") NVIDIA Triton 系列文章(11):模型類別與調度器-2
NVIDIA Triton 系列文章(11):模型類別與調度器-2
在上篇文章中,已經(jīng)說明了有狀態(tài)(stateful)模型的“控制輸入”與“隱式狀態(tài)管理”的使用方式,本文內容接著就繼續(xù)說明“調度策略”的使用。
(續(xù)前一篇文章的編號)
(3) 調度策略(Scheduling Strategies)在決定如何對分發(fā)到同一模型實例的序列進行批處理時,序列批量處理器(sequence batcher)可以采用以下兩種調度策略的其中一種:
現(xiàn)在簡單說明以下配置的內容: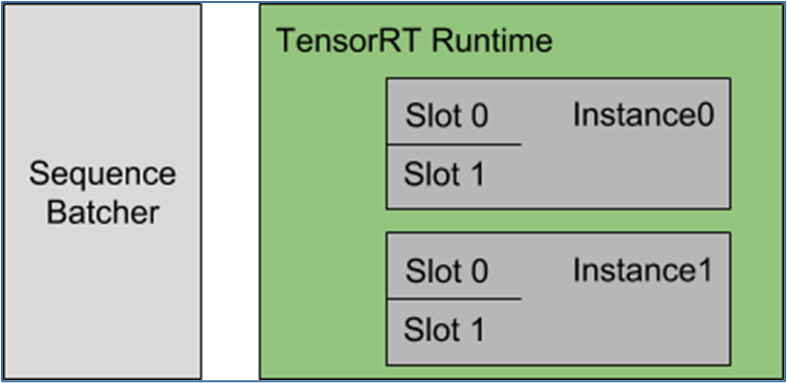 每個模型實例都在維護每個批處理槽的狀態(tài),并期望將給定序列的所有推理請求分發(fā)到同一槽,以便正確更新狀態(tài)。對于本例,這意味著 Triton 可以同時 4 個序列進行推理。
使用直接調度策略,序列批處理程序會執(zhí)行以下動作:
每個模型實例都在維護每個批處理槽的狀態(tài),并期望將給定序列的所有推理請求分發(fā)到同一槽,以便正確更新狀態(tài)。對于本例,這意味著 Triton 可以同時 4 個序列進行推理。
使用直接調度策略,序列批處理程序會執(zhí)行以下動作:
下圖顯示使用直接調度策略,將多個序列調度到模型實例上的執(zhí)行:
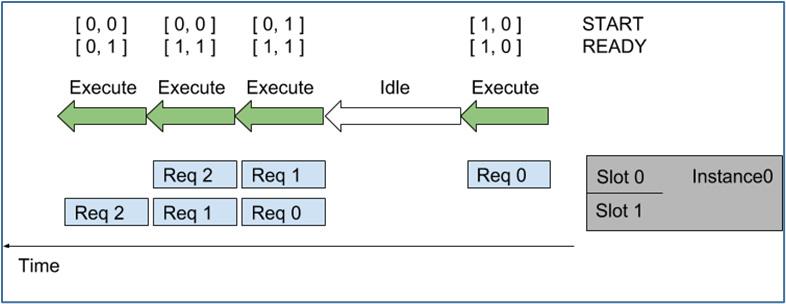
 圖左顯示了到達 Triton 的 5 個請求序列,每個序列可以由任意數(shù)量的推理請求組成。圖右側顯示了推理請求序列是如何隨時間安排到模型實例上的,
圖左顯示了到達 Triton 的 5 個請求序列,每個序列可以由任意數(shù)量的推理請求組成。圖右側顯示了推理請求序列是如何隨時間安排到模型實例上的,
 ?隨著時間的推移(從右向左),會發(fā)生以下情況:
?隨著時間的推移(從右向左),會發(fā)生以下情況:
在本示例中,模型需要序列批量處理的開始、結束和相關 ID 控制輸入。下圖顯示了此配置指定的序列批處理程序和推理資源的表示。
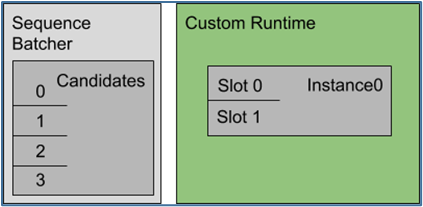 使用最舊的調度策略,序列批處理程序會執(zhí)行以下工作:
使用最舊的調度策略,序列批處理程序會執(zhí)行以下工作:
下圖顯示將多個序列調度到上述示例配置指定的模型實例上,左圖顯示 Triton 接收了四個請求序列,每個序列由多個推理請求組成:
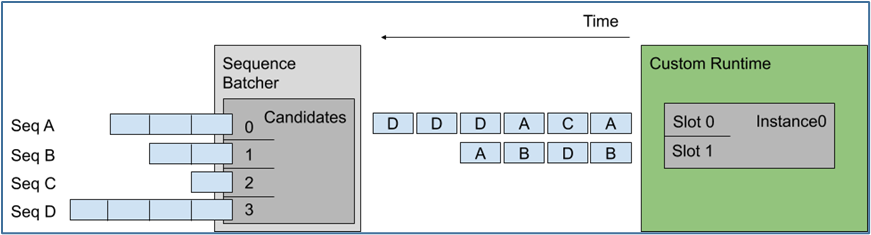 這里假設每個請求的長度是相同的,那么左邊候選序列中送進右邊批量處理槽的順序,就是上圖中間的排列順序。
最舊的策略從最舊的請求中形成一個動態(tài)批處理,但在一個批處理中從不包含來自給定序列的多個請求,例如上面序列 D 中的最后兩個推理不是一起批處理的。
以上是關于有狀態(tài)模型的“調度策略”主要內容,剩下的“集成模型”部分,會在下篇文章中提供完整的說明。
這里假設每個請求的長度是相同的,那么左邊候選序列中送進右邊批量處理槽的順序,就是上圖中間的排列順序。
最舊的策略從最舊的請求中形成一個動態(tài)批處理,但在一個批處理中從不包含來自給定序列的多個請求,例如上面序列 D 中的最后兩個推理不是一起批處理的。
以上是關于有狀態(tài)模型的“調度策略”主要內容,剩下的“集成模型”部分,會在下篇文章中提供完整的說明。
- 直接(direct)策略
| name: "direct_stateful_model"platform: "tensorrt_plan"max_batch_size: 2sequence_batching{ max_sequence_idle_microseconds: 5000000direct { } control_input [{name: "START" control [{ kind: CONTROL_SEQUENCE_START fp32_false_true: [ 0, 1 ]}]},{name: "READY" control [{ kind: CONTROL_SEQUENCE_READY fp32_false_true: [ 0, 1 ]}]}]}#續(xù)接右欄 | #上接左欄input [{name: "INPUT" data_type: TYPE_FP32dims: [ 100, 100 ]}]output [{name: "OUTPUT" data_type: TYPE_FP32dims: [ 10 ]}]instance_group [{ count: 2}] |
- sequence_batching 部分指示模型會使用序列調度器的 Direct 調度策略;
- 示例中模型只需要序列批處理程序的啟動和就緒控制輸入,因此只列出這些控制;
- instance_group 表示應該實例化模型的兩個實例;
- max_batch_size 表示這些實例中的每一個都應該執(zhí)行批量大小為 2 的推理計算。
每個模型實例都在維護每個批處理槽的狀態(tài),并期望將給定序列的所有推理請求分發(fā)到同一槽,以便正確更新狀態(tài)。對于本例,這意味著 Triton 可以同時 4 個序列進行推理。
使用直接調度策略,序列批處理程序會執(zhí)行以下動作:
| 所識別的推理請求種類 | 執(zhí)行動作 |
| 需要啟動新序列 | 1. 有可用處理槽時:就為該序列分配批處理槽2. 無可用處理槽時:就將推理請求放在積壓工作中 |
| 是已分配處理槽序列的一部分 | 將該請求分發(fā)到該配置好的批量處理槽 |
| 是積壓工作中序列的一部分 | 將請求放入積壓工作中 |
| 是最后一個推理請求 | 1. 有積壓工作時:將處理槽分配給積壓工作的序列2. 有積壓工作:釋放該序列處理槽給其他序列使用 |
圖左顯示了到達 Triton 的 5 個請求序列,每個序列可以由任意數(shù)量的推理請求組成。圖右側顯示了推理請求序列是如何隨時間安排到模型實例上的,
- 在實例 0 與實例 1 中各有兩個槽 0 與槽 1;
- 根據(jù)接收的順序,為序列 0 至序列 3 各分配一個批量處理槽,而序列 4 與序列 5 先處于排隊等候狀態(tài);
- 當序列 3 的請求全部完成之后,將處理槽釋放出來給序列 4 使用;
- 當序列 1 的請求全部完成之后,將處理槽釋放出來給序列 5 使用;
?隨著時間的推移(從右向左),會發(fā)生以下情況:- 序列中第一個請求(Req 0)到達槽 0 時,因為模型實例尚未執(zhí)行推理,則序列調度器會立即安排模型實例執(zhí)行,因為推理請求可用;
- 由于這是序列中的第一個請求,因此 START 張量中的對應元素設置為 1,但槽 1 中沒有可用的請求,因此 READY 張量僅顯示槽 0 為就緒。
- 推理完成后,序列調度器會發(fā)現(xiàn)任何批處理槽中都沒有可用的請求,因此模型實例處于空閑狀態(tài)。
- 接下來,兩個推理請求(上面的 Req 1 與下面的 Req 0)差不多的時間到達,序列調度器看到兩個處理槽都是可用,就立即執(zhí)行批量大小為 2 的推理模型實例,使用 READY 顯示兩個槽都有可用的推理請求,但只有槽 1 是新序列的開始(START)。
- 對于其他推理請求,處理以類似的方式繼續(xù)。
- 最舊的(oldest)策略
| 直接(direct)策略 | 最舊的(oldest)策略 |
|
direct {} |
oldest { max_candidate_sequences: 4 } |
使用最舊的調度策略,序列批處理程序會執(zhí)行以下工作:
| 所識別的推理請求種類 | 執(zhí)行動作 |
| 需要啟動新序列 | 嘗試查找具有候選序列空間的模型實例,如果沒有實例可以容納新的候選序列,就將請求放在一個積壓工作中 |
| 已經(jīng)是候選序列的一部分 | 將該請求分發(fā)到該模型實例 |
| 是積壓工作中序列的一部分 | 將請求放入積壓工作中 |
| 是最后一個推理請求 | 模型實例立即從積壓工作中刪除一個序列,并將其作為模型實例中的候選序列,或者記錄如果沒有積壓工作,模型實例可以處理未來的序列。 |
這里假設每個請求的長度是相同的,那么左邊候選序列中送進右邊批量處理槽的順序,就是上圖中間的排列順序。
最舊的策略從最舊的請求中形成一個動態(tài)批處理,但在一個批處理中從不包含來自給定序列的多個請求,例如上面序列 D 中的最后兩個推理不是一起批處理的。
以上是關于有狀態(tài)模型的“調度策略”主要內容,剩下的“集成模型”部分,會在下篇文章中提供完整的說明。
原文標題:NVIDIA Triton 系列文章(11):模型類別與調度器-2
文章出處:【微信公眾號:NVIDIA英偉達企業(yè)解決方案】歡迎添加關注!文章轉載請注明出處。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權轉載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
英偉達
+關注
關注
22文章
3815瀏覽量
91492
原文標題:NVIDIA Triton 系列文章(11):模型類別與調度器-2
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業(yè)解決方案】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
NVIDIA推出開放式Llama Nemotron系列模型
作為 NVIDIA NIM 微服務,開放式 Llama Nemotron 大語言模型和 Cosmos Nemotron 視覺語言模型可在任何加速系統(tǒng)上為 AI 智能體提供強效助力。
Triton編譯器與GPU編程的結合應用
Triton編譯器簡介 Triton編譯器是一種針對并行計算優(yōu)化的編譯器,它能夠自動將高級語言代碼轉換為針對特定硬件優(yōu)化的低級代碼。
Triton編譯器如何提升編程效率
在現(xiàn)代軟件開發(fā)中,編譯器扮演著至關重要的角色。它們不僅將高級語言代碼轉換為機器可執(zhí)行的代碼,還通過各種優(yōu)化技術提升程序的性能。Triton 編譯器作為一種先進的編譯器,通過多種方式提升
Triton編譯器在高性能計算中的應用
高性能計算(High-Performance Computing,HPC)是現(xiàn)代科學研究和工程計算中不可或缺的一部分。隨著計算需求的不斷增長,對計算資源的要求也越來越高。Triton編譯器作為一種
Triton編譯器的優(yōu)化技巧
在現(xiàn)代計算環(huán)境中,編譯器的性能對于軟件的運行效率至關重要。Triton 編譯器作為一個先進的編譯器框架,提供了一系列的優(yōu)化技術,以確保生成的
Triton編譯器的優(yōu)勢與劣勢分析
Triton編譯器作為一種新興的深度學習編譯器,具有一系列顯著的優(yōu)勢,同時也存在一些潛在的劣勢。以下是對Triton編譯
Triton編譯器的常見問題解決方案
Triton編譯器作為一款專注于深度學習的高性能GPU編程工具,在使用過程中可能會遇到一些常見問題。以下是一些常見問題的解決方案: 一、安裝與依賴問題 檢查Python版本 Triton編譯器
Triton編譯器支持的編程語言
Triton編譯器支持的編程語言主要包括以下幾種: 一、主要編程語言 Python :Triton編譯器通過Python接口提供了對Triton
Triton編譯器與其他編譯器的比較
Triton編譯器與其他編譯器的比較主要體現(xiàn)在以下幾個方面: 一、定位與目標 Triton編譯器 : 定位:專注于深度學習中最核心、最耗時的
Triton編譯器功能介紹 Triton編譯器使用教程
Triton 是一個開源的編譯器前端,它支持多種編程語言,包括 C、C++、Fortran 和 Ada。Triton 旨在提供一個可擴展和可定制的編譯器框架,允許開發(fā)者添加新的編程語言
NVIDIA助力提供多樣、靈活的模型選擇
在本案例中,Dify 以模型中立以及開源生態(tài)的優(yōu)勢,為廣大 AI 創(chuàng)新者提供豐富的模型選擇。其集成的 NVIDIAAPI Catalog、NVIDIA NIM和Triton 推理服務
NVIDIA Nemotron-4 340B模型幫助開發(fā)者生成合成訓練數(shù)據(jù)
Nemotron-4 340B 是針對 NVIDIA NeMo 和 NVIDIA TensorRT-LLM 優(yōu)化的模型系列,該系列包含最先進

使用NVIDIA Triton推理服務器來加速AI預測
這家云計算巨頭的計算機視覺和數(shù)據(jù)科學服務使用 NVIDIA Triton 推理服務器來加速 AI 預測。
利用NVIDIA產(chǎn)品技術組合提升用戶體驗
本案例通過利用NVIDIA TensorRT-LLM加速指令識別深度學習模型,并借助NVIDIA Triton推理服務器在





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論