 為千億參數模型量身定制,最高可實現60%的稀疏化水平
為千億參數模型量身定制,最高可實現60%的稀疏化水平
為千億參數模型量身定制,最高可實現 60% 的稀疏化水平。
自 2020 年 GPT-3 橫空出世以來,ChatGPT 的爆火再一次將 GPT 家族的生成式大型語言模型帶到聚光燈下,它們在各種任務中都已顯示出了強大的性能。
但模型的龐大規模也帶來了計算成本的上升和部署難度的增加。
比如,GPT?175B 模型總計至少占 320GB 半精度 (FP16) 格式的存儲空間,在推理時,起碼需要五個 80 GB 存儲空間的 A100 GPU。
模型壓縮(model compression)是當前使用較多的一種降低大模型計算成本的方法,但迄今為止,幾乎所有現有的 GPT 壓縮方法都專注于量化(quantization),即降低單個權重的數值表示的精度。
另一種模型壓縮方法是剪枝(pruning),即刪除網絡元素,包括從單個權重(非結構化剪枝)到更高粒度的組件如權重矩陣的整行/列(結構化剪枝)。這種方法在視覺和較小規模的語言模型中很有效,但會導致精度損失,從而需要對模型進行大量再訓練來恢復精度,所以遇到 GPT 這樣大規模的模型時,成本就又變得過于昂貴了。雖然也有一些單次剪枝方法,無需重新訓練即可壓縮模型,但它們計算量太大,難以應用于具有數十億參數的模型。
那么針對 GPT-3 這種規模的大模型,有沒有一種方法能夠對其作精確的剪枝、同時保持最小的精度損失且降低計算成本?
近日,來自奧地利科學技術研究所 (ISTA) 的兩名研究人員 Elias Frantar 和 Dan Alistarh 合作了一項研究,首次針對 100 至 1000 億參數的模型規模,提出了精確的單次剪枝方法 SparseGPT。

論文地址:https://arxiv.org/pdf/2301.00774.pdf
SparseGPT 可以將 GPT 系列模型單次剪枝到 50% 的稀疏性,而無需任何重新訓練。目前最大的公開可用的 GPT-175B 模型,只需要使用單個 GPU 在幾個小時內就能實現這種剪枝。
而且,SparseGPT 還很準確,能將精度損失降到最小。比如在目前最大的開源模型 OPT?175B 和 BLOOM?176B 上執行SparseGPT 時,可以達到 60% 的稀疏度,同時將精度損失降到最小。
超大模型的研究近幾年非常活躍,但到目前為止,還沒有一個百億參數以上的模型能夠實現非常準確的高度稀疏化。
現有方法對計算成本的要求都過高,以目前最準確的訓練后方法 OBC 為例,對于十億參數模型,它需要 1 個小時以上的時間來進行壓縮。已知最快的訓練后方法 AdaPrune 也需要幾分鐘來對十億參數模型進行剪枝,按此速度,GPT-3 規模的模型估計需要數百小時(幾周)的計算。
大多數現有的剪枝方法如漸進幅度剪枝(gradual magnitude pruning),需要在剪枝步驟后進行大量的再訓練以恢復準確性,而 GPT 規模的模型通常需要大量的用于訓練或微調的計算量和參數調整量,這使得基于再訓練的方法難以應用。因此,在 GPT 規模上應用這種漸進的剪枝方法是行不通的。
ISTA 團隊的這項工作提出了 SparseGPT 方法,可以實現幾個小時內在單個 GPU 上運行千億以上參數的模型,并且足夠準確,可將模型修剪到 50%-60% 的稀疏度水平,而不會大幅度降低性能。
SparseGPT 的核心是一種新的大規模近似稀疏回歸算法,它可以推廣到半結構化(2:4 和 4:8)模式,并且與現有的權重量化方法兼容。
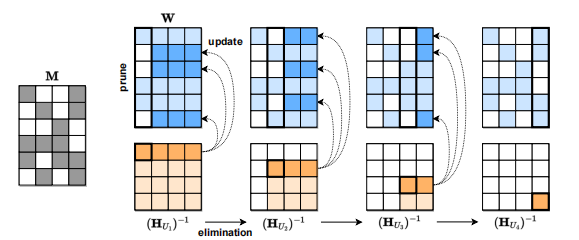
圖注:SparseGPT 重建算法的可視化。給定一個固定的剪枝掩碼 M,使用 Hessian 逆序列(HUj )并更新這些行中位于列“右側”的剩余權重,逐步修剪權重矩陣 W 的每一列中的權重處理。具體來說,修剪后權重(深藍?)“右側”的權重將被更新以補償修剪錯誤,而未修剪的權重不會生成更新(淺藍?)。
大多數現有的剪枝方法如漸進幅度剪枝(gradual magnitude pruning),需要在剪枝步驟后進行大量的再訓練以恢復準確性,而 GPT 規模的模型通常需要大量的用于訓練或微調的計算量和參數調整量,這使得基于再訓練的方法難以應用。因此,在 GPT 規模上應用這種漸進的剪枝方法是行不通的。
SparseGPT 是針對 GPT 規模模型的后訓練(post-training)方法,因為它不執行任何微調。
目前有許多量化 GPT 規模模型的后訓練的方法,如 ZeroQuant、LLM.int8() 和 nuQmm 等,但由于異常特征的存在,激活量化可能會很困難。GPTQ 利用近似二階信息將權重精確量化到 2?4 位,適用于最大的模型,而且當它與高效的 GPU 內核相結合時,可以帶來2?5 倍的推理加速。
但由于 GPTQ 側重于稀疏化而不是量化,因此 SparseGPT是對量化方法的補充,二者可以結合應用。
另外,除了非結構化修剪,SparseGPT 也適用于半結構化的模式,比如流行的 n:m 稀疏格式,在 Ampere NVIDIA GPU 上可以 2:4 的比例實現加速。
對 SparseGPT 壓縮模型的效果進行評估后,研究人員發現,大型語言模型進行稀疏化的難度與模型大小成比例,與已有的幅度剪枝(Magnitude Pruning)方法相比,使用 SparseGPT 能夠實現更高的模型稀疏化程度,同時保持最低限度的精度損失。
研究人員在 PyTorch 上中實現了 SparseGPT,并使用 HuggingFace 的 Transformers 庫來處理模型和數據集,并且都在具有 80GB 內存的單個 NVIDIA A100 GPU 上進行。在這樣的實驗條件下,SparseGPT 可以在大約 4 小時內對 1750 億參數的模型實現完全稀疏化。
研究人員按順序依次稀疏 Transformer 層,這顯著降低了內存需求,并且還大大提高了并行處理所有層的準確性。所有的壓縮實驗都是一次性進行,沒有任何微調。
評估對象主要是 OPT 系列模型,包含從 1.25 億到 1750 億參數的一套模型,方便觀察剪枝相對于模型大小的縮放表現。此外還分析了 BLOOM 的 1760 億參數變體。
在數據集和評估指標方面,實驗采用了原始 WikiText2 測試集的困惑度來評估 SparseGPT 壓縮方法的準確性,同時為了增加可解釋性,還使用了一些 ZeroShot 精度指標。另外,評估的重點在于稀疏模型相對于密集模型基線的準確性,而非絕對數字。
研究人員對 OPT 整個模型系列的所有線性層進行剪枝(不包括標準的嵌入和頭部),分別達到 50% 的非結構化稀疏度、全 4:8 或全 2:4 的半結構化稀疏度,結果如下圖。
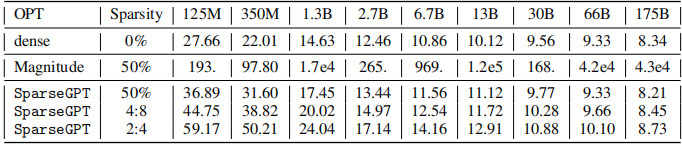
圖注:OPT 模型家族在原始 WikiText2 測試集的困惑度
可見,使用幅度剪枝來壓縮的模型準確性在所有尺寸上都很糟糕,而且模型越大,準確度下降得越厲害。
而使用 SparseGPT 來壓縮的模型趨勢不同,在 27 億參數下,困惑度損失 < 1 point,在 660 億參數下則是零損失。而且,與密集模型的基線相比,在模型規模非常大的情況下精度甚至還有所提高。
一個總的趨勢是,較大的模型更容易稀疏化,在固定的稀疏度水平下,稀疏模型相對于密集模型的相對精度下降會隨著模型大小的增加而縮小。作者推測這可能是由于它們的參數化程度更高,總體上抗噪能力也更強。
相比于密集模型基線,在最大規模下,使用 SparseGPT 將模型壓縮至 4:8 和 2:4 稀疏度時,困惑度增長分別僅為 0.11 和 0.39。這樣的結果意味著,我們可以在實踐中實現 2 倍的加速,商用的 NVIDIA Ampere GPU 對 2:4 的稀疏度已經有了支持。
作者研究了 OPT-175B 和 BLOOM-176B 兩個千億模型的性能與使用 SparseGPT 帶來的稀疏程度之間的關系,結果下圖所示。
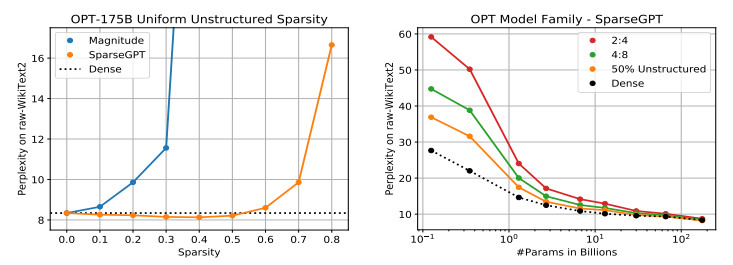
圖注:左圖為分別使用 SparseGPT 和幅度剪枝將 OPT-175B 統一壓縮至不同稀疏水平。右圖為使用 SparseGPT 將整個 OPT 模型系列壓縮至不同的稀疏水平。
可以看到,對于 OPT-175B 模型,幅度剪枝最多可以實現 10% 的稀疏度,緊接著就會有較大的精度損失。而 SparseGPT 在困惑度增加的下還能實現 60% 的稀疏度。
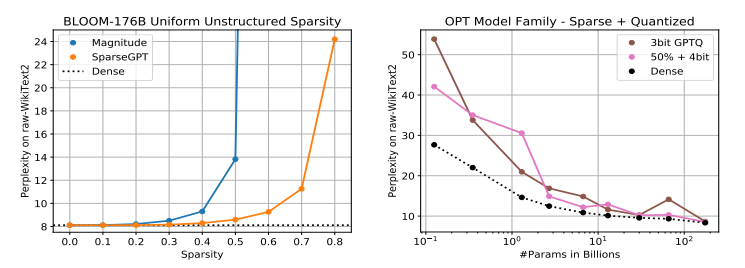
圖注:左圖為分別使用 SparseGPT 和幅度剪枝將 BLOOM-176B 統一壓縮至不同稀疏水平。右圖為在 OPT 家族模型上 50% 稀疏度 + 4 bit 量化聯合壓縮 與 3-bit 的對比。
對于 BLOOM-176B 模型,盡管幅度剪枝可以達到 30% 的稀疏度而沒有顯著的精度損失,但相比之下,SparseGPT 可以實現 50% 的稀疏度,即 1.66 倍的提升。而且,在 80% 的稀疏度下,使用 SparseGPT 壓縮的模型的困惑度仍然保持在合理水平,但幅度剪枝在達到 OPT 的 40% 稀疏度和 BLOOM 的 60% 稀疏度時,困惑度就已經 > 100。
另外,SparseGPT 能夠從這些模型中移除大約 1000 億個權重,對模型準確性的影響有限。
最后總結一下,該研究首次表明,基于 Transformer 的大規模預訓練模型可以通過一次性權重修剪壓縮到高稀疏性,無需任何再訓練,精度損失也很低。
值得注意的是,SparseGPT 的方法是局部的:在每個修剪步驟之后,它都會執行權重更新,旨在保留每一層的輸入輸出關系,這些更新是在沒有任何全局梯度信息的情況下計算的。因此,大規模 GPT 模型的高度參數化似乎使這種方法能夠直接識別密集預訓練模型“近鄰”中的稀疏精確模型。
另外,由于實驗所采用的的準確度指標(困惑度)非常敏感,因此生成的稀疏模型輸出似乎與密集模型的輸出密切相關。
這項研究在緩解大模型的算力限制方面具有很大的積極意義,將來的一個工作方向是研究大模型的微調機制來進一步恢復精度,同時,擴大 SparseGPT 的方法在模型訓練期間的適用性,將會減少訓練大模型的計算成本。
審核編輯 :李倩
-
算法
+關注
關注
23文章
4626瀏覽量
93151 -
模型
+關注
關注
1文章
3286瀏覽量
49006 -
數據集
+關注
關注
4文章
1209瀏覽量
24767
原文標題:首個千億模型壓縮算法 SparseGPT 來了,降低算力成本的同時保持高精度
文章出處:【微信號:AI智勝未來,微信公眾號:AI智勝未來】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AI模型部署邊緣設備的奇妙之旅:目標檢測模型
階躍星辰發布國內首個千億參數端到端語音大模型
SOLIDWORKS參數化軟件可實現的功能
可靈AI全球首發視頻模型定制功能,助力AI視頻創作
Al大模型機器人
昆侖萬維開源2千億稀疏大模型Skywork-MoE
快手自研文生圖大模型“可圖”開放,支持AI圖像創作及定制
通義千問開源千億級參數模型
阿里云通義千問發布320億參數模型,優化性能及效率
KIMI與海內外主流模型對比及應用方向
愛星物聯開源IoT平臺助力企業構建安全可定制化的IoT解決方案
百川智能發布超千億大模型Baichuan 3
小紅書搜索團隊研究新框架:負樣本在大模型蒸餾中的重要性
Microchip發布PIC16F13145系列MCU,促進可定制邏輯的新發展






 工商網監
工商網監
評論