") 阿里達(dá)摩院提出ABPN:高清人像美膚模型
阿里達(dá)摩院提出ABPN:高清人像美膚模型
一、論文&代碼
論文:
https://openaccess.thecvf.com/content/CVPR2022/papers/Lei_ABPN_Adaptive_Blend_Pyramid_Network_for_Real-Time_Local_Retouching_of_CVPR_2022_paper.pdf
模型&代碼:
https://www.modelscope.cn/models/damo/cv_unet_skin-retouching/summary
二、背景
隨著數(shù)字文化產(chǎn)業(yè)的蓬勃發(fā)展,人工智能技術(shù)開始廣泛應(yīng)用于圖像編輯和美化領(lǐng)域。其中,人像美膚無疑是應(yīng)用最廣、需求最大的技術(shù)之一。傳統(tǒng)美顏算法利用基于濾波的圖像編輯技術(shù),實(shí)現(xiàn)了自動(dòng)化的磨皮去瑕疵效果,在社交、直播等場(chǎng)景取得了廣泛的應(yīng)用。然而,在門檻較高的專業(yè)攝影行業(yè),由于對(duì)圖像分辨率以及質(zhì)量標(biāo)準(zhǔn)的較高要求,人工修圖師還是作為人像美膚修圖的主要生產(chǎn)力,完成包括勻膚、去瑕疵、美白等一系列工作。通常,一位專業(yè)修圖師對(duì)一張高清人像進(jìn)行美膚操作的平均處理時(shí)間為1-2分鐘,在精度要求更高的廣告、影視等領(lǐng)域,該處理時(shí)間則更長(zhǎng)。
相較于互娛場(chǎng)景的磨皮美顏,廣告級(jí)、影樓級(jí)的精細(xì)化美膚給算法帶來了更高的要求與挑戰(zhàn)。一方面,瑕疵種類眾多,包含痘痘、痘印、雀斑、膚色不均等,算法需要對(duì)不同瑕疵進(jìn)行自適應(yīng)地處理;另一方面,在去除瑕疵的過程中,需要盡可能的保留皮膚的紋理、質(zhì)感,實(shí)現(xiàn)高精度的皮膚修飾;最后也是十分重要的一點(diǎn),隨著攝影設(shè)備的不斷迭代,專業(yè)攝影領(lǐng)域目前常用的圖像分辨率已經(jīng)達(dá)到了4K甚至8K,這對(duì)算法的處理效率提出了極其嚴(yán)苛的要求。為此,我們以實(shí)現(xiàn)專業(yè)級(jí)的智能美膚為出發(fā)點(diǎn),研發(fā)了一套高清圖像的超精細(xì)局部修圖算法ABPN,在超清圖像中的美膚與服飾去皺任務(wù)中都實(shí)現(xiàn)了很好的效果與應(yīng)用。
三、相關(guān)工作
3.1 傳統(tǒng)美顏算法
傳統(tǒng)美顏算法的核心就是讓皮膚區(qū)域的像素變得更平滑,降低瑕疵的顯著程度,從而使皮膚看起來更加光滑。一般來說,現(xiàn)有的美顏算法可劃分為三步:1)圖像濾波算法,2)圖像融合,3)銳化。整體流程如下:
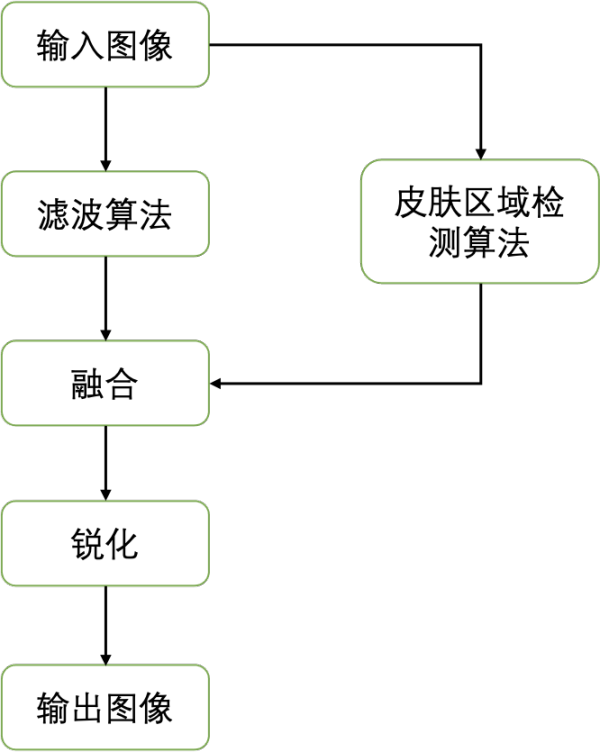
其中為了實(shí)現(xiàn)皮膚區(qū)域的平滑,同時(shí)保留圖像中的邊緣,傳統(tǒng)美顏算法首先使用保邊濾波器(如雙邊濾波、導(dǎo)向?yàn)V波等)來對(duì)圖像進(jìn)行處理。不同于常用的均值濾波、高斯濾波,保邊濾波器考慮了不同區(qū)域像素值的變化,對(duì)像素變化較大的邊緣部分以及變化較為平緩的中間區(qū)域像素采取不同的加權(quán),從而實(shí)現(xiàn)對(duì)于圖像邊緣的保留。而后,為了不影響背景區(qū)域,分割檢測(cè)算法通常被用于定位皮膚區(qū)域,引導(dǎo)原圖與平滑后的圖像進(jìn)行融合。最后,銳化操作可以進(jìn)一步提升邊緣的顯著性以及感官上的清晰度。下圖展示了目前傳統(tǒng)美顏算法的效果:

原圖像來自u(píng)nsplash[31]
從效果來看,傳統(tǒng)美顏算法存在兩大問題:1)對(duì)于瑕疵的處理是非自適應(yīng)的,無法較好的處理不同類型的瑕疵。2)平滑處理造成了皮膚紋理、質(zhì)感的丟失。這些問題在高清圖像中尤為明顯。
3.2 現(xiàn)有深度學(xué)習(xí)算法
為了實(shí)現(xiàn)皮膚不同區(qū)域、不同瑕疵的自適應(yīng)修飾,基于數(shù)據(jù)驅(qū)動(dòng)的深度學(xué)習(xí)算法似乎是更好的解決方案。考慮任務(wù)的相關(guān)性,我們對(duì)Image-to-Image Translation、Photo Retouching、Image Inpainting、High-resolution Image Editing這四類現(xiàn)有方法對(duì)于美膚任務(wù)的適用性進(jìn)行了討論和對(duì)比。
3.2.1 Image-to-Image Translation
圖像翻譯(Image-to-Image Translation)任務(wù)最開始由pix2pix[1]所定義,其將大量計(jì)算機(jī)視覺任務(wù)總結(jié)為像素到像素的預(yù)測(cè)任務(wù),并且提出了一個(gè)基于條件生成對(duì)抗網(wǎng)絡(luò)的通用框架來解決這類問題。基于pix2pix[1],各類方法被陸續(xù)提出以解決圖像翻譯問題,其中包括利用成對(duì)數(shù)據(jù)(paired images)的方法[2,3,4,5]以及利用非成對(duì)數(shù)據(jù)(unpaired images)的方法[6,7,8,9]。一些工作聚焦于某些特定的圖像翻譯任務(wù)(比如語義圖像合成[2,3,5],風(fēng)格遷移等[9,10,11,12]),取得了令人印象深刻效果。然而,上述大部分的圖像翻譯主要關(guān)注于圖像到圖像的整體變換,缺乏對(duì)于局部區(qū)域的注意力,這限制了其在美膚任務(wù)中的表現(xiàn)。
3.2.2 Photo Retouching
受益于深度卷積神經(jīng)網(wǎng)絡(luò)的發(fā)展,基于學(xué)習(xí)的方法[13,14,15,16]近年來在修圖領(lǐng)域展現(xiàn)了出色的效果。然而,與大多數(shù)圖像翻譯方法相似的是,現(xiàn)有的retouching算法主要聚焦于操控圖像的一些整體屬性,比如色彩、光照、曝光等。很少關(guān)注局部區(qū)域的修飾,而美膚恰恰是一個(gè)局部修飾任務(wù)(Local Photo Retouching),需要在修飾目標(biāo)區(qū)域的同時(shí),保持背景區(qū)域不動(dòng)。
3.2.3 Image Inpainting
圖像補(bǔ)全(image inpainting)算法常用于對(duì)圖像缺失的部分進(jìn)行補(bǔ)全生成,與美膚任務(wù)有著較大的相似性。憑借著強(qiáng)大的特征學(xué)習(xí)能力,基于深度生成網(wǎng)絡(luò)的方法[17,18,19,20]這些年在inpainting任務(wù)中取得了巨大的進(jìn)步。然而,inpainting方法依賴于目標(biāo)區(qū)域的mask作為輸入,而在美膚以及其他局部修飾任務(wù)中,獲取精確的目標(biāo)區(qū)域mask本身就是一個(gè)非常具有挑戰(zhàn)性的任務(wù)。因而,大部分的image inpainting任務(wù)無法直接用于美膚。近年來,一些blind image inpainting的方法[21,22,23]擺脫了對(duì)于mask的依賴,實(shí)現(xiàn)了目標(biāo)區(qū)域的自動(dòng)檢測(cè)與補(bǔ)全。盡管如此,同大多數(shù)其他image inpainting方法一樣,這些方法存在兩個(gè)問題:a)缺乏對(duì)于目標(biāo)區(qū)域紋理及語義信息的充分利用,b)計(jì)算量較大,難以應(yīng)用于超高分辨率圖像。
3.2.4 High-resolution Image Editing
為了實(shí)現(xiàn)高分辨率圖像的編輯,[15,24,25,26]等方法通過將主要的計(jì)算量從高分辨率圖轉(zhuǎn)移到低分辨率圖像中,以減輕空間和時(shí)間的負(fù)擔(dān)。盡管在效率上取得了出色的表現(xiàn),由于缺乏對(duì)于局部區(qū)域的關(guān)注,其中大部分方法都不適用于美膚這類局部修飾任務(wù)。
綜上,現(xiàn)有的深度學(xué)習(xí)方法大都難以直接應(yīng)用于美膚任務(wù)中,主要原因在于缺乏對(duì)局部區(qū)域的關(guān)注或者是計(jì)算量較大難以應(yīng)用于高分辨率圖像。
四、基于自適應(yīng)混合金字塔的局部修圖框架
美膚本質(zhì)在于對(duì)圖像的編輯,不同于大多數(shù)其他圖像轉(zhuǎn)換任務(wù)的是,這種編輯是局部的。與其相似的還有服飾去皺,商品修飾等任務(wù)。這類局部修圖任務(wù)具有很強(qiáng)的共通性,我們總結(jié)其三點(diǎn)主要的困難與挑戰(zhàn):1)目標(biāo)區(qū)域的精準(zhǔn)定位。2)具有全局一致性以及細(xì)節(jié)保真度的局部生成(修飾)。3)超高分辨率圖像處理。為此,我們提出了一個(gè)基于自適應(yīng)混合金字塔的局部修圖框架(ABPN: Adaptive Blend Pyramid Network for Real-Time Local Retouching of Ultra High-Resolution Photo, CVPR2022,[27]),以實(shí)現(xiàn)超高分辨率圖像的精細(xì)化局部修圖,下面我們對(duì)其實(shí)現(xiàn)細(xì)節(jié)進(jìn)行介紹。
4.1 網(wǎng)絡(luò)整體結(jié)構(gòu)
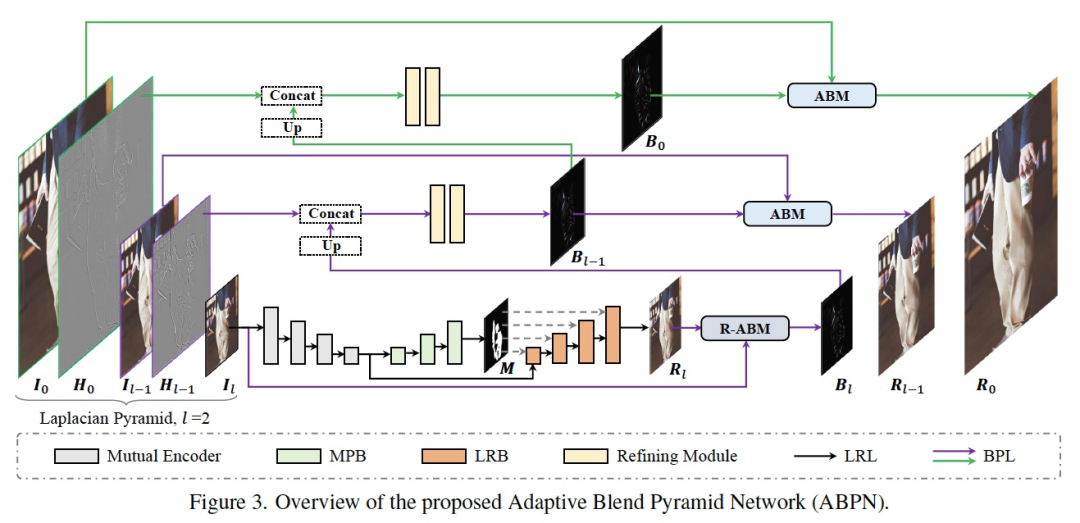
如上圖所示,網(wǎng)絡(luò)結(jié)構(gòu)主要由兩個(gè)部分組成:上下文感知的局部修飾層(LRL)和自適應(yīng)混合金字塔層(BPL)。其中LRL的目的是對(duì)降采樣后的低分辨率圖像進(jìn)行局部修飾,生成低分辨率的修飾結(jié)果圖,充分考慮全局的上下文信息以及局部的紋理信息。進(jìn)一步,BPL用于將LRL中生成的低分辨率結(jié)果逐步向上拓展到高分辨率結(jié)果。其中,我們?cè)O(shè)計(jì)了一個(gè)自適應(yīng)混合模塊(ABM)及其逆向模塊(R-ABM),利用中間混合圖層Bi,可實(shí)現(xiàn)原圖與結(jié)果圖之間的自適應(yīng)轉(zhuǎn)換以及向上拓展,展現(xiàn)了強(qiáng)大的可拓展性和細(xì)節(jié)保真能力。我們?cè)谀槻啃揎椉胺椥揎梼蓚€(gè)數(shù)據(jù)集中進(jìn)行了大量實(shí)驗(yàn),結(jié)果表明我們的方法在效果和效率上都大幅度地領(lǐng)先了現(xiàn)有方法。值得一提的是,我們的模型在單卡P100上實(shí)現(xiàn)了4K超高分辨率圖像的實(shí)時(shí)推理。下面,我們對(duì)LRL、BPL及網(wǎng)絡(luò)的訓(xùn)練loss分別進(jìn)行介紹。
4.2 上下文感知的局部修飾層(Context-aware Local Retouching Layer)
在LRL中,我們想要解決三中提到的兩個(gè)挑戰(zhàn):目標(biāo)區(qū)域的精準(zhǔn)定位以及具有全局一致性的局部生成。如Figure 3所示,LRL由一個(gè)共享編碼器、掩碼預(yù)測(cè)分支(MPB)以及局部修飾分支(LRB)構(gòu)成。
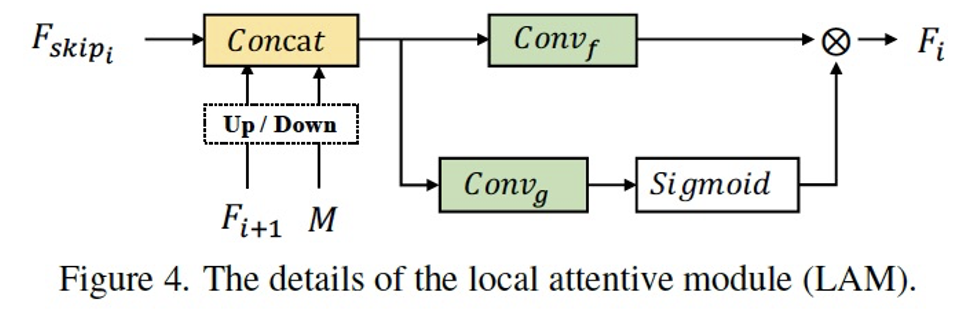

總得來說,我們使用了一個(gè)多任務(wù)的結(jié)構(gòu),以實(shí)現(xiàn)顯式的目標(biāo)區(qū)域預(yù)測(cè),與局部修飾的引導(dǎo)。其中,共享編碼器的結(jié)構(gòu)可以利用兩個(gè)分支的共同訓(xùn)練優(yōu)化特征,提高修飾分支對(duì)于目標(biāo)全局的語義信息和局部的感知。大多數(shù)的圖像翻譯方法使用傳統(tǒng)的encoder-decoder結(jié)構(gòu)直接實(shí)現(xiàn)局部的編輯,沒有將目標(biāo)定位與生成進(jìn)行解耦,從而限制了生成的效果(網(wǎng)絡(luò)的容量有限),相比之下多分支的結(jié)構(gòu)更利于任務(wù)的解耦以及互利。在局部修飾分支LRB中我們?cè)O(shè)計(jì)了LAM(Figure 4),將空間注意力機(jī)制與特征注意力機(jī)制同時(shí)作用,以實(shí)現(xiàn)特征的充分融合以及目標(biāo)區(qū)域的語義、紋理的捕捉。消融實(shí)驗(yàn)(Figure 6)展現(xiàn)了各個(gè)模塊設(shè)計(jì)的有效性。
4.3 自適應(yīng)混合金字塔層(Adaptive Blend Pyramid Layer)
LRL在低分辨率上實(shí)現(xiàn)了局部修飾,如何將修飾的結(jié)果拓展到高分辨率同時(shí)增強(qiáng)其細(xì)節(jié)保真度?這是我們?cè)谶@部分想要解決的問題。
4.3.1 自適應(yīng)混合模塊(Adaptive Blend Module)
在圖像編輯領(lǐng)域,混合圖層(blend layer)常被用于與圖像(base layer)以不同的模式混合以實(shí)現(xiàn)各種各樣的圖像編輯任務(wù),比如對(duì)比度的增強(qiáng),加深、減淡操作等。通常地,給定一張圖片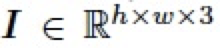 ,以及一個(gè)混合圖層
,以及一個(gè)混合圖層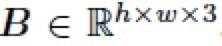 ,我們可以將兩個(gè)圖層進(jìn)行混合得到圖像編輯結(jié)果
,我們可以將兩個(gè)圖層進(jìn)行混合得到圖像編輯結(jié)果
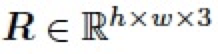
,如下:

其中 f 是一個(gè)固定的逐像素映射函數(shù),通常由混合模式所決定。受限于轉(zhuǎn)化能力,一個(gè)特定的混合模式及固定的函數(shù) f 難以直接應(yīng)用于種類多樣的編輯任務(wù)中去。為了更好的適應(yīng)數(shù)據(jù)的分布以及不同任務(wù)的轉(zhuǎn)換模式,我們借鑒了圖像編輯中常用的柔光模式,設(shè)計(jì)了一個(gè)自適應(yīng)混合模塊 (ABM),如下:
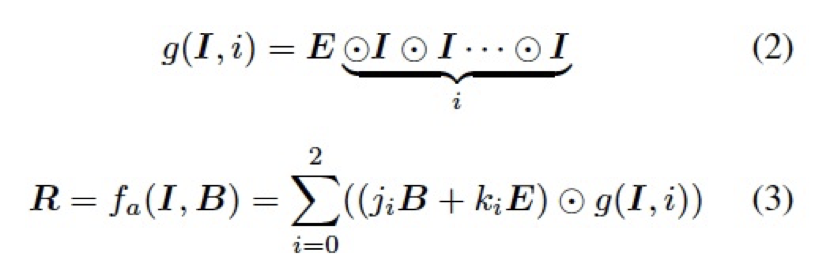
其中 表示 Hadmard product,
表示 Hadmard product,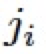 和
和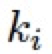 為可學(xué)習(xí)的參數(shù),被網(wǎng)絡(luò)中所有的 ABM 模塊以及接下來的 R-ABM 模塊所共享,
為可學(xué)習(xí)的參數(shù),被網(wǎng)絡(luò)中所有的 ABM 模塊以及接下來的 R-ABM 模塊所共享,
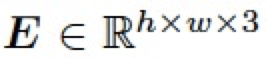
表示所有值為 1 的常數(shù)矩陣。 4.3.2 逆向自適應(yīng)混合模塊(Reverse Adaptive Blend Module) 實(shí)際上,ABM 模塊是基于混合圖層 B 已經(jīng)獲得的前提假設(shè)。然而,我們?cè)?LRL 中只獲得了低分辨率的結(jié)果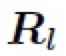 ,為了得到混合圖層 B,我們對(duì)公式 3 進(jìn)行求解,構(gòu)建了一個(gè)逆向自適應(yīng)混合模塊 (R-ABM),如下: ?
,為了得到混合圖層 B,我們對(duì)公式 3 進(jìn)行求解,構(gòu)建了一個(gè)逆向自適應(yīng)混合模塊 (R-ABM),如下: ?
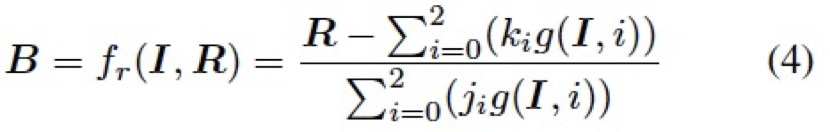
總的來說,通過利用混合圖層作為中間媒介,ABM 模塊和 R-ABM 模塊實(shí)現(xiàn)了圖像 I 和結(jié)果 R 之間的自適應(yīng)轉(zhuǎn)換,相比于直接對(duì)低分辨率結(jié)果利用卷積上采樣等操作進(jìn)行向上拓展(如 Pix2PixHD),我們利用混合圖層來實(shí)現(xiàn)這個(gè)目標(biāo),有其兩方面的優(yōu)勢(shì):1)在局部修飾任務(wù)中,混合圖層主要記錄了兩張圖像之間的局部轉(zhuǎn)換信息,這意味著其包含更少的無關(guān)信息,且更容易由一個(gè)輕量的網(wǎng)絡(luò)進(jìn)行優(yōu)化。2)混合圖層直接作用于原始圖像來實(shí)現(xiàn)最后的修飾,可以充分利用圖像本身的信息,進(jìn)而實(shí)現(xiàn)高度的細(xì)節(jié)保真。
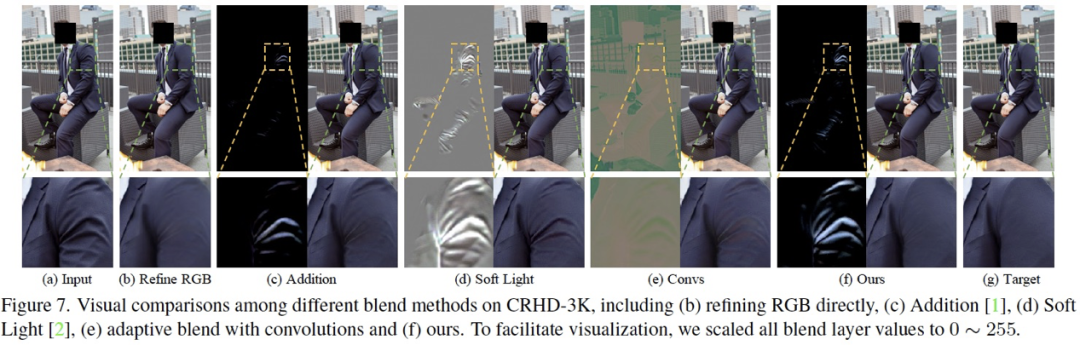
實(shí)際上,關(guān)于自適應(yīng)混合模塊有許多可供選擇的函數(shù)或者策略,我們?cè)谡撐闹袑?duì)設(shè)計(jì)的動(dòng)機(jī)以及其他方案的對(duì)比進(jìn)行了詳細(xì)介紹,這里不進(jìn)行更多的闡述了,F(xiàn)igure 7 展示了我們的方法和其他混合方法的消融對(duì)比。 4.3.3 Refining Module

4.4 損失函數(shù)

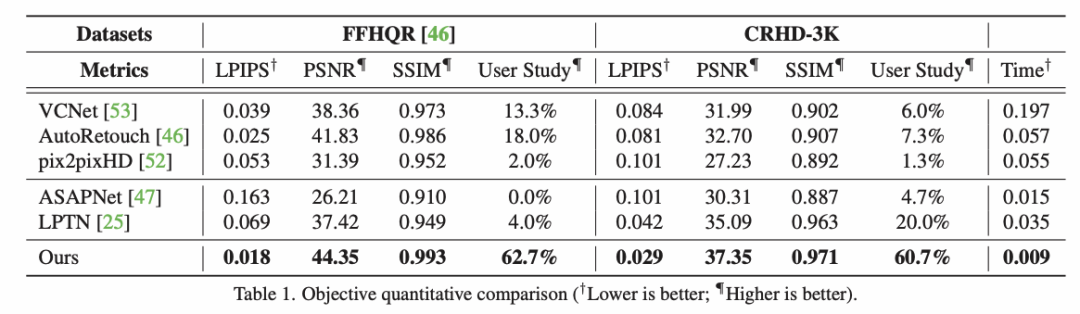
實(shí)驗(yàn)結(jié)果5.1 與 SOTA 方法對(duì)比
5.2 消融實(shí)驗(yàn)

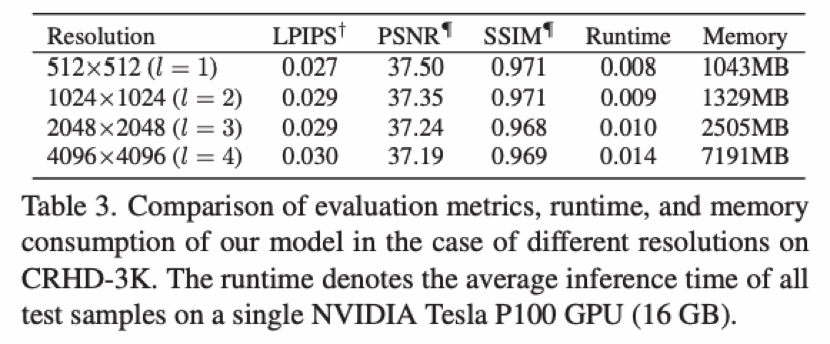
5.3 運(yùn)行速度與內(nèi)存消耗
效果展示 美膚效果展示:
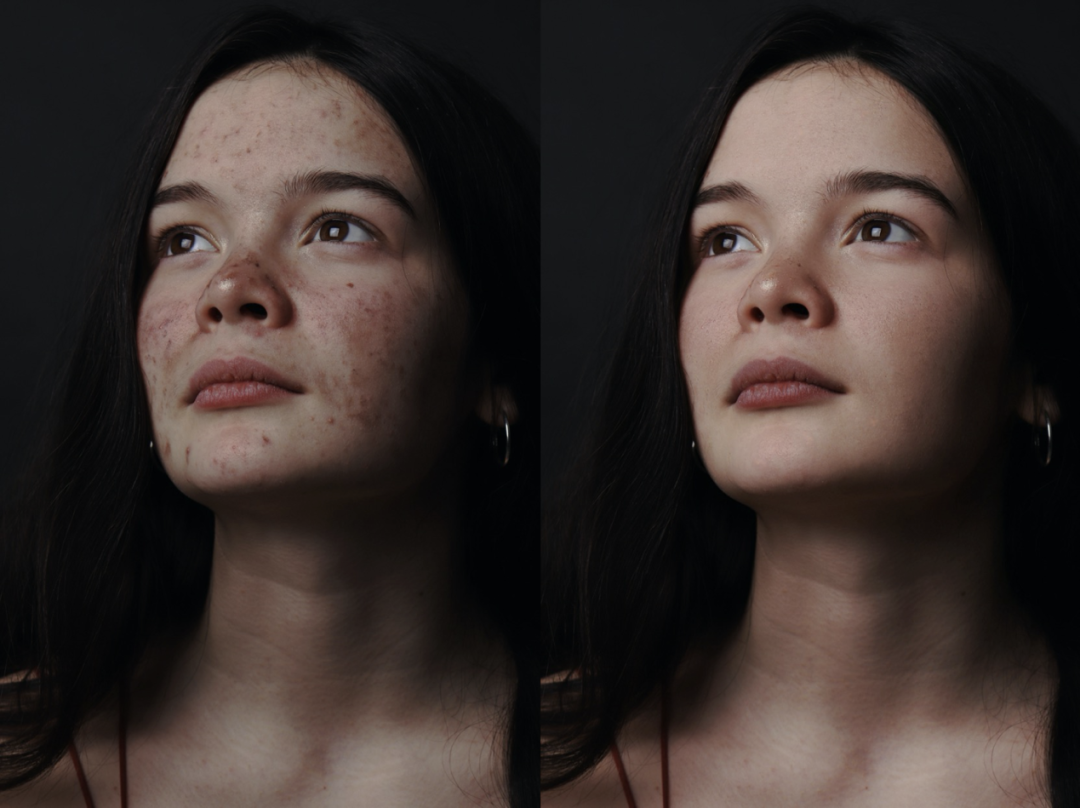
原圖像來自 unsplash [31]

原圖像來自人臉數(shù)據(jù)集 FFHQ [32]

原圖像來自人臉數(shù)據(jù)集 FFHQ [32] 可以看到,相較于傳統(tǒng)的美顏算法,我們提出的局部修圖框架在去除皮膚瑕疵的同時(shí),充分的保留了皮膚的紋理和質(zhì)感,實(shí)現(xiàn)了精細(xì)、智能化的膚質(zhì)優(yōu)化。進(jìn)一步,我們將該方法拓展到服飾去皺領(lǐng)域,也實(shí)現(xiàn)了不錯(cuò)的效果,如下:


審核編輯 :李倩
-
濾波器
+關(guān)注
關(guān)注
161文章
7855瀏覽量
178593 -
算法
+關(guān)注
關(guān)注
23文章
4626瀏覽量
93151 -
圖像
+關(guān)注
關(guān)注
2文章
1088瀏覽量
40518
原文標(biāo)題:CVPR 2022 | 阿里達(dá)摩院提出ABPN:高清人像美膚模型
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
看點(diǎn):阿里發(fā)布大模型報(bào)告 蘋果股價(jià)連續(xù)四日再創(chuàng)新高 傳阿里巴巴與韓國(guó)易買得合并
阿里云開源推理大模型QwQ
阿里通義千問代碼模型全系列開源
阿里云開源Qwen2.5-Coder代碼模型系列
阿里國(guó)際發(fā)布翻譯大模型Marco
阿里達(dá)摩院發(fā)布玄鐵R908 CPU
阿里云設(shè)備的物模型數(shù)據(jù)里面始終沒有值是為什么?
阿里達(dá)摩院提出“知識(shí)鏈”框架,降低大模型幻覺
潤(rùn)開鴻榮膺達(dá)摩院“玄鐵優(yōu)選伙伴”獎(jiǎng)
玄鐵RISC-V生態(tài)大會(huì)深圳召開,達(dá)摩院引領(lǐng)RISC-V創(chuàng)新應(yīng)用

達(dá)摩院院長(zhǎng)張建鋒:RISC-V迎來蝶變,進(jìn)入應(yīng)用爆發(fā)期
達(dá)摩院牽頭成立“無劍聯(lián)盟”,探索RISC-V產(chǎn)業(yè)合作新范式






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論