 GA-RPN:Region Proposal by Guided Anchoring 引導錨點的建議區域網絡
GA-RPN:Region Proposal by Guided Anchoring 引導錨點的建議區域網絡
論文地址:https://arxiv.org/pdf/1901.03278.pdf
代碼地址:GitHub - open-mmlab/mmdetection: OpenMMLab Detection Toolbox and Benchmark
1.RPN
RPN即Region Proposal Network,是用RON來選擇感興趣區域的,即proposal extraction。例如,如果一個區域的p>0.5,則認為這個區域中可能是80個類別中的某一類,具體是哪一類現在還不清楚。到此為止,網絡只需要把這些可能含有物體的區域選取出來就可以了,這些被選取出來的區域又叫做ROI(Region of Interests),即感興趣的區域。當然RPN同時也會在feature map上框定這些ROI感興趣區域的大致位置,即輸出Bounding Box。
RPN詳細介紹:https://mp.weixin.qq.com/s/VXgbJPVoZKjcaZjuNwgh-A
2.Guided Anchoring
通常用(x,y,w,h)來描述一個anchor,即中心點坐標和寬高。文章將anchor的分布用條件概率來表示,公式為:
p(x,y,w,h|I)=p(x,y|I)p(w,h|x,y,I)
兩個條件概率的分布,代表給定圖像特征之后anchor的 中心點概率分布 ,和給定圖像特征和中心點之后的 形狀概率分布 。這樣看來,原來我們所獲取anchor的方法就可以看成上述條件概率分布的一個特例,即p(x,y|I)是均勻分布而p(w,h|x,y,I)是沖激函數。
根據上面的公式,anchor的生成過程可以分解為兩個步驟,anchor位置預測和形狀預測。
論文中用到的方法如下:
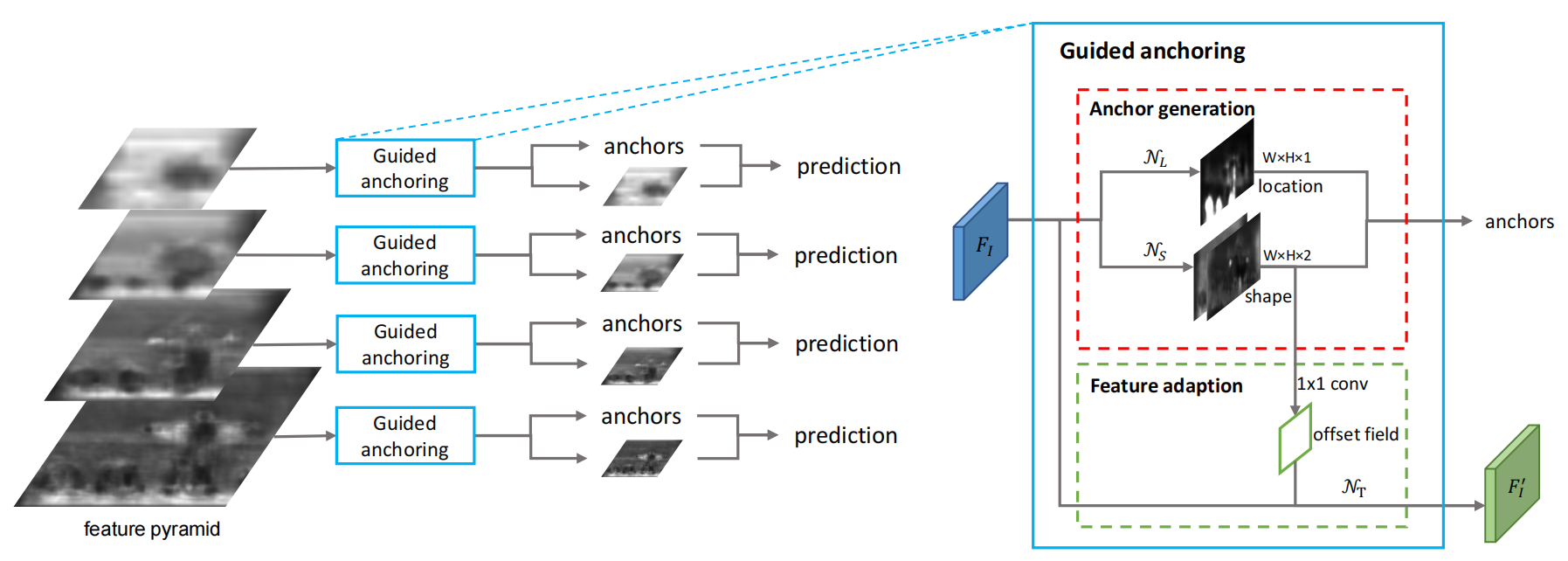
這個框架就是在原始的RPN的特征圖基礎上,采用兩個分值分別預測anchor的位置和形狀,然后再結合到一起得到anchor。之后采用一個Feature Adaption模塊進行anchor特征的調整,得到新的特征圖供之后的預測使用(anchor的分類和回歸)。整個方法可以端到端訓練,而且相比之前只是增加了3個1×1 conv 和一個3×3 deformable conv,帶來的模型參數量變化很小。
(1)位置預測
位置預測分支的目標是預測哪些區域應該作為中心點來生成anchor,也是一個二分類問題,但是不同于RPN的分類,我們并不是預測每個點是前景還是背景,而是預測是不是物體中心。
我們將整個feature map的區域分為物體中心區域、外圍區域和忽略區域,大致思路就是將groundtruth 框的中心一小塊對應在feature map上的區域標為物體中心區域,在訓練的時候作為 正樣本 ,其余區域按照離中心的距離標為忽略或者 負樣本 。最后通過選擇對應概率值高于預定閾值的位置來確定可能存在對象活動的區域。F1 對輸入的特征圖使用 1×1 的卷積,得到與 F1 相同分辨率的輸出,N_L 得到輸出的每個位置的值表示原圖I上對應位置出現物體的可能性,也就是概率圖,最后通過選擇對應概率值高于預定閾值的位置來確定可能存在對象活動的區域。
通過位置預測,我們可以篩選出一小部分區域作為anchor的候選中心點位置,使得anchor數量大大降低。這樣在最后我們就可以只針對有anchor的地方進行計算。
(2)形狀預測
形狀預測分支是目標是給定anchor中心點,預測最佳的長和寬,這是一個回歸問題。
采用1×1的卷積網絡 N_s 輸入 F_1,輸出與 F_1 尺寸相同的2通道的特征圖,每個通道分別代表 dw 和 dh,表示每個位置可能的最好的 anchor 尺寸。雖然我們的預測目標是 w 和 h,但是直接預測這兩個數字不穩定,因為范圍很大,所以將空間近似 [0,1000] 映射到了 [-1,1] 中,公式為:
w=\\sigma \\times s \\times e^{dw},w=\\sigma \\times s \\times e^{dh}
其中 s 是步幅,σ 是經驗因子,實驗中取 σ=8。實驗中產生 dw,dh 的雙通道映射,通過這個方程實現了逐像素轉換。文章中直接用 IOU 作為監督來學習 w 和 h。
對于 anchor 和 ground truth 匹配問題,傳統 RPN 都是直接計算 anchor 和所有 ground truth 的 IOU,然后將anchor 匹配給 IOU 最大的那個 ground truth,但是現在由于我們的改進,anchor 的 w 和 h 都是不確定的,是一個需要預測的變量。文中將這個 anchor 和某個 ground truth 的 IOU 表示為:
vIOU(a_{wh},gt)=\\max_{w>0,h>0}IOU_{normal}(a_{wh},gt)
我們不可能把所有可能的 w 和 h 遍歷一遍求 IOU 的最大值,文中采用了9組可能的 w 和 h 作為樣本,近似效果已經足夠。
到這里我們就可以生成 anchor 了。這時所生成的 anchor 就是稀疏而且每個位置不一樣的。實驗可得此時的平均 recall 已經超過普通的 RPN 了,僅僅是增加了兩個 conv。

(3)特征精調模塊
由于每個位置的形狀不同,大的anchor對應較大感受野,小的anchor對應小的感受野。所以不能像之前基于anchor的方法那樣直接對feature map進行卷積來預測,而是要對feature map進行feature adaptation。作者利用可變形卷積(deformable convolution)的思想,根據形狀對各個位置單獨進行轉換。

方法就是把anchor的形狀信息直接融入到特征圖當中,得到新的特征圖去適應每個位置anchor的形狀。這里就利用了上述的3×3的可變形卷積進行對原始特征圖的修正,可變形卷積的變化量是通過anchor的w和h經過一個1×1 conv得到的。
f'_i=N_t(f_i,w_i,h_i)
其中,fi 是第 i 個位置的特征,(wi, hi) 是對應的 anchor 形狀。NT 通過 3×3 的變形卷積實現。首先通過形狀預測分支預測偏移字段 offset field,然后對帶偏移的原始 feature map 做變形卷積獲得 adapted features。之后進一步做分類和 bounding box 回歸。
通過這樣的操作,達到了讓 feature 的有效范圍和 anchor 形狀更加接近的目的,同一個 conv 的不同位置也可以代表不同形狀大小的 anchor 了。
文中實驗結果示例:

學習更多編程知識,請關注我的公眾號:
[代碼的路]
-
神經網絡
+關注
關注
42文章
4772瀏覽量
100851 -
代碼
+關注
關注
30文章
4791瀏覽量
68699
發布評論請先 登錄
相關推薦
激光焊接技術在焊接醫療引導管的工藝應用

“中國芯”產業的十年歷程和國內集成電路區域發展研究(下篇)

VL53L1CB TOF開發(2)----多區域掃描模式


UWB-AOA單錨點數字鑰匙與雷達

激光焊接視覺定位引導方法


訊維通信技術在跨區域企業通信網絡整合中的應用案例
stm32H705xb jlink調試不穩定怎么解決?
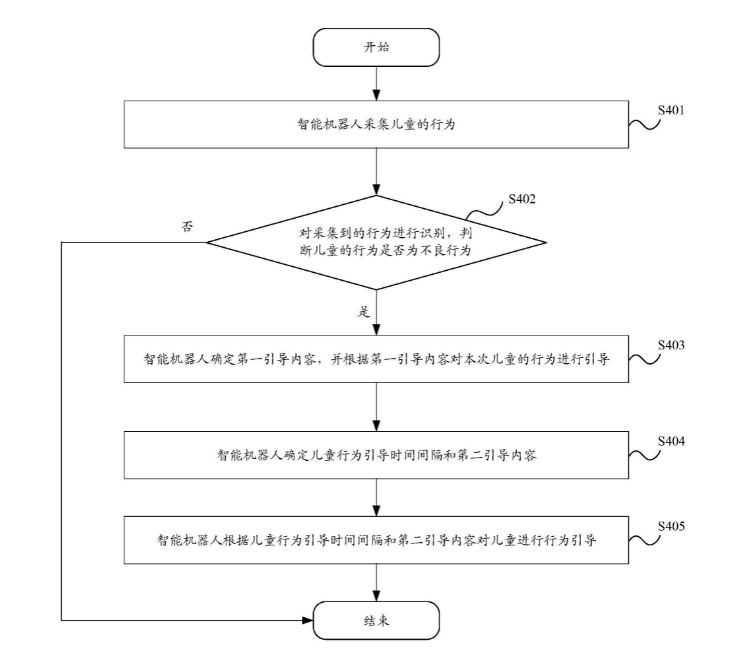
華為公開兒童行為引導專利
區域架構及其對優化成本和功耗的新機會






 工商網監
工商網監
評論