") 自動(dòng)駕駛:自動(dòng)泊車之AVM環(huán)視系統(tǒng)算法2
自動(dòng)駕駛:自動(dòng)泊車之AVM環(huán)視系統(tǒng)算法2
本文的內(nèi)容主要講述AVM 3D算法pipeline,一種自研提取角點(diǎn)標(biāo)定方法,汽車輔助視角。每個(gè)部分都涵蓋了完整的算法理論以及部分代碼,適合有一些計(jì)算機(jī)視覺基礎(chǔ)的同學(xué),或許可以給相關(guān)方向的同學(xué)做些參考。
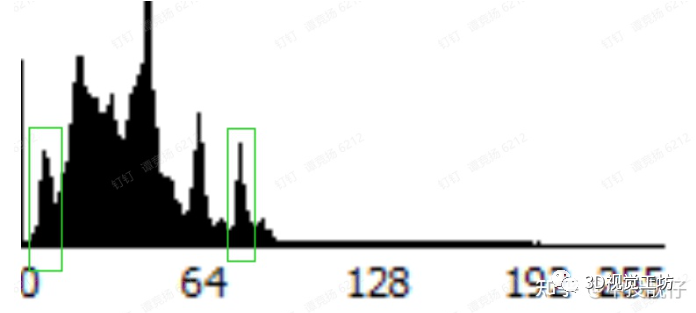
·雙峰自適應(yīng)閾值二值化大體思路為:計(jì)算圖像的亮度直方圖。分別計(jì)算暗區(qū)局部極大值,亮區(qū)局部極大值,即“雙峰”。計(jì)算雙峰亮度的平均值,作為閾值,來對(duì)圖像做二值化。因此稱為“雙峰自適應(yīng)閾值”。
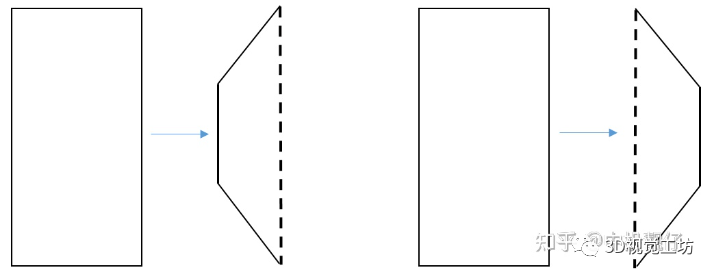
·使用上述約束條件篩選出大方格的角點(diǎn)。綜上,使用這種方法提取出的角點(diǎn)分布得更廣泛,且都在鳥瞰圖的分布區(qū)域,因此拼接融合得效果更佳。 大部分車上的廣角功能是對(duì)魚眼圖直接做了去畸變,這種方法帶來的問題及產(chǎn)生原因如下:·放大上表中普通廣角圖,不難發(fā)現(xiàn)標(biāo)定布前邊緣并不是平直的,它有一定的傾斜。這是因?yàn)橄鄼C(jī)有一個(gè)roll翻滾角,相當(dāng)于人眼沒有水平正視前方,而是歪著腦袋看前面。·在遠(yuǎn)離圖像中心的位置,像素被嚴(yán)重拉伸,這是透視畸變的一種(見附錄),會(huì)導(dǎo)致即便是我們把去畸變圖的分辨率調(diào)整到非常大,在這張圖像上依然不能看到FOV范圍很大的內(nèi)容,如圖所示。
大部分車上的廣角功能是對(duì)魚眼圖直接做了去畸變,這種方法帶來的問題及產(chǎn)生原因如下:·放大上表中普通廣角圖,不難發(fā)現(xiàn)標(biāo)定布前邊緣并不是平直的,它有一定的傾斜。這是因?yàn)橄鄼C(jī)有一個(gè)roll翻滾角,相當(dāng)于人眼沒有水平正視前方,而是歪著腦袋看前面。·在遠(yuǎn)離圖像中心的位置,像素被嚴(yán)重拉伸,這是透視畸變的一種(見附錄),會(huì)導(dǎo)致即便是我們把去畸變圖的分辨率調(diào)整到非常大,在這張圖像上依然不能看到FOV范圍很大的內(nèi)容,如圖所示。
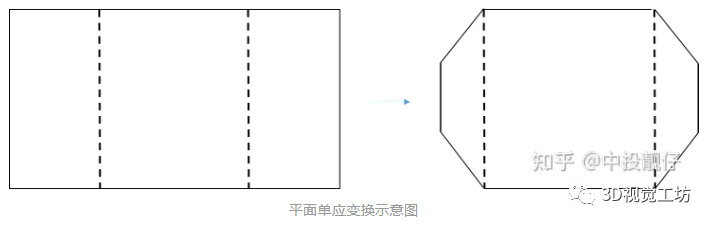
這個(gè)流程與上面的車輪視角的算法流程幾乎是相同的,所有的相機(jī)位姿變換導(dǎo)致的視角轉(zhuǎn)換都可以用這個(gè)流程來實(shí)現(xiàn)。在上面的相機(jī)位姿矯正示意圖中我們可以看到,垂直于地面的墻、柱子的傾斜問題都解決了。被我們用基于相機(jī)位姿矯正的單應(yīng)變換強(qiáng)行掰正了。但是,這個(gè)圖在遠(yuǎn)離圖像中心的邊緣依然存在嚴(yán)重的拉伸。導(dǎo)致即使圖像的分辨率很大,我們可以看到的實(shí)際FOV范圍依然很小。針對(duì)這個(gè)問題,再一次進(jìn)行平面的單應(yīng)變換。·平面單應(yīng)變換 廣角與超廣角實(shí)際的實(shí)現(xiàn)方法如下圖所示,在廣角圖像上選取4個(gè)點(diǎn)(即遠(yuǎn)離圖像中心在圖像左右兩邊的兩個(gè)小長方形),并設(shè)置這四個(gè)點(diǎn)做投影變換的結(jié)果(這4個(gè)點(diǎn)是通過大量實(shí)驗(yàn)調(diào)試出的一組最優(yōu)超參數(shù)),使用這四對(duì)匹配點(diǎn)計(jì)算單應(yīng)矩陣H。即計(jì)算將小長方形壓縮成梯形的單應(yīng)矩陣H。
廣角與超廣角實(shí)際的實(shí)現(xiàn)方法如下圖所示,在廣角圖像上選取4個(gè)點(diǎn)(即遠(yuǎn)離圖像中心在圖像左右兩邊的兩個(gè)小長方形),并設(shè)置這四個(gè)點(diǎn)做投影變換的結(jié)果(這4個(gè)點(diǎn)是通過大量實(shí)驗(yàn)調(diào)試出的一組最優(yōu)超參數(shù)),使用這四對(duì)匹配點(diǎn)計(jì)算單應(yīng)矩陣H。即計(jì)算將小長方形壓縮成梯形的單應(yīng)矩陣H。
一. 一種更優(yōu)的聯(lián)合標(biāo)定方案
1.1 算法原理分析
在前面的工作中,我們調(diào)用opencv函數(shù)findChessboardCorners提取圖像上位于標(biāo)定布中間的棋盤格角點(diǎn),然后計(jì)算投影矩陣H。在SLAM 14講中[1],計(jì)算H就是求解Ax=0這樣一個(gè)問題。其原理就是構(gòu)造一個(gè)最小二乘的形式,用奇異值分解的方式來計(jì)算一個(gè)誤差最小的解。而為了逼近這個(gè)最小誤差,可能造成除了棋盤格角點(diǎn)以外的其他像素值的投影誤差很大。換句話說,由于棋盤格角點(diǎn)集中于鳥瞰圖的中心很小的一部分區(qū)域,如果選擇棋盤格角點(diǎn)進(jìn)行H的計(jì)算,會(huì)導(dǎo)致只有棋盤格附近的區(qū)域能夠進(jìn)行準(zhǔn)確的投影,遠(yuǎn)離該區(qū)域會(huì)有較大誤差。類似于nn的訓(xùn)練數(shù)據(jù)過于局限,訓(xùn)練的模型過擬合了。這也就能夠解釋為什么在之前的工作中,我們的鳥瞰圖拼接區(qū)域總是拼不齊,就是因?yàn)槲覀冞x擇的角點(diǎn)遠(yuǎn)離拼接區(qū)域,計(jì)算出的投影矩陣H在拼接區(qū)域的投影誤差太大。我們開發(fā)了一種基于自動(dòng)提取角點(diǎn)算法的汽車標(biāo)定方法,該方法可以提取標(biāo)定布上拼接區(qū)域黑色方格的角點(diǎn)。如圖所示:

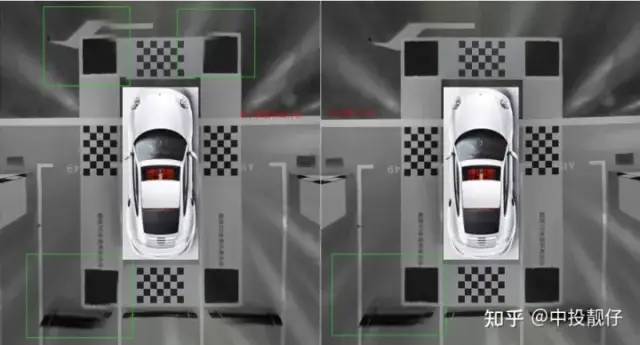
1.2 基于自動(dòng)提取角點(diǎn)算法的汽車標(biāo)定方法

|
1. 雙峰自適應(yīng)閾值二值化 2. 多邊形檢測 3. 四邊形篩選 4. 提取四邊形頂點(diǎn) |

|
1. 多邊形擬合結(jié)果必須為四邊形,即篩選出二值化圖中的四邊形 2. 四邊形面積必須大于某閾值(opencv源碼中這個(gè)超參適用于篩選棋盤格的,我們要把這個(gè)閾值搞得大一些,用于篩選大方格) 3. 相鄰邊長不可相差過多 4. 選取黑色的四邊形,而不是白色的四邊形 5. 限制四邊形分布范圍,即四邊形不能過于靠近圖像邊緣,具體情況與相機(jī)的位姿相關(guān) |
二. AVM輔助視角——基于外參的視角變換
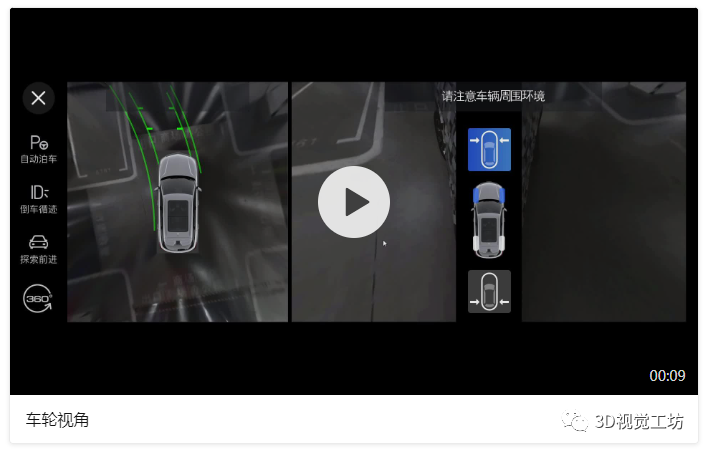
本章節(jié)主要講述單應(yīng)矩陣與PNP的原理,以及它們?cè)贏VM輔助視角中的實(shí)際應(yīng)用,附帶部分代碼。關(guān)鍵詞:單應(yīng)矩陣、PNP、標(biāo)定、廣角、超廣角、車輪視角、越野模式車載魚眼相機(jī)可以獲取到范圍非常大的內(nèi)容,但是魚眼圖像并不能夠在汽車行駛過程中給駕駛員提供符合人類視覺習(xí)慣的視頻圖像,這一章節(jié)主要來講述如何利用魚眼相機(jī)的圖像信息,來提供各種輔助視角。例如:(1)在進(jìn)出車位或經(jīng)過狹小空間時(shí),駕駛員會(huì)更加關(guān)注車輪位置的內(nèi)容,那么我們需要使用某種算法對(duì)左側(cè)、右側(cè)的魚眼相機(jī)拍攝到的內(nèi)容進(jìn)行處理,得到“車輪視角”;

2.1 單應(yīng)矩陣H的原理
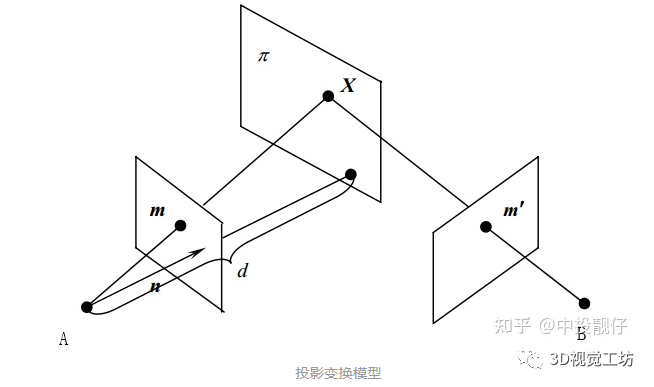
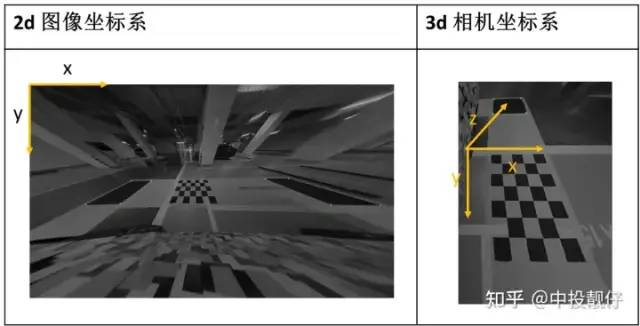
有CV基礎(chǔ)的同學(xué)們大多知道單應(yīng)矩陣表示“一個(gè)平面到另外一個(gè)平面的變換關(guān)系”。這樣的描述是不準(zhǔn)確的,或者如果對(duì)單應(yīng)矩陣僅能說出這些,說明對(duì)單應(yīng)矩陣的認(rèn)識(shí)是片面的。正確的理解應(yīng)該是:H描述的是在不同位姿下的兩個(gè)相機(jī)cam1,cam2拍攝同一個(gè)平面(例如標(biāo)定板),這個(gè)平面在兩個(gè)相機(jī)成像平面上的成像結(jié)果之間的變換關(guān)系。投影變換模型圖如下。以上這段話,被很多人簡單理解成了“H描述的是兩張圖象之間的變換關(guān)系”,這里有兩個(gè)點(diǎn)需要注意:(1)不要忽略掉了前面那部分和相機(jī)投影相關(guān)的物理模型(2)H描述的是空間中的某個(gè)平面分別在兩個(gè)相機(jī)圖像平面上的成像結(jié)果之間的變換,而不是兩個(gè)圖像之間的變換。對(duì)于單應(yīng)矩陣,我們可以思考一個(gè)問題:我們拍攝到的內(nèi)容,大多數(shù)情況下不僅僅包含某一個(gè)平面。而我們?cè)谧鐾队白儞Q的時(shí)候,H就是基于某個(gè)平面計(jì)算出來的,這會(huì)導(dǎo)致雖然圖像中的該平面部分的投影是合理的,但是因?yàn)槠矫嬉酝獾钠渌糠忠廊挥孟嗤腍做投影,這些部分的投影結(jié)果就會(huì)顯得非常的奇怪。相信很多同學(xué)聽說過一個(gè)結(jié)論:基于H的圖像拼接方法,比較適用于視距較遠(yuǎn)的環(huán)境下。這是因?yàn)橐暰噍^遠(yuǎn)的環(huán)境下,拍攝到的景象我們可以近似認(rèn)為它們?cè)谕粋€(gè)平面上,那么我們基于這個(gè)平面計(jì)算出來的H,就幾乎適用于整個(gè)圖像中的內(nèi)容。我們從最基礎(chǔ)的相機(jī)物理模型來推導(dǎo)一遍單應(yīng)矩陣H的公式,這樣有利于我們更深入地理解。(本文僅推導(dǎo)這一個(gè)公式,通過物理模型對(duì)單應(yīng)矩陣進(jìn)行推導(dǎo)對(duì)后面的算法理解十分重要)如圖所示,同一個(gè)相機(jī)在A,B兩個(gè)位置以不同的位姿拍攝同一個(gè)平面:

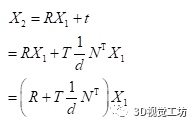
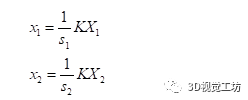
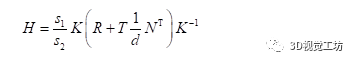
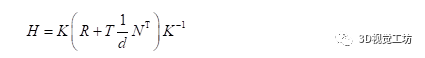
2.2 PNP的原理
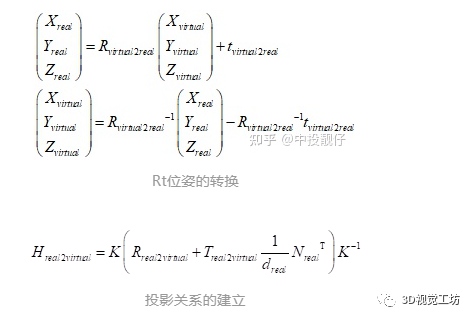
用一句話概括PNP到底做了什么:已知相機(jī)A坐標(biāo)系下的一組三維點(diǎn),以及這組三維點(diǎn)在另外一個(gè)相機(jī)的圖像坐標(biāo)系下的二維坐標(biāo),就可以通過數(shù)學(xué)方法計(jì)算出A、B兩個(gè)相機(jī)之間的位姿R,t。注意R,t是從A->B。公式如下:
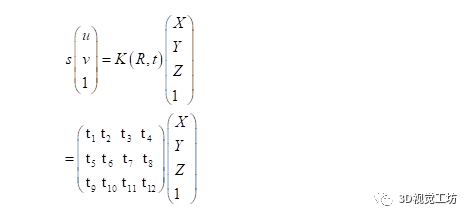
2.3 車輪視角

//函數(shù)定義 void solveRtFromPnP(const vector &corners2D, const vector &obj3D, const Mat &intrinsic, Mat &R, Mat &t) { Mat r = Mat::zeros(3, 1, CV_32FC1); solvePnP(obj3D, corners2D, intrinsic, cv::Mat(), r, t); Rodrigues(r, R); } //函數(shù)調(diào)用 solveRtFromPnP(corners_2D, obj_3D, m_intrinsic_undis, R, t); 以上,我們獲取到了虛擬相機(jī)->真實(shí)部署相機(jī)之間的位姿R,t。至于R,t為什么不是從真實(shí)部署相機(jī)->虛擬相機(jī),可以從PNP算法的公式推導(dǎo)中得知(前面已經(jīng)講過),或者見視覺SLAM第二版P180-P181。再回到投影變換H模型圖中,圖中的A就是虛擬相機(jī),B就是真實(shí)部署相機(jī)。我們已經(jīng)通過PNP計(jì)算出虛擬相機(jī)->真實(shí)部署相機(jī)的R,t。但是我們想要的是如何將真實(shí)相機(jī)拍攝到的某個(gè)平面(對(duì)于車輪視角而言是地面)通過H轉(zhuǎn)換到虛擬相機(jī)的視角下。因此我們需要對(duì)R,t做一些處理,將其轉(zhuǎn)化為真實(shí)部署相機(jī)->虛擬相機(jī)的位姿關(guān)系:公式推導(dǎo):
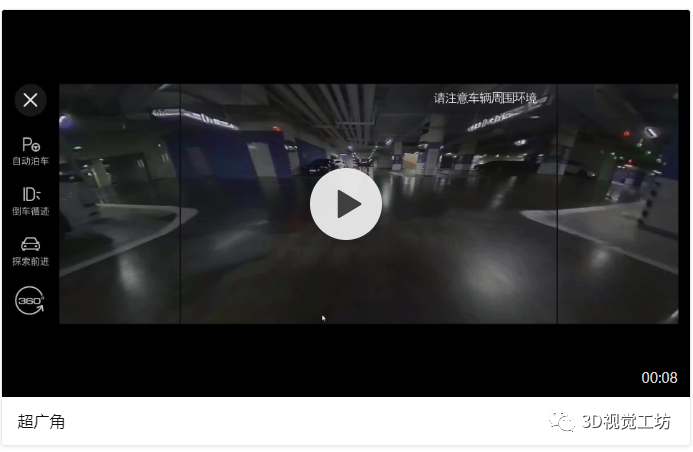
//基于Rt計(jì)算H Mat solveHFromRt(const Mat &R, const Mat &t, const float d, const Mat &n, const Mat &intrinsic) { Mat intrinsic_inverse; invert(intrinsic, intrinsic_inverse, DECOMP_LU); Mat H = intrinsic * (R + t / d * n.t()) * intrinsic_inverse; return H; } PNP求解外參:/****************************************************************************************************************/ //R t:PNP算出的結(jié)果,從虛擬相機(jī)->真實(shí)部署相機(jī)的位姿 //計(jì)算出 真實(shí)部署相機(jī)->虛擬相機(jī)的位姿 Mat R_Camera2Real; invert(R, R_Real2Virtual, DECOMP_LU); Mat t_Real2Virtual = -R_Real2Virtual * t; //虛擬相機(jī)到地面的垂直單位向量 Mat n = (Mat_(3, 1) << 0, 1, 0); //真實(shí)部署相機(jī)到地面的垂直單位向量 n = R * n; // rotation float theta_X = m_wheel_sight_angle / 180.f * 3.14f; Mat R_virtual = (Mat_(3, 3) << 1, 0, 0, 0, cos(theta_X), -sin(theta_X), 0, sin(theta_X), cos(theta_X)); R_Camera2Virtual = R_virtual * R_Camera2Virtual; t_Camera2Virtual = R_virtual * t_Camera2Virtual; //計(jì)算單應(yīng)矩陣H:真實(shí)視角->虛擬視角 Mat H = solveHFromRt(R_Camera2Virtual, t_Camera2Virtual, d, n, intrinsic); 幾點(diǎn)說明:·n(0,1,0),說明單應(yīng)矩陣選取的平面為地面。不要忘了我們最開始強(qiáng)調(diào)的,H描述的是在不同位姿下的兩個(gè)相機(jī)cam1,cam2拍攝同一個(gè)平面(例如標(biāo)定板),這個(gè)平面在兩個(gè)相機(jī)成像平面上的成像結(jié)果之間的變換關(guān)系。因此這個(gè)平面的選擇,對(duì)最終的投影結(jié)果有很大的影響。車輪視角選取地面作為我們要進(jìn)行投影的平面,最終的效果非常nice。·代碼中還包含rotation部分,這是因?yàn)槲覀冊(cè)跇?biāo)定的時(shí)候讓虛擬相機(jī)朝正前方,但顯然理想的車輪視角相機(jī)應(yīng)該朝向車輪,即應(yīng)加一個(gè)俯仰角pitch。2.4 超級(jí)廣角
這部分我們是對(duì)標(biāo)現(xiàn)有某德系車載超廣角功能進(jìn)行實(shí)現(xiàn)的,相比于直接做去畸變的廣角效果,超廣角的優(yōu)勢在于·糾正了相機(jī)翻滾角帶來的視覺不適·糾正了左右兩側(cè)遠(yuǎn)離圖像中心的拉伸效果·糾正了豎直方向由于透視畸變“近大遠(yuǎn)小”帶來的柱體傾斜效果大部分車上的廣角功能是對(duì)魚眼圖直接做了去畸變,這種方法帶來的問題及產(chǎn)生原因如下:·放大上表中普通廣角圖,不難發(fā)現(xiàn)標(biāo)定布前邊緣并不是平直的,它有一定的傾斜。這是因?yàn)橄鄼C(jī)有一個(gè)roll翻滾角,相當(dāng)于人眼沒有水平正視前方,而是歪著腦袋看前面。·在遠(yuǎn)離圖像中心的位置,像素被嚴(yán)重拉伸,這是透視畸變的一種(見附錄),會(huì)導(dǎo)致即便是我們把去畸變圖的分辨率調(diào)整到非常大,在這張圖像上依然不能看到FOV范圍很大的內(nèi)容,如圖所示。


| 1. 假設(shè)虛擬相機(jī)的位姿為朝向正前方,光軸與正前方的那面墻垂直,坐標(biāo)系x、y、z如上表中“位姿校正的廣角”所示 2. 標(biāo)定出地面上那些角點(diǎn)在虛擬相機(jī)坐標(biāo)系下的三維坐標(biāo) 3. 在真實(shí)相機(jī)拍攝的圖像中提取角點(diǎn)的圖像坐標(biāo)(實(shí)際上在第一章的標(biāo)定過程中已經(jīng)完成) 4. PNP計(jì)算虛擬相機(jī)->真實(shí)相機(jī)的位姿 RT 5. 計(jì)算真實(shí)相機(jī)->虛擬相機(jī)的位姿rt 6. 我們選定的是垂直于相機(jī)光軸的平面,計(jì)算這個(gè)平面從真實(shí)相機(jī)->虛擬相機(jī)的單應(yīng)矩陣H,在我們的算法中,這個(gè)平面距離相機(jī)的距離d=10m,這是一個(gè)經(jīng)驗(yàn)值。 |
廣角與超廣角實(shí)際的實(shí)現(xiàn)方法如下圖所示,在廣角圖像上選取4個(gè)點(diǎn)(即遠(yuǎn)離圖像中心在圖像左右兩邊的兩個(gè)小長方形),并設(shè)置這四個(gè)點(diǎn)做投影變換的結(jié)果(這4個(gè)點(diǎn)是通過大量實(shí)驗(yàn)調(diào)試出的一組最優(yōu)超參數(shù)),使用這四對(duì)匹配點(diǎn)計(jì)算單應(yīng)矩陣H。即計(jì)算將小長方形壓縮成梯形的單應(yīng)矩陣H。
Mat H_left = getPerspectiveTransform(p_src_left, p_dst_left); Mat H_right = getPerspectiveTransform(p_src_right, p_dst_right);三. 基于外參的3D 紋理映射方法
單目相機(jī)是丟失了深度信息的,計(jì)算機(jī)圖形學(xué)中經(jīng)常會(huì)使用將紋理圖映射到某個(gè)3D模型上的方法,呈現(xiàn)出一種偽3D的效果,即紋理映射。在AVM中,通常使用將相機(jī)捕捉到的圖像當(dāng)作紋理,以某種方式映射到 3D 碗狀模型上以呈現(xiàn)出一種3D 環(huán)視的效果。下面詳細(xì)講述下算法實(shí)現(xiàn):3.1 3D模型
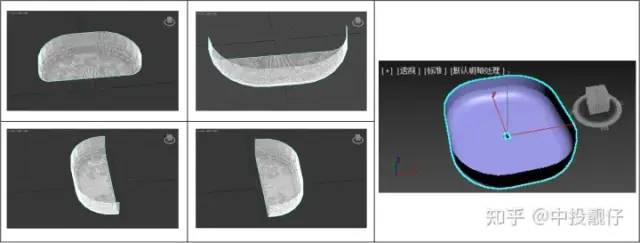
3.2 紋理映射
以前置相機(jī)為例,詳細(xì)描述3D模型與相機(jī)圖像之間的紋理映射關(guān)系:
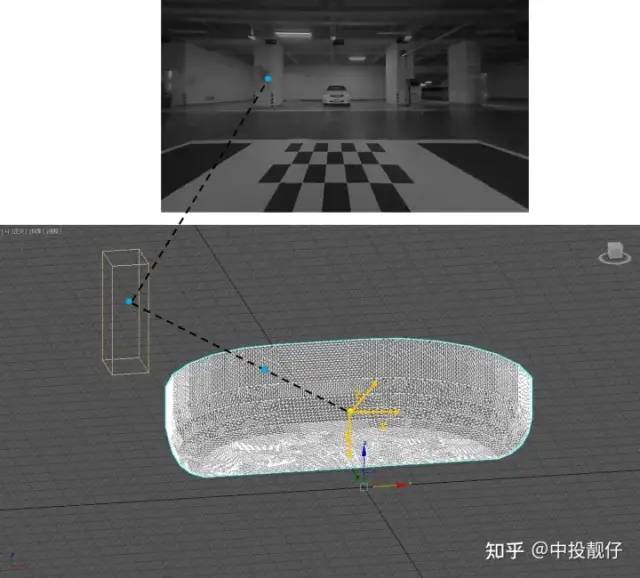
//calculate pose solveRtFromPnP(img_corners, obj_corners, intrinsic_undis, R, t); //3dsmax->camera Mat pts_3DsMax = (Mat_<float>(3, 1) << vertex[i].x, vertex[i].y, vertex[i].z); Mat camera_points = R * pts_3DsMax + t; //camera coordinate ->img coordinate Mat coor = intrinsic_undis * camera_points / camera_points.at<float>(2, 0); 上述代碼將解析出來的3dsmax坐標(biāo)系下的 3d碗模型的頂點(diǎn)三維坐標(biāo)轉(zhuǎn)換到相機(jī)坐標(biāo)系下,然后通過相機(jī)內(nèi)參轉(zhuǎn)換到圖像坐標(biāo)系。最終建立起3d碗模型與圖像紋理之間的映射關(guān)系。算法流程如下:算法流程| 1. 標(biāo)定3dsmax坐標(biāo)系下 標(biāo)定布上角點(diǎn)的三維坐標(biāo)。(即車身中心為原點(diǎn)的車身坐標(biāo)系) 2. 檢測相機(jī)拍攝到圖像中標(biāo)定布上角點(diǎn)的圖像坐標(biāo)。(第一章中已標(biāo)定) 3. 利用1、2的坐標(biāo)信息,通過PNP計(jì)算出 3dsmax坐標(biāo)系與相機(jī)坐標(biāo)系之間的位姿關(guān)系 R,t 4. 解析3d碗狀模型的obj文件 5. 將解析出來的3d碗狀模型的頂點(diǎn)三維坐標(biāo),通過R,t轉(zhuǎn)換到相機(jī)坐標(biāo)系下 6. 通過內(nèi)參將相機(jī)坐標(biāo)系的坐標(biāo)轉(zhuǎn)換到圖像坐標(biāo)系,建立起3d模型與相機(jī)圖像之間的紋理映射關(guān)系 |
3.3 融合
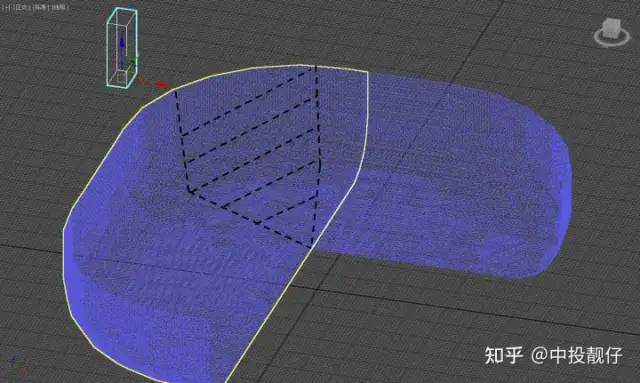
3.4 3D AVM算法存在的問題
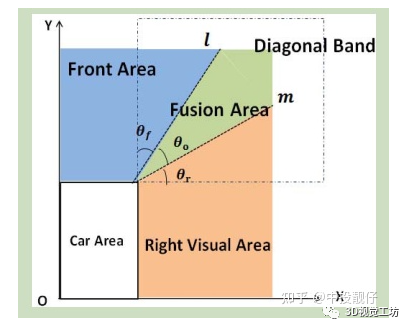
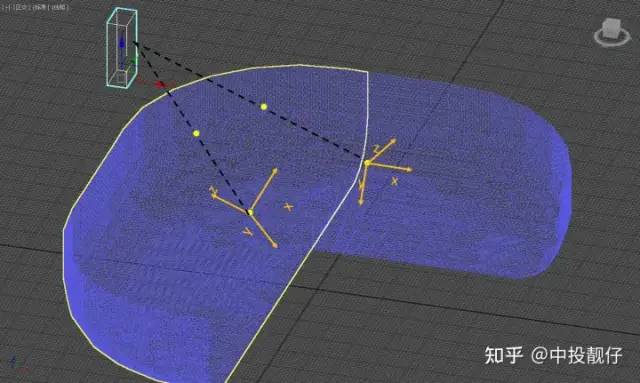
在討論這個(gè)問題之前,我們首先要理解相機(jī)坐標(biāo)系。相機(jī)坐標(biāo)系一般x為朝右,y為朝下,z為朝向正前方。圖中標(biāo)記的兩個(gè)坐標(biāo)系分別為汽車前置攝像頭、左側(cè)攝像頭的位姿。一個(gè)安裝在汽車前方朝向前下方,一個(gè)安裝在汽車左側(cè)后視鏡朝向左下方。
四 附錄
透視畸變
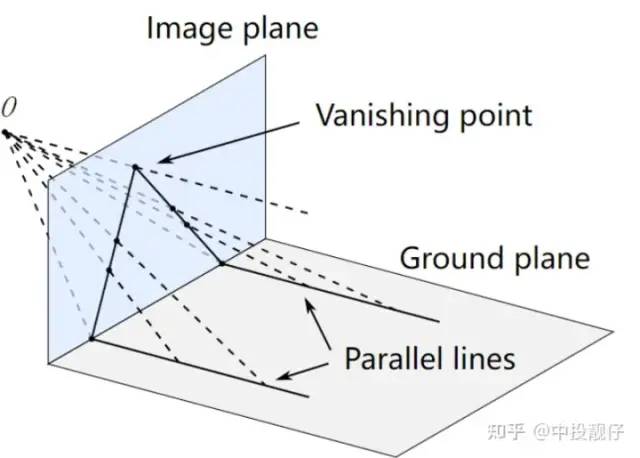
·“近大遠(yuǎn)小”“近大遠(yuǎn)小”表達(dá)的是:同一個(gè)物體,在遠(yuǎn)處的位置投影到相機(jī)平面上的大小要小于在近處的位置。例如,車道線投影到圖像上并不是平行線,會(huì)交于一點(diǎn)。下圖中O為相機(jī)原點(diǎn),Image plane為相機(jī)成像平面,parallel lines為現(xiàn)實(shí)世界中兩條平行線。這兩條平行線投影到image plane上,距離相機(jī)越遠(yuǎn)的位置,其間距投影到image plane上的長度越短,最后匯聚到一點(diǎn),即“消失點(diǎn)”。這個(gè)現(xiàn)象就類似于我們對(duì)圖像做去畸變后,汽車前方兩個(gè)垂直的柱子在圖像中是斜的,最終會(huì)交于一點(diǎn)。但是如果相機(jī)光軸垂直于地面,車道線在圖像上的成像結(jié)果就是平行的,類似于BEV。所以,我們?cè)谧龀瑥V角功能的時(shí)候,要對(duì)相機(jī)做位姿矯正,使相機(jī)的光軸朝向正前方,這樣得到的圖像結(jié)果中柱子就不會(huì)傾斜。
五 總結(jié)
本篇本章為avm系列的第二篇,至此AVM主要的算法原理已經(jīng)講述完畢,包含有:相機(jī)模型、相機(jī)內(nèi)外參標(biāo)定、相機(jī)聯(lián)合標(biāo)定方法、魚眼去畸變、投影變換、光流、拼接融合、PNP、3D紋理映射、上帝視角、3d視角、廣角、超廣角、車輪視角等。后續(xù)還要做一些其他工作,例如:亮度一致調(diào)整、基于車道線的道路自標(biāo)定、動(dòng)態(tài)拼接線、相機(jī)模型優(yōu)化等。希望以后還有機(jī)會(huì)和同學(xué)們交流,共同進(jìn)步!審核編輯 :李倩
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請(qǐng)聯(lián)系本站處理。
舉報(bào)投訴
-
算法
+關(guān)注
關(guān)注
23文章
4612瀏覽量
92894 -
自動(dòng)泊車
+關(guān)注
關(guān)注
0文章
104瀏覽量
13684 -
自動(dòng)駕駛
+關(guān)注
關(guān)注
784文章
13812瀏覽量
166457
原文標(biāo)題:自動(dòng)駕駛:自動(dòng)泊車之AVM環(huán)視系統(tǒng)算法2
文章出處:【微信號(hào):3D視覺工坊,微信公眾號(hào):3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
FPGA在自動(dòng)駕駛領(lǐng)域有哪些應(yīng)用?
是FPGA在自動(dòng)駕駛領(lǐng)域的主要應(yīng)用:
一、感知算法加速
圖像處理:自動(dòng)駕駛中需要通過攝像頭獲取并識(shí)別道路信息和行駛環(huán)境,這涉及到大量的圖像處理任務(wù)。FPGA在處理圖像上的運(yùn)算速度快,可并行性強(qiáng),且功耗
發(fā)表于 07-29 17:09
FPGA在自動(dòng)駕駛領(lǐng)域有哪些優(yōu)勢?
可以根據(jù)自動(dòng)駕駛系統(tǒng)的具體需求,通過編程來配置FPGA的邏輯功能和連接關(guān)系,以適應(yīng)不同的應(yīng)用場景和算法變化。這種靈活性使得FPGA能夠快速適應(yīng)自動(dòng)駕駛技術(shù)的快速發(fā)展和變化。
低延遲:
發(fā)表于 07-29 17:11
自動(dòng)駕駛真的會(huì)來嗎?
實(shí)際上,按照美國高速公路安全委員會(huì)(NHTSA)的5個(gè)分級(jí),特斯拉所使用的自動(dòng)駕駛屬于第2級(jí)別的“混合功能自動(dòng)化”,該級(jí)別主要包含能同時(shí)提供組合式的自動(dòng)化功能。比如
發(fā)表于 07-21 09:00
細(xì)說關(guān)于自動(dòng)駕駛那些事兒
輔助系統(tǒng)系統(tǒng))用到的技術(shù)重迭。自駕車如何看見世界為什么要這么多種傳感器?優(yōu)缺點(diǎn)互補(bǔ)目前多數(shù)車商在量產(chǎn)車中配備的“自動(dòng)駕駛”功能,包含特斯拉、Volvo、Mercedes-Benz、奧迪等,事實(shí)上就是搭載
發(fā)表于 05-15 17:49
自動(dòng)駕駛的到來
距離,更寬的速度探測范圍,以及更高的距離、速度及角度分辨率。 另外,隨著V2V,V2X的普及,自動(dòng)駕駛所需要處理的實(shí)時(shí)數(shù)據(jù)將呈現(xiàn)級(jí)數(shù)增長,這對(duì)處理芯片的性能也提出了更高的要求。ADI可以提供獨(dú)具特色
發(fā)表于 06-08 15:25
即插即用的自動(dòng)駕駛LiDAR感知算法盒子 RS-Box
,即可快速、無縫地將激光雷達(dá)感知模塊嵌入到自己的無人駕駛方案中,真正實(shí)現(xiàn)“一鍵獲得自動(dòng)駕駛激光雷達(dá)環(huán)境感知能力”。RS-BoxLiDAR感知算法專業(yè)硬件平臺(tái)RS-Box 由嵌入式硬件平臺(tái)、獨(dú)立操作
發(fā)表于 12-15 14:20
UWB主動(dòng)定位系統(tǒng)在自動(dòng)駕駛中的應(yīng)用實(shí)踐
,可稱為輔助駕駛。比如自適應(yīng)巡航、自動(dòng)緊急剎車等,系統(tǒng)開始對(duì)車輛有主動(dòng)的操控行為;L2系統(tǒng)能自動(dòng)駕駛
發(fā)表于 12-14 17:30
如何讓自動(dòng)駕駛更加安全?
自動(dòng)駕駛、完全自動(dòng)駕駛。第四級(jí)別是汽車駕駛自動(dòng)化、智能化程度最高級(jí)別,也就是通常所說的無人駕駛。現(xiàn)實(shí)中,部分
發(fā)表于 05-13 00:26
自動(dòng)駕駛汽車的處理能力怎么樣?
功能;但作為一個(gè)行業(yè),我們僅僅是才觸及ADAS系統(tǒng)的表面,更不用說完全自主駕駛了。示意圖:自動(dòng)駕駛的五個(gè)級(jí)別自動(dòng)駕駛的級(jí)別
發(fā)表于 08-07 07:13
聯(lián)網(wǎng)安全接受度成自動(dòng)駕駛的關(guān)鍵
隨著時(shí)代的演進(jìn)與汽車工業(yè)技術(shù)、機(jī)器視覺系統(tǒng)、人工智能和傳感器相關(guān)技術(shù)上不斷創(chuàng)新與進(jìn)步,無人自動(dòng)駕駛汽車已不是一件遙不可及的夢想,Google與國際車廠相繼針對(duì)自動(dòng)駕駛技術(shù)致力研究開發(fā),進(jìn)一步讓
發(fā)表于 08-26 06:45
自動(dòng)駕駛系統(tǒng)設(shè)計(jì)及應(yīng)用的相關(guān)資料分享
作者:余貴珍、周彬、王陽、周亦威、白宇目錄第一章 自動(dòng)駕駛系統(tǒng)概述1.1 自動(dòng)駕駛系統(tǒng)架構(gòu)1.1.1 自動(dòng)駕駛
發(fā)表于 08-30 08:36
LabVIEW開發(fā)自動(dòng)駕駛的雙目測距系統(tǒng)
LabVIEW開發(fā)自動(dòng)駕駛的雙目測距系統(tǒng)
隨著車輛駕駛技術(shù)的不斷發(fā)展,自動(dòng)駕駛技術(shù)正日益成為現(xiàn)實(shí)。從L2級(jí)別的輔助
發(fā)表于 12-19 18:02
車輛自動(dòng)駕駛技術(shù)之自動(dòng)記憶泊車原理分析
自動(dòng)記憶泊車是車輛自動(dòng)駕駛技術(shù)的重要應(yīng)用。相關(guān)技術(shù)中,為了實(shí)現(xiàn)自動(dòng)記憶泊車,一般需要先生成泊車地
發(fā)表于 02-05 11:05
?1264次閱讀
基于自動(dòng)泊車的自動(dòng)駕駛控制算法設(shè)計(jì)與研究
介紹了自動(dòng)泊車系統(tǒng)的硬件架構(gòu),在此基礎(chǔ)上,對(duì)自動(dòng)泊車控制算法進(jìn)行了設(shè)計(jì)與研究,包括APA





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論