 P99是如何計算的
P99是如何計算的
Latency(延遲)是我們在監控線上的組件運行情況的一個非常重要的指標,它可以告訴我們請求在多少時間內完成。監控 Latency 是一個很微妙的事情,比如,假如一分鐘有 1億次請求,你就有了 1億個數字。如何從這些數字中反映出用戶的真實體驗呢?
之前的公司用平均值來反應所有有關延遲的數據,這樣的好處是計算量小,實施簡單。只需要記錄所有請求的一個時間總和,以及請求次數,兩個數字,就可以計算出平均耗時。
但問題是,平均耗時非常容易掩蓋真實的問題。比如現在有 1% 的請求非常慢,但是其余的請求很快,那么這 1% 的請求耗時會被其他的 99% 給拉平,將真正的問題掩蓋。
所以更加科學的一種監控方式是觀察 P99/P95/P90 等,叫做 Quantile。簡單的理解,P99 就是第 99% 個請求所用的耗時。假如 P99 現在是 10ms,那么我們可以說 “99% 的請求都在 10ms 內完成”。雖然在一些請求量較小的情況下,P99 可能受長尾請求的影響。但是由于 SRE 一般不會給在量小的業務上花費太多精力,所以這個問題并不是很大。
但是計算就成了一個問題。P99 是計算時間的分布,所以我們是否要保存下來 1 億個請求的時間,才能知道第 99% 的請求所用的時間呢?
這樣耗費的資源太大了。考慮到監控所需要的數據對準確性的要求并不高。比如說 P99 實際上是 15.7ms 但是計算得到數據是 15.5ms,甚至是 14ms,我認為都是可以接受的。
我們關注更多的是它的變化。“P99 耗時從 10.7ms 上漲到了 14ms” 和 “P99耗時從 11ms 上漲到了 15.5ms” 這個信息對于我們來說區別并不是很大。(當然了,如果是用于衡量服務是否達到了服務等級協議 SLO 的話,還是很大的。這樣需要合理地規劃 Bucket 來提高準確性)。
所以基于這個,Prometheus 采用了一種非常巧妙的數據結構來計算 Quantile: Histogram。
Histogram 本質上是一些桶。舉例子說,我們為了計算 P99,可以將所有的請求分成 10 個桶,第一個存放 0-1ms 完成的請求的數量,后面 9 個桶存放的請求耗時上區間分別是 5ms、10ms、50ms、100ms、200ms、300ms、500ms、1s、2s,這樣只要保存 10 個數字就可以了。
要計算 P99 的話,只需要知道第 99% 個數字落在了哪一個桶,比如說落在了 300ms-500ms 的桶,那我們就可以說現在的 99% 的請求都在 500ms 之內完成(這樣說不太準確,如果準確的說,應該是第 99% 個請求在 300ms – 500ms 之間完成)。這些數據也可以用來計算 P90、P95 等等。
由于我們的監控一般是繪制一條曲線,而不是一個區間。所以 P99 在 300-500 之間是不行的,需要計算出一個數字來。
Prometheus 是假設每一個桶內的數據都是線性分布的,比如說現在 300-500 的桶里面一共有 100 個請求,小于300個桶里面一共有 9850 個請求。所有的桶一共有 1萬個請求。
那么我們要找的 P99 其實是第 10000 * 0.99 = 9900 個請求。第 9900 個請求在 300-500 的桶里面是第 9900 – 9850 = 50 個請求。根據桶里面都是線性分布的假設,第 50 個請求在這個桶里面的耗時是 (500 – 300) * (50/100) = 400ms,即 P99 就是 400ms。
可以注意到因為是基于線性分布的假設,不是準確的數據。比如假設 300-500 的桶中耗時最高的請求也只有 310ms,得到的計算結果也會是 400ms。桶的區間越大,越不準確,桶的區間越小,越準確。
寫這篇文章,是因為昨天同事跑來問我,“為啥我的日志顯示最慢的請求也才 1s 多,但是這個 P999 latency 顯示是 3s?”
我查了一下確實如他所說,但是這個結果確實預期的。因為我們設置的桶的分布是:10ms、50ms、100ms、500ms、1s、5s、10s、60s。
如上所說,Prometheus 只能保證 P999 latency 落在了 1s – 5s 之間,但不能保證誤差。
如果要計算準確的 Quantile,可以使用 Summary 計算。簡單來說,這個算法沒有分桶,是直接在機器上計算準確的 P99 的值,然后保存 P99 這個數字。但問題一個是在機器本地計算,而不是在 Prometheus 機器上計算,會占用業務機器的資源;另一個是無法聚合,如果我們有很多實例,知道每一個實例的 P99 是沒有什么意義的,我們更想知道所有請求的 P99。顯然,原始的信息已經丟失,這個 P99 per instance 是無法支持繼續計算的。
另外一個設計巧妙的地方是,300-500 這個桶保存的并不是 300-500 耗時的請求數,而是 <500ms 的請求數。也就是說,后面的桶的請求數總是包含了它前面的所有的桶。這樣的好處是,雖然我們保存的數據沒有增加(還是10個數字),但是保存的信息增加了。假如說中間丟棄一個桶,依然能夠計算出來 P99,在某些情況下非常有用,比如監控資源不夠了,我們可以臨時不收集前5個桶,依然可以計算 P99。
-
監控
+關注
關注
6文章
2216瀏覽量
55254
原文標題:P99 是如何計算的?
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
將信號引入DS99R104 ,DS99R104沒有輸出反應,為什么?
CBM99D57BQ
刀片計算機設計方案:192-6U VPX i7 刀片計算機

如何計算感性負載的功率因數?
14位,3.3V CMOS直接數字合成器-CBM99D10
數控車床m99指令的用法
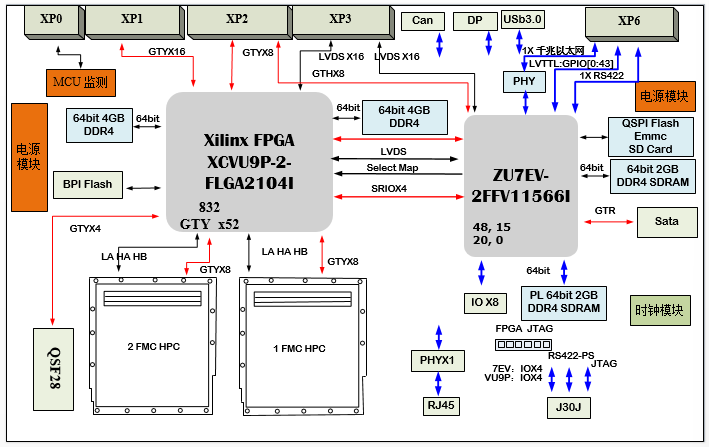
XCVU9P 板卡設計原理圖:616-基于6U VPX XCVU9P+XCZU7EV的雙FMC信號處理板卡 高性能數字計算卡
CBM24AD99Q數據手冊-中文版
智能加速計算卡設計原理圖:628-基于VU3P的雙路100G光纖加速計算卡 XCVU3P板卡

DS99R101/DS99R102 3-40MHz DC平衡24位LVDS串行器和解串器數據表

數控車床m99指令的用法
cnc怎么編程m99循環次數
樂鑫ESP32-P4芯片應用,WT99P4C6-S1開發板應用方案






 工商網監
工商網監
評論