傳統(tǒng) FC 網(wǎng)絡(luò)當(dāng)前主流商用端口帶寬只有8G,最大端口帶寬只有 32G,同城 100G 存儲(chǔ)傳輸往往需要 4~10 條以上的鏈路。相比之下,以太網(wǎng)絡(luò) 100G/400G 接口能力已經(jīng)成熟商用,可以大幅減少同城鏈路資源。然而,在同城雙活及災(zāi)備場景中,跨城傳輸時(shí)延增大,短距流控反壓機(jī)制存在嚴(yán)重的滯后性。以同城 70 公里傳輸場景為例,RTT(Round-TripTime)時(shí)延往往大于 1 毫秒,導(dǎo)致傳統(tǒng)流控機(jī)制徹底失效。網(wǎng)絡(luò)時(shí)延由四部分組成:
動(dòng)態(tài)時(shí)延:主要由排隊(duì)時(shí)延產(chǎn)生,受端口擁塞影響;
靜態(tài)時(shí)延:主要包括網(wǎng)絡(luò)轉(zhuǎn)發(fā)(查表)時(shí)延和轉(zhuǎn)發(fā)接口時(shí)延,一般為固定值,當(dāng)前以太交換靜態(tài)時(shí)延遠(yuǎn)高于超算專網(wǎng);
網(wǎng)絡(luò)跳數(shù):指消息在網(wǎng)絡(luò)中所經(jīng)歷的設(shè)備數(shù);
入網(wǎng)次數(shù):指消息進(jìn)入網(wǎng)絡(luò)的次數(shù)。新一代無損以太網(wǎng)絡(luò)在動(dòng)態(tài)時(shí)延、靜態(tài)時(shí)延、網(wǎng)絡(luò)跳數(shù)以及入網(wǎng)次數(shù)幾個(gè)方面均做出了系統(tǒng)性優(yōu)化,大幅優(yōu)化了網(wǎng)絡(luò)性能,可滿足高性能計(jì)算場景的實(shí)際訴求。
傳統(tǒng)的以太交換機(jī)在轉(zhuǎn)發(fā)層面,因需要考慮兼容性和眾多協(xié)議支持等問題,導(dǎo)致轉(zhuǎn)發(fā)流程復(fù)雜、轉(zhuǎn)發(fā)時(shí)延較大。與此同時(shí),以太查表算法復(fù)雜、查表時(shí)延大,導(dǎo)致整體轉(zhuǎn)發(fā)處理時(shí)延長。目前業(yè)界主流商用以太交換機(jī)的靜態(tài)轉(zhuǎn)發(fā)時(shí)延大約在 600ns-1us 左右。
高性能計(jì)算場景的流量關(guān)注靜態(tài)時(shí)延的同時(shí)需要支持超大規(guī)模組網(wǎng)。然而傳統(tǒng)的 CLOS 架構(gòu)作為主流網(wǎng)絡(luò)架構(gòu),主要關(guān)注通用性,犧牲了時(shí)延和性價(jià)比。業(yè)界針對該問題開展了多樣的架構(gòu)研究和新拓?fù)涞脑O(shè)計(jì)。
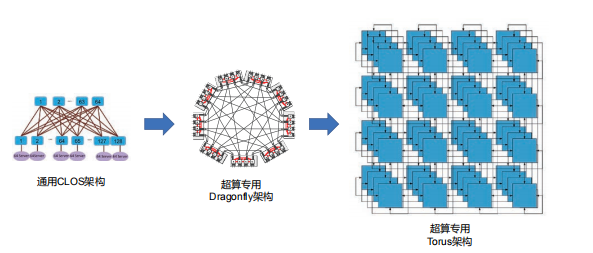
當(dāng)前數(shù)據(jù)中心網(wǎng)絡(luò)架構(gòu)設(shè)計(jì)大多基于工程經(jīng)驗(yàn),不同搭建方式之間難以選擇,缺乏理論指導(dǎo)和統(tǒng)一性設(shè)計(jì)語言。網(wǎng)絡(luò)拓?fù)湫阅苤笜?biāo)繁多,不同指標(biāo)之間相互制約,指標(biāo)失衡很難避免。
審核編輯:郭婷
-
cpu
+關(guān)注
關(guān)注
68文章
10890瀏覽量
212405 -
SSD
+關(guān)注
關(guān)注
21文章
2871瀏覽量
117588 -
數(shù)據(jù)中心
+關(guān)注
關(guān)注
16文章
4832瀏覽量
72252
原文標(biāo)題:超融合數(shù)據(jù)中心網(wǎng)絡(luò)解決方案
文章出處:【微信號:架構(gòu)師技術(shù)聯(lián)盟,微信公眾號:架構(gòu)師技術(shù)聯(lián)盟】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
簡述數(shù)據(jù)中心網(wǎng)絡(luò)架構(gòu)的演變
云數(shù)據(jù)中心、智算中心、超算中心,有何區(qū)別?

數(shù)據(jù)中心交換機(jī)購買指南
華為聯(lián)合IEEE面向全球發(fā)布L4數(shù)據(jù)中心自動(dòng)駕駛網(wǎng)絡(luò)白皮書

超融合基礎(chǔ)架構(gòu)的軟硬件設(shè)計(jì)思路

訊維融合通信系統(tǒng)在金融數(shù)據(jù)中心建設(shè)的實(shí)踐探索
超融合架構(gòu)解決方案


傳統(tǒng)數(shù)據(jù)中心架構(gòu)和葉脊架構(gòu)網(wǎng)絡(luò)解決方案
CloudFabric3.0超融合數(shù)據(jù)中心網(wǎng)絡(luò)全新升級,攜手共筑算力新聯(lián)接
介紹一種高性能計(jì)算和數(shù)據(jù)中心網(wǎng)絡(luò)架構(gòu):InfiniBand(IB)
數(shù)據(jù)中心網(wǎng)絡(luò)架構(gòu):萬兆電口模塊的重要作用

華為發(fā)布2024數(shù)據(jù)中心能源十大趨勢,引領(lǐng)未來變革






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論