 Arm微架構之Armv9時代
Arm微架構之Armv9時代
1、引言
在上一篇文章“從A76到A78——在變化中學習Arm微架構”中,我們了解了Arm處理器微架構的基本組成,介紹了Armv8架構最后幾代經典處理器架構。現在,Arm公司已經在2021年3月推出了其最新的Armv9架構系列處理器,距上一代Armv8系列架構發布相隔了整整10年時間。新一代的Armv9產品,不但會帶來更強大的計算性能,在安全、AI等領域也帶來了全新的設計。可以說,Armv9系列繼承了Armv8架構的優勢,同時也為Arm公司的下一個十年拉開了帷幕。本文將著重介紹基于Armv9架構的A710、A715、A510等處理器架構,讓大家了解Armv9架構和Armv8架構的差異。
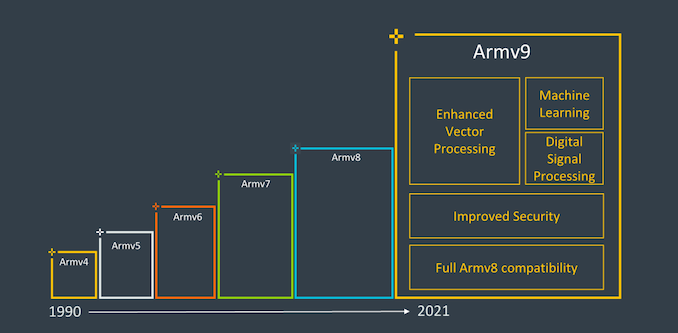
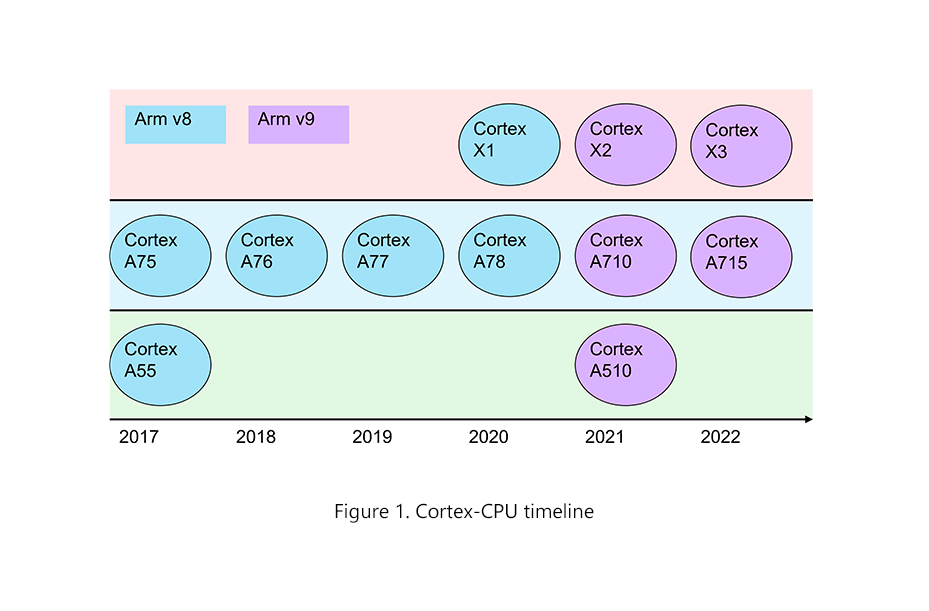
2、Arm的Cortex-X定制CPU計劃
在介紹Armv9系列前,我們先看一下ARM的Cortex-X定制CPU計劃。Cortex-X方案先于Armv9發布,在Arm發布A78時,同時也發布了Cortex-X1這一顆性能強大的CPU,后續大家習慣稱之為超級大核。從此,旗艦處理器的架構從4+4(4大+4小)逐步變成了1+3+4(1超大+3大+4小)架構。Cortex-X計劃不但帶來了如X1這樣的超級大核心設計,也允許廠商參與定制Cortex-X系列的核心設計。X系列超級大核心相比A系列大核心,擁有更大的芯片面積,同時支持更多的發射和解碼能力,還增加了緩存和ROB空間等,圖中Arm宣稱X1相比A78的性能提升超過30%。后續計劃專門寫一篇文章介紹Cortex-X的系列處理器。

3、64bit應用生態
32bit和64bit應用兼容問題已經歷經多年討論,主流的蘋果和安卓平臺都明確表示要切換到64bit以提供更大的應用訪問空間和支持處理器的最新特性。蘋果公司在2017年的iOS11中就強制要求開發者切換到64bit應用,谷歌公司則要求安卓開發者在2021年將上傳的應用完全切換到64bit。但是,由于安卓系統的開放性,應用商店的多樣性,且開發者可以自由安裝應用,市場上的應用商店的存量應用更新64bit的速度較慢,直到2021年的Armv9處理器,我們明確看到了存量32bit應用對于使用的影響。
2021年,Armv9第一代的A510處理器和Cortex-X2處理器不支持運行32bit應用,但是A710處理器是可以支持的,所以采用X2+A710+A510的處理器(例如驍龍8Gen1)只支持在3顆A710中運行32bit應用,運行32bit應用時存在高耗電和卡頓的風險。
2022年,Armv9第二代的A510r處理器增加了32bit應用支持,但是Cortex-X3和A715處理器不支持運行32bit處理器,所以如果采用X3+A715+A510r(1+3+4)的處理器(例如天璣9200)只支持在4顆A510r小核運行32bit應用,運行32bit應用會有嚴重的卡頓風險(MTK也提供了對應的優化方案)。相信高通也提前預判到了這個風險,在2022年的驍龍8Gen2設計中,采用了X3+A715+A710+A510r(1+2+2+3)的架構,提供了2顆兼容32bit的A710大核心,從另一個角度消解了大核心無法運行32bit應用的風險。
希望安卓和Arm可以在2023年實現純64bit的計劃。

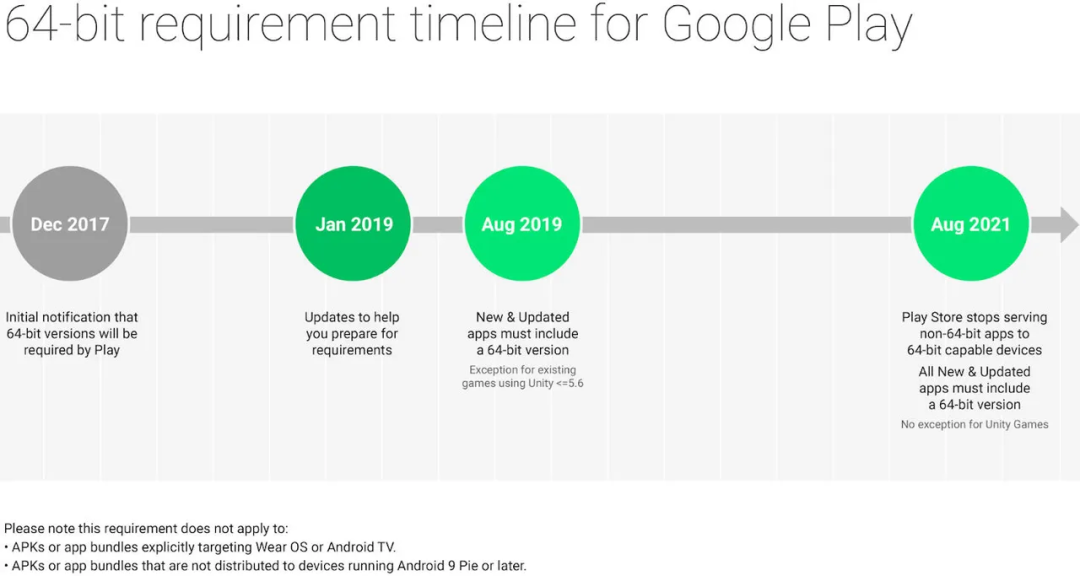
4、SVE2擴展指令集
Armv9和Armv8在核心指令集上變化不大,依然采用AArch64。Arm自v7開始推出的NEON指令集作為向量擴展指令,可以大幅度提高多媒體運行的效率,無疑是非常成功的,這次Armv9給大家帶來了全新的SVE2(Scalable Vector Extension 2)擴展指令集。
SVE2是基于SVE的擴展,實際上SVE在2016年就有發布,SVE2在2019年也專門對外進行過發布。我們在了解處理器微架構的執行單元時,可以看到浮點運算單元中提供了多種SIMD的運算模塊。SVE2有三個特點,一是基于SVE指令集的擴展,二是提升了擴展性,三是支持更多類型任務的矢量化運算。舉個例子,NEON指令是固定的128bits,SVE2指令則可以從128bits到擴展到最大2048bits。

雖然擴展指令集聽起來很香,實際使用起來并不是在編譯器中打開編譯開關就可以高枕無憂的,編譯器雖然提供了一些基礎能力,可將一些固定計算邏輯轉換成擴展指令集,但若想要充分利用擴展指令集的能力,還是需要開發者充分學習擴展指令集的能力,通過專用的編程語法(Intrinsics )甚至去寫擴展指令集的專用匯編,通過合理的邏輯排序組合,充分利用指令集的優勢,才能獲得最佳的效果。
5、聊聊Arm的產品代號
A710的產品代號叫做Matterhorn(馬特洪峰),海拔4478米,阿爾卑斯山系最著名的山脈之一。
A715的產品代號叫做Makalu(馬卡魯峰)海拔8463米,屬于喜馬拉雅山脈,是世界第五高峰。
A510的產品代號叫做Klein(克萊因),CK里面的K就是這個單詞。
A715的下一代產品代號叫做Hunter(獵人),Hunter下一代產品代號叫做Chaberton。
A510的下一代產品代號則叫做Hayes(海因斯)。
有時候我不禁聯想,Matterhorn和Makalu兩座高山,可能代表著工程師想挑戰的高度吧!
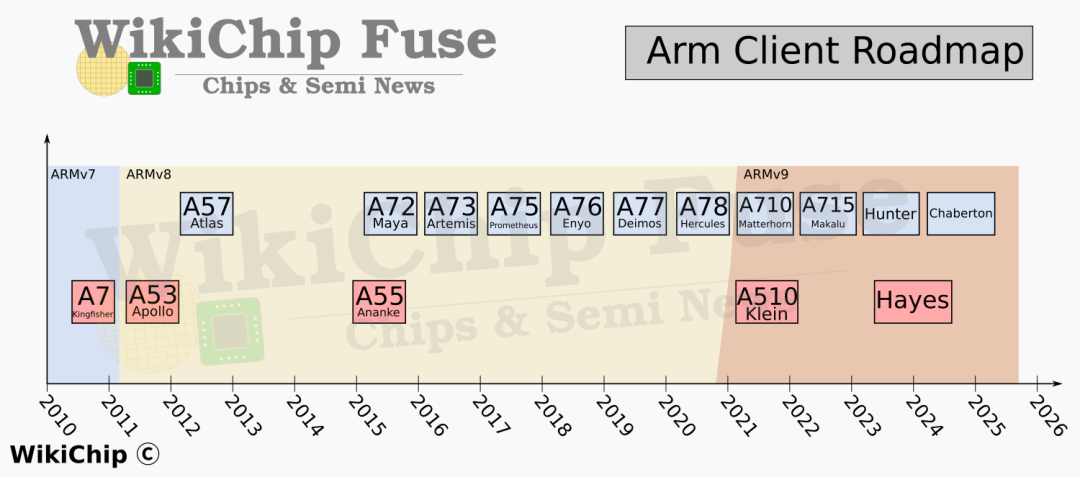
ARM處理器路線圖
6、A710和A715微架構介紹
6.1 A78回顧
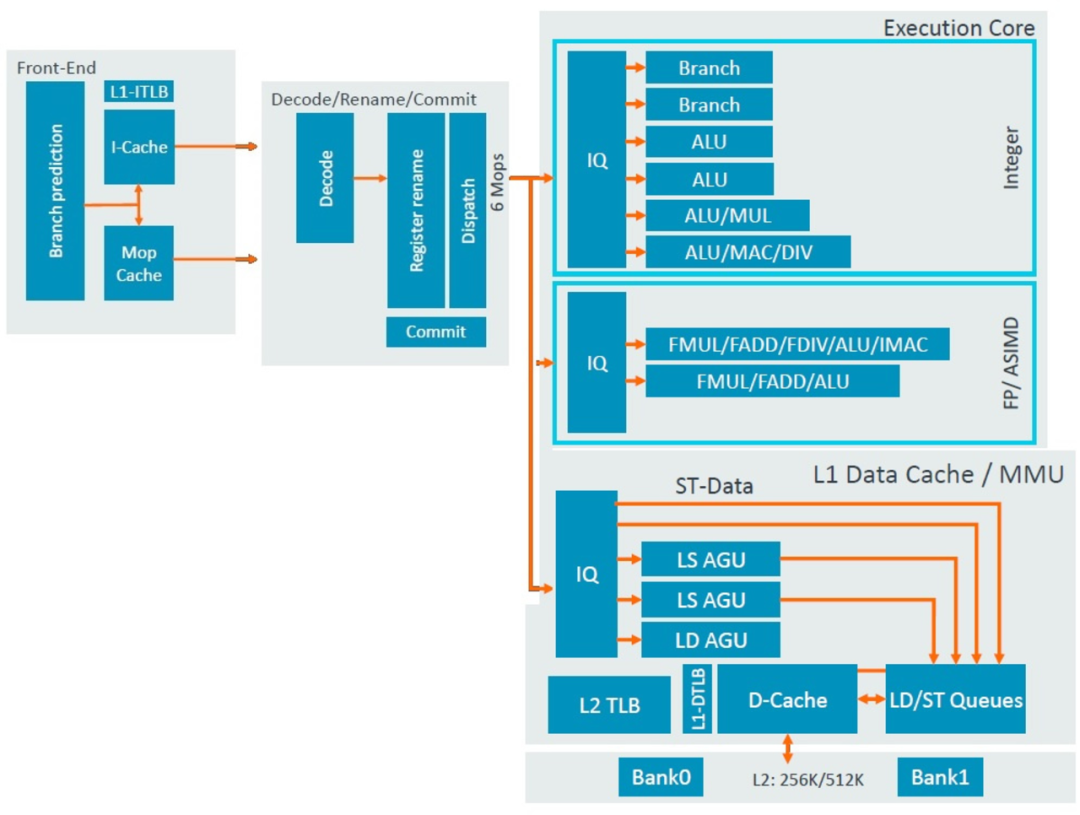
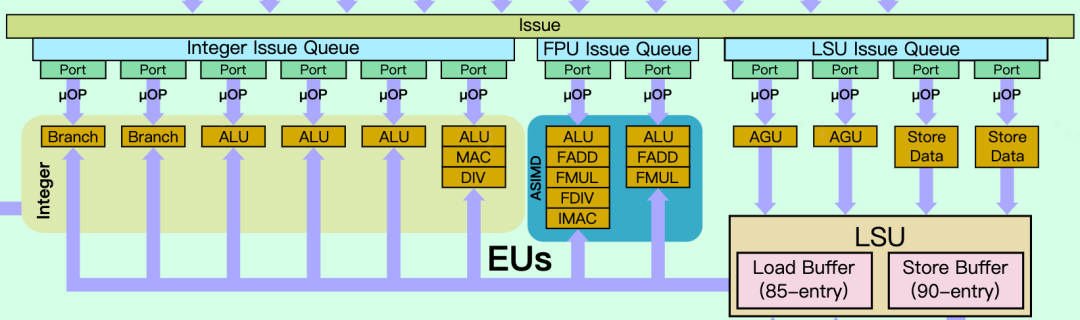
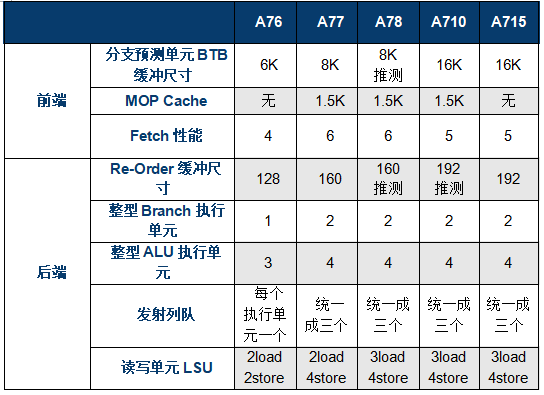
文章都寫了一半了,終于到聊到正題了?還沒有!因為A710是基于A78微架構優化而來,我們先要先回顧一下A78。這里和大家快速回顧下A78的微架構,4路decode,加上Mop Cache可以一次最多提供6路Mops指令進入執行單元,整數執行單元提供2個Branch,4個ALU,浮點單元提供2個FPU,存儲單元提供2個LS AGU,1個LD AGU和2個ST-Data通路。
6.2 A710和A715簡介

A710是Armv9家族的第一顆大核心,A710也是第一次正式引入了SVE2擴展指令集,A710沒有放棄32bit的支持,可以同時兼容32bit和64bit應用。
A715是Armv9家族的第二顆大核心,值得注意的是核心序號只加了5,難道Arm覺得還達不到A720的預期?我們后續揭曉。A715相比A710最大的變化是輕裝上陣,拋棄了32bit的支持,讓設計師可以更加聚焦設計一款純64bit的核心。
6.3 A710能效

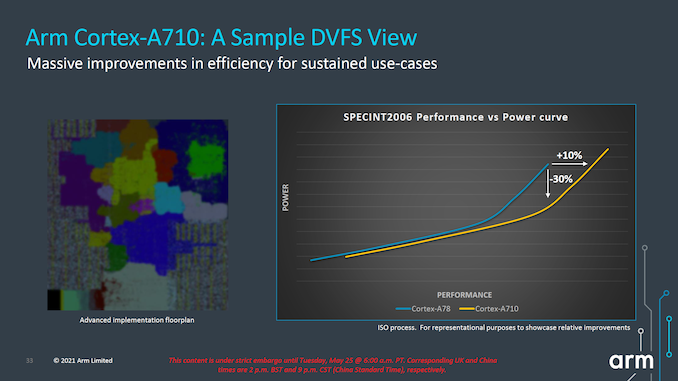
Arm在A710這一代產品希望重點優化能效。根據Arm提供的性能功耗曲線數據,A710依然是一顆高能效比的核心,相比A78在同樣的能耗下性能可以提升約10%,同樣的性能條件下功耗可以降低約30%,需要注意2點,第一是這個數據是在高頻率區間取得的,低頻率區間的能效曲線和A78較為接近;第二是性能的提升是在L3緩存增加情況下得出的,緩存增大理論也貢獻了一部分性能得分。
可惜A710的出生似乎有些生不逢時,大家寄予厚望的采用了A710的第一代產品高通驍龍8Gen1處理器,由于采用了三星工藝代工,整體能效表現一般,直到高通公司第二年將工藝切換TSMC并量產了驍龍8+Gen1芯片,整體芯片能效有了明顯提升,才發揮出了A710應有的實力。
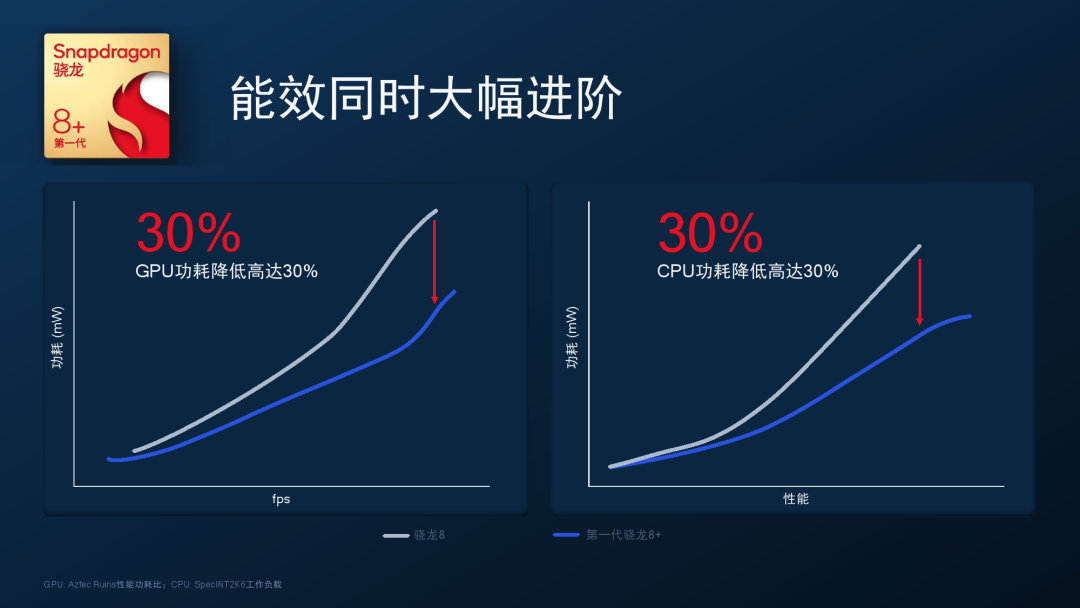
驍龍8+Gen1和8Gen1能效對比數據
6.4 A710架構設計

A710在前端設計部分上和A78差異不大,同樣提供了1.5K的MOP cache,提供了可動態配置3264KB的L1緩存和可動態配置256512KB的L2緩存。Arm在A710上的優化點是提升了分支預測的能力,將關鍵的分支預測結構體容量空間翻了一番,此外L1的TLB容量也翻了一倍。

A710微架構的一個關鍵的修改在指令分發Dispatch模塊,該模塊發生了一些有趣的變化,大家還記得A77新引入MOP cache時就是4路decode和6路dispatch,A78同樣繼承如此,到了A710上Arm將其減少到了5路dispatch。減少一條通路意味著可以節省芯片電路和面積,另一方向性能上也難免會有一定的損失。為了彌補這個損失,Arm宣稱做了一系列基于MOP cache的優化,并將分支預測到分支執行的流水線縮減到10個時鐘周期,從而達成宣稱的能效優化指標。

目前網絡上A710的資料并不多,特別缺乏后端設計部分的詳細資料,根據推測后端設計和A78比差異不大,推測ROB應該會增加,推測訪存LSU的單元和A78沒有明顯變化,后續我們可以在A715上再次論證。
Arm還提到A710通過優化數據預取(prefetcher)來提升性能和能效,減少CPU的數據預取次數,可以減少對于DSU的訪問參數,同業也可以降低對于DRAM的訪問次數,從圖中數據看,相比A78,A710在DSU和DRAM的訪問上都有明顯改善。
簡單總結下,A710相比A78的設計僅相隔了一年,并不是一個準備多年的全新架構升級,在A78的基礎上,A710保留了32bit的支持,優化了流水線和數據預取能力,前端分支預測和指令通路是最明顯的變化。這次Armv9架構升級涉及到X2、A710和A510三款核心,相比之下X2和A510的變化更多,我們后續會詳細分析。
6.5 A715能效

目前最新的Arm大核心是A715,從官方數據中我們可以看出A715這一代的目標并不是以提升性能為主,同樣功耗下性能只提升了5%,或許這也是被叫做A715的一個原因。在能效方面,相同性能下可以降低20%的功耗。
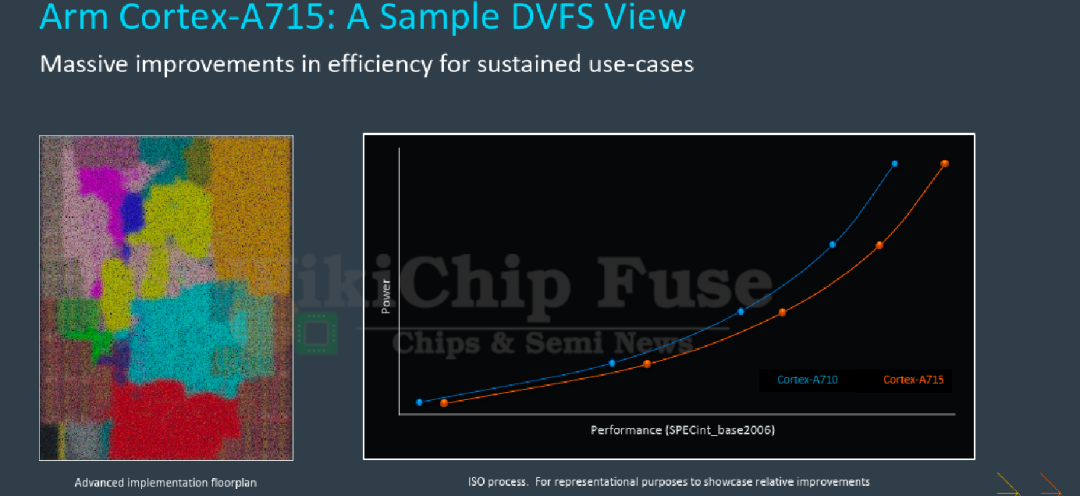
再來看一下DVFS曲線,A715的曲線和A710比較接近,同樣功耗下性能有小幅度提升。后續這幾代Arm大核心微架構上都不會有像A75、A76那樣大幅變化,基本是保持A715對A710這樣的穩定功耗優化,性能小幅度提升。
從數據上看,A715整體的能效優化幅度不高,可以認為A715是A710的一個小改款。結合微架構分析整體看,Arm需要一顆更經濟的核心來支撐整個產品線以及平衡性能和功耗。
6.6 A715架構設計
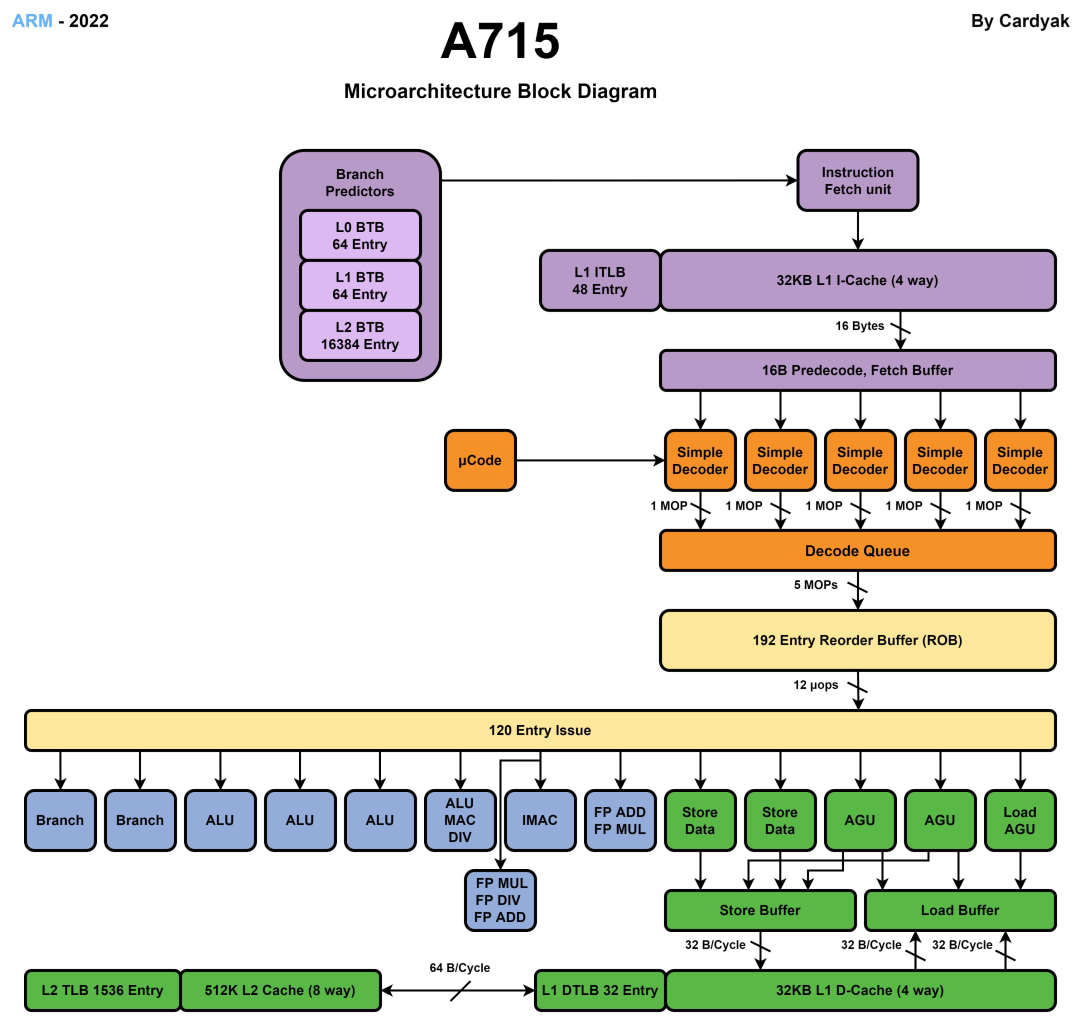
很幸運,網絡有高手(Cardyak)放出了A715的微架構圖,我們可以借此一窺A77到A715的變化。

A715的前端分支預測能力有了進一步提升,Arm在Armv9上很重視分支預測能力,每一代都有一些優化。A710相比A78提升了分支預測能力,這次A715進一步優化,以提升IPC和能效。細節上,A715將Direction Predictor的容量提升了一倍,從而進一步提升分支預測的準確性。A715每個周期支持預測2個分支,比A710多支持了條件分支的預測能力。此外,在分支預測方案上,Arm傳統支持0級和2級預測模型,這次A715將2級預測模型拆分成3級,增加了一個faster turnaroud功能,在發現預測錯誤時可以快速返回,提升分支預測效率。最后是訪問指令緩存(Icache)方面,A715將指令緩存的查找帶寬也提升了一倍,從而支持更好的訪問指令緩存的效率。
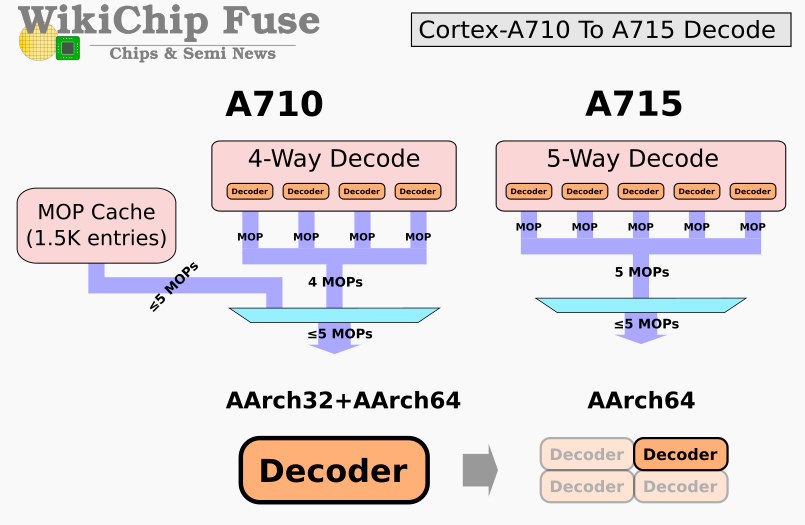

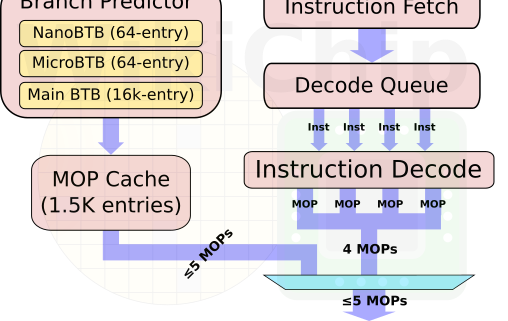
解碼模塊依然是Armv9重點優化的部分,也是A715變化最大的模塊。在A715上有一個關鍵的修改,Arm出于成本考慮,將自A77開始加入的MOP cache模塊移除了。MOP cache可以緩存一些常用的核心指令,降低從L1取指令的負擔,但是Arm宣稱可以通過其他優化方法,進一步提升性能和能效。第一點,A715是一顆純64bit的大核心,憑借這一點,可以節省原來為了兼容32bit而增加的晶體管電路;第二是A715上增加了一路decode通路,從4通路提升到5通路,在A710之后Dispatch也改成了5通路,A715這一代Fetch和Dispatch到后端模塊的通道正好對齊都是5通路,可以發揮最高的效率;第三是采用了小尺寸的decoder,將原來A710的統一大尺寸decoder拆分成4個小尺寸的decoder,便于分配資源和節省能耗;最后是A715提升了復雜指令(NEONSVESVE2)的吞吐率,讓它們可以快速發送到對應的執行單元。
在ROB重排序緩沖方面,A715提供了192個entry,相比A77的160個entry提升了20%,和A77至A715的性能提升可以匹配上。執行單元的Issue entry還是120個,這個大小自A76開始就沒有變化。在執行單元上,A715相比A710和A78都沒有明顯變化,還是2個Branch,4個ALU,浮點單元提供2個FPU,存儲單元提供2個LS AGU,1個LD AGU和2個ST-Data通路,看來Arm認為這塊的設計非常合理不需要改變。

在存儲單元上,A715增大了Load Replay隊列尺寸,可以提供更多的數據預取和L2訪問機會。此外A715提供了2倍的Data Cache Banks,可以支持更多同步讀寫數據,降低并發沖突從而降低能耗。A715的L2的TLB entry增大了50%,達到了1.5K個entry,提升了數據預取的準確性,也可以降低內存的訪問,進而提升綜合性能。
6.7 小結
階段總結下,A715相比A710的微架構修改較大,A715取消了32bit的支持,取消了MOP cache,優化了分支預測、指令單元和存儲單元,統一了指令通路數量,還提出了小decoder的模型。目前A715已經在高通驍龍8Gen2,MTK天璣9200等產品成功應用,搭配最新的4nm工藝,性能和能效表現可圈可點。
7、A510微架構介紹
7.1 A510簡介
我們并沒有花很多篇幅去介紹A55這顆處理器,因為A55實在是“久經沙場”,伴隨著A75登場,歷經A75-A78四代產品。到Armv9時代,Arm認為必須更新一下A5x系列的小核心產品線了,于是我們看到了最新的A510系列小核心處理器。
21年Arm更新了A510產品線,22年Arm又做了小幅度優化,更新了A510r產品線。由于Arm維持了每年迭代的產品快速更新策略,進入Armv9后一年需要更新X2、A710和A510三款產品,難免造成資源分散。例如對于32bit的支持問題上,A710支持32bit,X2和A510不支持,但是在22年更新的A510r第二代產品,又加入了32bit的支持。
7.2 A510能效

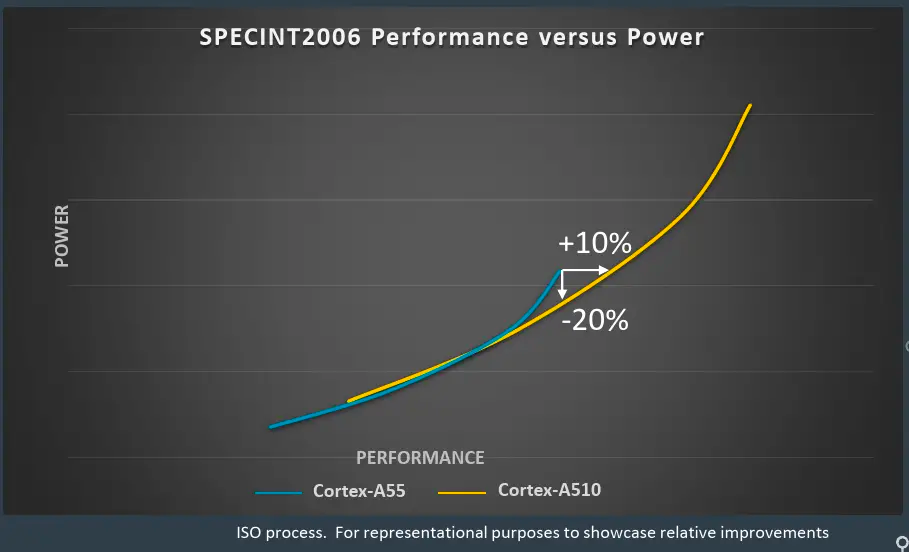
官方數據顯示A510可以提升35%的性能,能效優化20%,ML性能是以前A55的3倍。從能效曲線看,性能提升35%都是保守的,后續的架構分析也可以支撐這一說法,但是能效的20%優化要加限定詞,限定在A55高頻率段區間比較合理,因為整體的功耗和性能提升成正比,簡單說就是A510的極限性能和極限功耗都增加了。
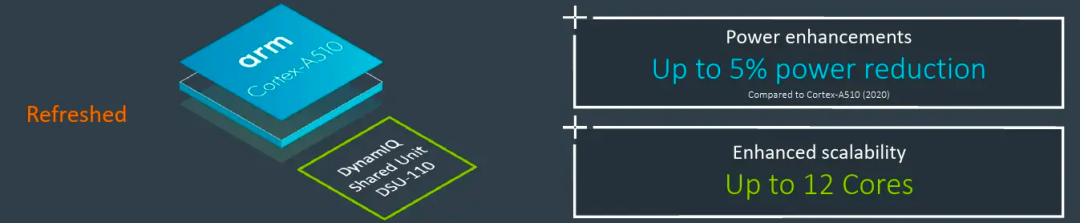
對于A510的能效,Arm也提出后續會不斷優化,例如A510r重新設計了一些電路,宣稱可以提升5%的能效。下一代的Hayes也會繼續優化能效。為什么A510的性能提升,能效沒有進一步提升呢?在后面的架構設計部分大家應該可以得出一些推論。
7.3 A510架構設計
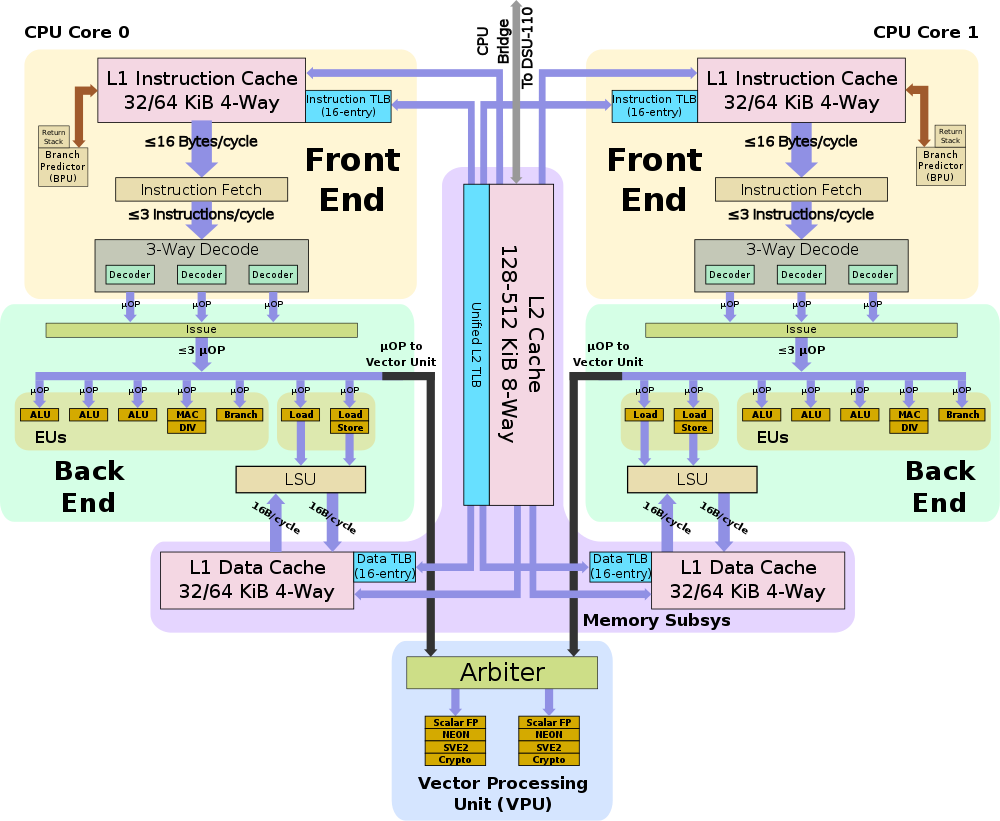
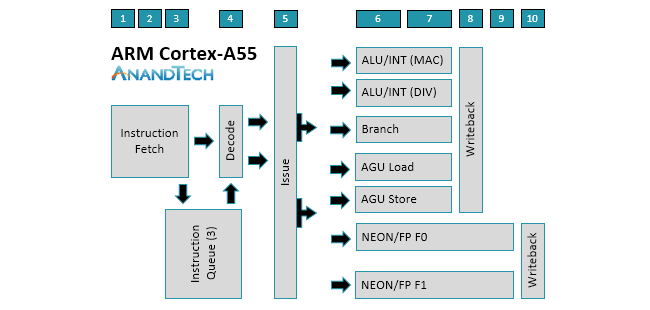
上面是A510的微架構圖和A55的架構簡圖,從圖中可以看到A510相比A710的大核心設計,確實有很多簡化的地方,但是相比A55還是有明顯增強的。
A510和A55一樣,是一顆不支持亂序執行(OoO-Out of oder)的核心,不支持OoO意味著沒有重排序緩沖(ROB)模塊,可以節省芯片面積,缺點則是無法充分填充和利用流水線,指令執行的效率較低。
此外,第一代的A510不支持32bit應用,第二年Arm在A510r上,又把32bit應用的支持加回來了。
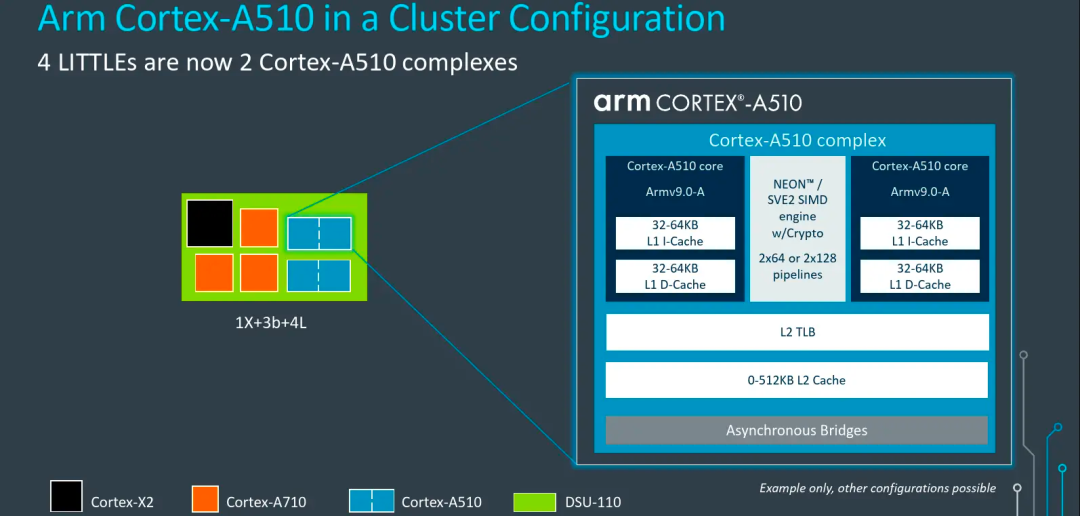
A510為了進一步優化芯片面積,采用了拼接核心設計,如圖中所示,兩顆A510被封裝在一起,共享L2緩存、L2 TLB等模塊。這種硬件設計對于軟件調度器的設計提供了優化思路,因為共享L2,在2顆共享核心之間調度的效率會高于跨L2,所以軟件在選擇任務遷移時,如果還是移動到小核心執行,應當優先去選擇共享L2的那個CPU去執行,效率會最高。
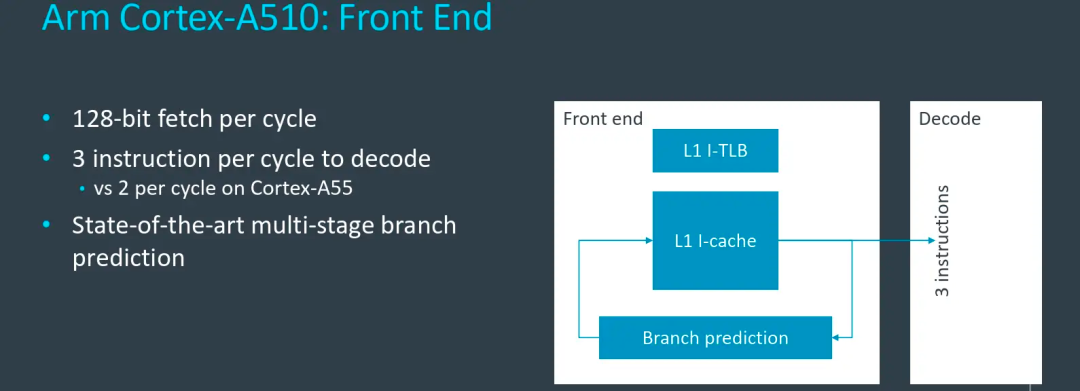
在前端設計上,A510相比A55最大的改變是將2寬度流水線拓展到了3寬度,如指令Fetch能力從2提升到3,等于增加了一條通路,這也是A510同頻率性能可以提升的關鍵影響因素。此外,A55每個周期可以fetch 64-bit,A510每時鐘周期則可以fetch128-bit指令。同時,A510還借鑒了Armv9系列架構的分支預測方案設計,相比A55可以提供更為準確的分支預測能力,減少流水線的損失。
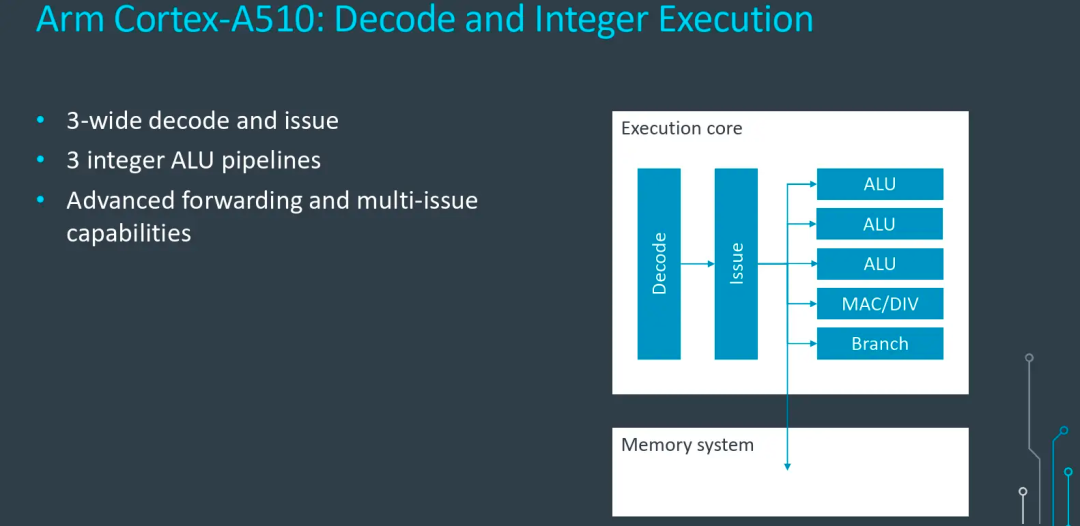
A510相比A55的通路增加是完整的,在指令Fetch模塊后,指令Decode和Issue模塊的通路也從2增加到3,提升了50%。
運算單元部分,小核心僅有1個Branch單元沒有變化,ALU數量(含MAC、DIV)從2提升到4,也提升了50%。FPU(又叫做VPU)被挪到了2個核心共享,雖然無法直接對比,根據Arm提供的數據看FP也有50%的性能提升。
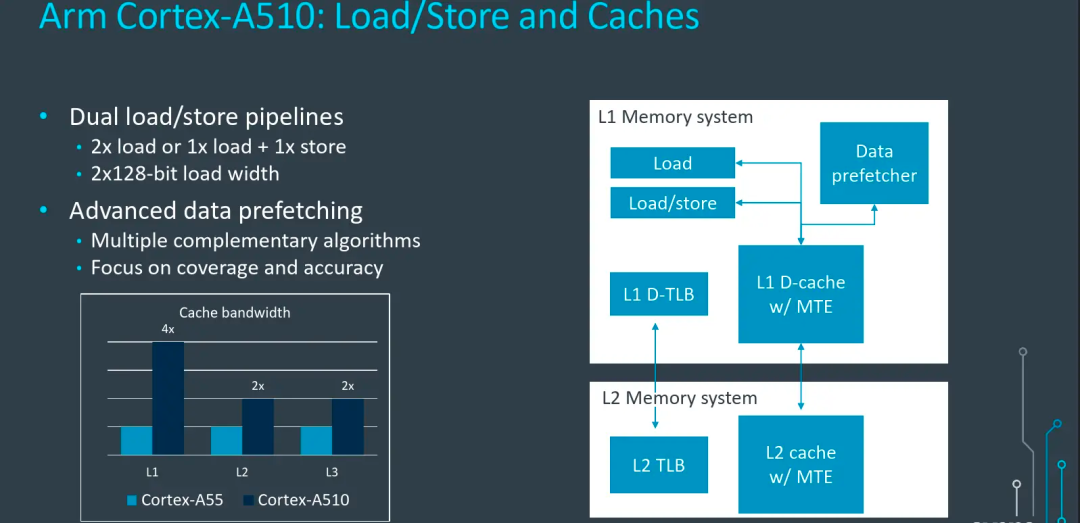
存儲模塊上,A510相比A55也有明顯提升,A55提供了1個Load和1個Store通路,A510雖然還是2通路,但是一個支持Load,另一個同時支持Load和Store,Load能力有提升。同時,Load帶寬從A55的64bit提升到128bit,如圖中顯示L1帶寬可以提升4倍,L2和L3分別也提升了2倍。此外,Data Prefetcher模塊也引入了Armv9的系列優化,可以提升數據預取準確性。
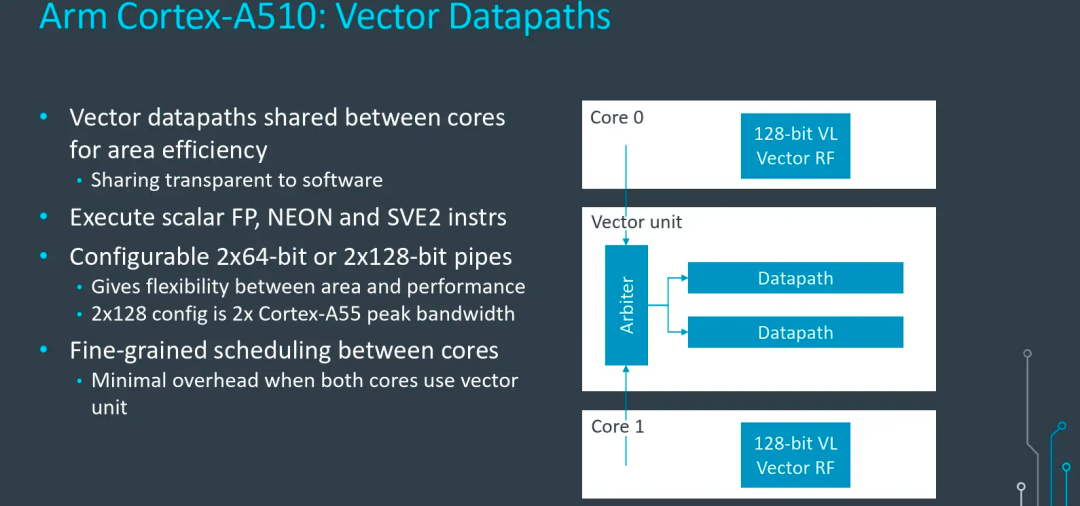
最后,A510的兩個核心還共享了矢量運算單元(VPU),用于處理Scalar FP、NEON、SVE2等指令,Arm期望通過這種設計進一步優化小核心的面積,優化能效。
7.4 小結
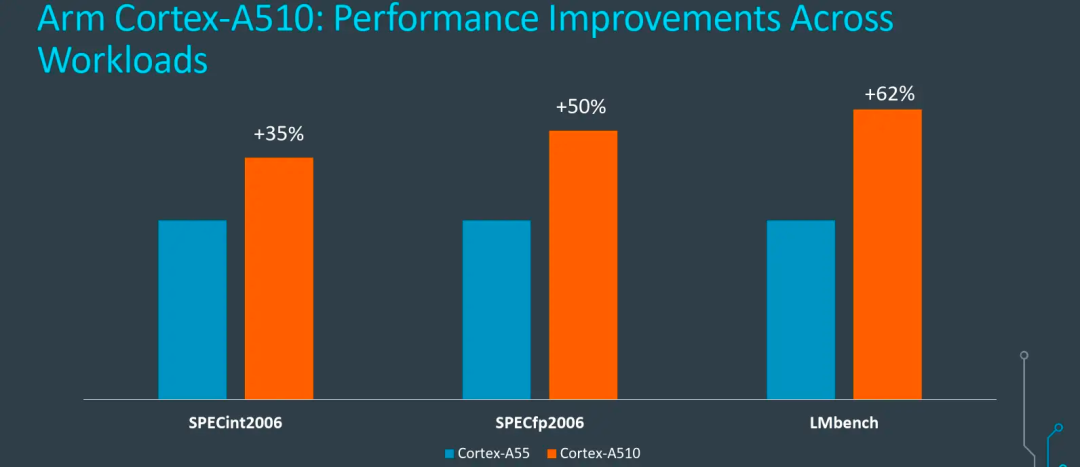
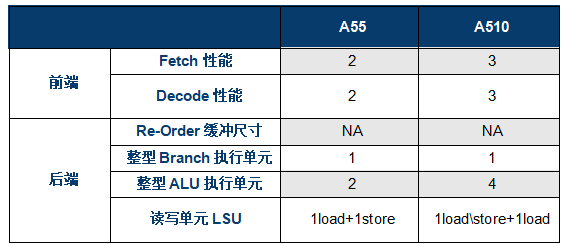
相隔4年,Arm終于更新了A5x系列小核心,看完后還是感覺有點不夠過癮,意猶未盡的感覺。雖然A510相比A55,不論在整數、浮點還是存儲性能上都有明顯的提升(見上圖),但是整體處理器的能效并沒有明顯的改善,究其根因,這次A510的升級,并沒有引入OoO亂序執行等大核心的先進特性,而是基于A55的架構上通過增加通路和運算模塊達成的性能提升,總體能效改善不夠明顯。
A510的這次升級,也導致終端廠商在實際產品開發中,針對A510的小核心的處理需要更加謹慎,例如盡可能利用和A55性能接近的區間,獲取最大能效收益,在軟件調度時需要考慮2個共享核心內優先調度以獲取最低的開銷等等。
相信Arm公司對于A5x會持續迭代優化,在后續的A510r和Hayes等產品中,Arm也是提出了不斷優化能效的目標。
8、總結
通過本篇文章我們了解了Armv9的大核心A710、A715和小核心A510的微架構設計,以及進入Armv9時代后Arm推進的超級大核心Cortex-X定制計劃、SVE2指令集,并討論了Arm對于32bit和64bit兼容的態度,希望Arm可以持續迭代Armv9系列架構,推動移動處理器持續高速發展,不斷提升用戶的移動終端體驗。由于篇幅限制,本文沒有深入討論超級大核心Cortex-X系列處理器,計劃在后續的文章中補完這部分。
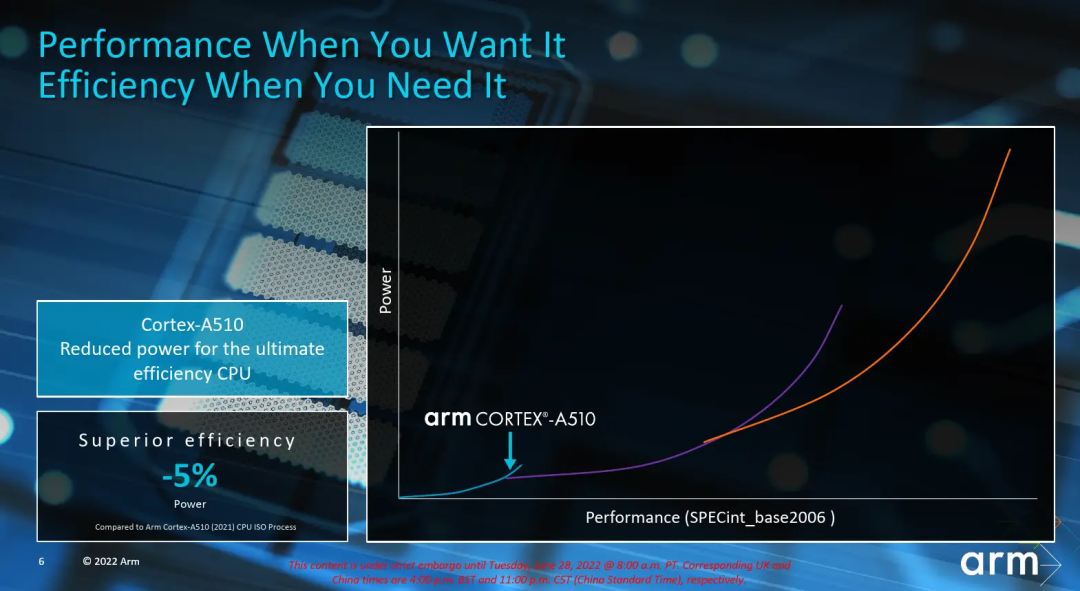
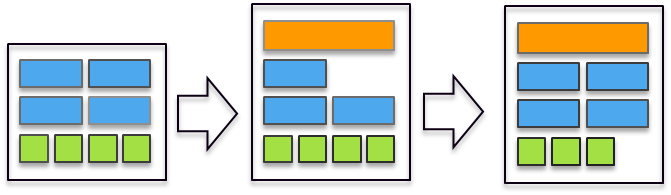
最后補個彩蛋,看Armv9三系列能效曲線圖,小核心迭代速度較慢,逐漸無法滿足日益增長的性能需求,由于小核心不支持亂序執行等特性,導致高頻率區間能效反而不如大核心A715和A710(見圖中箭頭位置),在Armv9時代我們可以看到已經有廠商開始改變傳統的1+3+4的架構。例如高通驍龍8Gen2芯片,將1+3+4的架構改成1+4+3的架構,減少一顆小核心,增加一顆大核心。這是一個很關鍵的變化,新架構的出現意味著更多的可能性,并且從實際測試數據看,性能有收益,跑分達130w+,能效方面8Gen2相比8+Gen1也有了進一步的改善。從8Gen2的處理器架構變化可以看出,芯片廠商也在走出多年不變的1+3+4八核心架構模式,希望以后有機會看到更多有意思的芯片架構設計組合。
審核編輯 :李倩
-
ARM
+關注
關注
134文章
9094瀏覽量
367541 -
cpu
+關注
關注
68文章
10863瀏覽量
211748 -
微架構
+關注
關注
0文章
22瀏覽量
7043
原文標題:Arm微架構之Armv9時代
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Armv9核心A710、A715和A510微架構解讀
十年來最大技術革新!Arm發布Armv9架構!不受美國EAR約束,華為可獲授權!
安謀科技:十年磨一劍的Armv9架構,下半年將有終端面市
重磅!Arm正式推出Armv9架構

重磅!Arm推出新一代指令集架構Armv9,整體性能躍升一級
Arm推出Arm?v9架構 面向人工智能、安全和專用計算的未來
Arm確定其Armv9架構不受美國出口管理條例(EAR)的約束
淺談ARM發布Armv9的三大改進
Arm公司正式發布了該公司的新一代Armv9架構的首個細節





 工商網監
工商網監
評論