") 一文走進(jìn)多核架構(gòu)下的內(nèi)存模
一文走進(jìn)多核架構(gòu)下的內(nèi)存模
走進(jìn)多核編程
CPU 發(fā)展早期階段,性能的提升主要來(lái)自于主頻的提升和架構(gòu)的優(yōu)化,當(dāng)這條優(yōu)化途徑出現(xiàn)瓶頸后,多核 CPU 開(kāi)始流行起來(lái)。多核心同時(shí)執(zhí)行任務(wù)極大地提高了系統(tǒng)整體性能,但也對(duì)硬件架構(gòu)和軟件編寫提出了更大的挑戰(zhàn)。各個(gè)核心都有自己的 Cache,以及不同層級(jí)的 Cache,彼此共享內(nèi)存。一個(gè)典型的多核 CUP 架構(gòu)如下圖所示:
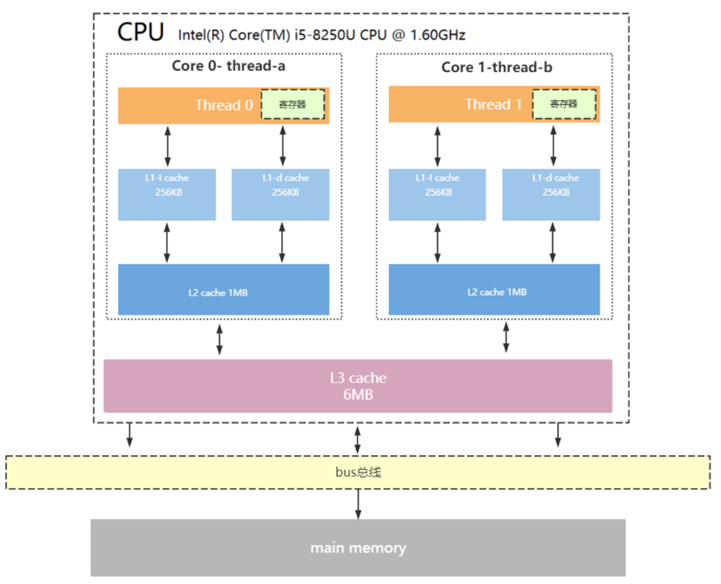
利用多核心的優(yōu)勢(shì)在各個(gè)核之間互相配合完成任務(wù),如何進(jìn)行各個(gè)核心間的數(shù)據(jù)同步(各個(gè)核心所屬 L1 Cache/L2 Cache 數(shù)據(jù)的同步)是問(wèn)題的關(guān)鍵所在。雖然發(fā)展出多種數(shù)據(jù)同步方式,以及流水線亂序執(zhí)行的模式,但數(shù)據(jù)在各個(gè)核之間的一致性和可見(jiàn)性并不是那么理想;再加上編譯器也會(huì)做優(yōu)化,最終導(dǎo)致各個(gè)核的指令執(zhí)行順序和各個(gè)變量值的可見(jiàn)性變得不確定。
這種現(xiàn)象可以通稱為重排,即原本應(yīng)該有全序的內(nèi)存讀寫操作被打亂。不過(guò)無(wú)論產(chǎn)生什么樣的重排,都會(huì)保證對(duì)于單線程內(nèi)部的執(zhí)行結(jié)果不會(huì)有任何區(qū)別。下面是一個(gè)簡(jiǎn)單例子:
1. //Thread1
2. //readywasinitializedtofalse
3. p.init();
4. ready=true;
1. //thread2
2. if(ready){
3. p.bar();
4. }
對(duì)于 Thread 1 內(nèi)部,p 和 ready 沒(méi)有關(guān)聯(lián),完全可以被重排而不影響正確性,而 Thread 2 依賴 ready 做標(biāo)識(shí)位,一旦重排,Thread 2 在看到 ready 為 true 的時(shí)候 p 都可能沒(méi)有 init,顯然這是有問(wèn)題的。
二
多核編程中臨界區(qū)保護(hù)
利用多線程做并發(fā)的任務(wù)中通常都會(huì)有公共的臨界區(qū),比如最常用的一種數(shù)據(jù)結(jié)構(gòu):并發(fā)隊(duì)列,生產(chǎn)者和消費(fèi)者需要訪問(wèn)隊(duì)列的公共內(nèi)存進(jìn)行寫入和讀取。目前對(duì)于臨界區(qū)的保護(hù)方式通常可以分為三個(gè)級(jí)別:互斥、Lock-free 和 Wait-free。
1、互斥
互斥,顧名思義每個(gè)線程訪問(wèn)臨界區(qū)之前都需要獲得互斥鎖,如果被別的線程占用了就阻塞等待。當(dāng)進(jìn)入臨界區(qū)的線程發(fā)生阻塞,或被操作系統(tǒng)換出時(shí),會(huì)出現(xiàn)全局阻塞,因?yàn)楂@得鎖的線程被換出無(wú)法執(zhí)行操作,而未獲得鎖的線程也只能一同等待,出現(xiàn)了阻塞傳播。如果另一個(gè)線程先進(jìn)入臨界區(qū),有可能反而可以更快的順利完成。因?yàn)榇嬖谌肿枞目赡苄裕捎没コ饧夹g(shù)進(jìn)行臨界區(qū)保護(hù)的算法有著最低的阻塞容忍能力。
2、Lock-free
Lock-free 允許單個(gè)線程阻塞,但是會(huì)保證系統(tǒng)整體層面上的吞吐。如果當(dāng)程序線程運(yùn)行足夠長(zhǎng)時(shí)間的情況下,至少有一個(gè)線程取得了進(jìn)展,那么就可以說(shuō)這個(gè)算法是 Lock-free 的。如果一個(gè)線程被掛起,那么 Lock-free 算法保證剩余的線程仍然可以進(jìn)行。
使用鎖的代碼一定不是 Lock-free 的,因?yàn)橐粋€(gè)線程加鎖后如果被系統(tǒng)切出去了,其他所有線程都處于等待中。但是沒(méi)用鎖也不一定是 Lock-free,因?yàn)槠胀ǖ拇a邏輯也可能會(huì)導(dǎo)致一個(gè)線程夯住另一個(gè)線程。鎖之所以在高并發(fā)的時(shí)候表現(xiàn)很差,主要原因是加鎖的線程會(huì)夯住其他等待加鎖的線程,Lock-free 可以很好地解決這一問(wèn)題。
在實(shí)現(xiàn)上一般先假設(shè)臨界區(qū)不存在競(jìng)爭(zhēng),各個(gè)線程直接開(kāi)始在臨界區(qū)的執(zhí)行,執(zhí)行過(guò)程中通過(guò)良好的程序設(shè)計(jì),讓這段預(yù)先的執(zhí)行是無(wú)沖突并且是可回滾的。最終有一個(gè)需要同步的提交操作,一般基于原子變量 CAS 操作,或者版本校驗(yàn)等機(jī)制完成。在提交階段如果發(fā)生沖突,那么被仲裁為失敗的各方需要對(duì)臨界區(qū)預(yù)執(zhí)行進(jìn)行回滾,并重新發(fā)起一輪嘗試。
注意,并不是說(shuō) Lock-free 的算法就一定比加鎖的算法好,Lock-free 需要處理更多更復(fù)雜的 race condition 移機(jī) ABA 等問(wèn)題,編寫出合理的 Lock-free 代碼也需要更深厚的技術(shù)功底,需要對(duì)底層有更多地了解,完成相同目的的代碼會(huì)比用鎖更復(fù)雜,執(zhí)行時(shí)間可能更長(zhǎng),代碼也更難理解。
很多場(chǎng)景下合理地使用鎖就能很好的勝任,Lock-free 和鎖之間在應(yīng)用場(chǎng)景上更多的是一種互補(bǔ)的關(guān)系。Lock-free 算法的價(jià)值在于其保證了一個(gè)或所有線程始終在做有用的事,而不是絕對(duì)的高性能。但 Lock-free 相較于鎖在并發(fā)度高(競(jìng)爭(zhēng)激烈導(dǎo)致上下文切換開(kāi)銷變得突出)的某些場(chǎng)景下會(huì)有很大的性能優(yōu)勢(shì),比如實(shí)現(xiàn)一個(gè)多線程的 Lock-free queue。總的來(lái)說(shuō),在多核環(huán)境下,Lock-free 是很有意義的。
3、Wait-free
Lock-free 技術(shù)主要解決了臨界區(qū)內(nèi)的阻塞傳播問(wèn)題,但是本質(zhì)上,依然是多個(gè)線程排隊(duì)順序經(jīng)過(guò)臨界區(qū)。而 Wait-free 和 Lock-free 的主要區(qū)別也就體現(xiàn)在系統(tǒng)吞吐上。在無(wú)全局停頓的基礎(chǔ)上,Wait-free 進(jìn)一步保障了執(zhí)行任意算法的線程,都應(yīng)該在有限的步驟內(nèi)完成。不只是整體算法時(shí)時(shí)刻刻都存在有效計(jì)算,每個(gè)線程依然是需要持續(xù)進(jìn)行有效的計(jì)算。這就要求多線程在臨界區(qū)內(nèi)不能被細(xì)粒度地串行起來(lái),而必須是同時(shí)都能進(jìn)行有效計(jì)算。雖然理論角度存在不少有 Wait-free 的算法,但大多并不具備工業(yè)使用的價(jià)值。
4、相關(guān)技術(shù)
Lock-free 和 Wait-free 編程中最重要的兩個(gè)相關(guān)技術(shù)就是原子操作和控制 Memory Order。
CPU 保證沒(méi)有線程能觀察到原子操作的中間態(tài),也就是說(shuō)一個(gè)原子操作對(duì)于所有的線程來(lái)說(shuō)要么做了要么沒(méi)做。原子操作主要包括賦值原子操作、Read-Modify-Write(比如C++ 11里的fetch_add)、Compare-And-Swap(比如 C++ 11 里的 Compare_exchange_strong)等操作。原子操作保證了各線程在進(jìn)行共享內(nèi)存的存取的時(shí)候能讀到完整的值。
Memory Order 即內(nèi)存排序,指 CPU 訪問(wèn)主存的順序。可以是編譯器在編譯時(shí)產(chǎn)生,也可以是 CPU 在運(yùn)行時(shí)產(chǎn)生。為了充分利用不用內(nèi)存的總線帶寬,現(xiàn)代處理器大多是亂序執(zhí)行的。無(wú)鎖算法沒(méi)有顯式的鎖,將會(huì)直接觀察到這些和代碼順序不一致的重排,C++ 11 引入的 Memory Order 給使用者提供了一種跨平臺(tái)的通用方法來(lái)限制上述兩種重排。
三
Memory Order
Memory Model 內(nèi)存模型,定義了特定處理器上或者工具鏈上的重排情況。某個(gè)處理器或者工具鏈對(duì)代碼的重排會(huì)嚴(yán)格遵循對(duì)應(yīng)的 Memory Model。這里討論的重排只是針對(duì)單個(gè)線程內(nèi)部在單個(gè)核內(nèi)的指令的執(zhí)行順序問(wèn)題。可以理解為指定 Memory order,就是通過(guò)限制重排來(lái)保證共享數(shù)據(jù)的可見(jiàn)性和正確同步。
1、Reorder 類型和 Memory Order 的強(qiáng)弱
對(duì)內(nèi)存的操作可以概括為讀和寫,可以表示為 Load 和 store 操作,因此 Reorder 也就可以整體上分為以下四種類型:
-
Load-load reorder:兩個(gè)讀操作之間重排;
-
Load-store reorder:原來(lái)在寫操作之前的讀操作重排到之后;
-
Store-load reorder:原來(lái)在讀操作之前的寫操作重排到之后;
-
Store-store reorder:兩個(gè)寫操作之間重排。
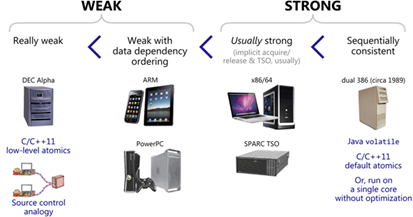
Memory Model 既有軟件層面的 Software Memory Model,又有硬件平臺(tái)的 Hardware Memory Model,下圖中是幾種 CPU 架構(gòu)下的 Hardware Memory Model。
-
DEC Alpha 架構(gòu)下,上述四種 Reorder 都有可能發(fā)生,只保證不改變單線程內(nèi)部的執(zhí)行正確性。
-
ARM 架構(gòu)下的 CPU 也允許四種 Reorder 的發(fā)生,額外保證了數(shù)據(jù)依賴順序。
-
X86/X64 平臺(tái)屬于強(qiáng) Memory Model 的范疇,只可能發(fā)生 Store-load reorder。
-
C++ 11 中原子操作的內(nèi)存序?qū)儆?Software Memory Model 的范疇,在軟件層面進(jìn)行相關(guān)限制,讓 CPU 實(shí)現(xiàn)相應(yīng)操作的效果。
2、Compiler Barrier 與 Runtime Memory Barrier
無(wú)論是哪種 Memory Model 中涉及的重排,都是指的在沒(méi)有其他限制的情況。為了能夠保證程序的正確性,CPU 和編譯器(語(yǔ)言)的設(shè)計(jì)者都預(yù)留了手方法來(lái)改變這些重排,這類方法可以抽象成一個(gè)統(tǒng)一的概念 Barrier:屏障。需要使用者用代碼來(lái)限制編譯階段和運(yùn)行階段的重排,因此可以分為 Compiler Barrier 和 Runtime Memory Barrier。
Compiler Barrier,編譯器層面的屏障,可以防止編譯器在將源碼轉(zhuǎn)換成機(jī)器碼的過(guò)程中重排。簡(jiǎn)單的例子如下:
inta,b;
intmain()
{
a=b+1;
//asmvolatile("":::"memory");
b=0;
return0;
}
對(duì)于以上代碼,使用 gcc 4.9.4 整體不開(kāi)啟優(yōu)化進(jìn)行編譯,得到匯編代碼如下:
$ gcc -S main.cpp
$ cat main.s
...
movl_b(%rip),%eax
addl$1,%eax
movl%eax,_a(%rip)
movl$0,_b(%rip)
movl$0,%eax
popq%rbp
...
同樣使用 gcc 4.9.4 整體開(kāi)啟優(yōu)化進(jìn)行編譯,得到匯編代碼如下:
$gcc–O2-Smain.cpp
$catmain.s
...
movl_b(%rip),%eax
movl$0,_b(%rip)
addl$1,%eax
movl%eax,_a(%rip)
xorl%eax,%eax
...
如果想要整體開(kāi)啟優(yōu)化,但是對(duì)于部分代碼不想要重排,那么就可以使用 Compiler Barrier,在 gcc 里,asm volatile("" ::: “memory”)就是這么一個(gè) Compiler Barrier。在使用 Compiler Barrier 后,使用使用 gcc 4.9.4 整體開(kāi)啟優(yōu)化進(jìn)行編譯,得到匯編代碼如下:
$gcc-O2-Smain.cpp
$catmain.s
...
movl_b(%rip),%eax
addl$1,%eax
movl%eax,_a(%rip)
movl$0,_b(%rip)
xorl%eax,%eax
...
可以看到和未開(kāi)啟編譯優(yōu)化時(shí)的結(jié)果保持一致。
Compiler Barrier 只能保證編譯階段不重排。在多核系統(tǒng)里,光做到這一點(diǎn)還不夠,因?yàn)樗鼪](méi)法對(duì) CPU 核心運(yùn)行時(shí)的重排做出限制。因此,在多核編程中,通常需要同時(shí)對(duì)編譯重排和運(yùn)行時(shí)重排做出限制,需要使用到 Runtime Memory Barrier。
審核編輯 :李倩
-
cpu
+關(guān)注
關(guān)注
68文章
10901瀏覽量
212662 -
架構(gòu)
+關(guān)注
關(guān)注
1文章
519瀏覽量
25512 -
單線程
+關(guān)注
關(guān)注
0文章
17瀏覽量
1782
原文標(biāo)題:一文走進(jìn)多核架構(gòu)下的內(nèi)存模
文章出處:【微信號(hào):OSC開(kāi)源社區(qū),微信公眾號(hào):OSC開(kāi)源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
AUTOSAR架構(gòu)下的多核通信介紹

數(shù)字信號(hào)處理器重新采納多核架構(gòu)
以全新的多核SoC架構(gòu)進(jìn)行LTE開(kāi)發(fā)
嵌入式實(shí)時(shí)系統(tǒng)多核負(fù)載均衡調(diào)度架構(gòu)的相關(guān)資料推薦
介紹在ARM64架構(gòu)下啟動(dòng)多核的兩種方式
多核處理器架構(gòu)及調(diào)試
多核架構(gòu)及編程技術(shù)
多核處理器架構(gòu)及調(diào)試方案
基于共享內(nèi)存多核數(shù)據(jù)結(jié)構(gòu)研究
Linux操作系統(tǒng)知識(shí)講解:走進(jìn)內(nèi)存
NUMA架構(gòu)下的內(nèi)存數(shù)據(jù)庫(kù)命令日志故障恢復(fù)
走進(jìn)多核編程
一文看懂共模電感和差模電感的區(qū)別
基于Tricore架構(gòu)的RTThread多核實(shí)現(xiàn)
基于Tricore芯片的AUTOSAR架構(gòu)下的多核啟動(dòng)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論