 解析Armv8.1-M的一些特性
解析Armv8.1-M的一些特性
簡單闡述下ARMv8.1-M的一些特性,更多的特性及其詳細信息,請查看Armv8-M Architecture Reference Manual-DDI0553B_m。
1. MVE(M-Profile Vector Extension) or Helium technology
MVE其實就是ARM-M系列的SIMD特性,使得M-profile processor在DSP和AI等應用領域具有更強的處理能力。
8個128bit的vector size,可以拆成多個elements。
lane predication,適用code形式:if (a[i] != 0) then b[i]=a[i]*b[i],當然還有其它變形形式,這時候需要結合VPTE指令來配合。
Vector gather load和vector scatter store,如VLDRB, VLDRH, VLDRW, VLDRD (vector)和VSTRB, VSTRH, VSTRW, VSTRD (vector)等。
MVE interleaving/de-interleaving loads and stores,如VLD2/VLD4和VST2/VST4等。
Beatwise operation,因為vector可能的一條指令會執行多個步驟,如果在執行期間有中斷,可以用ECI寄存當前instruction執行到哪個步驟了。
Support Circular Buffer,combine an instruction that generates wrapping offsets(VIWDUP) with a scatter‐gather instruction to access data at these offsets。
2. LoB/Loop Tail Predication/BF
LoB/Loop Tail Predication/BF可以用于提高loops循環和branches分支的效率,減少不需要耗在control flow指令上的時間。
Loop iteration optimization: LoB,在LO_BRANCH_INFO寄存器里存入end_addr和jump_addr,然后next instruction的address匹配上end_addr就可以直接跳轉了,甚至都不需要去去LE跳轉指令了。減少在必須要的循環控制指令上的時間消耗。需要用到WLS和LE指令。
Loop Tail Predication,假如處理的elements個數不是vector length的整數倍內,例如vector length=4,但要處理7個elements?一種方法就是最后一個使用普通的非vector去處理,前面的仍然用vector處理。另一種更好的方法是MVE中引入了WLSTP/LETP指令對,允許loop迭代中的最后一條vector instruction只處理remaining elements,在loop開始之前用WLSTP設置LR寄存器的值為多少個要處理的elements,每循環一次,LETP對LR減去vector的elements個數。
Branch feature:類似于提供“variable length delay slots” – to further eliminate bubbles caused by branch instructions (but only direct branches), since we already have the “LO_BRANCH_INFO” hardware available and can double use it to squeeze out a bit more performance.BFX指令執行的時候,會設置LO_BRANCH_INFO去指示在哪一個address上會發生跳轉,因此當執行執行到該address時,就可以執行跳轉了,甚至都不需要取和譯碼BX LR指令了,因此減少因為執行分支而造成的branch penalty(通常那些已經取的instruction會被處理為Bubbles)。如果在BFX和BX期間發生interrupt了,那么LO_BRANCH_INFO會被清除,這時候就需要BX LR了。如果在processor中不支持Branch Feature這個特性,那么將被實現為NOP。
3. Security 由于越來越多的MCU會運行第三方軟件和連接到互聯網上,如何保證不被黑客攻擊也成了重要的問題。
Execution permission:例如在v8.1-M里有PXN/UXN,減少被利用堆棧溢出攻擊而導致的安全問題。PXN是Privileged Execute-Never(這個是因為有些code就是想讓它在non-priv模式下執行,來限制訪問權限,防止資源受到破壞),UXN是non-Privileged Execute-Never。在MPU_RLAR寄存器中有PXN bit,如果某個region的該bit置為1,那么privilege去訪問該region的code會fault exception。
V8.2-M PAC(Pointer Authentication): 減少利用RoP(Return-oriented Programming)攻擊導致的安全問題 。將會對return address(pointer)進行加擾,然后要返回時去除擾動,如果認證通過,那么就正常返回,反之報出exception。
V8.2-M BTI(Branch Target Instructions): 減少利用JoP(Jump-oriented Programming)攻擊導致的安全問題。BIT的基本思想就是限制indirect branch只能跳轉到特定的address空間上(only branching to allowed “landing pad instructions”)。
DIT(Data Independent Timing):同樣的instruction可能會花費不同的執行時間,例如處理11和9999999999的算術運算占用時間不一樣的,這樣可能會暴露data信息給黑客。因此在AIRCR寄存器中增加了DIT bit,如果使能DIT功能,那么所有ALU instructions的執行時間才會采用最長的cycle數,也就是通過降低performance來換取安全。
UDE(Unprivileged Debug Extension):在v8.0-M中,如果secure debug打開,那么software開發人員對priv和un-priv的secure world有完全的debug訪問權限。但是,如果禁用了secure debug,那么debugger將不能訪問所有的secure world。在v8.1-M中新增了更細粒度的debug方式(UDE),當secure debug被關閉了,secure priv software可以通過DAUTHCTRL寄存器的UIDEN和UIDAPEN來使能UDE。這樣也可以使用unpriv去debug一些library code的了,而不是局限于privilege模式才能debug。另外說下,ARMv8在handler mode下是privilege的,在thread mode下,可能是priv或un-priv,取決于CONTROL寄存器的值。
4. 附注
在ARM-M手冊中涉及到lanes、beats和elements的概念。
operation的lane寬度是由正在執行的instruction決定的。允許的lane寬度和每一個beat進行的lane operation如下:1個beat是32bit,lane width可以有8/16/32/64bit.
For a 64-bit lane size, a beat performs half of the lane peration.
For a 32-bit lane size, a beat performs a one lane operation.
For a16-bit lane size, a beat performs a two lane operations.
For an 8-bit lane size, a beat performs a four lane operations.
elements就是表示有多少個data會放在每個lane中。比如lane=16bit,那么element的size就為16bit(2Byte, size=2’b01)。其它類似。因為lane最大為64bit,也就是說elements最大也就是64bit(4Byte, size=2’b11)。
雖然vector instruction可以同時進行多個elements的運算,有時候element size(esize)可以為32bit,但要運算的data實際為16bit,如VLDRH,這時候會對從memory里load過來的data進行zero或sign-extended,然后才放到vector register。這個實際給每個element load的data大小就是msize,因此msize肯定不大于esize的。總得來說,msize永遠不會大于esize,如果msize
當然,在processor實現時,不只是每一個beat只load一個msize大小的data,這樣效率太低,如果在data width允許的情況下,可以load多個msize大小的data,也就是一次搞定multiple elements。
我們假設一次實際load的data為dsize,對scalar來說,由于不會進行vector操作,esize沒什么用,msize也永遠等于dsize。對vector來說,vector register存在多個elements的操作,如果esize用于表示每個element的大小,msize是element中真正會填充的數據大小,如果dsize>msize,也就是說每一次load的data其實可以填充多個elements的,比如dsize=Word, msize=Byte, esize=Byte,那么只需要load 4次data就可以填滿1個register vector了,如果每次load的size為msize(Byte),那么需要load 16次才可以填滿,想想就知道效率很低的。
如果dsize
不過有一點要注意,在做對齊檢查和atomicity分析時,由于實際其實就是要load msize大小的數據,dsize只是投機多搞一些數據回來,因此檢查和分析還是要按msize來的。
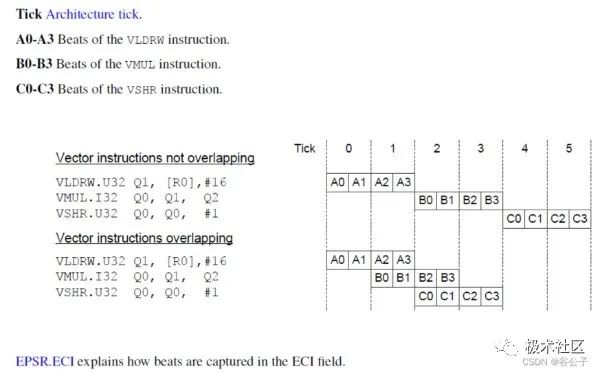
Vector instruction涉及到128bit,也就是有4個beats,因此是從beat0到beat3順序執行的。
在每一個architecture tick下,會執行多少個beat,表征了該system是多個beat。如下:
In a single-beat system, one beat might occur for each tick.
In a dual-beat system, two beats might occur for each tick.
In a quad-beat system, four beats might complete for each tick.
ARM的cortex-M55就是一個dual-beat的processor。在dual-beat overlap system中,意味著上一條vector instruction的最后two beats可以和后一條vector instruction的two beats可以重疊起來,加快執行效率。以下是dual-beat system在每一個architecture tick下,執行的示意圖。
如果data dependency是以beat粒度,而不是instruction粒度進行的,architecture是允許vector instructions有overlap的。在每一個architecture tick下,architectural instruction的重疊情況可由EPSR.ECI值來表示。
審核編輯:湯梓紅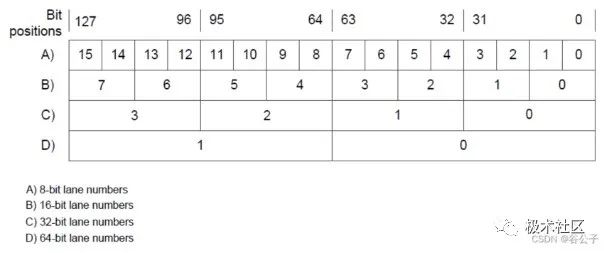

-
dsp
+關注
關注
553文章
7998瀏覽量
348925 -
mcu
+關注
關注
146文章
17148瀏覽量
351197 -
ARM
+關注
關注
134文章
9097瀏覽量
367555 -
寄存器
+關注
關注
31文章
5343瀏覽量
120365 -
ARMv8
+關注
關注
1文章
35瀏覽量
14158
原文標題:學習分享 | Armv8.1-M的一些特性
文章出處:【微信號:Ithingedu,微信公眾號:安芯教育科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
keil mdk的一些常見錯誤解析
使用ISE 13.3更改8.1 FIFO IP內核中的一些參數可能有什么問題?
ARMv8-A AArch32主要特性
你知道ARM Cortex-M55處理器的新功能都有哪些嗎
使用GCC10充分利用Arm架構的案例
Armv8.1-M PAC和BTI擴展簡析
介紹Armv8.6-A引進的一些新功能的概況
ARMv8-M處理器故障處理和檢測
Armv8.1-M性能監控用戶指南
Arm Cortex-M55處理器數據集
模擬電路的一些簡單的特性
下一代Armv8.1-M架構能夠提升最小型邊緣設備的機器學習能力

如何克服Amdahl定律的影響呢?





 工商網監
工商網監
評論