 基于OTel的移動端全鏈路Trace為什么很難復現和定位?
基于OTel的移動端全鏈路Trace為什么很難復現和定位?
首先,我們了解一下移動端全鏈路 Trace 的背景:

從移動端的視角來看,一個 App 產品從概念產生,到最終的成熟穩定,產品研發過程中涉及到的研發人員、工程中的代碼行數、工程架構規模、產品發布頻率、線上業務問題修復時間等等都會發生比較大的變化。這些變化,給我們在排查問題方面帶來不小的困難和挑戰,業務問題會往往難以復現和排查定位。
比如,在產品初期的時候,工程規模往往比較小,業務流程也比較簡單,線上問題往往能很快定位。而等到工程規模比較大的時候,業務流程往往涉及到的模塊會比較多,這個時候有些線上問題就會比較難以復現和定位排查。
本文匯集了筆者在 2022 D2 終端技術大會上的相關技術分享,希望能給大家帶來一些思考和啟發。
端側問題為什么很難復現和定位?

線上業務問題為什么很難復現和排查定位?經過我們的分析,主要是由 4 個原因導致:
移動端 & 服務端日志采集不統一,沒有統一的標準規范來約束數據的采集和處理。
端側往往涉及的模塊非常多,研發框架也各不相同,代碼相互隔離,設備碎片化,網絡環境復雜,會導致端側數據采集比較難。
從端視角出發,不同框架、系統之間的數據在分析問題時往往獲取比較難,而且數據之間缺少上下文關聯信息,數據關聯分析不容易。
業務鏈路涉及到的業務域往往也會比較多,從端的視角去復現和排查問題,往往需要對應域的同學參與排查,人肉運維成本比較高。
這些問題如何來解決? 我們的思路是四步走:
建立統一標準,使用 標準協議 來約束數據的采集和處理。
針對不同的平臺和框架,統一數據采集能力。
對多系統、多模塊產生的數據進行自動上下文關聯分析和處理。
我們也基于機器學習,在自動化經驗分析方面做了一些探索。
統一數據采集標準
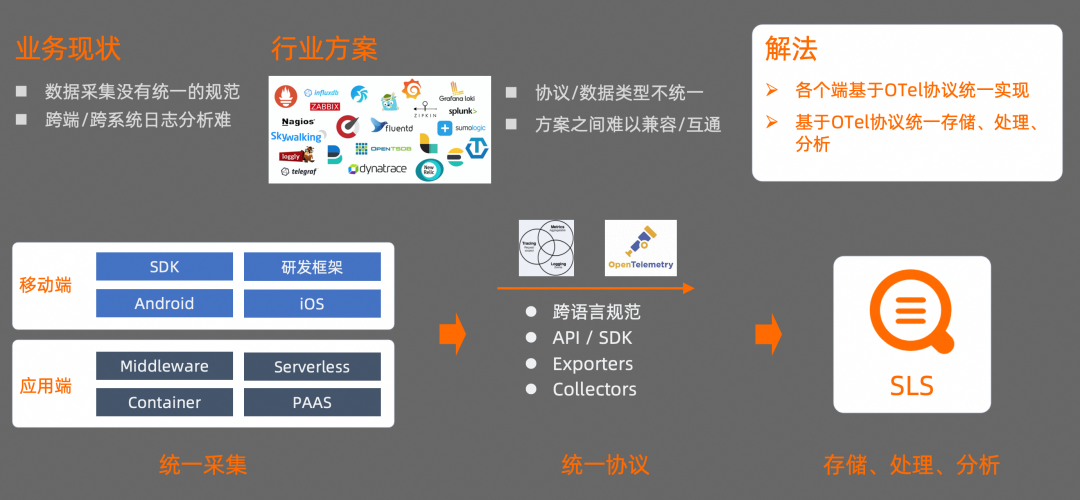
如何統一標準? 目前行業內也有各種各樣的解決方案,但存在的問題也很明顯:
不同方案之間,協議/數據類型不統一;
不同方案之間,也比較難以兼容/互通。
標準這里,我們選擇了 OTel,OTel 是 OpenTelemetry 的簡稱,主要原因有兩點:
OTel 是由云原生計算基金會(CNCF)主導,它是由 OpenTracing 和 OpenCensus 合并而來,是目前可觀測性領域的準標準協議;
OTel 對不同語言和數據模型進行了統一,可以同時兼容 OpenTracing 和 OpenCensus,它還提供了一個廠商無關的 Collectors,用于接收、處理和導出可觀測數據。
在我們的解決方案中,所有端的數據采集規范都基于 OTel,數據存儲、處理、分析是基于 SLS 提供的 LogHub 能力進行構建。
端側數據采集的難點

只統一數據協議還不夠,還要解決端側在數據采集方面存在的一些問題。總的來說,端側采集當前面臨 3 個主要的難點:
數據串聯難
性能保障難
不丟數據難
端側研發過程中涉及到的框架、模塊往往比較多,業務也有一定的復雜性,存在線程、協程多種異步調用 API,在數據采集過程中,如何解決數據之間的自動串聯問題?移動端設備碎片化嚴重,系統版本分布比較散,機型眾多,如何保障多端一致的采集性能?App 使用場景的不確定性也比較大,如何確保采集到的數據不會丟失?
端側數據串聯的難點

我們先來分析一下端側數據自動串聯所面臨的主要問題。
在端側數據采集過程中,不僅會采集業務鏈路數據,還會采集各種性能&穩定性監控數據,可觀測數據源比較多;
如果用到其他的研發框架,如 OkHttp、Fresco 等,可能還會采集三方框架的關鍵數據用于網絡請求,圖片加載等問題的分析和定位。對于業務研發同學來說,我們往往不會過多的關注這類三方框架技術能力,涉及到這類框架問題的排查時,過程往往比較困難;
除此之外,端側幾乎完全異步調用,而且異步調用 API 比較多,如線程、協程等,鏈路打通也存在一定的挑戰。
這里會有幾個共性問題:
三方框架的數據如何采集?如何串聯?
不同可觀測數據源之間如何串聯?
分布在不同線程、協程之間的數據如何自動串聯?
端側數據自動串聯方案
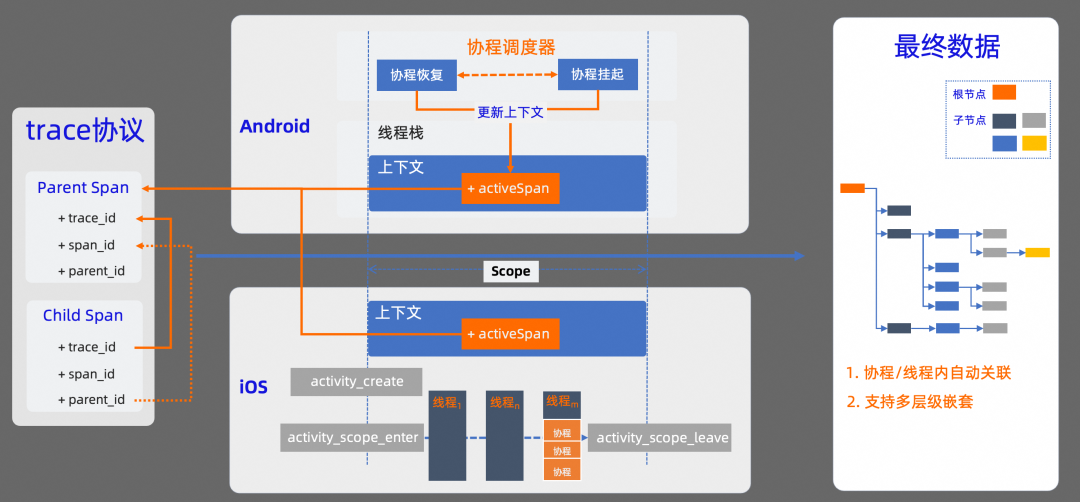
我們先看下端側數據自動串聯的方案。
在 OTel 協議標準中,是通過 trace 協議來約束不同數據之間的串聯關系。OTel 定義了 trace 數據鏈路中每條數據必須要包含的必要字段,我們需要確保同一條鏈路中數據的一致性。比如,同一條 trace 鏈路中,trace_id 需要相同;其次,如果數據之間有父子關系,子數據的 parent_id 也需要與父數據的 span_id 相同。
我們知道,不管是 Android 平臺,還是 iOS 平臺,線程都是操作系統能夠調度的最小單元。也就是說,我們所有的代碼,最終都會在線程中被執行。在代碼被執行過程中,如果我們能把上下文信息和當前線程進行關聯,在代碼執行時,就能自動獲取當前上下文信息,這樣就可以解決同一個線程內的 trace 數據自動關聯問題。
在 Android 中,可以基于線程變量 ThreadLocal 來存儲當前線程棧的上下文信息,這樣可以確保在同一線程中采集到的業務數據進行自動關聯。如果是在協程中使用,基于線程變量的方案就會存在問題。因為在協程中,協程真實運行的線程是不確定的,可能會在協程執行的生命周期內進行線程切換,我們需要利用協程調度器和協程 Context 來保持當前上下文的正確性。在協程恢復時,讓關聯的上下文信息在當前線程生效,在協程掛起時,再讓上下文信息在當前線程失效。
在 iOS 中,主要基于 activity tracing 機制來保持上下文信息的有效性。通過 activity tracing 機制,在一個業務鏈路開始時,會自動創建一個 activity,我們把上下文信息與 activity 進行關聯。在當前 activity 作用域范圍內,所有產生的數據都會與當前上下文自動關聯。
基于這兩種方案,在產生 Trace 數據時,SDK 會按照 OTel 協議的標準,自動把上下文信息關聯到當前數據中。最終產生的數據,會以一棵樹的形式進行邏輯關聯,樹的根節點就是 Trace 鏈路的起點。這種方式,不僅支持協程/線程內的數據自動關聯,還支持多層級嵌套。
三方框架的數據采集和串聯
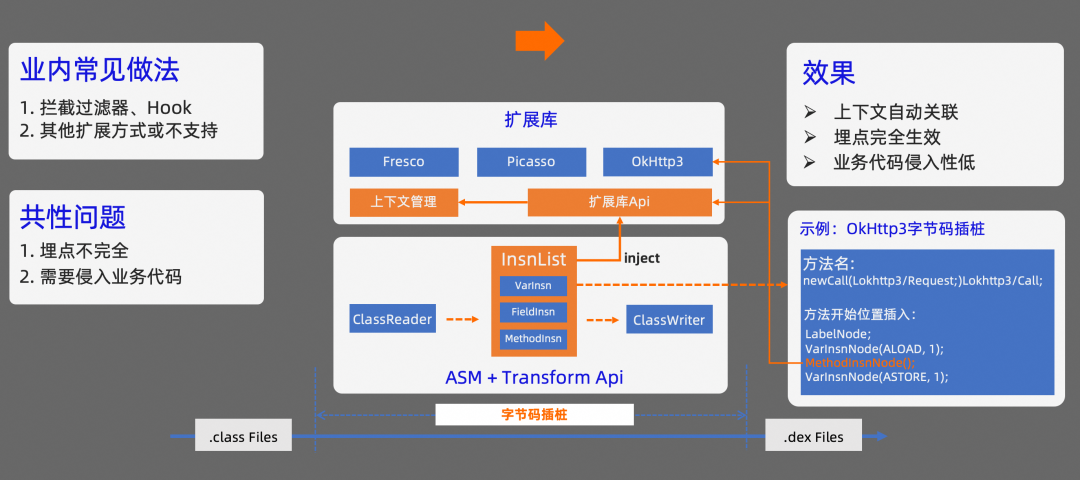
針對三方框架的數據采集,我們先看看業內通行的做法,目前主要有兩類:
如果三方庫支持攔截器或代理的配置,一般會通過在對應攔截器增加埋點代碼的方式來實現;
如果三方庫對外暴露的接口比較少,一般會通過 Hook 或其他方式增加埋點代碼,或者不支持對應框架的埋點。
這種做法會存在兩個主要的問題:
埋點不完全,拿 OkHttp 來舉例說明,三方 SDK 內部也可能存在對 OkHttp 的依賴,通過攔截器的方式,可能只支持當前業務代碼的埋點采集,三方 SDK 的網絡請求信息無法被采集到,會導致埋點信息不完全;
可能需要侵入業務代碼,為了實現對應框架的埋點,需要有一個切入時機,這個切入時機往往需要在對應框架初始化時增加代碼配置項來實現。
如何解這兩個問題?
我們使用的方案是實現一個 Gradle Plugin,在 Plugin 中對字節碼進行插樁處理。我們知道,Android App 在打包的過程中,有個流程會把 .class 文件轉為 .dex 文件,在這個過程中,可以通過 transform api 對 class 文件進行處理。我們是借助 ASM 的方式來實現 class 文件的插樁處理。在對字節碼處理的過程中,需要先找到合適的插樁點,然后注入合適的指令。
這里拿 OkHttp 的字節插樁進行舉例:插樁的目標是在 OkHttpClient 調用 newCall 方法時,把當前線程的上下文信息關聯到 OkHttp 的 Request 中。在 Transform 過程中,我們先根據 OkHttpClient 的類名過濾出目標 class 文件,然后再根據 newCall 這個方法名過濾要插樁的方法。接下來,需要在 newCall 方法開始的地方把上下文信息插入到 request 的 tags 對象中。經過我們的分析,需要在 newCall 方法調用開始的時候,插入目標代碼。為了方便實現和調試,我們在擴展庫中實現了一個 OkHttp 的輔助工具,在目標位置插入調用這個工具的字節碼,傳入 request 對象就可以了。
插入后的字節碼會和擴展庫進行關聯。這樣就能解決三方框架數據采集和上下文自動關聯的問題。
相對于傳統做法,使用字節碼插樁的方案,業務代碼侵入性會更低,埋點對業務代碼和三方框架都能生效,同時結合擴展庫也能完成上下文的自動關聯。
如何確保性能
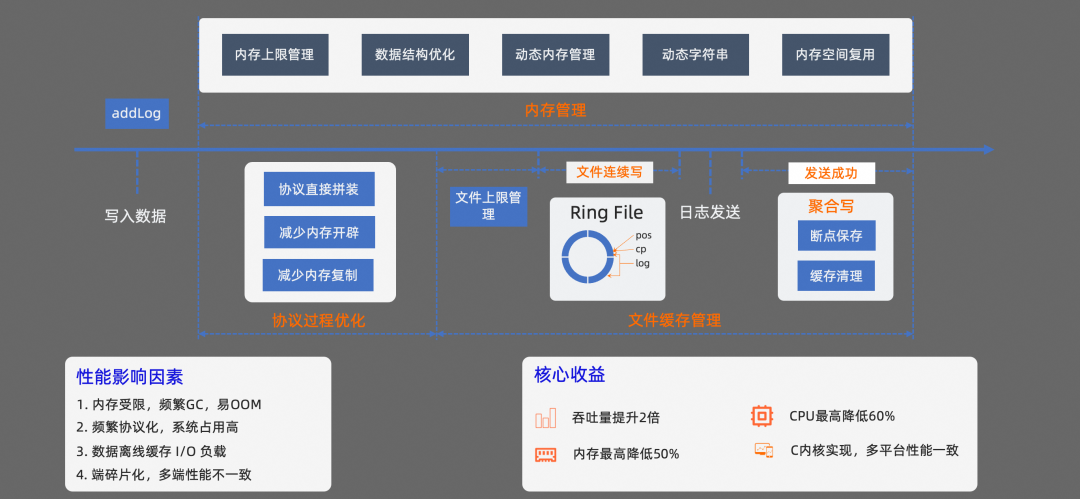
在可觀測數據采集過程中,會有大量的數據產生,對內存、CPU 占用、I/O 負載都有一定的性能要求。
我們基于 C 對核心部分進行實現,確保多平臺的性能一致性,并從三個方面對性能做了優化:
首先,是對協議化處理過程進行優化。數據協議方面選擇使用 Protocal Buffer 協議,Protocal Buffer 相對 JSON 來說,不僅速度更快,而且更省內存空間。在協議的序列化上,我們采用了手動封裝協議的實現,在序列化的過程中,避免了很多臨時內存空間的開辟、復制以及無關函數的調用。
其次,在內存管理方面,我們直接對 SDK 的最大使用內存做了可配置的大小限制。內存的使用,可以根據業務情況按需配置,避免 SDK 內存占用過大對 App 的穩定性造成影響;其次,還引入了動態內存管理機制,內存空間的使用按需增加,不會一直占用 App 的內存空間,避免內存空間的浪費。同時還提升了字符串的處理性能。在字符的處理上,引入了動態字符串機制,它可以記錄字符串自身的長度,獲取字符長度時,操作復雜度低,而且可以避免緩沖區溢出,同時也可以減少修改字符串時帶來的內存重分配次數。
最后,在文件緩存管理方面,我們也限制了文件大小的上限,避免對端設備存儲空間的浪費。在緩存文件的落盤處理上,我們引入了 Ring File 機制,把緩存數據存儲在多個文件上面,以日志文件組的形式對多個文件進行組裝。整個日志文件組以環形數組的形式,從頭開始寫,寫到末尾再回到頭重新循環寫。
通過這種方式寫數據,可以減少寫文件時的隨機 Seek,而且 Ring File 的機制,可以確保單個日志文件不會過大,從而盡可能的降低系統 I/O 的負載。除了 Ring File 的機制外,還把斷點保存、緩存清理的邏輯放到了一起聚合執行,減少隨機 Seek。checkpoint 的文件大小也做了限制,在超出指定大小后會對 checkpoint 文件進行清理,避免 checkpoint 文件過大影響文件讀寫效率。
經過上面的這些優化措施之后,最終 SDK 采集數據的吞吐量提升了 2 倍,內存和 CPU 占用都有明顯的降低。每秒鐘最高可支持 400+條數據的采集。
如何確保日志不丟失?
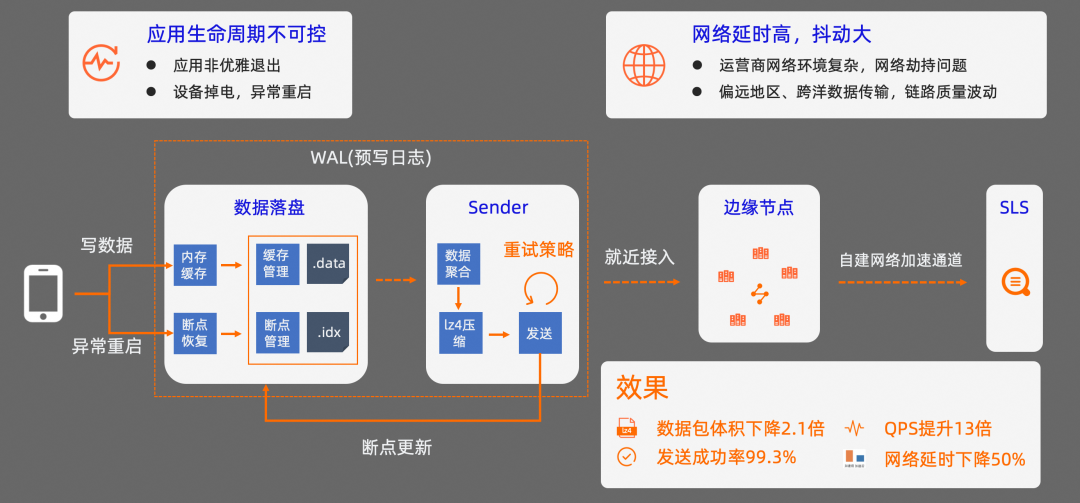
性能滿足要求還不夠,還需要確保采集到的數據不能丟失。在 App 的使用過程中,app 經常可能會出現異常崩潰,手機設備異常重啟,以及網絡質量差,網絡延時、抖動大的情況。在這類異常場景下,如何確保采集到數據不會丟失?
在采集數據時,我們使用了預寫日志(WAL)機制,并結合自建網絡加速通道來優化這個問題。
引入預寫日志機制的目的是確保寫入到 SDK 的數據,在發送到服務器之前,不會因為異常原因而丟失。這個過程的核心是,在數據成功發送到服務器之前,先把數據緩存在移動設備的磁盤上,數據發送成功之后,再移除磁盤上的緩存數據。如果因為 App 異常原因,或者設備重啟導致數據發送失敗,因為緩存的數據還在,SDK 會根據記錄的斷點信息對數據發送進度進行恢復。同時預寫日志機制可以確保數據的寫入和發送并發執行,不會互相阻塞;
在數據發送之前,還會對多條數據做聚合處理,并通過 lz4 算法進行壓縮處理,這種做法可以降低數據發送時的請求次數和網絡傳輸流量的消耗。如果數據發送失敗,還會有重試策略,確保數據至少能成功發送一次;
在數據發送時,SDK 支持就近接入加速邊緣節點,并通過邊緣節點與 SLS 之間的內部網絡加速通道傳輸數據。
經過這三種主要的方式優化之后,數據包的平均大小降低了 2.1 倍,整體的 QPS 平均提升 13 倍,數據整體的發送成功率達到了 99.3%,網絡延時平均下降了 50%。
多系統數據關聯處理
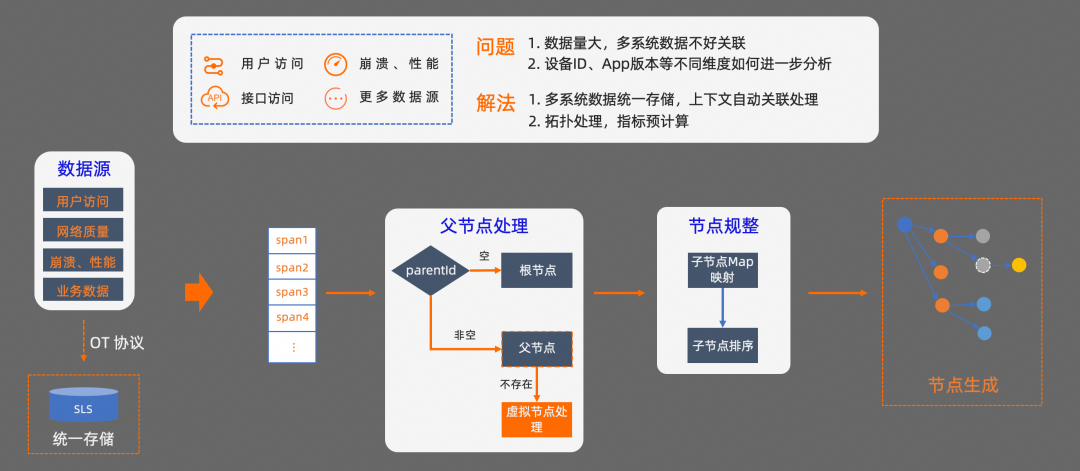
解決了端側數據的串聯和采集性能問題之后,還需要處理多系統之間的數據存儲和關聯分析問題。
數據存儲方面,我們直接基于 SLS LogHub 能力,把相關的數據統一存儲,基于 SLS,日均可以承載 PB 級別的流量,這個吞吐量可以支持移動端可觀測數據的全量采集。
解決了數據的統一存儲問題之后,還需要處理兩個主要的問題。
第一個問題,不同系統可觀測數據之間的上下文關聯如何處理?
根據 OTel 協議的約束,我們可以基于 parent_id 和 span_id 來處理根節點、父節點、子節點之間的映射關系。首先,在查詢 Trace 數據鏈路時,會先從 SLS 拉取一定時間段內的所有 Trace 數據。然后按照 OTel 協議的約束,對每條數據進行節點類型的判定。
由于多系統的數據可能存在延時,在查詢 Trace 數據鏈路時,有些數據可能還沒有到達。我們還需要對暫時不存在的父節點進行虛擬化處理,確保 Trace 鏈路的準確性。接下來,還需要對節點進行規整處理,把屬于同一個 parent_id 的節點進行聚合,然后再按照每個節點的開始時間進行排序,最終就可以得到一條 trace 鏈路信息,基于這個鏈路信息,我們可以還原出系統的調用鏈路。
第二個問題, 在進行 Trace 分析時,我們往往還需要從系統視角出發,對不同維度的數據進一步分析。比如,如果想從設備 ID、App 版本、服務調用等不同維度,對 Trace 數據進一步分析,該怎么做?我們來看一下怎么解決這個問題。
多系統數據拓撲生成
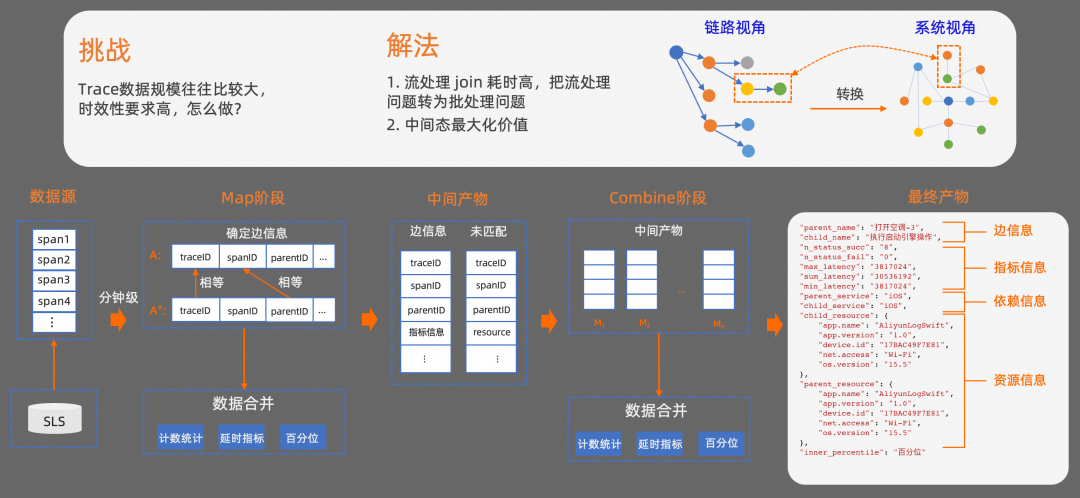
當我們從系統整體視角對問題進行分析時,所需要的 Trace 數據規模往往會比較大,每分鐘可能有數千萬條數據,而且對數據的時效性要求也比較高。傳統的流處理方式在這種場景下很容易遇到性能瓶頸問題。我們采用的方案是,把流處理問題轉換為批處理問題,把傳統的鏈路處理視角轉換為系統處理視角。經過視角轉化之后,從系統視角來看,解決這個問題最主要的核心,就是如何確定兩個節點之間的關系。
我們看一下具體的處理過程。在批處理上,我們使用了 MapReduce 框架。首先,在數據源處理階段,我們基于 SLS 的定時分析(ScheduledSQL)能力,對數據進行聚合處理,按照分鐘級從 Trace 數據源中撈取數據。在 Map 階段,先按照 traceID 進行分組,對分組之后的數據再按照 spanID、parentID 維度對數據進行聚合。
然后計算出相關的統計數據,如成功率、失敗率、延時指標等基礎統計數據。在實際的業務使用中,往往還會采集一些和具體業務屬性相關的數據,這部分數據往往會根據業務的不同,有比較大的差異。針對這部分類型的數據,在聚合處理的過程中,支持按照其他維度對結果進行分組。此時會得到兩種中間產物:
包含兩個節點關系的聚合數據,我們把這種類型的數據,叫做邊信息
以及未匹配到的原始數據
這兩種中間產物,在 Combine 階段還會再進行聚合處理,最終會得到包含基礎統計指標,以及其他維度的結果數據。
最終產物會包含幾個主要的信息:
邊信息,可以體現調用關系。
依賴信息,可以體現服務依賴關系。
還有指標信息,以及其他資源信息等。其中,業務屬性相關的數據會體現在資源信息中。
基于這些產物,我們可以通過對資源、服務等信息的多個維度篩選,來統計出對應維度的問題分布和影響鏈路。
自動化問題根因定位探索
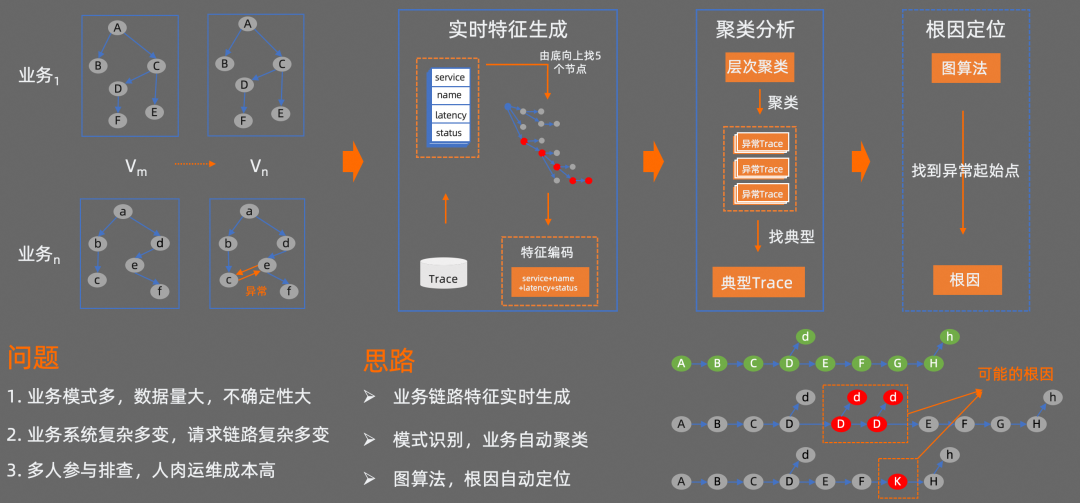
接下來向大家介紹下,我們在自動化問題根因定位方向的一些探索。
我們知道,隨著 App 版本的迭代,每次 App 的發版可能會涉及到多個業務的代碼變更。這些變更,有的經過充分測試,也有的未經過充分測試,或者常規測試方法沒有覆蓋到,對線上業務可能會產生一定的潛在影響,導致部分業務不可用。App 規模越大,業務模式越多,對應的業務數據量,請求鏈路,不確定性就越大。出了問題之后,往往需要多人跨域參與排查,人肉運維成本比較高。
如何在端側問題排查定位方向,通過技術手段進行研發效能的提速? 我們基于機器學習技術做了一些探索。
我們目前的方法是,先對 Trace 源數據進行特征處理;然后再對特征進行聚類分析,去找到異常 Trace;最后再基于圖算法等,對異常 Trace 進行分析,找到異常的起始點。
首先,實時特征處理階段會讀取 Trace 源數據,對每個 Trace 鏈路按照由底向上找 5 個節點的方式生成一個特征,并對特征進行編碼。然后對編碼之后的特征通過 HDBSCAN 算法進行層次聚類分析,此時相似的異常會分到同一個組里面,接下來再從每組異常 Trace 中找出一條典型的異常 Trace。最后,通過圖算法找到這條異常 Trace 的起點,從而確定當前異常 Trace 可能存在的問題根因。通過這種方式,只要是遵循 OTel 標準協議的數據源都能夠進行處理。
案例:多端鏈路追蹤

經過對數據處理之后,我們來看下最終的效果。
這里有一個模擬 Android、iOS、服務端,端到端鏈路追蹤的場景。
我們使用 iOS App 來作為指令的發送端,Android App 來作為指令的響應端,用來模擬遠程打開汽車空調的操作。我們從圖上可以看到,iOS 端“打開車機空調”這個操作觸發后,依次經過了“用戶權限校驗”、“發送指令”、“調用網絡請求”等環節。Android 端收到指令后,依次執行“遠程啟動空調”、“狀態檢查”等環節。
從這個調用圖可以看得到,Android、iOS、服務端,多端鏈路被串聯到了一起。我們可以從 Android、iOS、服務端的任何一個視角,對調用鏈路進行分析。每個操作的耗時,對應服務的請求數,錯誤率,以及服務依賴都能體現出來。
整體架構
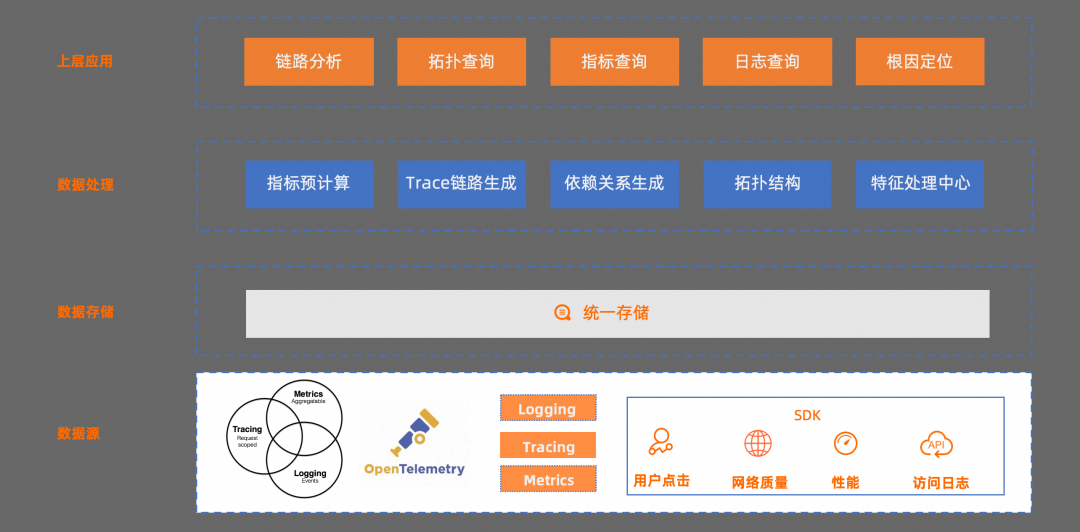
接下來,我們來看下整套解決方案的架構:
最底層是數據源,遵循 OTel 協議,各個端對應的 SDK 按照協議規范統一實現;
數據存儲層,是直接依托于 SLS LogHub,所有系統采集到的數據統一存儲;
再往上是數據處理層,對關鍵指標、Trace 鏈路、依賴關系、拓撲結構、還有特征等進行了預處理。
最后是上層應用,提供鏈路分析、拓撲查詢、指標查詢、原始日志查詢,以及根因定位等能力
后續規劃
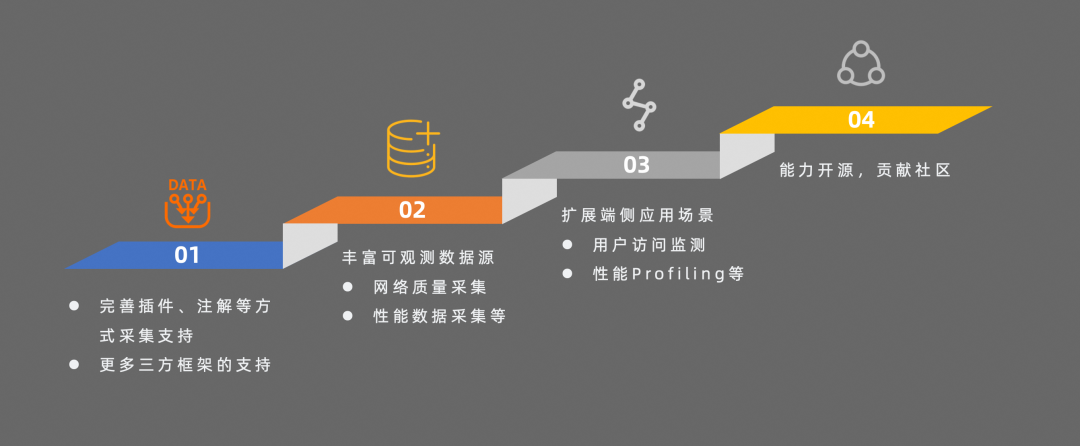
最后總結下我們后續的規劃:
在采集層,會繼續完善插件、注解等方式的支持,降低業務代碼的侵入性,提升接入效率
在數據側,會豐富可觀測數據源,后續會支持網絡質量、性能等相關數據的采集
在應用側,會提供用戶訪問監測、性能分析等能力
審核編輯:劉清
-
API
+關注
關注
2文章
1507瀏覽量
62219 -
Trace
+關注
關注
0文章
19瀏覽量
10571 -
SDK
+關注
關注
3文章
1044瀏覽量
46078 -
SLS
+關注
關注
0文章
15瀏覽量
8926 -
調度器
+關注
關注
0文章
98瀏覽量
5262
原文標題:SLS:基于 OTel 的移動端全鏈路 Trace 建設思考和實踐
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
奇瑞iCAR V23搭載思必馳全鏈路智能語音語言交互技術
使用OTDR進行光纖鏈路測試的方法
調試PCIE鏈路動態均衡介紹
IR615如何實現VPN鏈路備份?
IG網關產品實現鏈路備份的方法
LM2512A移動像素鏈路,24位RGB顯示接口串行器數據表

光纖鏈路的相關介紹
如何識別光纖鏈路問題?
如何辨別光纖鏈路的好壞?
永久鏈路、信道測試的區別
長城汽車攜手軟件測評中心打造整車全鏈路智能化的深度測試模式
比亞迪與京東聯手,提升汽車全鏈路體驗
什么是鏈路聚合?LACP是如何工作的?





 工商網監
工商網監
評論