") 軟件設(shè)計(jì)開(kāi)發(fā)性能優(yōu)化的十種手段(取與舍)
軟件設(shè)計(jì)開(kāi)發(fā)性能優(yōu)化的十種手段(取與舍)
作者(code2life)寫了上中下三篇關(guān)于性能優(yōu)化的文章,內(nèi)容由淺入深涉及性能方方面面,并不僅僅局限于代碼層面。 于是借花獻(xiàn)佛,把作者的三篇整理合并之后分享給大家。希望你也能有所收獲。 本文是上篇,講解六種通用的“時(shí)間”與“空間”互換取舍的手段。
引言:取與舍
軟件設(shè)計(jì)開(kāi)發(fā)某種意義上是“取”與“舍”的藝術(shù)。 關(guān)于性能方面,就像建筑設(shè)計(jì)成抗震9度需要額外的成本一樣,高性能軟件系統(tǒng)也意味著更高的實(shí)現(xiàn)成本,有時(shí)候與其他質(zhì)量屬性甚至?xí)_突,比如安全性、可擴(kuò)展性、可觀測(cè)性等等。 大部分時(shí)候我們需要的是:在業(yè)務(wù)遇到瓶頸之前,利用常見(jiàn)的技術(shù)手段將系統(tǒng)優(yōu)化到預(yù)期水平。 那么,性能優(yōu)化有哪些技術(shù)方向和手段呢? 性能優(yōu)化通常是“時(shí)間”與“空間”的互換與取舍。 本篇分兩個(gè)部分,在上篇,講解六種通用的“時(shí)間”與“空間”互換取舍的手段:
索引術(shù)
壓縮術(shù)
緩存術(shù)
預(yù)取術(shù)
削峰填谷術(shù)
批量處理術(shù)
在下篇,介紹四種進(jìn)階性的內(nèi)容,大多與提升并行能力有關(guān):
八門遁甲 —— 榨干計(jì)算資源
影分身術(shù) —— 水平擴(kuò)容
奧義 —— 分片術(shù)
秘術(shù) —— 無(wú)鎖術(shù)
每種性能優(yōu)化的技術(shù)手段,我都找了一張應(yīng)景的《火影忍者》中人物或忍術(shù)的配圖,評(píng)論區(qū)答出任意人物或忍術(shù)送一顆小星星。 (注:所有配圖來(lái)自動(dòng)漫《火影忍者》,部分圖片添加了文字方便理解,僅作技術(shù)交流用途)
索引術(shù)
索引的原理是拿額外的存儲(chǔ)空間換取查詢時(shí)間,增加了寫入數(shù)據(jù)的開(kāi)銷,但使讀取數(shù)據(jù)的時(shí)間復(fù)雜度一般從O(n)降低到O(logn)甚至O(1)。 索引不僅在數(shù)據(jù)庫(kù)中廣泛使用,前后端的開(kāi)發(fā)中也在不知不覺(jué)運(yùn)用。 在數(shù)據(jù)集比較大時(shí),不用索引就像從一本沒(méi)有目錄而且內(nèi)容亂序的新華字典查一個(gè)字,得一頁(yè)一頁(yè)全翻一遍才能找到; 用索引之后,就像用拼音先在目錄中先找到要查到字在哪一頁(yè),直接翻過(guò)去就行了。 書籍的目錄是典型的樹(shù)狀結(jié)構(gòu),那么軟件世界常見(jiàn)的索引有哪些數(shù)據(jù)結(jié)構(gòu),分別在什么場(chǎng)景使用呢?
哈希表(Hash Table):哈希表的原理可以類比銀行辦業(yè)務(wù)取號(hào),給每個(gè)人一個(gè)號(hào)(計(jì)算出的Hash值),叫某個(gè)號(hào)直接對(duì)應(yīng)了某個(gè)人,索引效率是最高的O(1),消耗的存儲(chǔ)空間也相對(duì)更大。K-V存儲(chǔ)組件以及各種編程語(yǔ)言提供的Map/Dict等數(shù)據(jù)結(jié)構(gòu),多數(shù)底層實(shí)現(xiàn)是用的哈希表。
二叉搜索樹(shù)(Binary Search Tree):有序存儲(chǔ)的二叉樹(shù)結(jié)構(gòu),在編程語(yǔ)言中廣泛使用的紅黑樹(shù)屬于二叉搜索樹(shù),確切的說(shuō)是“不完全平衡的”二叉搜索樹(shù)。從C++、Java的TreeSet、TreeMap,到Linux的CPU調(diào)度,都能看到紅黑樹(shù)的影子。Java的HashMap在發(fā)現(xiàn)某個(gè)Hash槽的鏈表長(zhǎng)度大于8時(shí)也會(huì)將鏈表升級(jí)為紅黑樹(shù),而相比于紅黑樹(shù)“更加平衡”的AVL樹(shù)反而實(shí)際用的更少。
平衡多路搜索樹(shù)(B-Tree):這里的B指的是Balance而不是Binary,二叉樹(shù)在大量數(shù)據(jù)場(chǎng)景會(huì)導(dǎo)致查找深度很深,解決辦法就是變成多叉樹(shù),MongoDB的索引用的就是B-Tree。
葉節(jié)點(diǎn)相連的平衡多路搜索樹(shù)(B+ Tree):B+ Tree是B-Tree的變體,只有葉子節(jié)點(diǎn)存數(shù)據(jù),葉子與相鄰葉子相連,MySQL的索引用的就是B+樹(shù),Linux的一些文件系統(tǒng)也使用的B+樹(shù)索引inode。其實(shí)B+樹(shù)還有一種在枝椏上再加鏈表的變體:B*樹(shù),暫時(shí)沒(méi)想到實(shí)際應(yīng)用。
日志結(jié)構(gòu)合并樹(shù)(LSM Tree):Log Structured Merge Tree,簡(jiǎn)單理解就是像日志一樣順序?qū)懴氯ィ鄬佣鄩K的結(jié)構(gòu),上層寫滿壓縮合并到下層。LSM Tree其實(shí)本身是為了優(yōu)化寫性能犧牲讀性能的數(shù)據(jù)結(jié)構(gòu),并不能算是索引,但在大數(shù)據(jù)存儲(chǔ)和一些NoSQL數(shù)據(jù)庫(kù)中用的很廣泛,因此這里也列進(jìn)去了。
字典樹(shù)(Trie Tree):又叫前綴樹(shù),從樹(shù)根串到樹(shù)葉就是數(shù)據(jù)本身,因此樹(shù)根到枝椏就是前綴,枝椏下面的所有數(shù)據(jù)都是匹配該前綴的。這種結(jié)構(gòu)能非常方便的做前綴查找或詞頻統(tǒng)計(jì),典型的應(yīng)用有:自動(dòng)補(bǔ)全、URL路由。其變體基數(shù)樹(shù)(Radix Tree)在Nginx的Geo模塊處理子網(wǎng)掩碼前綴用了;Redis的Stream、Cluster等功能的實(shí)現(xiàn)也用到了基數(shù)樹(shù)(Redis中叫Rax)。
跳表(Skip List):是一種多層結(jié)構(gòu)的有序鏈表,插入一個(gè)值時(shí)有一定概率“晉升”到上層形成間接的索引。跳表更適合大量并發(fā)寫的場(chǎng)景,不存在紅黑樹(shù)的再平衡問(wèn)題,Redis強(qiáng)大的ZSet底層數(shù)據(jù)結(jié)構(gòu)就是哈希加跳表。
倒排索引(Inverted index):這樣翻譯不太直觀,可以叫“關(guān)鍵詞索引”,比如書籍末頁(yè)列出的術(shù)語(yǔ)表就是倒排索引,標(biāo)識(shí)出了每個(gè)術(shù)語(yǔ)出現(xiàn)在哪些頁(yè),這樣我們要查某個(gè)術(shù)語(yǔ)在哪用的,從術(shù)語(yǔ)表一查,翻到所在的頁(yè)數(shù)即可。倒排索引在全文索引存儲(chǔ)中經(jīng)常用到,比如ElasticSearch非常核心的機(jī)制就是倒排索引;Prometheus的時(shí)序數(shù)據(jù)庫(kù)按標(biāo)簽查詢也是在用倒排索引。
數(shù)據(jù)庫(kù)主鍵之爭(zhēng):自增長(zhǎng) vs UUID。主鍵是很多數(shù)據(jù)庫(kù)非常重要的索引,尤其是MySQL這樣的RDBMS會(huì)經(jīng)常面臨這個(gè)難題:是用自增長(zhǎng)的ID還是隨機(jī)的UUID做主鍵? 自增長(zhǎng)ID的性能最高,但不好做分庫(kù)分表后的全局唯一ID,自增長(zhǎng)的規(guī)律可能泄露業(yè)務(wù)信息;而UUID不具有可讀性且太占存儲(chǔ)空間。 爭(zhēng)執(zhí)的結(jié)果就是找一個(gè)兼具二者的優(yōu)點(diǎn)的折衷方案:
用雪花算法生成分布式環(huán)境全局唯一的ID作為業(yè)務(wù)表主鍵,性能尚可、不那么占存儲(chǔ)、又能保證全局單調(diào)遞增,但引入了額外的復(fù)雜性,再次體現(xiàn)了取舍之道。
再回到數(shù)據(jù)庫(kù)中的索引,建索引要注意哪些點(diǎn)呢?
定義好主鍵并盡量使用主鍵,多數(shù)數(shù)據(jù)庫(kù)中,主鍵是效率最高的聚簇索引;
在Where或Group By、Order By、Join On條件中用到的字段也要按需建索引或聯(lián)合索引,MySQL中搭配explain命令可以查詢DML是否利用了索引;
類似枚舉值這樣重復(fù)度太高的字段不適合建索引(如果有位圖索引可以建),頻繁更新的列不太適合建索引;
單列索引可以根據(jù)實(shí)際查詢的字段升級(jí)為聯(lián)合索引,通過(guò)部分冗余達(dá)到索引覆蓋,以避免回表的開(kāi)銷;
盡量減少索引冗余,比如建A、B、C三個(gè)字段的聯(lián)合索引,Where條件查詢A、A and B、A and B and C
都可以利用該聯(lián)合索引,就無(wú)需再給A單獨(dú)建索引了;根據(jù)數(shù)據(jù)庫(kù)特有的索引特性選擇適合的方案,比如像MongoDB,還可以建自動(dòng)刪除數(shù)據(jù)的TTL索引、不索引空值的稀疏索引、地理位置信息的Geo索引等等。
數(shù)據(jù)庫(kù)之外,在代碼中也能應(yīng)用索引的思維,比如對(duì)于集合中大量數(shù)據(jù)的查找,使用Set、Map、Tree這樣的數(shù)據(jù)結(jié)構(gòu),其實(shí)也是在用哈希索引或樹(shù)狀索引,比直接遍歷列表或數(shù)組查找的性能高很多。
緩存術(shù)
緩存優(yōu)化性能的原理和索引一樣,是拿額外的存儲(chǔ)空間換取查詢時(shí)間。緩存無(wú)處不在,設(shè)想一下我們?cè)跒g覽器打開(kāi)這篇文章,會(huì)有多少層緩存呢?
首先解析DNS時(shí),瀏覽器一層DNS緩存、操作系統(tǒng)一層DNS緩存、DNS服務(wù)器鏈上層層緩存;
發(fā)送一個(gè)GET請(qǐng)求這篇文章,服務(wù)端很可能早已將其緩存在KV存儲(chǔ)組件中了;
即使沒(méi)有擊中緩存,數(shù)據(jù)庫(kù)服務(wù)器內(nèi)存中也緩存了最近查詢的數(shù)據(jù);
即使沒(méi)有擊中數(shù)據(jù)庫(kù)服務(wù)器的緩存,數(shù)據(jù)庫(kù)從索引文件中讀取,操作系統(tǒng)已經(jīng)把熱點(diǎn)文件的內(nèi)容放置在Page Cache中了;
即使沒(méi)有擊中操作系統(tǒng)的文件緩存,直接讀取文件,大部分固態(tài)硬盤或者磁盤本身也自帶緩存;
數(shù)據(jù)取到之后服務(wù)器用模板引擎渲染出HTML,模板引擎早已解析好緩存在服務(wù)端內(nèi)存中了;
歷經(jīng)數(shù)十毫秒之后,終于服務(wù)器返回了一個(gè)渲染后的HTML,瀏覽器端解析DOM樹(shù),發(fā)送請(qǐng)求來(lái)加載靜態(tài)資源;
需要加載的靜態(tài)資源可能因Cache-Control在瀏覽器本地磁盤和內(nèi)存中已經(jīng)緩存了;
即使本地緩存到期,也可能因Etag沒(méi)變服務(wù)器告訴瀏覽器304 Not Modified繼續(xù)緩存;
即使Etag變了,靜態(tài)資源服務(wù)器也因其他用戶訪問(wèn)過(guò)早已將文件緩存在內(nèi)存中了;
加載的JS文件會(huì)丟到JS引擎執(zhí)行,其中可能涉及的種種緩存就不再展開(kāi)了;
整個(gè)過(guò)程中鏈條上涉及的所有的計(jì)算機(jī)和網(wǎng)絡(luò)設(shè)備,執(zhí)行的熱點(diǎn)代碼和數(shù)據(jù)很可能會(huì)載入CPU的多級(jí)高速緩存。
這里列舉的僅僅是一部分常見(jiàn)的緩存,就有多種多樣的形式:從廉價(jià)的磁盤到昂貴的CPU高速緩存,最終目的都是用來(lái)?yè)Q取寶貴的時(shí)間。 既然緩存那么好,那么問(wèn)題就來(lái)了:緩存是“銀彈”嗎? 不,Phil Karlton 曾說(shuō)過(guò):
There are only two hard things in Computer Science: cache invalidation and naming things.
計(jì)算機(jī)科學(xué)中只有兩件困難的事情:緩存失效和命名規(guī)范。 緩存的使用除了帶來(lái)額外的復(fù)雜度以外,還面臨如何處理緩存失效的問(wèn)題。
多線程并發(fā)編程需要用各種手段(比如Java中的synchronized volatile)防止并發(fā)更新數(shù)據(jù),一部分原因就是防止線程本地緩存的不一致;
緩存失效衍生的問(wèn)題還有:緩存穿透、緩存擊穿、緩存雪崩。解決用不存在的Key來(lái)穿透攻擊,需要用空值緩存或布隆過(guò)濾器;解決單個(gè)緩存過(guò)期后,瞬間被大量惡意查詢擊穿的問(wèn)題需要做查詢互斥;解決某個(gè)時(shí)間點(diǎn)大量緩存同時(shí)過(guò)期的雪崩問(wèn)題需要添加隨機(jī)TTL;
熱點(diǎn)數(shù)據(jù)如果是多級(jí)緩存,在發(fā)生修改時(shí)需要清除或修改各級(jí)緩存,這些操作往往不是原子操作,又會(huì)涉及各種不一致問(wèn)題。
除了通常意義上的緩存外,對(duì)象重用的池化技術(shù),也可以看作是一種緩存的變體。 常見(jiàn)的諸如JVM,V8這類運(yùn)行時(shí)的常量池、數(shù)據(jù)庫(kù)連接池、HTTP連接池、線程池、Golang的sync.Pool對(duì)象池等等。 在需要某個(gè)資源時(shí)從現(xiàn)有的池子里直接拿一個(gè),稍作修改或直接用于另外的用途,池化重用也是性能優(yōu)化常見(jiàn)手段。
壓縮術(shù)
說(shuō)完了兩個(gè)“空間換時(shí)間”的,我們?cè)倏匆粋€(gè)“時(shí)間換空間”的辦法——壓縮。 壓縮的原理消耗計(jì)算的時(shí)間,換一種更緊湊的編碼方式來(lái)表示數(shù)據(jù)。 為什么要拿時(shí)間換空間?時(shí)間不是最寶貴的資源嗎? 舉一個(gè)視頻網(wǎng)站的例子,如果不對(duì)視頻做任何壓縮編碼,因?yàn)閹捰邢蓿薮蟮臄?shù)據(jù)量在網(wǎng)絡(luò)傳輸?shù)暮臅r(shí)會(huì)比編碼壓縮的耗時(shí)多得多。 對(duì)數(shù)據(jù)的壓縮雖然消耗了時(shí)間來(lái)?yè)Q取更小的空間存儲(chǔ),但更小的存儲(chǔ)空間會(huì)在另一個(gè)維度帶來(lái)更大的時(shí)間收益。 這個(gè)例子本質(zhì)上是:“操作系統(tǒng)內(nèi)核與網(wǎng)絡(luò)設(shè)備處理負(fù)擔(dān) vs 壓縮解壓的CPU/GPU負(fù)擔(dān)”的權(quán)衡和取舍。 我們?cè)诖a中通常用的是無(wú)損壓縮,比如下面這些場(chǎng)景:
HTTP協(xié)議中Accept-Encoding添加Gzip/deflate,服務(wù)端對(duì)接受壓縮的文本(JS/CSS/HTML)請(qǐng)求做壓縮,大部分圖片格式本身已經(jīng)是壓縮的無(wú)需壓縮;
HTTP2協(xié)議的頭部HPACK壓縮;
JS/CSS文件的混淆和壓縮(Uglify/Minify);
一些RPC協(xié)議和消息隊(duì)列傳輸?shù)南⒅校捎枚M(jìn)制編碼和壓縮(Gzip、Snappy、LZ4等等);
緩存服務(wù)存過(guò)大的數(shù)據(jù),通常也會(huì)事先壓縮一下再存,取的時(shí)候解壓;
一些大文件的存儲(chǔ),或者不常用的歷史數(shù)據(jù)存儲(chǔ),采用更高壓縮比的算法存儲(chǔ);
JVM的對(duì)象指針壓縮,JVM在32G以下的堆內(nèi)存情況下默認(rèn)開(kāi)啟“UseCompressedOops”,用4個(gè)byte就可以表示一個(gè)對(duì)象的指針,這也是JVM盡量不要把堆內(nèi)存設(shè)置到32G以上的原因;
MongoDB的二進(jìn)制存儲(chǔ)的BSON相對(duì)于純文本的JSON也是一種壓縮,或者說(shuō)更緊湊的編碼。但更緊湊的編碼也意味著更差的可讀性,這一點(diǎn)也是需要取舍的。純文本的JSON比二進(jìn)制編碼要更占存儲(chǔ)空間但卻是REST API的主流,因?yàn)閿?shù)據(jù)交換的場(chǎng)景下的可讀性是非常重要的。
信息論告訴我們,無(wú)損壓縮的極限是信息熵。進(jìn)一步減小體積只能以損失部分信息為代價(jià),也就是有損壓縮。 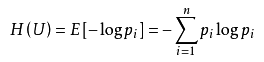 那么,有損壓縮有哪些應(yīng)用呢?
那么,有損壓縮有哪些應(yīng)用呢?
預(yù)覽和縮略圖,低速網(wǎng)絡(luò)下視頻降幀、降清晰度,都是對(duì)信息的有損壓縮;
音視頻等多媒體數(shù)據(jù)的采樣和編碼大多是有損的,比如MP3是利用傅里葉變換,有損地存儲(chǔ)音頻文件;jpeg等圖片編碼也是有損的。雖然有像WAV/PCM這類無(wú)損的音頻編碼方式,但多媒體數(shù)據(jù)的采樣本身就是有損的,相當(dāng)于只截取了真實(shí)世界的極小一部分?jǐn)?shù)據(jù);
散列化,比如K-V存儲(chǔ)時(shí)Key過(guò)長(zhǎng),先對(duì)Key執(zhí)行一次“傻”系列(SHA-1、SHA-256)哈希算法變成固定長(zhǎng)度的短Key。另外,散列化在文件和數(shù)據(jù)驗(yàn)證(MD5、CRC、HMAC)場(chǎng)景用的也非常多,無(wú)需耗費(fèi)大量算力對(duì)比完整的數(shù)據(jù)。
除了有損/無(wú)損壓縮,但還有一個(gè)辦法,就是壓縮的極端——從根本上減少數(shù)據(jù)或徹底刪除。 能減少的就減少:
JS打包過(guò)程“搖樹(shù)”,去掉沒(méi)有使用的文件、函數(shù)、變量;
開(kāi)啟HTTP/2和高版本的TLS,減少了Round Trip,節(jié)省了TCP連接,自帶大量性能優(yōu)化;
減少不必要的信息,比如Cookie的數(shù)量,去掉不必要的HTTP請(qǐng)求頭;
更新采用增量更新,比如HTTP的PATCH,只傳輸變化的屬性而不是整條數(shù)據(jù);
縮短單行日志的長(zhǎng)度、縮短URL、在具有可讀性情況下用短的屬性名等等;
使用位圖和位操作,用風(fēng)騷的位操作最小化存取的數(shù)據(jù)。典型的例子有:用Redis的位圖來(lái)記錄統(tǒng)計(jì)海量用戶登錄狀態(tài);布隆過(guò)濾器用位圖排除不可能存在的數(shù)據(jù);大量開(kāi)關(guān)型的設(shè)置的存儲(chǔ)等等。
能刪除的就刪除:
刪掉不用的數(shù)據(jù);
刪掉不用的索引;
刪掉不該打的日志;
刪掉不必要的通信代碼,不去發(fā)不必要的HTTP、RPC請(qǐng)求或調(diào)用,輪詢改發(fā)布訂閱;
終極方案:砍掉整個(gè)功能。
畢竟有位叫做 Kelsey Hightower 的大佬曾經(jīng)說(shuō)過(guò):
No code is the best way to write secure and reliable applications. Write nothing; deploy nowhere
不寫代碼,是編寫安全可靠的應(yīng)用程序的最佳方式。什么都不寫;哪里都不部署。
預(yù)取術(shù)
預(yù)取通常搭配緩存一起用,其原理是在緩存空間換時(shí)間基礎(chǔ)上更進(jìn)一步,再加上一次“時(shí)間換時(shí)間”,也就是:用事先預(yù)取的耗時(shí),換取第一次加載的時(shí)間。 當(dāng)可以猜測(cè)出以后的某個(gè)時(shí)間很有可能會(huì)用到某種數(shù)據(jù)時(shí),把數(shù)據(jù)預(yù)先取到需要用的地方,能大幅度提升用戶體驗(yàn)或服務(wù)端響應(yīng)速度。
是否用預(yù)取模式就像自助餐餐廳與廚師現(xiàn)做的區(qū)別,在自助餐餐廳可以直接拿做好的菜品,一般餐廳需要坐下來(lái)等菜品現(xiàn)做。 那么,預(yù)取在哪些實(shí)際場(chǎng)景會(huì)用呢?
視頻或直播類網(wǎng)站,在播放前先緩沖一小段時(shí)間,就是預(yù)取數(shù)據(jù)。有的在播放時(shí)不僅預(yù)取這一條數(shù)據(jù),甚至還會(huì)預(yù)測(cè)下一個(gè)要看的其他內(nèi)容,提前把數(shù)據(jù)取到本地;
HTTP/2 Server Push,在瀏覽器請(qǐng)求某個(gè)資源時(shí),服務(wù)器順帶把其他相關(guān)的資源一起推回去,HTML/JS/CSS幾乎同時(shí)到達(dá)瀏覽器端,相當(dāng)于瀏覽器被動(dòng)預(yù)取了資源;
一些客戶端軟件會(huì)用常駐進(jìn)程的形式,提前預(yù)取數(shù)據(jù)或執(zhí)行一些代碼,這樣可以極大提高第一次使用的打開(kāi)速度;
服務(wù)端同樣也會(huì)用一些預(yù)熱機(jī)制,一方面熱點(diǎn)數(shù)據(jù)預(yù)取到內(nèi)存提前形成多級(jí)緩存;另一方面也是對(duì)運(yùn)行環(huán)境的預(yù)熱,載入CPU高速緩存、熱點(diǎn)函數(shù)JIT編譯成機(jī)器碼等等;
熱點(diǎn)資源提前預(yù)分配到各個(gè)實(shí)例,比如:秒殺、售票的庫(kù)存性質(zhì)的數(shù)據(jù);分布式唯一ID等等
天上不會(huì)掉餡餅,預(yù)取也是有副作用的。 正如烤箱預(yù)熱需要消耗時(shí)間和額外的電費(fèi),在軟件代碼中做預(yù)取/預(yù)熱的副作用通常是啟動(dòng)慢一些、占用一些閑時(shí)的計(jì)算資源、可能取到的不一定是后面需要的。
削峰填谷術(shù)
削峰填谷的原理也是“時(shí)間換時(shí)間”,谷時(shí)換峰時(shí)。 削峰填谷與預(yù)取是反過(guò)來(lái)的:預(yù)取是事先花時(shí)間做,削峰填谷是事后花時(shí)間做。就像三峽大壩可以抗住短期巨量洪水,事后雨停再慢慢開(kāi)閘防水。軟件世界的“削峰填谷”是類似的,只是不是用三峽大壩實(shí)現(xiàn),而是用消息隊(duì)列、異步化等方式。 常見(jiàn)的有這幾類問(wèn)題,我們分別來(lái)看每種對(duì)應(yīng)的解決方案:
針對(duì)前端、客戶端的啟動(dòng)優(yōu)化或首屏優(yōu)化:代碼和數(shù)據(jù)等資源的延時(shí)加載、分批加載、后臺(tái)異步加載、或按需懶加載等等。
背壓控制 - 限流、節(jié)流、去抖等等。一夫當(dāng)關(guān),萬(wàn)夫莫開(kāi),從入口處削峰,防止一些惡意重復(fù)請(qǐng)求以及請(qǐng)求過(guò)于頻繁的爬蟲(chóng),甚至是一些DDoS攻擊。簡(jiǎn)單做法有網(wǎng)關(guān)層根據(jù)單個(gè)IP或用戶用漏桶控制請(qǐng)求速率和上限;前端做按鈕的節(jié)流去抖防止重復(fù)點(diǎn)擊;網(wǎng)絡(luò)層開(kāi)啟TCP SYN Cookie防止惡意的SYN洪水攻擊等等。徹底杜絕爬蟲(chóng)、黑客手段的惡意洪水攻擊是很難的,DDoS這類屬于網(wǎng)絡(luò)安全范疇了。
針對(duì)正常的業(yè)務(wù)請(qǐng)求洪峰,用消息隊(duì)列暫存再異步化處理:常見(jiàn)的后端消息隊(duì)列Kafka、RocketMQ甚至Redis等等都可以做緩沖層,第一層業(yè)務(wù)處理直接校驗(yàn)后丟到消息隊(duì)列中,在洪峰過(guò)去后慢慢消費(fèi)消息隊(duì)列中的消息,執(zhí)行具體的業(yè)務(wù)。另外執(zhí)行過(guò)程中的耗時(shí)和耗計(jì)算資源的操作,也可以丟到消息隊(duì)列或數(shù)據(jù)庫(kù)中,等到谷時(shí)處理。
捋平毛刺:有時(shí)候洪峰不一定來(lái)自外界,如果系統(tǒng)內(nèi)部大量定時(shí)任務(wù)在同一時(shí)間執(zhí)行,或與業(yè)務(wù)高峰期重合,很容易在監(jiān)控中看到“毛刺”——短時(shí)間負(fù)載極高。一般解決方案就是錯(cuò)峰執(zhí)行定時(shí)任務(wù),或者分配到其他非核心業(yè)務(wù)系統(tǒng)中,把“毛刺”攤平。比如很多數(shù)據(jù)分析型任務(wù)都放在業(yè)務(wù)低谷期去執(zhí)行,大量定時(shí)任務(wù)在創(chuàng)建時(shí)盡量加一些隨機(jī)性來(lái)分散執(zhí)行時(shí)間。
避免錯(cuò)誤風(fēng)暴帶來(lái)的次生洪峰:有時(shí)候網(wǎng)絡(luò)抖動(dòng)或短暫宕機(jī),業(yè)務(wù)會(huì)出現(xiàn)各種異常或錯(cuò)誤。這時(shí)處理不好很容易帶來(lái)次生災(zāi)害,比如:很多代碼都會(huì)做錯(cuò)誤重試,不加控制的大量重試甚至?xí)?dǎo)致網(wǎng)絡(luò)抖動(dòng)恢復(fù)后的瞬間,積壓的大量請(qǐng)求再次沖垮整個(gè)系統(tǒng);還有一些代碼沒(méi)有做超時(shí)、降級(jí)等處理,可能導(dǎo)致大量的等待耗盡TCP連接,進(jìn)而導(dǎo)致整個(gè)系統(tǒng)被沖垮。解決之道就是做限定次數(shù)、間隔指數(shù)級(jí)增長(zhǎng)的Back-Off重試,設(shè)定超時(shí)、降級(jí)策略。
批量處理術(shù)
批量處理同樣可以看成“時(shí)間換時(shí)間”,其原理是減少了重復(fù)的事情,是一種對(duì)執(zhí)行流程的壓縮。以個(gè)別批量操作更長(zhǎng)的耗時(shí)為代價(jià),在整體上換取了更多的時(shí)間。 批量處理的應(yīng)用也非常廣泛,我們還是從前端開(kāi)始講:
打包合并的JS文件、雪碧圖等等,將一批資源集中到一起,一次性傳輸;
前端動(dòng)畫使用requestAnimationFrame在UI渲染時(shí)批量處理積壓的變化,而不是有變化立刻更新,在游戲開(kāi)發(fā)中也有類似的應(yīng)用;
前后端中使用隊(duì)列暫存臨時(shí)產(chǎn)生的數(shù)據(jù),積壓到一定數(shù)量再批量處理;在不影響可擴(kuò)展性情況下,一個(gè)接口傳輸多種需要的數(shù)據(jù),減少大量ajax調(diào)用(GraphQL在這一點(diǎn)就做到了極致);
系統(tǒng)間通信盡量發(fā)送整批數(shù)據(jù),比如消息隊(duì)列的發(fā)布訂閱、存取緩存服務(wù)的數(shù)據(jù)、RPC調(diào)用、插入或更新數(shù)據(jù)庫(kù)等等,能批量做盡可能批量做,因?yàn)檫@些系統(tǒng)間通信的I/O時(shí)間開(kāi)銷已經(jīng)很昂貴了;
數(shù)據(jù)積壓到一定程度再落盤,操作系統(tǒng)本身的寫文件就是這么做的,Linux的fwrite只是寫入緩沖區(qū)暫存,積壓到一定程度再fsync刷盤。在應(yīng)用層,很多高性能的數(shù)據(jù)庫(kù)和K-V存儲(chǔ)的實(shí)現(xiàn)都體現(xiàn)了這一點(diǎn):一些NoSQL的LSM Tree的第一層就是在內(nèi)存中先積壓到一定大小再往下層合并;Redis的RDB結(jié)合AOF的落盤機(jī)制;Linux系統(tǒng)調(diào)用也提供了批量讀寫多個(gè)緩沖區(qū)文件的系統(tǒng)調(diào)用:readv/writev;
延遲地批量回收資源,比如JVM的Survivor Space的S0和S1區(qū)互換、Redis的Key過(guò)期的清除策略。
批量處理如此好用,那么問(wèn)題來(lái)了,每一批放多大最合適呢? 這個(gè)問(wèn)題其實(shí)沒(méi)有定論,有一些個(gè)人經(jīng)驗(yàn)可以分享。
前端把所有文件打包成單個(gè)JS,大部分時(shí)候并不是最優(yōu)解。Webpack提供了很多分塊的機(jī)制,CSS和JS分開(kāi)、JS按業(yè)務(wù)分更小的Chunk結(jié)合懶加載、一些體積大又不用在首屏用的第三方庫(kù)設(shè)置external或單獨(dú)分塊,可能整體性能更高。不一定要一批搞定所有事情,分幾個(gè)小批次反而用戶體驗(yàn)的性能更好。
Redis的MGET、MSET來(lái)批量存取數(shù)據(jù)時(shí),每批大小不宜過(guò)大,因?yàn)镽edis主線程只有一個(gè),如果一批太大執(zhí)行期間會(huì)讓其他命令無(wú)法響應(yīng)。經(jīng)驗(yàn)上一批50-100個(gè)Key性能是不錯(cuò)的,但最好在真實(shí)環(huán)境下用真實(shí)大小的數(shù)據(jù)量化度量一下,做Benchmark測(cè)試才能確定一批大小的最優(yōu)值。
MySQL、Oracle這類RDBMS,最優(yōu)的批量Insert的大小也視數(shù)據(jù)行的特性而定。我之前在2U8G的Oracle上用一些普遍的業(yè)務(wù)數(shù)據(jù)做過(guò)測(cè)試,批量插入時(shí)每批5000-10000條數(shù)據(jù)性能是最高的,每批過(guò)大會(huì)導(dǎo)致DML的解析耗時(shí)過(guò)長(zhǎng),甚至單個(gè)SQL語(yǔ)句體積超限,單批太多反而得不償失。
消息隊(duì)列的發(fā)布訂閱,每批的消息長(zhǎng)度盡量控制在1MB以內(nèi),有些云服務(wù)商提供的消息隊(duì)列限制了最大長(zhǎng)度,那這個(gè)長(zhǎng)度可能就是性能拐點(diǎn),比如AWS的SQS服務(wù)對(duì)單條消息的限制是256KB。
總之,多大一批可以確保單批響應(yīng)時(shí)間不太長(zhǎng)的同時(shí)讓整體性能最高,是需要在實(shí)際情況下做基準(zhǔn)測(cè)試的,不能一概而論。而批量處理的副作用在于:處理邏輯會(huì)更加復(fù)雜,尤其是一些涉及事務(wù)、并發(fā)的問(wèn)題;需要用數(shù)組或隊(duì)列用來(lái)存放緩沖一批數(shù)據(jù),消耗了額外的存儲(chǔ)空間。
作者:code2life 在此特別鳴謝!
-
數(shù)據(jù)庫(kù)
+關(guān)注
關(guān)注
7文章
3841瀏覽量
64545 -
軟件設(shè)計(jì)
+關(guān)注
關(guān)注
3文章
58瀏覽量
17788 -
Oracle
+關(guān)注
關(guān)注
2文章
296瀏覽量
35159 -
MySQL
+關(guān)注
關(guān)注
1文章
821瀏覽量
26651
原文標(biāo)題:性能優(yōu)化的十種手段(取與舍)
文章出處:【微信號(hào):架構(gòu)師技術(shù)聯(lián)盟,微信公眾號(hào):架構(gòu)師技術(shù)聯(lián)盟】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
HarmonyOS NEXT應(yīng)用開(kāi)發(fā)性能優(yōu)化入門引導(dǎo)
HarmonyOS Web開(kāi)發(fā)性能優(yōu)化指導(dǎo)
人生要學(xué)會(huì)舍取,才能活的快樂(lè)
請(qǐng)問(wèn)怎么做一個(gè)跑馬燈有十種模式,第十種模式有三種音樂(lè),可加速減速和無(wú)線遙控?
高速DSP系統(tǒng)中的軟件設(shè)計(jì)優(yōu)化
ARM嵌入式系統(tǒng)開(kāi)發(fā)-軟件設(shè)計(jì)與優(yōu)化

ARM嵌入式系統(tǒng)開(kāi)發(fā)軟件設(shè)計(jì)與優(yōu)化 電子書下載

ARM嵌入式系統(tǒng)開(kāi)發(fā)_軟件設(shè)計(jì)與優(yōu)化_part2
基于UML對(duì)象建模的財(cái)務(wù)軟件設(shè)計(jì)研究
十種不同模式實(shí)現(xiàn)簡(jiǎn)單的計(jì)算案例





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論