") TensorFlow和PyTorch的實際應(yīng)用比較
TensorFlow和PyTorch的實際應(yīng)用比較
TensorFlow和PyTorch是兩個最受歡迎的開源深度學(xué)習(xí)框架,這兩個框架都為構(gòu)建和訓(xùn)練深度學(xué)習(xí)模型提供了廣泛的功能,并已被研發(fā)社區(qū)廣泛采用。但是作為用戶,我們一直想知道哪種框架最適合我們自己特定項目,所以在本文與其他文章的特性的對比不同,我們將以實際應(yīng)用出發(fā),從性能、可伸縮性和其他高級特性方面比較TensorFlow和PyTorch。
01性能
在選擇深度學(xué)習(xí)框架時,一個關(guān)鍵的考慮因素是你構(gòu)建和訓(xùn)練的模型的性能。
TensorFlow和PyTorch都進行了性能優(yōu)化,這兩個框架都提供了大量的工具和技術(shù)來提高模型的速度。
就原始性能而言,TensorFlow比PyTorch更好一些。這兩個框架之間的一個關(guān)鍵區(qū)別是使用靜態(tài)計算圖而不是動態(tài)計算圖。在TensorFlow中,在模型訓(xùn)練之前,計算圖是靜態(tài)構(gòu)造的。這使得TensorFlow可以通過分析圖并應(yīng)用各種優(yōu)化技術(shù)來更有效地優(yōu)化圖的性能。
而PyTorch使用動態(tài)計算圖,這意味著圖是在訓(xùn)練模型時動態(tài)構(gòu)建的。雖然這可能更靈活,更容易使用,但在某些情況下也可能效率較低。
但是記住這一點很重要
TensorFlow和PyTorch之間的性能差異相非常小,這是因為這兩個框架都對性能進行了優(yōu)化,并提供了許多工具和方法來提高模型的速度,在很多情況下根本發(fā)現(xiàn)不了他們的區(qū)別。
除了使用靜態(tài)與動態(tài)計算圖之外,還有許多其他因素會影響模型的性能。這些因素包括硬件和軟件環(huán)境的選擇、模型的復(fù)雜性以及數(shù)據(jù)集的大小。通過考慮這些因素并根據(jù)需要應(yīng)用優(yōu)化技術(shù),可以使用TensorFlow或PyTorch構(gòu)建和訓(xùn)練高性能模型。
除了原始性能,TensorFlow和PyTorch都提供了大量的工具和方法來提高模型的速度:
TensorFlow提供了多種優(yōu)化方法,可以極大地提高模型的性能,例如自動混合精度和XLA。
XLA(加速線性代數(shù)):TensorFlow包括一個稱為XLA的即時(JIT)編譯器,它可以通過應(yīng)用多種優(yōu)化技術(shù)來優(yōu)化模型的性能,包括常數(shù)折疊、代數(shù)簡化和循環(huán)融合。要啟用XLA,可以使用tf.config.optimizer.set_jit函數(shù)。
TFX (TensorFlow Extended): TFX是一套用于構(gòu)建和部署機器學(xué)習(xí)管道的庫和工具,包括用于數(shù)據(jù)處理、模型訓(xùn)練和模型服務(wù)的工具。TFX可以通過自動化所涉及的許多步驟,更有效地構(gòu)建和部署機器學(xué)習(xí)模型。
tf.function函數(shù)裝飾器可以將TensorFlow函數(shù)編譯成一個圖,這可能比強制執(zhí)行函數(shù)更快,可以利用TensorFlow的優(yōu)化技術(shù)來提高模型的性能。
PyTorch通過使用torch.autograd 和torch.jit等提供了優(yōu)化模型的方法,它提高模型的有效性
torch.autograd.profiler:通過跟蹤 PyTorch 模型的各種元素使用的時間和內(nèi)存量,可以幫助找到瓶頸和代碼中需要改進的地方。
torch.nn.DataParallel:torch.nn.DataParallel 類可跨多個設(shè)備(例如 GPU)并行訓(xùn)練 PyTorch 模型。通過使用 DataParallel,可以利用多個設(shè)備來增加模型的推理效率。
torch.jit:使用即時 (JIT) 編譯器優(yōu)化 PyTorch 模型。torch.jit 將模型編譯成靜態(tài)計算圖,與動態(tài)圖相比可以更有效地進行優(yōu)化。
靜態(tài)與動態(tài)計算圖定義的編碼示例:
如前所述,TensorFlow在原始性能方面比PyTorch略有優(yōu)勢,這是由于它的靜態(tài)計算圖。
下面是一個在TensorFlow中構(gòu)建前饋神經(jīng)網(wǎng)絡(luò)的簡單例子:
import tensorflow as tf
# Define the model
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(64,)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# Compile the model
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Fit the model
model.fit(x_train, y_train, epochs=5)
下面是在PyTorch中實現(xiàn)和訓(xùn)練的相同模型:
import torch
import torch.nn as nn
import torch.optim as optim
# Define the model
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(64, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
# Create the model instance
model = Net()
# Define the loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
# Training loop
for epoch in range(5):
# Forward pass
output = model(x_train)
loss = criterion(output, y_train)
# Backward pass and optimization step
optimizer.zero_grad()
loss.backward()
optimizer.step()
這兩個例子都展示了如何構(gòu)建和訓(xùn)練一個簡單的前饋神經(jīng)網(wǎng)絡(luò),雖然方法不同但是他們的性能基本卻相同。對于性能的對比,目前來說兩個框架基本相同,差異可以忽略不計。
02可伸縮性
在選擇深度學(xué)習(xí)框架時,另一個重要考慮因素是可伸縮性。隨著模型的復(fù)雜性和規(guī)模的增長,需要一個能夠處理不斷增長的計算需求的框架。
這兩個框架都提供了擴展模型的策略,但它們處理問題的方式略有不同。
TensorFlow在設(shè)計時考慮了可伸縮性,并提供了許多用于分布式訓(xùn)練和部署的工具。
例如,TensorFlow 的 tf. distribute API 可以輕松地跨多個設(shè)備和服務(wù)器分發(fā)訓(xùn)練,而 TensorFlow Serving 可以將經(jīng)過訓(xùn)練的模型部署到生產(chǎn)環(huán)境。
PyTorch也提供用于分布式培訓(xùn)和部署的工具,但重點更多地放在研究和開發(fā)上,而不是生產(chǎn)環(huán)境。
PyTorch 的 torch.nn.DataParallel 和 torch.nn.parallel.DistributedDataParallel 類可以跨多個設(shè)備并行訓(xùn)練,而 PyTorch Lightning 庫(非官方)為分布式訓(xùn)練和部署提供了一個高級接口。
TensorFlow
tf.distribute.Strategy:tf.distribute.Strategy API 可跨多個設(shè)備和機器并行訓(xùn)練 TensorFlow 模型。有許多不同的策略可用,包括 tf.distribute.MirroredStrategy,它支持在單臺機器上的多個 GPU 上進行訓(xùn)練,以及 tf.distribute.experimental.MultiWorkerMirroredStrategy,它在具有多個 GPU 的多臺機器上提供訓(xùn)練。
tf.data.Dataset:可以為訓(xùn)練構(gòu)建了高效且高度并行化的數(shù)據(jù)管道。通過使用 tf.data.Dataset,可以輕松地并行加載和預(yù)處理大型數(shù)據(jù)集,這可以模型擴展到更大的數(shù)據(jù)集。
tf.keras.layers.Normalization:tf.keras.layers.Normalization 層實時規(guī)范化輸入數(shù)據(jù),這可能有助于提高模型的性能。應(yīng)用歸一化可以減少大輸入值的影響,這可以幫助模型更快地收斂并獲得更好的性能。
tf.data.Dataset.interleave:通過對數(shù)據(jù)并行應(yīng)用函數(shù),再次并行處理輸入數(shù)據(jù)。這對于數(shù)據(jù)預(yù)處理等任務(wù)非常有用,在這些任務(wù)中您需要對數(shù)據(jù)應(yīng)用大量轉(zhuǎn)換。
Pytorch
torch.nn.parallel.DistributedDataParallel:torch.nn.parallel.DistributedDataParallel 類在多個設(shè)備和機器上并行訓(xùn)練 PyTorch 模型。但是需要使用torch.nn.parallel.DistributedDataParallel.init_process_group 設(shè)置分布式訓(xùn)練環(huán)境。
torch.utils.data.DataLoader:創(chuàng)建一個數(shù)據(jù)迭代器,用于并行處理數(shù)據(jù)的加載和預(yù)處理。
torch.utils.data.distributed.DistributedSampler:類似于 torch.utils.data.DistributedSampler,但設(shè)計用于與 DistributedDataParallel 類一起使用。通過使用 DistributedSampler,可以確保在使用DistributedDataParallel 進行訓(xùn)練時,每個設(shè)備都會收到平衡的數(shù)據(jù)樣本。
通過利用這些函數(shù)和類,可以將 TensorFlow 和 PyTorch 模型擴展到更大的數(shù)據(jù)集和更強大的硬件,構(gòu)建更準(zhǔn)確、更強大的模型。
下面介紹了提高可伸縮性的兩種不同方法。
TensorFlow的第一個例子使用了tf.distribute. mirrredstrategy:
import tensorflow as tf
# Define the model
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(64,)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# Compile the model
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Define the distribution strategy
strategy = tf.distribute.MirroredStrategy()
# Load the dataset
dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(64)
# Define the training loop
with strategy.scope():
for epoch in range(5):
for x_batch, y_batch in dataset:
model.fit(x_batch, y_batch)
在PyTorch使用 torch.nn.DataParallel :
import torch
import torch.nn as nn
import torch.optim as optim
# Define the model
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(64, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
# Create the model instance and wrap it in DataParallel
model = nn.DataParallel(Net())
# Define the loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
# Training loop
for epoch in range(5):
# Forward pass
output = model(x_train)
loss = criterion(output, y_train)
# Backward pass and optimization step
optimizer.zero_grad()
loss.backward()
optimizer.step()
這兩個例子都展示了如何在多個設(shè)備上并行訓(xùn)練,但TensorFlow對于分布式訓(xùn)練的支持要比Pytorch更好一些。
03高級的特性
除了性能和可伸縮性之外,這兩個框架還提供了許多項目相關(guān)的高級特性。
例如,TensorFlow擁有強大的工具和庫生態(tài)系統(tǒng),包括用于可視化的TensorBoard和用于模型部署和服務(wù)的TensorFlow Extended。
PyTorch也多個高級特性,一般都會命名為 torchXXX,比如torchvision,torchaudio等等
我們以TensorBoard為例介紹兩個庫的使用,雖然TensorBoard是TensorFlow的一部分,但是Pytorch也通過代碼部分兼容了數(shù)據(jù)部分的發(fā)送,也就是說使用Pytorch也可以往TensorBoard寫入數(shù)據(jù),然后通過TensorBoard進行查看。
TensorFlow 在訓(xùn)練時使用TensorBoard的callback可以自動寫入。
import tensorflow as tf
# Define the model
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(64,)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# Compile the model
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Define a TensorBoard callback
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir='logs')
# Fit the model
model.fit(x_train, y_train, epochs=5, callbacks=[tensorboard_callback])
Pytorch需要自行代碼寫入:
import numpy as np
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(comment='test_tensorboard')
for x in range(100):
writer.add_scalar('y=2x', x * 2, x)
writer.add_scalar('y=pow(2, x)', 2 ** x, x)
writer.add_scalars('data/scalar_group', {"xsinx": x * np.sin(x),
"xcosx": x * np.cos(x),
"arctanx": np.arctan(x)}, x)
writer.close()
在高級特性中我覺得最主要的就是TensorFlow 中引入了Keras,這樣只需要幾行代碼就可以完成完整的模型訓(xùn)練
# Compile the model
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
而Pytorch還要手動進行損失計算,反向傳播
output = model(x_train)
loss = criterion(output, y_train)
# Backward pass and optimization step
optimizer.zero_grad()
loss.backward()
optimizer.step()
雖然這樣靈活性很高,但是應(yīng)該有一個像Keras這樣的通用方法(TensorFlow 也可以手動指定計算過程,并不是沒有),所以在這一部分中我覺得TensorFlow要比Pytorch好很多。
當(dāng)然也有一些第三方的庫來簡化Pytorch的訓(xùn)練過程比如PyTorch Lightning、TorchHandle等但是終究不是官方的庫。
04 最后總結(jié)
最適合你的深度學(xué)習(xí)框架將取決于你的具體需求和要求
TensorFlow 和 PyTorch 都提供了廣泛的功能和高級特性,并且這兩個框架都已被研發(fā)社區(qū)廣泛采用。作為高級用戶,我的個人建議是深入學(xué)習(xí)一個庫,另外一個庫代碼基本上是類似的,基礎(chǔ)到了基本上做到能看懂就可以了,比如
class DNNModel(nn.Module):
def __init__(self):
super(DNNModel, self).__init__()
self.fc1 = nn.Linear(2,4)
self.fc2 = nn.Linear(4,8)
self.fc3 = nn.Linear(8,1)
# 正向傳播
def forward(self,x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
y = nn.Sigmoid()(self.fc3(x))
return y
################
class DNNModel(models.Model):
def __init__(self):
super(DNNModel, self).__init__()
def build(self,input_shape):
self.dense1 = layers.Dense(4,activation = "relu",name = "dense1")
self.dense2 = layers.Dense(8,activation = "relu",name = "dense2")
self.dense3 = layers.Dense(1,activation = "sigmoid",name = "dense3")
super(DNNModel,self).build(input_shape)
# 正向傳播
@tf.function(input_signature=[tf.TensorSpec(shape = [None,2], dtype = tf.float32)])
def call(self,x):
x = self.dense1(x)
x = self.dense2(x)
y = self.dense3(x)
return y
看看上面代碼的兩個類它們的區(qū)別并不大,對吧。
下面是google trends的趨勢對比,我們可以看到明顯的區(qū)別
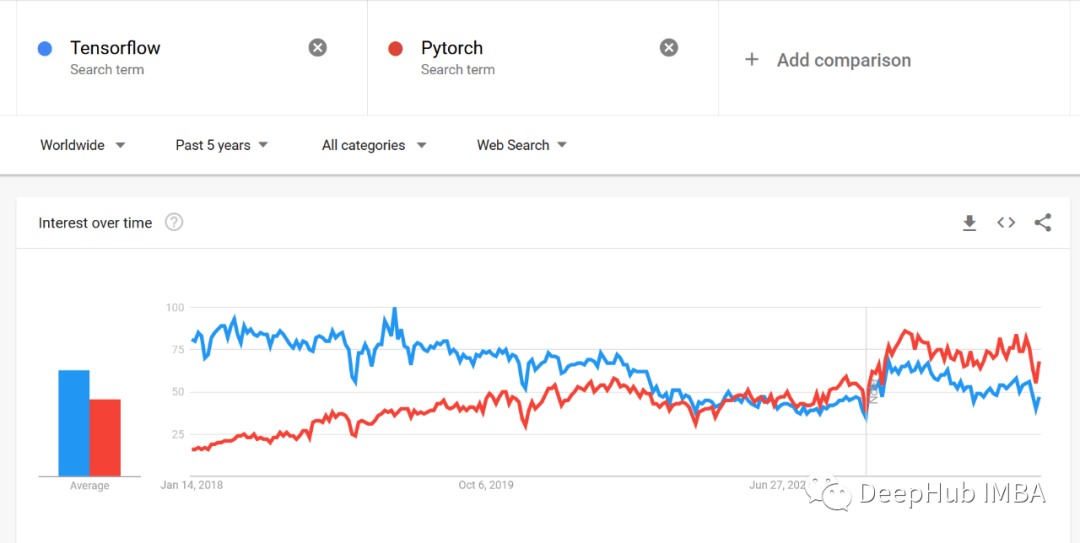
審核編輯:湯梓紅
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4771瀏覽量
100766 -
開源
+關(guān)注
關(guān)注
3文章
3349瀏覽量
42499 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5503瀏覽量
121162 -
tensorflow
+關(guān)注
關(guān)注
13文章
329瀏覽量
60536 -
pytorch
+關(guān)注
關(guān)注
2文章
808瀏覽量
13226
原文標(biāo)題:【光電智造】TensorFlow和PyTorch的實際應(yīng)用比較
文章出處:【微信號:今日光電,微信公眾號:今日光電】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
TensorFlow、PyTorch,“后浪”O(jiān)neFlow 有沒有機會
在Ubuntu 18.04 for Arm上運行的TensorFlow和PyTorch的Docker映像
S32G-GoldVip上的Pytorch和Tensorflow如何啟用?
什么是張量,如何在PyTorch中操作張量?
PyTorch可以和TensorFlow一樣快,有時甚至比TensorFlow更快了?
tensorflow和python的關(guān)系_tensorflow與pytorch的區(qū)別
PyTorch1.8和Tensorflow2.5該如何選擇?
TensorFlow的衰落與PyTorch的崛起
深度學(xué)習(xí)框架PyTorch和TensorFlow如何選擇
PyTorch與TensorFlow的優(yōu)點和缺點






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論