 NVIDIA Triton 系列文章(13):模型與調度器-3
NVIDIA Triton 系列文章(13):模型與調度器-3
前面兩篇文章,已經將 Triton 的“無狀態模型”、“有狀態模型”與標準調度器的動態批量處理器與序列批量處理器的使用方式,做了較完整的說明。
大部分的實際應用都不是單純的推理模型就能完成服務的需求,需要形成前后關系的工作流水線。例如一個二維碼掃描的應用,除了需要第一關的二維碼識別模型之外,后面可能還得將識別出來的字符傳遞給語句識別的推理模型、關鍵字搜索引擎等功能,最后找到用戶所需要的信息,反饋給提出需求的用戶端。
本文的內容要說明 Triton 服務器形成工作流水線的“集成推理”功能,里面包括“集成模型(ensemble model)”與“集成調度器(ensemble scheduler)”兩個部分。下面是個簡單的推理流水線示意圖,目的是對請求的輸入圖像最終反饋“圖像分類”與“語義分割”兩個推理結果:
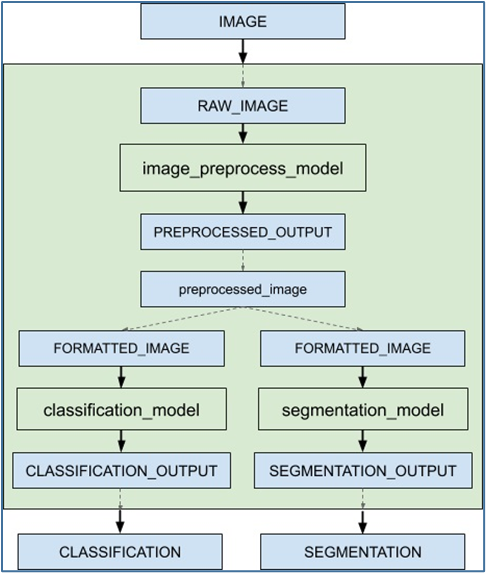 當接收到集成模型的推斷請求時,集成調度器將:
當接收到集成模型的推斷請求時,集成調度器將:
當接收到集成模型的推斷請求時,集成調度器將:
- 確認請求中的“IMAGE”張量映射到預處理模型中的輸入“RAW_IMAGE”。
- 檢查集合中的模型,并向預處理模型發送內部請求,因為所需的所有輸入張量都已就緒。
- 識別內部請求的完成,收集輸出張量并將內容映射到“預處理圖像”,這是集成中已知的唯一名稱。
- 將新收集的張量映射到集合中模型的輸入。在這種情況下,“classification_model”和“segmentation_model”的輸入將被映射并標記為就緒。
- 檢查需要新收集的張量的模型,并向輸入就緒的模型發送內部請求,在本例中是分類模型和分割模型。請注意,響應將根據各個模型的負載和計算時間以任意順序排列。
- 重復步驟 3-5,直到不再發送內部請求,然后用集成輸出名稱的張量去響應推理請求。
- 使用 image_prepoecess_model 模型,將原始圖像處理成preprocessed_image 數據;
- 將 preprocessed_image 數據傳遞給 classification_model 模型,執行圖像分類推理,最終返回“CLASSIFICATION”結果;
- 將 preprocessed_image 數據傳遞給 segmentation_model 模型,執行語義分割推理計算,最終返回“SEGMENTATION”結果;
- 支持一個或多個模型的流水線以及這些模型之間輸入和輸出張量的連接;
- 處理多個模型的模型拼接或數據流,例如“數據處理->推理->數據后處理”等;
- 收集每個步驟中的輸出張量,并根據規范將其作為其他步驟的輸入張量;
- 所集成的模型能繼承所涉及模型的特征,在請求方的元數據必須符合集成中的模型;
- 在模型倉里為流水線創建一個新的“組合模型”文件夾,例如為“ensemble_model”;
- 在目路下創建新的 config.pbtxt,并且使用“platform: "ensemble"”來定義這個模型要執行集成功能;
- 定義集成模型:
name:"ensemble_model"
platform: "ensemble"
max_batch_size: 1
input [
{
name: "IMAGE"
data_type: TYPE_STRING
dims: [ 1 ]
}
]
output [
{
name: "CLASSIFICATION"
data_type: TYPE_FP32
dims: [ 1000 ]
},
{
name: "SEGMENTATION"
data_type: TYPE_FP32
dims: [ 3, 224, 224 ]
}
]
從這個內容中可以看出,Triton 服務器將這個集成模型視為一個獨立模型。
4. 定義模型的集成調度器:這部分使用“ensemble_scheduling”來調動集成調度器,將使用到模型與數據形成完整的交互關系。
在上面示例圖中,灰色區塊所形成的工作流水線中,使用到 image_prepoecess_model、classification_model、segmentation_model 三個模型,以及 preprocessed_image 數據在模型中進行傳遞。
下面提供這部分的范例配置內容,一開始使用“ensemble_scheduling”來調用集成調度器,里面再用“step”來定義模組之間的執行關系,透過模型的“input_map”與“output_map”的“key:value”對的方式,串聯起模型之間的交互動作:
ensemble_scheduling{
step [
{
model_name: "image_preprocess_model"
model_version: -1
input_map {
key: "RAW_IMAGE"
value: "IMAGE"
}
output_map {
key: "PREPROCESSED_OUTPUT"
value: "preprocessed_image"
}
},
{
model_name: "classification_model"
model_version: -1
input_map {
key: "FORMATTED_IMAGE"
value: "preprocessed_image"
}
output_map {
key: "CLASSIFICATION_OUTPUT"
value: "CLASSIFICATION"
}
},
{
model_name: "segmentation_model"
model_version: -1
input_map {
key: "FORMATTED_IMAGE"
value: "preprocessed_image"
}
output_map {
key: "SEGMENTATION_OUTPUT"
value: "SEGMENTATION"
}
}
]
}
這里簡單說明一下工作流程:
(1) 模型 image_preprocess_model 接收外部輸入的 IMAGE 數據,進行圖像預處理任務,輸出 preprocessed_image 數據;(2) 模型 classification_model 的輸入為 preprocessed_image,表示這個模型的工作是在 image_preprocess_model 之后的任務,執行的推理輸出為 CLASSIFICATION;(3) 模型 segmentation_model 的輸入為 preprocessed_image,表示這個模型的工作是在 image_preprocess_model 之后的任務,執行的退輸出為 SEGMENTATION;(4) 上面兩步驟可以看出 classification_model 與 segmentation_model 屬于分支的同級模型,與上面工作流圖中的要求一致。
完成以上的步驟,就能用集成模型與集成調度器的搭配,來創建一個完整的推理工作流任務,相當簡單。
不過這類集成模型中,還有以下幾個需要注意的重點:
- 這是 Triton 服務器用來執行用戶定義模型流水線的抽象形式,由于沒有與集成模型關聯的物理實例,因此不能為其指定 instance_group 字段;
- 不過集成模型內容所組成的個別模型(例如image_preprocess_model),可以在其配置文件中指定 instance_group,并在集成接收到多個請求時單獨支持并行執行。
- 由于集成模型將繼承所涉及模型的特性,因此在請求起點的元數據(本例為“IMAGE”)必須符合集成中的模型,如果其中一個模型是有狀態模型,那么集成模型的推理請求應該包含有狀態模型中提到的信息,這些信息將由調度器提供給有狀態模型。
原文標題:NVIDIA Triton 系列文章(13):模型與調度器-3
文章出處:【微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
英偉達
+關注
關注
22文章
3815瀏覽量
91492
原文標題:NVIDIA Triton 系列文章(13):模型與調度器-3
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NVIDIA推出開放式Llama Nemotron系列模型
作為 NVIDIA NIM 微服務,開放式 Llama Nemotron 大語言模型和 Cosmos Nemotron 視覺語言模型可在任何加速系統上為 AI 智能體提供強效助力。
Triton編譯器與GPU編程的結合應用
Triton編譯器簡介 Triton編譯器是一種針對并行計算優化的編譯器,它能夠自動將高級語言代碼轉換為針對特定硬件優化的低級代碼。
Triton編譯器如何提升編程效率
在現代軟件開發中,編譯器扮演著至關重要的角色。它們不僅將高級語言代碼轉換為機器可執行的代碼,還通過各種優化技術提升程序的性能。Triton 編譯器作為一種先進的編譯器,通過多種方式提升
Triton編譯器的優化技巧
在現代計算環境中,編譯器的性能對于軟件的運行效率至關重要。Triton 編譯器作為一個先進的編譯器框架,提供了一系列的優化技術,以確保生成的
Triton編譯器的優勢與劣勢分析
Triton編譯器作為一種新興的深度學習編譯器,具有一系列顯著的優勢,同時也存在一些潛在的劣勢。以下是對Triton編譯
Triton編譯器的常見問題解決方案
Triton編譯器作為一款專注于深度學習的高性能GPU編程工具,在使用過程中可能會遇到一些常見問題。以下是一些常見問題的解決方案: 一、安裝與依賴問題 檢查Python版本 Triton編譯器
Triton編譯器支持的編程語言
Triton編譯器支持的編程語言主要包括以下幾種: 一、主要編程語言 Python :Triton編譯器通過Python接口提供了對Triton
Triton編譯器與其他編譯器的比較
Triton編譯器與其他編譯器的比較主要體現在以下幾個方面: 一、定位與目標 Triton編譯器 : 定位:專注于深度學習中最核心、最耗時的
Triton編譯器功能介紹 Triton編譯器使用教程
Triton 是一個開源的編譯器前端,它支持多種編程語言,包括 C、C++、Fortran 和 Ada。Triton 旨在提供一個可擴展和可定制的編譯器框架,允許開發者添加新的編程語言
NVIDIA助力提供多樣、靈活的模型選擇
在本案例中,Dify 以模型中立以及開源生態的優勢,為廣大 AI 創新者提供豐富的模型選擇。其集成的 NVIDIAAPI Catalog、NVIDIA NIM和Triton 推理服務
NVIDIA Nemotron-4 340B模型幫助開發者生成合成訓練數據
Nemotron-4 340B 是針對 NVIDIA NeMo 和 NVIDIA TensorRT-LLM 優化的模型系列,該系列包含最先進

NVIDIA加速微軟最新的Phi-3 Mini開源語言模型
NVIDIA 宣布使用 NVIDIA TensorRT-LLM 加速微軟最新的 Phi-3 Mini 開源語言模型。TensorRT-LLM 是一個開源庫,用于優化從 PC 到云端的
使用NVIDIA Triton推理服務器來加速AI預測
這家云計算巨頭的計算機視覺和數據科學服務使用 NVIDIA Triton 推理服務器來加速 AI 預測。
利用NVIDIA產品技術組合提升用戶體驗
本案例通過利用NVIDIA TensorRT-LLM加速指令識別深度學習模型,并借助NVIDIA Triton推理服務器在





 工商網監
工商網監
評論