 一種融合網絡RADIANT來解決雷達-攝像機關聯的方案
一種融合網絡RADIANT來解決雷達-攝像機關聯的方案
動機
作為一種能夠直接測量深度的傳感器,其相較于Lidar存在較大的誤差,因此利用雷達本身精度難以精確地將雷達結果與單目方法的3D估計相關聯。本文提出了一種融合網絡RADIANT來解決雷達-攝像機關聯的挑戰。通過預測雷達點到真實目標中心點的3D偏移,隨后利用修正后的雷達點修正圖像預測結果,使得網絡在特征層和檢測層完成融合。
貢獻
通過增強毫米波點云獲得3D目標的中心位置
使用增強后的毫米波點云完成相機-雷達的檢測結果關聯
在多個單目SOTA模型中驗證了結構有效性并取得SOTA
背景&問題定義
正雷達樣本點
對于目標檢測的訓練,關鍵就是:候選點的選擇、定義正負樣本,FCOS3D將每個像素點作為目標候選點,而正樣本點定義為GT目標中心周圍的區域內。同樣,對于本文,我們將每個雷達反射點作為目標的候選點,將成功與目標相關聯的雷達像素點作為正樣本點。
但是,由于毫米波反射點的模糊性(存在多徑干擾)和不準確性(檢測的分辨率不高)等問題,導致反射點許多無法反映真實的目標位置框內,同時目前的主流多模態數據集(radar+camera)沒有提供point-wise(點云級別)的標記,以上兩種原因導致了:現有的毫米波反射點無論是精度上還是標注上,都需要做一些工作。 由此,作者如此解決:
3D框內部的點云當然歸屬于對應目標,但是對于外部點云,作者設置距離閾值將一定范圍內的點云考慮在內
同時為了防止誤召回,上一步召回的點云還需要再徑向速度上與分配的GT目標相差在一定范圍內
Radar Depth Offset
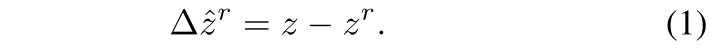
z為反射點相關聯的目標深度,z_r為反射點的原始測量深度
細化動機:
單目3D檢測性能一直受到深度估計不精確問題的裹挾
毫米波雷達能提供相較相機更精確的深度,但是其稀疏性、穿透性導致其很難反映出目標真實中心,甚至出現幽靈點,反射點到物體中心的偏移是未知的,但是又是關鍵的,我們通常需要通過物體的中心特征回歸目標的各類屬性
預測的偏移不僅要包括深度偏移,還有image-plane的投影像素偏移,補償雷達反射點在橫向等方向上誤差
因為點云和目標匹配需要類別信息,毫米波用于分類的信息較少(無法通過形狀判斷)
網絡架構
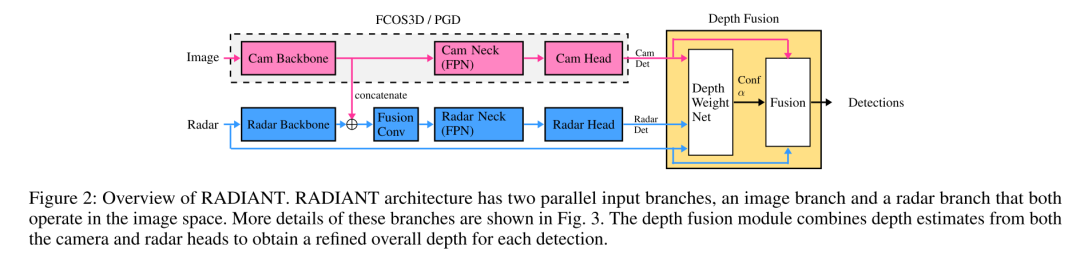
整體上,作者使用“雙流”網絡結構,圖像、雷達分支分別使用原始FCOS3D網絡、引入圖像特征的輕量級FCOS3D網絡,在Depth Fusion結構中,通過DWN(depth weight net)對兩個head預測結果引入可學習的深度加權網絡,并在最后預測加權后的目標深度。
我們按照(Backbone, Neck, Heads):分別生成圖像預測結果和點云預測結果, (Depth Fusion Modules):修正圖像預測結果,兩個部分介紹細節:
Backbone, Neck, Heads
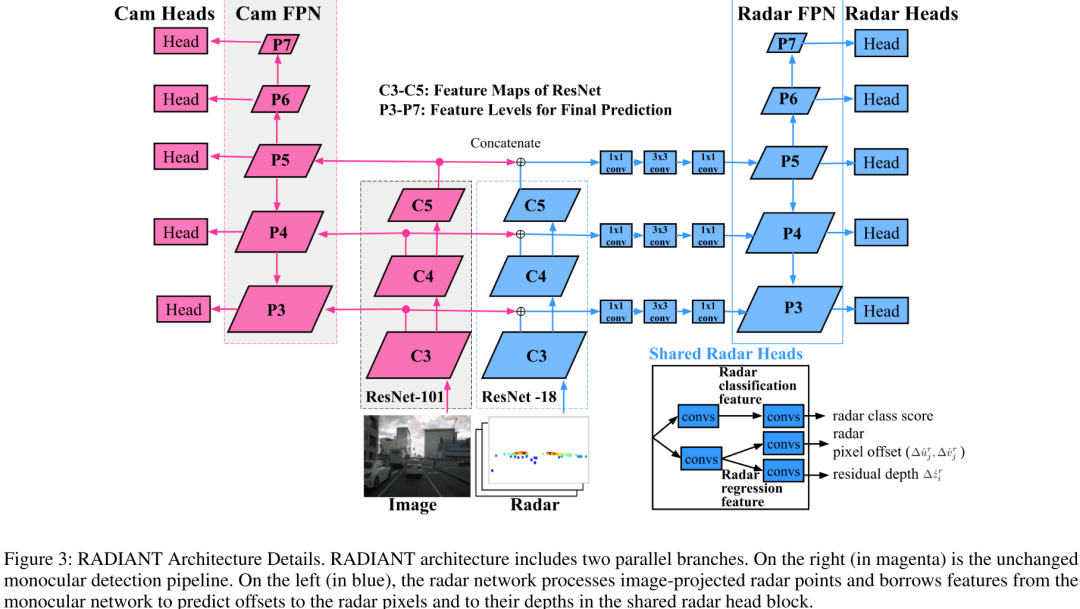
更進一步,對圖像分支采用原始FCOS3D網絡,不過多介紹。對Radar分支,輸入的是投影到image-plane的數據,其中包括深度、坐標、速度、占位掩碼(象征點云是否存在于像素中方便后面后處理),在neck部分加入了一些bottleneck瓶頸結構融合圖像和雷達數據,解決點云分類能力不足的問題。
最后就是在Head上,與圖像的各類目標屬性回歸不同,點云只在其分布的投影像素中,計算類別得分、像素偏移、深度殘差(偏移)三個屬性。最后的結果形式如下。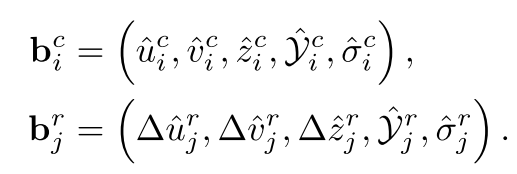
Depth Fusion Module
在得到heads的結果后,這部分的任務就是將兩個模態的結果融合,用radar預測的結果修正圖像預測結果:
關聯投影后的雷達反射點radar pixels(預測修正后)與圖像檢測結果
對關聯后的每個radar pixels預測深度可靠性概率
利用加權后的radar pixels,修正目標的深度,對于目標的尺度、角度等屬性不做修改,作者認為是毫米波缺少目標朝向、尺度信息
Radar-Camera Association
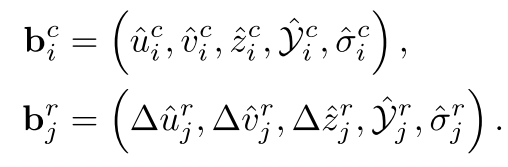
由上圖,我們已得到兩個Heads的輸出,我們取圖像預測結果的前1000個boxes按照得分,同樣,我們也取radar預測結果中滿足置信度>T_r的radar pixels用于融合,我們把雷達預測結果先修正: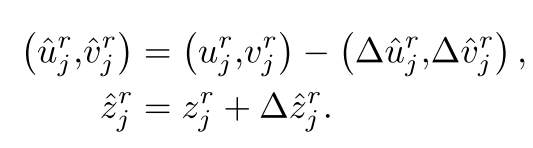
修正后,進行關聯:匹配要滿足以下條件:首先,類別相同,其次投影像素差在一定范圍內,最后,深度誤差在一定范圍內,由此,完成篩選和匹配,假設兩個Heads結果分別是MN個,則復雜度為O(MN)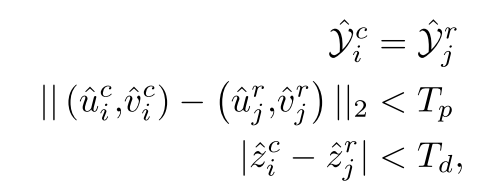
上部分完成了radar pixels的篩選和匹配,本部分進行融合 這部分采用可學習的方式,與之對比的是將匹配的radar pixels深度與圖像檢測的深度進行平均相加這種不可學習的固定方式
這個網絡的目的,就是判斷radar pixels是否可信,輸出可信度,用于最后的融合。 那么如何規定訓練標簽呢?
DWN預測的是每個點的置信度,DWN前向完成后,結合圖像預測和GT,給予每個點云權重標簽,用于訓練DWN,DWN僅根據點云head輸出特征、原始深度等信息預測,如果GT與radar更接近,α標記為1,反之和圖像預測的結果更接近則為0.
Fused Depth Calculation
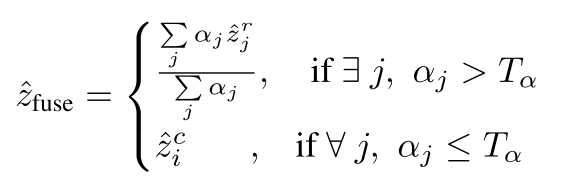
上一步預測的radar pixels權重,這一步根據權重融合加權得到結果,Tα就是閾值,如果任意點云的深度權重閾值<閾值,則只考慮相機的預測結果
實驗
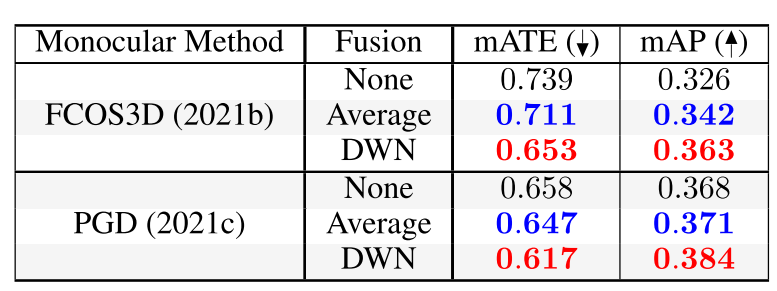
作者對融合方式做了消融實驗,其中None是不加入雷達反射點,Average代表平均反射點與圖像預測深度,DWN是作者提出的深度權重網絡。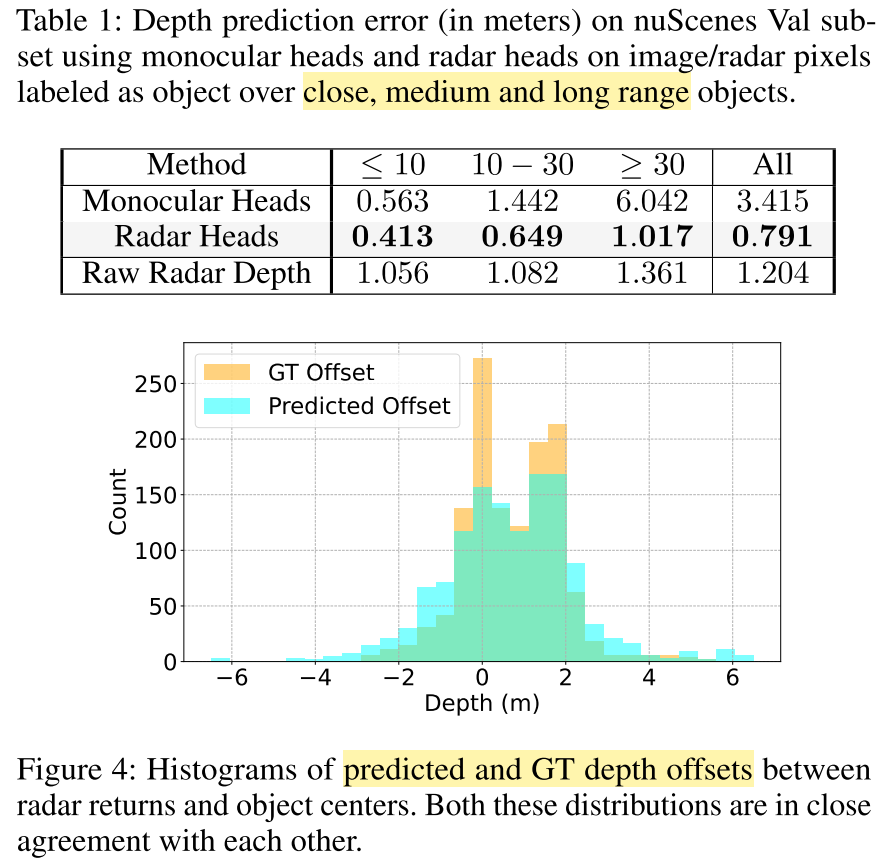
由上圖,最上面的Table1,表述了從由近到遠過程中,圖像、原始雷達、修正后雷達(中間)的預測誤差,可以看到經過offset的修正后,雷達的深度預測值在近處的修正作用占比更大。
這里不要被作者的數據嚇到,因為這是丈量雷達反射點到目標中心偏移誤差,因為雷達反射點本身就分布在非車身中心。
上圖中的Figure 4,分別代表:融合后目標深度預測值和雷達反射點之間的偏差,GT目標深度和雷達反射點之間的偏差,兩者的偏差分布整體是相似的,預測結果的偏差分布更加均勻。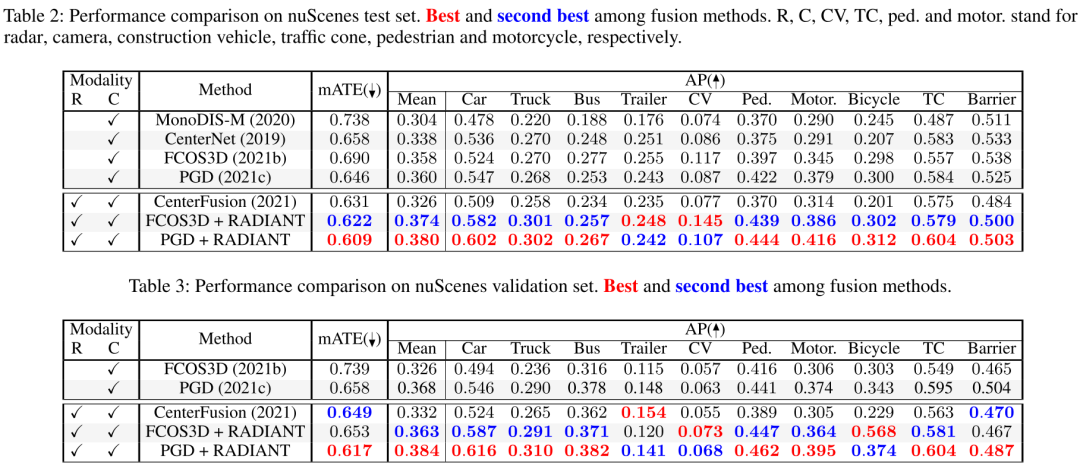
Table2是NuScenes數據集上的實驗結果對比,作者基于FOCOS3D, PGD兩類單目檢測模型改進,都得到了較大的提升,提升體現在mATE,AP兩個數據指標上。同時,相比經典的centerfusion,也有較大的提升。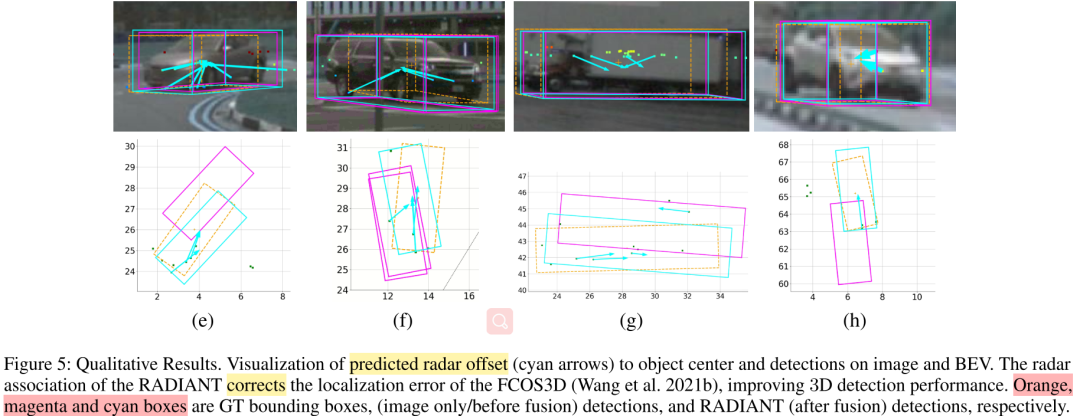
Figure 5中,分散的反射點通過預測offset,集中于目標的中心,目標的深度也得到了進一步的修正。
簡單總結:
作者提出的這種關聯、更新方式,有效改善了單目單幀的目標深度預測能力,提出了細粒度更高的標記NuScenes毫米波點云的一種方式
根據具體場景,根據傳感器特性,在feature-level和decision-level上多方式非對稱融合往往更加有效
作者基于image-plane,選擇的投影方式導致了點云偏移預測受限于特征提取方式,事實上雷達點云投影存在遮擋,同時點云稀疏,將其投影到image-plane上導致原本形狀進一步丟失,進一步加劇了數據的稀疏性
作者只通過radar改善了目標的位置性能和平均精度,事實上目標的RCS等信息對于其他屬性仍然有一定修正作用
審核編輯:劉清
-
傳感器
+關注
關注
2552文章
51383瀏覽量
756118 -
圖像檢測
+關注
關注
0文章
34瀏覽量
11902 -
毫米波
+關注
關注
21文章
1927瀏覽量
64970
原文標題:RV融合新SOTA!RADIANT:全新雷達-圖像關聯網絡的3D檢測
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論