") TiDB底層存儲(chǔ)結(jié)構(gòu)LSM樹(shù)原理介紹
TiDB底層存儲(chǔ)結(jié)構(gòu)LSM樹(shù)原理介紹
來(lái)源| OSCHINA 社區(qū)
作者 | 京東云開(kāi)發(fā)者-京東物流 劉家存
隨著數(shù)據(jù)量的增大,傳統(tǒng)關(guān)系型數(shù)據(jù)庫(kù)越來(lái)越不能滿(mǎn)足對(duì)于海量數(shù)據(jù)存儲(chǔ)的需求。對(duì)于分布式關(guān)系型數(shù)據(jù)庫(kù),我們了解其底層存儲(chǔ)結(jié)構(gòu)是非常重要的。本文將介紹下分布式關(guān)系型數(shù)據(jù)庫(kù) TiDB 所采用的底層存儲(chǔ)結(jié)構(gòu) LSM 樹(shù)的原理。
1 LSM 樹(shù)介紹
LSM 樹(shù)(Log-Structured-Merge-Tree) 日志結(jié)構(gòu)合并樹(shù)由 Patrick O’Neil 等人在論文《The Log-Structured Merge Tree》(https://www.cs.umb.edu/~poneil/lsmtree.pdf) 中提出,它實(shí)際上不是一棵樹(shù),而是 2 個(gè)或者多個(gè)不同層次的樹(shù)或類(lèi)似樹(shù)的結(jié)構(gòu)的集合。 LSM 樹(shù)的核心特點(diǎn)是利用順序?qū)憗?lái)提高寫(xiě)性能,代價(jià)就是會(huì)稍微降低讀性能(讀放大),寫(xiě)入量增大(寫(xiě)放大)和占用空間增大(空間放大)。 LSM 樹(shù)主要被用于 NoSql 數(shù)據(jù)庫(kù)中,如 HBase、RocksDB、LevelDB 等,知名的分布式關(guān)系型數(shù)據(jù)庫(kù) TiDB 的 kv 存儲(chǔ)引擎 TiKV 底層存儲(chǔ)就是用的上面所說(shuō)的 RocksDB,也就是用的 LSM 樹(shù)。
2 LSM 樹(shù)算法大概思路
LSM 樹(shù)由兩個(gè)或多個(gè)樹(shù)狀的結(jié)構(gòu)組成。
這一節(jié)我們以?xún)蓚€(gè)樹(shù)狀的結(jié)構(gòu)構(gòu)成的簡(jiǎn)單的雙層 LSM 樹(shù)舉例,來(lái)簡(jiǎn)單說(shuō)下 LSM 樹(shù)大概思路,讓大家對(duì) LSM 樹(shù)實(shí)現(xiàn)有個(gè)整體的認(rèn)識(shí)。 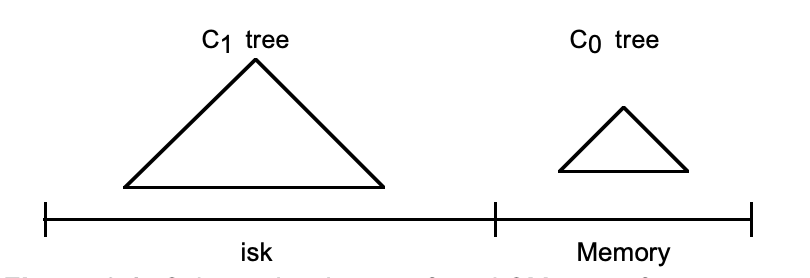 原論文中的圖
原論文中的圖
2.1 數(shù)據(jù)結(jié)構(gòu)
雙層 LSM 樹(shù)有一個(gè)較小的層,該層完全駐留在內(nèi)存中,作為 C0 樹(shù)(或 C0 層),以及駐留在磁盤(pán)上的較大層,稱(chēng)為 C1 樹(shù)。
盡管 C1 層駐留在磁盤(pán)上,但 C1 中經(jīng)常引用的節(jié)點(diǎn)將保留在內(nèi)存緩沖區(qū)中,因此 C1 經(jīng)常引用的節(jié)點(diǎn)也可以被視為內(nèi)存駐留節(jié)點(diǎn)。
2.2 寫(xiě)入
寫(xiě)入時(shí),首先將記錄行寫(xiě)入順序日志文件 WAL 中,然后再將此記錄行的索引項(xiàng)插入到內(nèi)存駐留的 C0 樹(shù)中,然后通過(guò)異步任務(wù)及時(shí)遷移到磁盤(pán)上的 C1 樹(shù)中。
2.3 讀取
任何搜索索引項(xiàng)將首先在 C0 中查找,在 C0 中未找到,然后再在 C1 中查找。
如果存在崩潰恢復(fù),還需要讀取恢復(fù)崩潰前未從磁盤(pán)中取出的索引項(xiàng)。
2.4 Compact 過(guò)程
將索引條目插入駐留在內(nèi)存中的 C0 樹(shù)的操作沒(méi)有 I/O 成本,然而,與磁盤(pán)相比,容納 C0 組件的內(nèi)存容量成本較高,這對(duì)其大小施加了限制。達(dá)到一定大小后,我們就需要將數(shù)據(jù)遷移到下一層。
我們需要一種有效的方法將記錄項(xiàng)遷移到駐留在成本較低的磁盤(pán)介質(zhì)上的 C1 樹(shù)中。為了實(shí)現(xiàn)這一點(diǎn),當(dāng)插入達(dá)到或接近每一層分配的最大值的閾值大小,將進(jìn)行一個(gè)滾動(dòng)合并(Compact)過(guò)程,用于從 C0 樹(shù)中刪除一些連續(xù)的記錄項(xiàng),并將其合并到 C1 中。
Compact 目前有兩種策略,size-tiered 策略,leveled 策略,我們將在下面的內(nèi)容里詳細(xì)介紹這兩種策略。
2.5 崩潰恢復(fù)
在 C0 樹(shù)中的項(xiàng)遷移到駐留在磁盤(pán)上的 C1 樹(shù)之前,存在一定的延遲(延遲),為了保證機(jī)器崩潰后 C0 樹(shù)中的數(shù)據(jù)不丟失,在生成每個(gè)新的歷史記錄行時(shí),首先將用于恢復(fù)此插入的日志記錄寫(xiě)入以常規(guī)方式創(chuàng)建的順序日志文件 WAL 中,然后再寫(xiě)入 C0 中。
3 LSM 樹(shù)的組成
LSM 樹(shù)有三個(gè)重要組成部分,MemTable,Immutable MemTable,SSTable (Sorted String Table),如下圖。 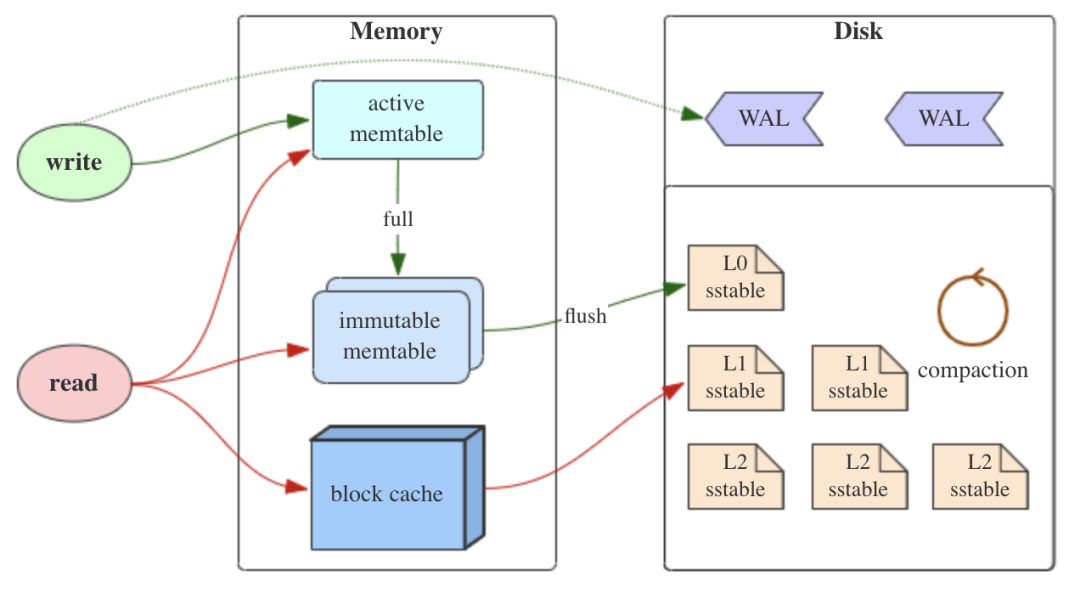 這張經(jīng)典圖片來(lái)自 Flink PMC 的 Stefan Richter 在 Flink Forward 2018 演講的 PPT 這幾個(gè)組成部分分別對(duì)應(yīng) LSM 樹(shù)的不同層次,不同層級(jí)間數(shù)據(jù)轉(zhuǎn)移見(jiàn)下圖。這節(jié)就是介紹 LSM 樹(shù)抽象的不同層的樹(shù)狀數(shù)據(jù)結(jié)構(gòu)的某個(gè)具體實(shí)現(xiàn)方式。
這張經(jīng)典圖片來(lái)自 Flink PMC 的 Stefan Richter 在 Flink Forward 2018 演講的 PPT 這幾個(gè)組成部分分別對(duì)應(yīng) LSM 樹(shù)的不同層次,不同層級(jí)間數(shù)據(jù)轉(zhuǎn)移見(jiàn)下圖。這節(jié)就是介紹 LSM 樹(shù)抽象的不同層的樹(shù)狀數(shù)據(jù)結(jié)構(gòu)的某個(gè)具體實(shí)現(xiàn)方式。 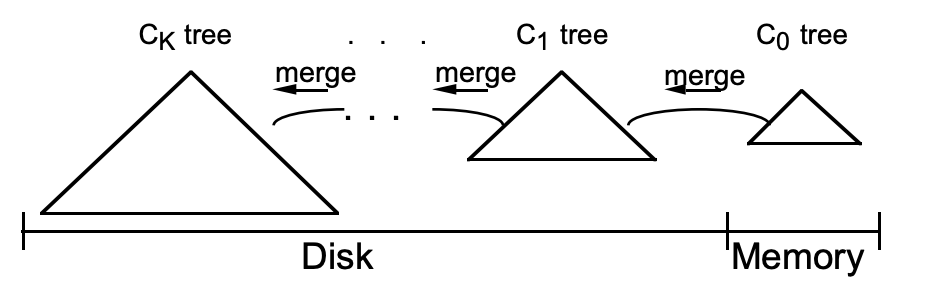
3.1 MemTable
MemTable 是在內(nèi)存中的數(shù)據(jù)結(jié)構(gòu),用于保存最近更新的數(shù)據(jù),會(huì)按照 Key 有序地組織這些數(shù)據(jù)。LSM 樹(shù)對(duì)于具體如何組織有序地組織數(shù)據(jù)并沒(méi)有明確的數(shù)據(jù)結(jié)構(gòu)定義,例如你可以任意選擇紅黑樹(shù)、跳表等數(shù)據(jù)結(jié)構(gòu)來(lái)保證內(nèi)存中 key 的有序。
3.2 Immutable MemTable
為了使內(nèi)存數(shù)據(jù)持久化到磁盤(pán)時(shí)不阻塞數(shù)據(jù)的更新操作,在 MemTable 變?yōu)?SSTable 中間加了一個(gè) Immutable MemTable。
當(dāng) MemTable 達(dá)到一定大小后,會(huì)轉(zhuǎn)化成 Immutable MemTable,并加入到 Immutable MemTable 隊(duì)列尾部,然后會(huì)有任務(wù)從 Immutable MemTable 隊(duì)列頭部取出 Immutable MemTable 并持久化磁盤(pán)里。
3.3 SSTable(Sorted String Table)
有序鍵值對(duì)集合,是 LSM 樹(shù)組在磁盤(pán)中的數(shù)據(jù)結(jié)構(gòu)。
其文件結(jié)構(gòu)基本思路就是先劃分為數(shù)據(jù)塊 (類(lèi)似于 mysql 中的頁(yè)),然后再為數(shù)據(jù)塊建立索引,索引項(xiàng)放在文件末尾,并用布隆過(guò)濾器優(yōu)化查找。
4 LSM 樹(shù)的 Compact 策略
當(dāng)某層數(shù)據(jù)量大小達(dá)到我們預(yù)設(shè)的閾值后,我們就會(huì)通過(guò) Compact 策略將其轉(zhuǎn)化到下一層。 在介紹 Compact 策略前,我們先想想如果讓我們自己設(shè)計(jì) Compact 策略,對(duì)于以下幾個(gè)問(wèn)題,我們?cè)撊绾芜x擇。
對(duì)于某一層的樹(shù),我們用單個(gè)文件還是多個(gè)文件進(jìn)行實(shí)現(xiàn)?
如果是多個(gè)文件,那同一層 SSTable 的 key 范圍是有序還是重合?有序方便讀,重合方便寫(xiě)。
每層 SSTable 的大小以及不同層之間文件大小是否相等。
每層 SSTable 的數(shù)量。如果同一層 key 范圍是重合的,則數(shù)量越多,讀的效率越低。
不同的選擇會(huì)造成不同的讀寫(xiě)策略,基于以上 3 個(gè)問(wèn)題,又帶來(lái)了 3 個(gè)概念:
讀放大:讀取數(shù)據(jù)時(shí)實(shí)際讀取的數(shù)據(jù)量大于真正的數(shù)據(jù)量。例如在 LSM 樹(shù)中可能需要在所有層次的樹(shù)中查看當(dāng)前 key 是否存在。
寫(xiě)放大:寫(xiě)入數(shù)據(jù)時(shí)實(shí)際寫(xiě)入的數(shù)據(jù)量大于真正的數(shù)據(jù)量。例如在 LSM 樹(shù)中寫(xiě)入時(shí)可能觸發(fā) Compact 操作,導(dǎo)致實(shí)際寫(xiě)入的數(shù)據(jù)量遠(yuǎn)大于數(shù)據(jù)的大小。
空間放大:數(shù)據(jù)實(shí)際占用的磁盤(pán)空間比數(shù)據(jù)的真正大小更多。LSM 樹(shù)中同一 key 在不同層次里或者同一層次的不同 SSTable 里可能會(huì)重復(fù)。
不同的策略實(shí)際就是圍繞這三個(gè)概念之間做出權(quán)衡和取舍,我們主要介紹兩種基本策略:size-tiered 策略和 leveled 策略,這兩個(gè)策略對(duì)于以上 3 個(gè)概念做了不同的取舍。
4.1 size-tiered 策略
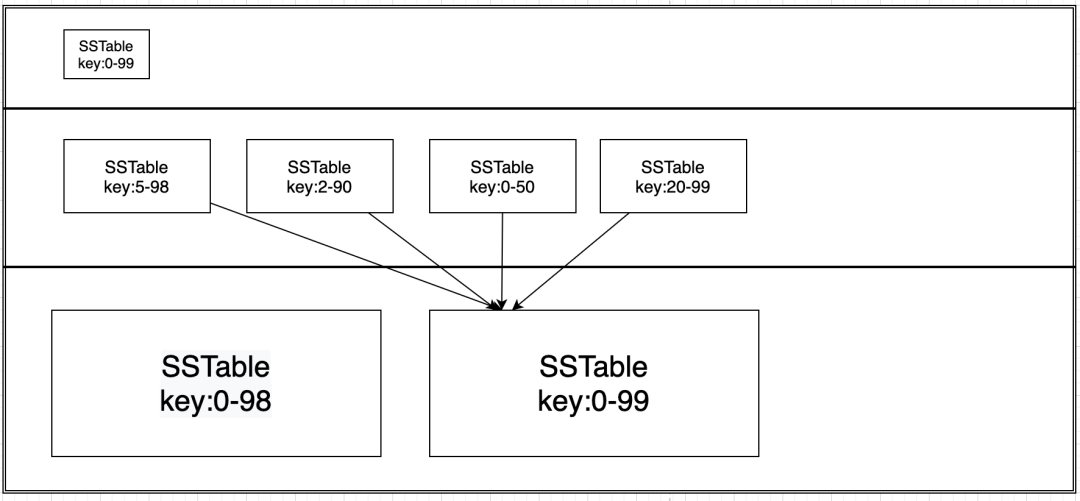
4.1.1 算法
size-tiered 策略每層 SSTable 的大小相近。
當(dāng)每一層 SSTable 的數(shù)量達(dá)到 N 后,則觸發(fā) Compact 操作合并這些 SSTable,并將合并后的結(jié)果寫(xiě)入到一個(gè)更大的 SStable。
新的更大的 SStable 將直接放到下一層 SStable 的隊(duì)尾。所以同一層不同 SStable key 范圍重合,查找時(shí)要從后向前掃描,且最壞情況下可能會(huì)掃描同一層所有 SStable ,這增大了讀放大的問(wèn)題 (之所以說(shuō)增大,是因?yàn)?LSM 樹(shù)不同層之間也有讀放大問(wèn)題)。
4.1.2 總結(jié)
由此可以看出 size-tiered 策略幾個(gè)特點(diǎn):
每層 SSTable 的數(shù)量相近。
當(dāng)層數(shù)達(dá)到一定數(shù)量時(shí),最底層的單個(gè) SSTable 的大小會(huì)變得非常大。
不但不同層之間,哪怕同一層不同 SSTable 之間,key 也可能會(huì)出現(xiàn)重復(fù)。空間放大比較嚴(yán)重。只有當(dāng)該層的 SSTable 執(zhí)行 compact 操作才會(huì)消除這些 key 的冗余記錄。
讀操作時(shí),需要同時(shí)讀取同一層所有 SSTable ,讀放大嚴(yán)重。
4.2 leveled 策略
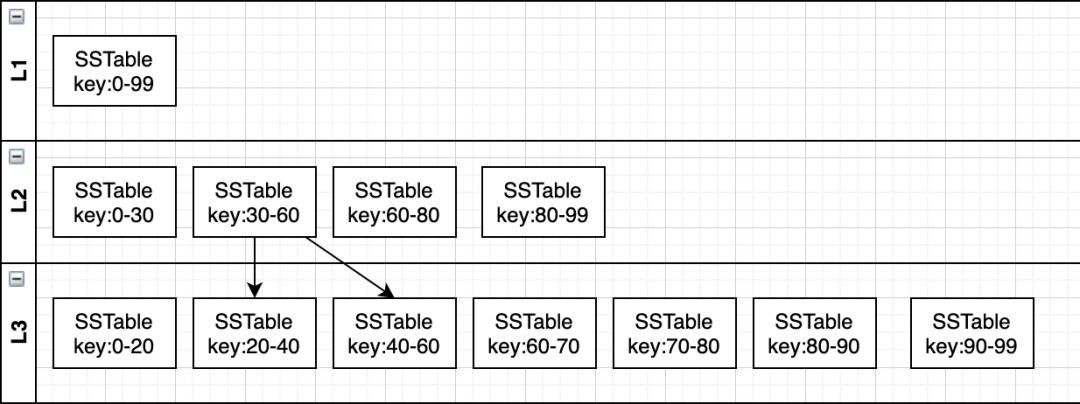
4.2.1 算法
leveled 策略和 size-tiered 策略不同的是,它限制 SSTable 文件的大小,每一層不同 SSTable 文件 key 范圍不重疊且后面的最小 key 大于前一個(gè)文件的最大 key
當(dāng)每一層 SSTable 的總大小達(dá)到閾值 N 后,則觸發(fā) Compact 操作。
首先會(huì)隨機(jī)選擇一個(gè) SSTable 合并到下層,由于下一層 key 是全局有序的,這就要求 leveled 策略 Compact 操作時(shí)需要當(dāng)前 SSTable 和下一層里和當(dāng)前 SSTable key 存在范圍重疊的所有 SSTable 進(jìn)行合并。最壞情況下可能下一層所有 SSTable 都參與合并,這就增大了寫(xiě)放大問(wèn)題 (之所以說(shuō)增大,是因?yàn)?LSM 樹(shù)不同層之間 Compact 也有寫(xiě)放大問(wèn)題)。
4.2.2 總結(jié)
由此可以看出 leveled 策略幾個(gè)特點(diǎn):
不會(huì)出現(xiàn)非常大的 SSTable 文件。
每一層不同 SSTable 文件 key 范圍不重疊。相對(duì)于 size-tiered 策略讀放大更小。
Compact 操作時(shí),需要同時(shí)和下一層 SSTable 一起合并,寫(xiě)放大嚴(yán)重。
5 LSM 樹(shù)的插入、修改、刪除
從 LSM 樹(shù)的名字,Log-Structured-Merge-Tree 日志結(jié)構(gòu)合并樹(shù)中我們大概就能知道 LSM 樹(shù)的插入、修改、刪除的方法了 —— 順序追加而非修改 (對(duì)磁盤(pán)操作而言)。
LSM 樹(shù)的插入、修改、刪除都是在 L0 層的樹(shù)里插入、修改、刪除一條記錄,并記錄記錄項(xiàng)的時(shí)間戳,由于只需要取最新的內(nèi)容即可,所以不需要操作后面層次的樹(shù)。
歷史的插入、修改、刪除的記錄會(huì)在每次 Compact 操作時(shí)被后面的記錄覆蓋。
6 LSM 樹(shù)的查找
由于后面的操作會(huì)覆蓋前面的操作,所以查找只需從 L0 層往下查,直到查到某個(gè) key 的記錄就可以了,之前的記錄不需要再查了。
對(duì)于 size-tiered 策略,同一層 SSTable 需要從后向前遍歷,直到找到符合的索引項(xiàng)。
在查找過(guò)程中也會(huì)使用其他一些手段進(jìn)行優(yōu)化,例如增加緩存、布隆過(guò)濾器等。
7 LSM 樹(shù)和 B+ 樹(shù)的比較
不考慮寫(xiě)日志等操作,插入、修改、刪除一條記錄 B+ 樹(shù)需要先找到數(shù)據(jù)位置,可能需要多次磁盤(pán) IO;LSM 樹(shù)不需要磁盤(pán) IO,單次插入耗時(shí)短,所以其寫(xiě)入的最大吞吐量是高于 B+ 樹(shù)的。
LSM 樹(shù)后面的 Compact 操作也會(huì)操作這條數(shù)據(jù)幾次,總的寫(xiě)入量是大于 B+ 樹(shù)的,但可以通過(guò)將 Compact 操作放到業(yè)務(wù)低峰時(shí)來(lái)降低這個(gè)劣勢(shì)的影響。
查找時(shí), LSM 樹(shù)需要遍歷所有層次的樹(shù),查找效率上要低于 B+ 樹(shù),但 LSM 樹(shù)寫(xiě)入時(shí)節(jié)省的磁盤(pán)資源占用,可以一定程度上彌補(bǔ)讀效率上的差距。
8 總結(jié)
LSM 樹(shù)特點(diǎn):順序?qū)懭搿ompact 操作、讀、寫(xiě)和空間放大。
LSM 樹(shù)適用場(chǎng)景:對(duì)于寫(xiě)操作吞吐量要求很高、讀操作吞吐量要就較高的場(chǎng)景,目前主要在 NoSql 數(shù)據(jù)庫(kù)中用的比較多。
審核編輯:湯梓紅
-
算法
+關(guān)注
關(guān)注
23文章
4612瀏覽量
92886 -
數(shù)據(jù)庫(kù)
+關(guān)注
關(guān)注
7文章
3799瀏覽量
64388 -
數(shù)據(jù)結(jié)構(gòu)
+關(guān)注
關(guān)注
3文章
573瀏覽量
40130 -
存儲(chǔ)結(jié)構(gòu)
+關(guān)注
關(guān)注
0文章
21瀏覽量
9717 -
底層存儲(chǔ)
+關(guān)注
關(guān)注
0文章
2瀏覽量
5382
原文標(biāo)題:TiDB底層存儲(chǔ)結(jié)構(gòu)LSM樹(shù)原理介紹
文章出處:【微信號(hào):OSC開(kāi)源社區(qū),微信公眾號(hào):OSC開(kāi)源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
樹(shù)的遞歸結(jié)構(gòu)和樹(shù)的存儲(chǔ)結(jié)構(gòu)分析
MySQL數(shù)據(jù)庫(kù)索引的底層是怎么實(shí)現(xiàn)的
Hypertable底層存儲(chǔ)結(jié)構(gòu)分析
基于KD樹(shù)和R樹(shù)的多維索引結(jié)構(gòu)

Linux 內(nèi)核里的數(shù)據(jù)結(jié)構(gòu)關(guān)鍵:基數(shù)樹(shù)
如何存儲(chǔ)Merkle樹(shù)
新數(shù)據(jù)結(jié)構(gòu)“樹(shù)”的詳細(xì)介紹
數(shù)據(jù)結(jié)構(gòu)字典樹(shù)的實(shí)現(xiàn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論