 TransGeo:第一種用于交叉視圖圖像地理定位的純Transformer方法
TransGeo:第一種用于交叉視圖圖像地理定位的純Transformer方法
主要內容:
提出了第一種用于交叉視圖圖像地理定位的純Transformer方法,在對齊和未對齊的數據集上都實現了最先進的結果,與基于CNN的方法相比,計算成本更低,所提出的方法不依賴于極坐標變換和數據增強,具有通用性和靈活性。
論文出發點:
基于CNN的交叉視圖圖像地理定位主要依賴于極坐標變換,無法對全局相關性進行建模,為了解決這些限制,論文提出的算法利用Transformer在全局信息建模和顯式位置信息編碼方面的優勢,還進一步利用Transformer輸入的靈活性,提出了一種注意力引導的非均勻裁剪方法去除無信息的圖像塊,性能下降可以忽略不計,從而降低了計算成本,節省下來的計算可以重新分配來提高信息patch的分辨率,從而在不增加額外計算成本的情況下提高性能。
這種“關注并放大”策略與觀察圖像時的人類行為高度相似。
圖像地理定位(名詞解釋):
基于圖像的地理定位旨在通過檢索GPS標記的參考數據庫中最相似的圖像來確定查詢圖像的位置,其應用在大城市環境中改善具有大的噪聲GPS和導航,在Transformer出現之前,通常使用度量學習損失來訓練雙通道CNN框架,但是這樣交叉視圖檢索系統在街道視圖和鳥瞰視圖之間存在很大的領域差距,因為CNN不能明確編碼每個視圖的位置信息,之后為了改善域間隙,算法在鳥瞰圖像上應用預定義的極坐標變換,變換后的航空圖像具有與街景查詢圖像相似的幾何布局,然而極坐標變換依賴于與兩個視圖相對應的幾何體的先驗知識,并且當街道查詢在空間上未在航空圖像的中心對齊時,極坐標轉換可能會失敗。
Contribution:
提出了第一種基于Transformer的方法用于交叉視圖圖像地理定位,無需依賴極坐標變換或數據增強。
提出了一種注意力引導的非均勻裁剪策略,去除參考航空圖像中的大量非信息補丁以減少計算量,性能下降可忽略不計,通過將省下來的計算資源重新分配到信息patch的更高圖像分辨率進一步提高了性能。
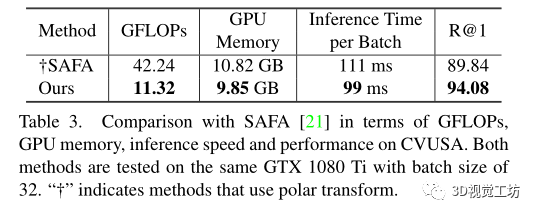
與基于CNN的方法相比,在數據集上的最先進性能具有更低的計算成本、GPU內存消耗和推理時間。
網絡架構:
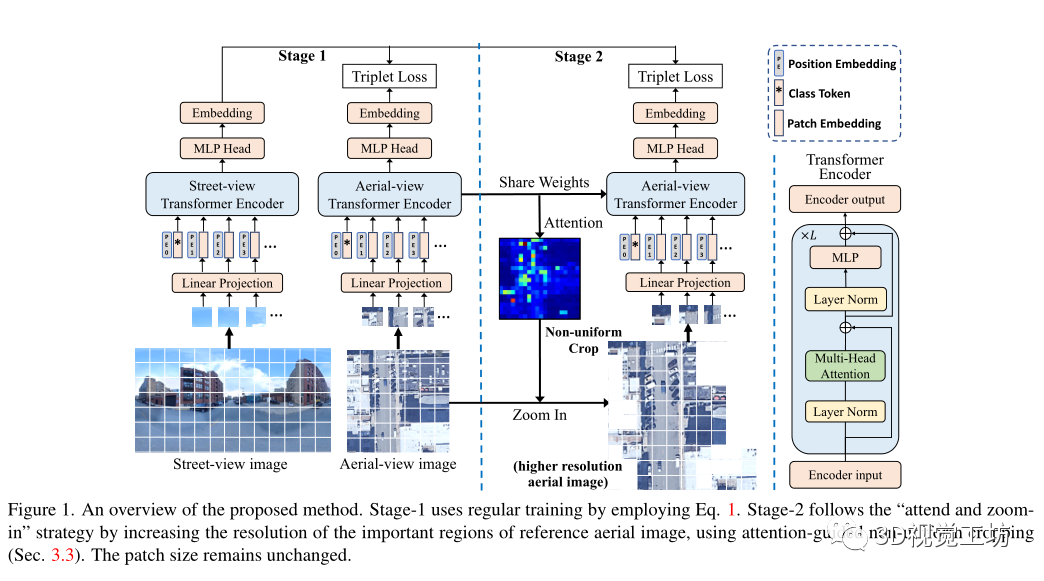

Patch Embedding:

Class Token:
最后一層輸出的類token被送到一個MLP頭以生成最終的分類向量,使用最終輸出向量作為嵌入特征,并使用上面說的損失對其進行訓練。
可學習的位置嵌入:
位置嵌入被添加到每個token以保持位置信息,采用了可學習的位置嵌入,這是包括class token在內的所有(N+1)token的可學習矩陣,可學習的位置嵌入使雙通道Transformer能夠學習每個視圖的最佳位置編碼,而無需任何關于幾何對應的先驗知識,因此比基于CNN的方法更通用和靈活。
多頭注意力:
Transformer編碼器內部架構是L個級聯的基本Transformer,關鍵組成部分是多頭注意力塊,它首先使用三個可學習的線性投影將輸入轉換為查詢、鍵和值,表示為Q、K、V,維度為D,然后將注意力輸出計算為
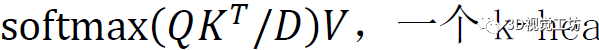
,一個k-head注意力塊用k個不同的head對Q、k、V進行線性投影,然后對所有k個head并行執行attention,輸出被連接并投影回模型維度D,多頭注意力可以模擬從第一層開始的任意兩個標記之間的強全局相關性,這在CNN中是不可能學習的,因為卷積的接受域有限。
Attention引導的非均勻裁剪:
當尋找圖像匹配的線索時,人類通常會第一眼找到最重要的區域,然后只關注重要的區域并放大以找到高分辨率的更多細節,把“關注并放大”的思想用在交叉圖像地理定位中可能更有益,因為兩個視圖只共享少量可見區域,一個視圖中的大量區域,例如鳥瞰圖中的高樓屋頂,在另一個視圖可能看不見,這些區域對最終相似性的貢獻微不足道,可以去除這些區域以減少計算和存儲成本,然而重要的區域通常分散在圖像上,因此CNN中的均勻裁剪不能去除分散的區域,因此提出了注意力引導的非均勻裁剪

在鳥瞰分支的最后一個transformer編碼器中使用注意力圖,它代表了每個token對最終輸出的貢獻,由于只有class token對應的輸出與MLP head連接,因此選擇class token與所有其他patch token之間的相關性作為注意力圖,并將其重塑為原始圖像形狀。
模型優化:
為了在沒有數據增強的情況下訓練Transformer模型,采用了正則化/泛化技術ASAM。在優化損失時使用ASAM來最小化損失landscape的自適應銳度使得該模型以平滑的損失曲率收斂以實現強大的泛化能力。
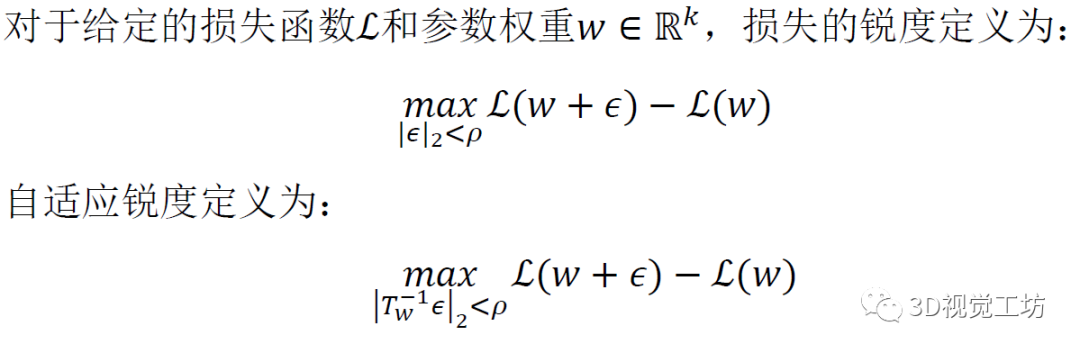
通過同時最小化的損失和自適應銳度,能夠在不使用任何數據增強的情況下克服過擬合問題
實驗:
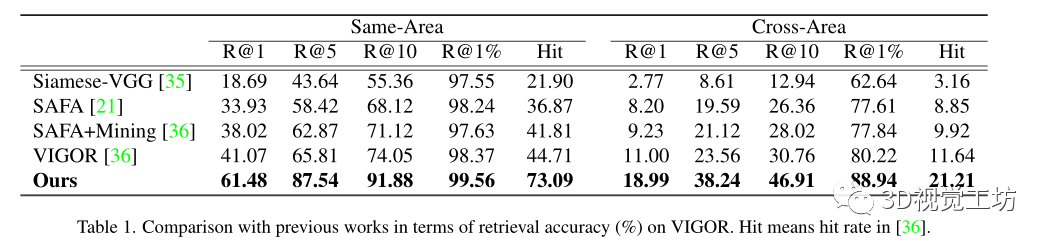
在兩個城市規模的數據集上進行了實驗,即CVUSA和VIGOR,分別代表了空間對齊和非對齊設置
評估度量:在top-k召回準確率,表示為“R@k”,基于每個查詢的余弦相似度檢索嵌入空間中的k個最近參考鄰居,如果地面真實參考圖像出現在前k個檢索圖像中,則認為其正確。
預測GPS位置和地面真實GPS位置之間的真實世界距離作為VIGOR數據集上的米級別的評估。
命中率,即覆蓋查詢圖像(包括地面真相)的前1個檢索參考圖像的百分比
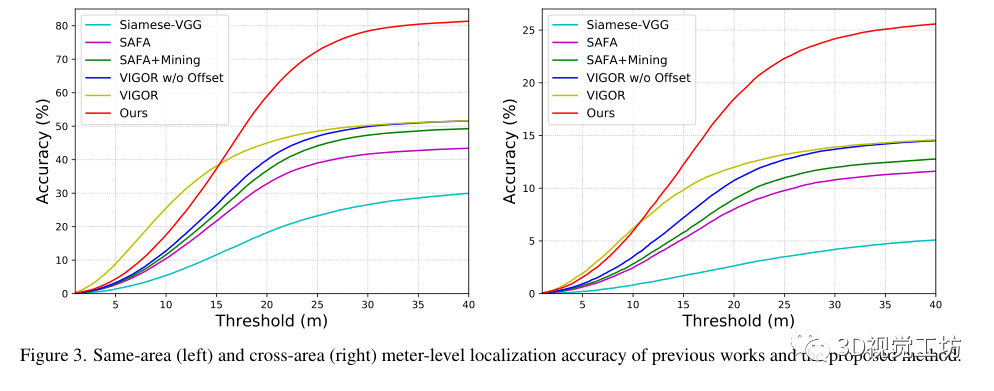
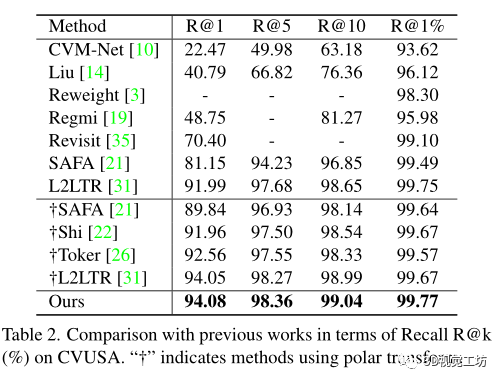
和之前SOTA方法SAFA在計算代價上的比較
總結:
提出了第一種用于交叉視圖圖像地理定位的純Transformer方法,在對齊和未對齊的數據集上都實現了最先進的結果,與基于CNN的方法相比,計算成本更低。
缺點是使用兩個管道,且patch選擇簡單地使用不可通過參數學習的注意力圖。
審核編輯 :李倩
-
圖像
+關注
關注
2文章
1088瀏覽量
40515 -
數據集
+關注
關注
4文章
1208瀏覽量
24749 -
cnn
+關注
關注
3文章
353瀏覽量
22267
原文標題:CVPR 2022 | TransGeo:第一種用于交叉視圖圖像地理定位的純Transformer方法
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
transformer專用ASIC芯片Sohu說明

Mamba入局圖像復原,達成新SOTA

自動駕駛中一直說的BEV+Transformer到底是個啥?

SegVG視覺定位方法的各個組件
一種將NeRFs應用于視覺定位任務的新方法

機器學習中的交叉驗證方法
地下金屬電纜故障定位儀的管線探測方法——每日了解電力知識

交叉導軌維護和保養的方法






 工商網監
工商網監
評論