 基于分割后門訓練過程的后門防御方法
基于分割后門訓練過程的后門防御方法
香港中文大學(深圳)吳保元教授課題組和浙江大學秦湛教授課題組聯合發表了一篇后門防御領域的文章,已順利被ICLR2022接收。近年來,后門問題受到人們的廣泛關注。隨著后門攻擊的不斷提出,提出針對一般化后門攻擊的防御方法變得愈加困難。該論文提出了一個基于分割后門訓練過程的后門防御方法。本文揭示了后門攻擊就是一個將后門投影到特征空間的端到端監督訓練方法。在此基礎上,本文分割訓練過程來避免后門攻擊。該方法與其他后門防御方法進行了對比實驗,證明了該方法的有效性。
1 背景介紹
后門攻擊的目標是通過修改訓練數據或者控制訓練過程等方法使得模型預測正確干凈樣本,但是對于帶有后門的樣本判斷為目標標簽。例如,后門攻擊者給圖片增加固定位置的白塊(即中毒圖片)并且修改圖片的標簽為目標標簽。用這些中毒數據訓練模型過后,模型就會判斷帶有特定白塊的圖片為目標標簽(如下圖所示)。

基本的后門攻擊
模型建立了觸發器(trigger)和目標標簽(target label)之間的關系。
2 相關工作
2.1 后門攻擊
現有的后門攻擊方法按照中毒圖片的標簽修改情況分為以下兩類,修改中毒圖片標簽的投毒標簽攻擊(Poison-Label Backdoor Attack),維持中毒圖片原本標簽的干凈標簽攻擊(Clean-Label Backdoor Attack)。
投毒標簽攻擊: BadNets (Gu et al., 2019)是第一個也是最具代表性的投毒標簽攻擊。之后(Chen et al., 2017)提出中毒圖片的隱身性應與其良性版本相似,并在此基礎上提出了混合攻擊(blended attack)。最近,(Xue et al., 2020; Li et al., 2020; 2021)進一步探索了如何更隱蔽地進行中毒標簽后門攻擊。最近,一種更隱形和有效的攻擊,WaNet (Nguyen & Tran, 2021年)被提出。WaNet采用圖像扭曲作為后門觸發器,在變形的同時保留了圖像內容。
干凈標簽攻擊: 為了解決用戶可以通過檢查圖像-標簽關系來注意到后門攻擊的問題,Turner等人(2019)提出了干凈標簽攻擊范式,其中目標標簽與中毒樣本的原始標簽一致。在(Zhao et al,2020b)中將這一思想推廣到攻擊視頻分類中,他們采用了目標通用對抗擾動(Moosavi-Dezfooli et al., 2017)作為觸發。盡管干凈標簽后門攻擊比投毒標簽后門攻擊更隱蔽,但它們的性能通常相對較差,甚至可能無法創建后門(Li et al., 2020c)。
2.2 后門防御
現有的后門防御大多是經驗性的,可分為五大類,包括
基于探測的防御(Xu et al,2021;Zeng et al,2011;Xiang et al,2022)檢查可疑的模型或樣本是否受到攻擊,它將拒絕使用惡意對象。
基于預處理的防御(Doan et al,2020;Li et al,2021;Zeng et al,2021)旨在破壞攻擊樣本中包含的觸發模式,通過在將圖像輸入模型之前引入預處理模塊來防止后門激活。
基于模型重構的防御(Zhao et al,2020a;Li et al,2021;)是通過直接修改模型來消除模型中隱藏的后門。
觸發綜合防御(Guo et al,2020;Dong et al,2021;Shen et al,2021)是首先學習后門,其次通過抑制其影響來消除隱藏的后門。
基于中毒抑制的防御(Du et al,2020;Borgnia et al,2021)在訓練過程中降低中毒樣本的有效性,以防止隱藏后門的產生
2.3 半監督學習和自監督學習
半監督學習:在許多現實世界的應用程序中,標記數據的獲取通常依賴于手動標記,這是非常昂貴的。相比之下,獲得未標記的樣本要容易得多。為了同時利用未標記樣本和標記樣本的力量,提出了大量的半監督學習方法(Gao et al.,2017;Berthelot et al,2019;Van Engelen & Hoos,2020)。最近,半監督學習也被用于提高模型的安全性(Stanforth et al,2019;Carmon et al,2019),他們在對抗訓練中使用了未標記的樣本。最近,(Yan et al,2021)討論了如何后門半監督學習。然而,該方法除了修改訓練樣本外,還需要控制其他訓練成分(如訓練損失)。
自監督學習:自監督學習范式是無監督學習的一個子集,模型使用數據本身產生的信號進行訓練(Chen et al,2020a;Grill et al,2020;Liu et al,2021)。它被用于增加對抗魯棒性(Hendrycks et al,2019;Wu et al,2021;Shi et al,2021)。最近,一些文章(Saha et al,2021;Carlini & Terzis, 2021;Jia et al,2021)探索如何向自監督學習投入后門。然而,這些攻擊除了修改訓練樣本外,它們還需要控制其他訓練成分(例如,訓練損失)。
3 后門特征
我們對CIFAR-10數據集(Krizhevsky, 2009)進行了BadNets和干凈標簽攻擊。對有毒數據集進行監督學習以及對未標記數據集進行自監督學習SimCLR(Chen et al., 2020a)。
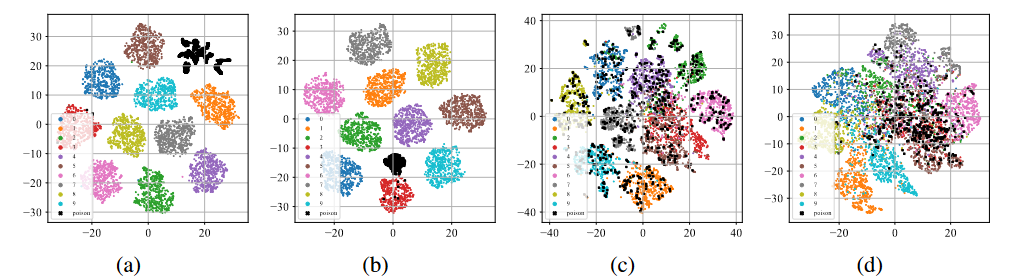
后門特征的t-sne展示
如上圖(a)-(b)所示,在經過標準監督訓練過程后,無論在投毒標簽攻擊還是干凈標簽攻擊下,中毒樣本(用黑點表示)都傾向于聚在一起形成單獨的聚類。這種現象暗示了現有的基于投毒的后門攻擊成功原因。過度的學習能力允許模型學習后門觸發器的特征。與端到端監督訓練范式相結合,模型可以縮小特征空間中中毒樣本之間的距離,并將學習到的觸發器相關特征與目標標簽連接起來。相反,如上圖(c)-(d)所示,在未標記的中毒數據集上,經過自監督訓練過程后,中毒樣本與帶有原有標簽的樣本非常接近。這表明我們可以通過自監督學習來防止后門的產生。
4 基于分割的后門防御
基于后門特征的分析,我們提出分割訓練階段的后門防御。如下圖所示,它包括三個主要階段,(1)通過自監督學習學習一個純化的特征提取器,(2)通過標簽噪聲學習過濾高可信樣本,(3)半監督微調。
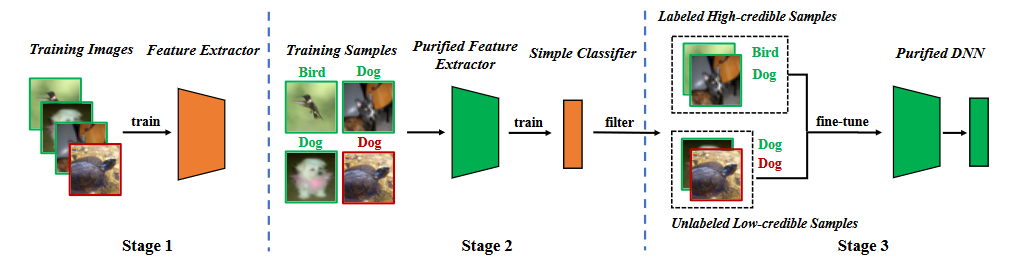
方法流程圖
4.1 學習特征提取器
我們用訓練數據集 去學習模型。模型的參數 包含兩部分,一部分是骨干模型(backbone model)的參數另一部分是全連接層(fully connected layer)的參數。我們利用自監督學習優化骨干模型的參數
其中是自監督損失(例如,NT-Xent在SimCLR (Chen et al,2020)). 通過前面的分析,我們可以知道特征提取器很難學習到后門特征。
4.2 標簽噪聲學習過濾樣本
一旦特征提取器被訓練好后,我們固定特征提取器的參數并用訓練數據集進一步學習全連接層參數,
其中是監督學習損失(例如,交叉熵損失(cross entropy))。
雖然這樣的分割流程會使得模型很難學到后門,但是它存在兩個問題。首先,與通過監督學習訓練的方法相比,由于學習到的特征提取器在第二階段被凍結,預測干凈樣本的準確率會有一定的下降。其次,當中毒標簽攻擊出現時,中毒樣本將作為“離群值”,進一步阻礙第二階段的學習。這兩個問題表明我們需要去除中毒樣本,并對整個模型進行再訓練或微調。
我們需要判斷樣本是否帶有后門。我們認為模型對于后門樣本難以學習,因此采用置信度作為區分指標,高置信度的樣本為干凈樣本,而低置信度的樣本為中毒樣本。通過實驗發現,利用對稱交叉熵損失訓練的模型對于兩種樣本的損失差距較大,從而區分度較高,如下圖所示。
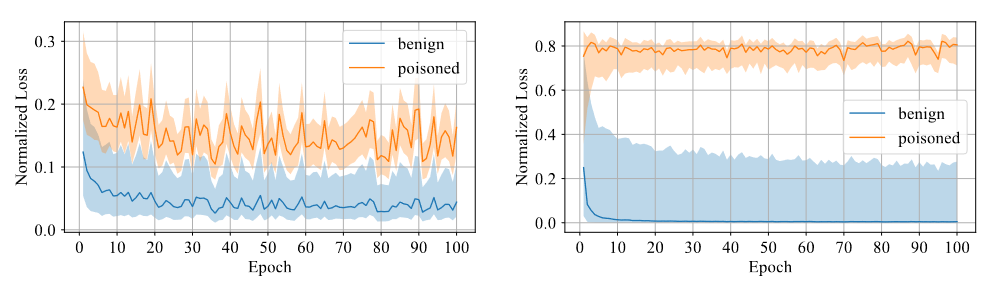
對稱交叉熵損失和交叉熵損失對比
因此,我們固定特征提取器利用對稱交叉熵損失訓練全連接層,并且通過置信度的大小篩選數據集為高置信度數據和低置信度數據。
4.3 半監督微調
首先,我們刪除低置信度數據的標簽 。我們利用半監督學習微調整個模型 。
其中是半監督損失(例如,在MixMatch(Berthelot et al,2019)中的損失函數)。
半監督微調既可以避免模型學習到后門觸發器,又可以使得模型在干凈數據集上表現良好。
5 實驗
5.1 數據集和基準
文章在兩個經典基準數據集上評估所有防御,包括CIFAR-10 (Krizhevsky, 2009)和ImageNet (Deng等人,2009)(一個子集)。文章采用ResNet18模型 (He et al., 2016)
文章研究了防御四種典型攻擊的所有防御方法,即badnets(Gu et al,2019)、混合策略的后門攻擊(blended)(Chen et al,2017)、WaNet (Nguyen & Tran, 2021)和帶有對敵擾動的干凈標簽攻擊(label-consistent)(Turner et al,2019)。

后門攻擊示例圖片
5.2 實驗結果
實驗的判斷標準為BA是干凈樣本的判斷準確率和ASR是中毒樣本的判斷準確率。
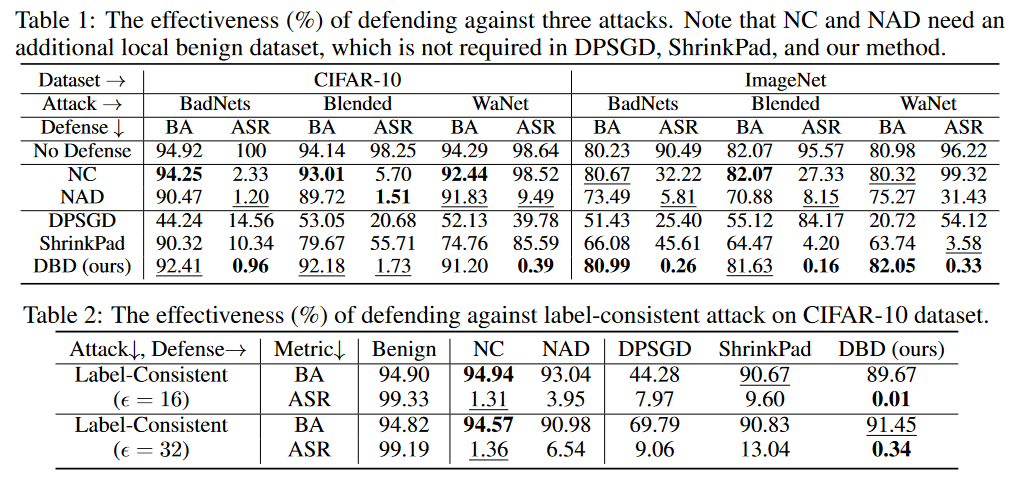
后門防御對比結果
如上表所示,DBD在防御所有攻擊方面明顯優于具有相同要求的防御(即DPSGD和ShrinkPad)。在所有情況下,DBD比DPSGD的BA超過20%,而ASR低5%。DBD模型的ASR在所有情況下都小于2%(大多數情況下低于0.5%),驗證了DBD可以成功地防止隱藏后門的創建。DBD與另外兩種方法(即NC和NAD)進行比較,這兩種方法都要求防御者擁有一個干凈的本地數據集。如上表所示,NC和NAD優于DPSGD和ShrinkPad,因為它們采用了來自本地的干凈數據集的額外信息。特別是,盡管NAD和NC使用了額外的信息,但DBD比它們更好。特別是在ImageNet數據集上,NC對ASR的降低效果有限。相比之下,DBD達到最小的ASR,而DBD的BA在幾乎所有情況下都是最高或第二高。此外,與未經任何防御訓練的模型相比,防御中毒標簽攻擊時的BA下降不到2%。在相對較大的數據集上,DBD甚至更好,因為所有的基線方法都變得不那么有效。這些結果驗證了DBD的有效性。
5.3 消融實驗
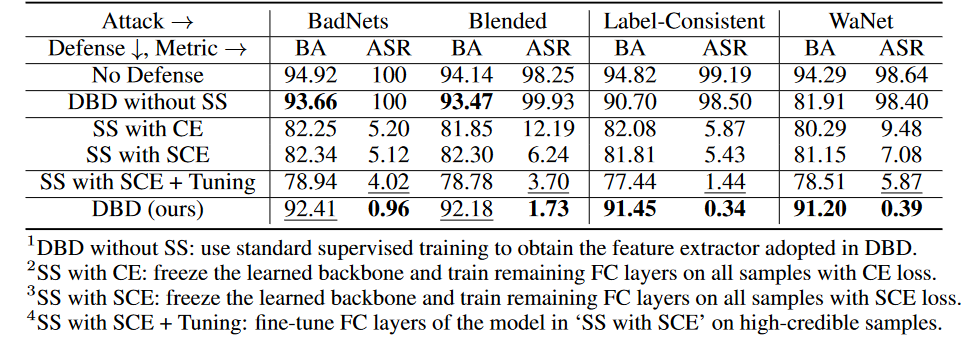
各階段消融實驗
在CIFAR-10數據集上,我們比較了提出的DBD及其四個變體,包括
DBD不帶SS,將由自監督學習生成的骨干替換為以監督方式訓練的主干,并保持其他部分不變
SS帶CE,凍結了通過自監督學習學習到的骨干,并在所有訓練樣本上訓練剩下的全連接層的交叉熵損失
SS帶SCE, 與第二種變體類似,但使用了對稱交叉熵損失訓練。
SS帶SCE + Tuning,進一步微調由第三個變體過濾的高置信度樣本上的全連接層。
如上表所示,解耦原始的端到端監督訓練過程在防止隱藏后門的創建方面是有效的。此外,比較第二個和第三個DBD變體來驗證SCE損失對防御毒藥標簽后門攻擊的有效性。另外,第4個DBD變異的ASR和BA相對于第3個DBD變異要低一些。這一現象是由于低可信度樣本的去除。這表明,在采用低可信度樣本的有用信息的同時減少其副作用對防御很重要。
5.4 對于潛在的自適應性攻擊的抵抗
如果攻擊者知道DBD的存在,他們可能會設計自適應性攻擊。如果攻擊者能夠知道防御者使用的模型結構,他們可以通過優化觸發模式,在自監督學習后,使中毒樣本仍然在一個新的集群中,從而設計自適應性攻擊,如下所示:
攻擊設定
對于一個-分類問題,讓代表那些需要被投毒的干凈樣本,代表原標簽為的樣本,以及是一個被訓練的骨干。給定攻擊者預定的中毒圖像生成器,自適應性攻擊旨在優化觸發模式,通過最小化有毒圖像之間的距離,同時最大化有毒圖像的中心與具有不同標簽的良性圖像集群的中心之間的距離,即。
其中,是一個距離判定。
實驗結果
自適應性攻擊在沒有防御的情況下的BA為94.96%,和ASR為99.70%。然而,DBD的防御結果為BA93.21%以及ASR1.02%。換句話說,DBD是抵抗這種自適應性攻擊的。
6 總結
基于投毒的后門攻擊的機制是在訓練過程中在觸發模式和目標標簽之間建立一種潛在的連接。本文揭示了這種連接主要是由于端到端監督訓練范式學習。基于這種認識,本文提出了一種基于解耦的后門防御方法。大量的實驗驗證了DBD防御在減少后門威脅的同時保持了預測良性樣本的高精度。
審核編輯:郭婷
-
觸發器
+關注
關注
14文章
2002瀏覽量
61273
原文標題:ICLR 2022 | DBD:基于分割后門訓練過程的后門防御方法
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
GPU是如何訓練AI大模型的
FP8模型訓練中Debug優化思路
AI訓練的基本步驟
脈沖神經網絡怎么訓練
機器學習中的數據分割方法
BP神經網絡的基本結構和訓練過程





 工商網監
工商網監
評論