") 嵌入式C語言代碼優(yōu)化經(jīng)驗與方法
嵌入式C語言代碼優(yōu)化經(jīng)驗與方法
在本篇文章中,收集了很多經(jīng)驗和方法。應用這些經(jīng)驗和方法,可以幫助我們從執(zhí)行速度和內(nèi)存使用等方面來優(yōu)化C語言代碼。
簡介
在最近的一個項目中,我們需要開發(fā)一個運行在移動設備上但不保證圖像高質(zhì)量的輕量級JPEG庫。期間,我總結(jié)了一些讓程序運行更快的方法。在本篇文章中,我收集了一些經(jīng)驗和方法。
應用這些經(jīng)驗和方法,可以幫助我們從執(zhí)行速度和內(nèi)存使用等方面來優(yōu)化C語言代碼。
盡管在C代碼優(yōu)化方面有很多的指南,但是關于編譯和你使用的編程機器方面的優(yōu)化知識卻很少。
通常,為了讓你的程序運行的更快,程序的代碼量可能需要增加。代碼量的增加又可能會對程序的復雜度和可讀性帶來不利的影響。這對于在手機、PDA等對于內(nèi)存使用有很多限制的小型設備上編寫程序時是不被允許的。
因此,在代碼優(yōu)化時,我們的座右銘應該是確保內(nèi)存使用和執(zhí)行速度兩方面都得到優(yōu)化。
聲明
實際上,在我的項目中,我使用了很多優(yōu)化ARM編程的方法(該項目是基于ARM平臺的),也使用了很多互聯(lián)網(wǎng)上面的方法。但并不是所有文章提到的方法都能起到很好的作用。所以,我對有用的和高效的方法進行了總結(jié)收集。同時,我還修改了其中的一些方法,使他們適用于所有的編程環(huán)境,而不是局限于ARM環(huán)境。
哪里需要使用這些方法?
沒有這一點,所有的討論都無從談起。程序優(yōu)化最重要的就是找出待優(yōu)化的地方,也就是找出程序的哪些部分或者哪些模塊運行緩慢亦或消耗大量的內(nèi)存。只有程序的各部分經(jīng)過了優(yōu)化,程序才能執(zhí)行的更快。
程序中運行最多的部分,特別是那些被程序內(nèi)部循環(huán)重復調(diào)用的方法最該被優(yōu)化。
對于一個有經(jīng)驗的碼農(nóng),發(fā)現(xiàn)程序中最需要被優(yōu)化的部分往往很簡單。此外,還有很多工具可以幫助我們找出需要優(yōu)化的部分。我使用過Visual C++內(nèi)置的性能工具profiler來找出程序中消耗最多內(nèi)存的地方。
另一個我使用過的工具是英特爾的Vtune,它也能很好的檢測出程序中運行最慢的部分。根據(jù)我的經(jīng)驗,內(nèi)部或嵌套循環(huán),調(diào)用第三方庫的方法通常是導致程序運行緩慢的最主要的起因。
整形數(shù)
如果我們確定整數(shù)非負,就應該使用unsigned int而不是int。有些處理器處理無符號unsigned 整形數(shù)的效率遠遠高于有符號signed整形數(shù)(這是一種很好的做法,也有利于代碼具體類型的自解釋)。
因此,在一個緊密循環(huán)中,聲明一個int整形變量的最好方法是:
registerunsignedintvariable_name;
記住,整形in的運算速度高浮點型float,并且可以被處理器直接完成運算,而不需要借助于FPU(浮點運算單元)或者浮點型運算庫。
盡管這不保證編譯器一定會使用到寄存器存儲變量,也不能保證處理器處理能更高效處理unsigned整型,但這對于所有的編譯器是通用的。
例如在一個計算包中,如果需要結(jié)果精確到小數(shù)點后兩位,我們可以將其乘以100,然后盡可能晚的把它轉(zhuǎn)換為浮點型數(shù)字。
除法和取余數(shù)
在標準處理器中,對于分子和分母,一個32位的除法需要使用20至140次循環(huán)操作。除法函數(shù)消耗的時間包括一個常量時間加上每一位除法消耗的時間。
Time(numerator/denominator)=C0+C1*log2(numerator/denominator) =C0+C1*(log2(numerator)-log2(denominator)).
對于ARM處理器,這個版本需要20+4.3N次循環(huán)。這是一個消耗很大的操作,應該盡可能的避免執(zhí)行。有時,可以通過乘法表達式來替代除法。
例如,假如我們知道b是正數(shù)并且b*c是個整數(shù),那么(a/b)>c可以改寫為a>(c * b)。如果確定操作數(shù)是無符號unsigned的,使用無符號unsigned除法更好一些,因為它比有符號signed除法效率高。
合并除法和取余數(shù)
在一些場景中,同時需要除法(x/y)和取余數(shù)(x%y)操作。這種情況下,編譯器可以通過調(diào)用一次除法操作返回除法的結(jié)果和余數(shù)。如果既需要除法的結(jié)果又需要余數(shù),我們可以將它們寫在一起,如下所示:
intfunc_div_and_mod(inta,intb)
{
return(a/b)+(a%b);
}
通過2的冪次進行除法和取余數(shù)
如果除法中的除數(shù)是2的冪次,我們可以更好的優(yōu)化除法。編譯器使用移位操作來執(zhí)行除法。因此,我們需要盡可能的設置除數(shù)為2的冪次(例如64而不是66)。并且依然記住,無符號unsigned整數(shù)除法執(zhí)行效率高于有符號signed整形出發(fā)。
typedefunsignedintuint;
uintdiv32u(uinta)
{
returna/32;
}
intdiv32s(inta)
{
returna/32;
}
上面兩種除法都避免直接調(diào)用除法函數(shù),并且無符號unsigned的除法使用更少的計算機指令。由于需要移位到0和負數(shù),有符號signed的除法需要更多的時間執(zhí)行。
取模的一種替代方法
我們使用取余數(shù)操作符來提供算數(shù)取模。但有時可以結(jié)合使用if語句進行取模操作。考慮如下兩個例子:
uintmodulo_func1(uintcount)
{
return(++count%60);
}
uintmodulo_func2(uintcount)
{
if(++count>=60)
count=0;
return(count);
}
優(yōu)先使用if語句,而不是取余數(shù)運算符,因為if語句的執(zhí)行速度更快。這里注意新版本函數(shù)只有在我們知道輸入的count結(jié)余0至59時在能正確的工作。
使用數(shù)組下標
如果你想給一個變量設置一個代表某種意思的字符值,你可能會這樣做:
switch(queue)
{
case0:letter='W';
break;
case1:letter='S';
break;
case2:letter='U';
break;
}
或者這樣做:
if(queue==0) letter='W'; elseif(queue==1) letter='S'; elseletter='U';
一種更簡潔、更快的方法是使用數(shù)組下標獲取字符數(shù)組的值。如下:
staticchar*classes="WSU"; letter=classes[queue];
全局變量
全局變量絕不會位于寄存器中。使用指針或者函數(shù)調(diào)用,可以直接修改全局變量的值。因此,編譯器不能將全局變量的值緩存在寄存器中,但這在使用全局變量時便需要額外的(常常是不必要的)讀取和存儲。所以,在重要的循環(huán)中我們不建議使用全局變量。
如果函數(shù)過多的使用全局變量,比較好的做法是拷貝全局變量的值到局部變量,這樣它才可以存放在寄存器。這種方法僅僅適用于全局變量不會被我們調(diào)用的任意函數(shù)使用。例子如下:
intf(void); intg(void); interrs; voidtest1(void) { errs+=f(); errs+=g(); } voidtest2(void) { intlocalerrs=errs; localerrs+=f(); localerrs+=g(); errs=localerrs; }
注意,test1必須在每次增加操作時加載并存儲全局變量errs的值,而test2存儲localerrs于寄存器并且只需要一個計算機指令。
使用別名
考慮如下的例子:
voidfunc1(int*data)
{
inti;
for(i=0;i<10;?i++)????
????{??????????
????????anyfunc(?*data,?i);????
????}
}
盡管*data的值可能從未被改變,但編譯器并不知道anyfunc函數(shù)不會修改它,所以程序必須在每次使用它的時候從內(nèi)存中讀取它。如果我們知道變量的值不會被改變,那么就應該使用如下的編碼:
voidfunc1(int*data)
{
inti;
intlocaldata;
localdata=*data;
for(i=0;i<10;?i++)????
????{??????????
????????anyfunc?(localdata,?i);????
????}
}
這為編譯器優(yōu)化代碼提供了條件。
變量的生命周期分割
由于處理器中寄存器是固定長度的,程序中數(shù)字型變量在寄存器中的存儲是有一定限制的。
有些編譯器支持“生命周期分割”(live-range splitting),也就是說在程序的不同部分,變量可以被分配到不同的寄存器或者內(nèi)存中。
變量的生命周期開始于對它進行的最后一次賦值,結(jié)束于下次賦值前的最后一次使用。在生命周期內(nèi),變量的值是有效的,也就是說變量是活著的。不同生命周期之間,變量的值是不被需要的,也就是說變量是死掉的。
這樣,寄存器就可以被其余變量使用,從而允許編譯器分配更多的變量使用寄存器。
需要使用寄存器分配的變量數(shù)目需要超過函數(shù)中不同變量生命周期的個數(shù)。如果不同變量生命周期的個數(shù)超過了寄存器的數(shù)目,那么一些變量必須臨時存儲于內(nèi)存。這個過程就稱之為分割。
編譯器首先分割最近使用的變量,用以降低分割帶來的消耗。禁止變量生命周期分割的方法如下:
限定變量的使用數(shù)量:這個可以通過保持函數(shù)中的表達式簡單、小巧、不使用太多的變量實現(xiàn)。將較大的函數(shù)拆分為小而簡單的函數(shù)也會達到很好的效果。
對經(jīng)常使用到的變量采用寄存器存儲:這樣允許我們告訴編譯器該變量是需要經(jīng)常使用的,所以需要優(yōu)先存儲于寄存器中。然而,在某種情況下,這樣的變量依然可能會被分割出寄存器。
變量類型
C編譯器支持基本類型:char、short、int、long(包括有符號signed和無符號unsigned)、float和double。使用正確的變量類型至關重要,因為這可以減少代碼和數(shù)據(jù)的大小并大幅增加程序的性能。
局部變量
我們應該盡可能的不使用char和short類型的局部變量。對于char和short類型,編譯器需要在每次賦值的時候?qū)⒕植孔兞繙p少到8或者16位。這對于有符號變量稱之為有符號擴展,對于無符號變量稱之為零擴展。
這些擴展可以通過寄存器左移24或者16位,然后根據(jù)有無符號標志右移相同的位數(shù)實現(xiàn),這會消耗兩次計算機指令操作(無符號char類型的零擴展僅需要消耗一次計算機指令)。
可以通過使用int和unsigned int類型的局部變量來避免這樣的移位操作。這對于先加載數(shù)據(jù)到局部變量,然后處理局部變量數(shù)據(jù)值這樣的操作非常重要。無論輸入輸出數(shù)據(jù)是8位或者16位,將它們考慮為32位是值得的。
考慮下面的三個函數(shù):
intwordinc(inta)
{
returna+1;
}
shortshortinc(shorta)
{
returna+1;
}
charcharinc(chara)
{
returna+1;
}
盡管結(jié)果均相同,但是第一個程序片段運行速度高于后兩者。
指針
我們應該盡可能的使用引用值的方式傳遞結(jié)構數(shù)據(jù),也就是說使用指針,否則傳遞的數(shù)據(jù)會被拷貝到棧中,從而降低程序的性能。我曾見過一個程序采用傳值的方式傳遞非常大的結(jié)構數(shù)據(jù),然后這可以通過一個簡單的指針更好的完成。
函數(shù)通過參數(shù)接受結(jié)構數(shù)據(jù)的指針,如果我們確定不改變數(shù)據(jù)的值,我們需要將指針指向的內(nèi)容定義為常量。例如:
voidprint_data_of_a_structure(constThestruct*data_pointer)
{
...printfcontentsofthestructure...
}
這個示例告訴編譯器函數(shù)不會改變外部參數(shù)的值(使用const修飾),并且不用在每次訪問時都進行讀取。同時,確保編譯器限制任何對只讀結(jié)構的修改操作從而給予結(jié)構數(shù)據(jù)額外的保護。
指針鏈
指針鏈經(jīng)常被用于訪問結(jié)構數(shù)據(jù)。例如,常用的代碼如下:
typedefstruct{intx,y,z;}Point3;
typedefstruct{Point3*pos,*direction;}Object;
voidInitPos1(Object*p)
{
p->pos->x=0;
p->pos->y=0;
p->pos->z=0;
}
然而,這種的代碼在每次操作時必須重復調(diào)用p->pos,因為編譯器不知道p->pos->x與p->pos是相同的。一種更好的方法是緩存p->pos到一個局部變量:
voidInitPos2(Object*p)
{
Point3*pos=p->pos;
pos->x=0;
pos->y=0;
pos->z=0;
}
另一種方法是在Object結(jié)構中直接包含Point3類型的數(shù)據(jù),這能完全消除對Point3使用指針操作。
條件執(zhí)行
條件執(zhí)行語句大多在if語句中使用,也在使用關系運算符(<,==,>等)或者布爾值表達式(&&,!等)計算復雜表達式時使用。對于包含函數(shù)調(diào)用的代碼片段,由于函數(shù)返回值會被銷毀,因此條件執(zhí)行是無效的。
因此,保持if和else語句盡可能簡單是十分有益處的,因為這樣編譯器可以集中處理它們。關系表達式應該寫在一起。
下面的例子展示編譯器如何使用條件執(zhí)行:
intg(inta,intb,intc,intd)
{
if(a>0&&b>0&&c
由于條件被聚集到一起,編譯器能夠?qū)⑺麄兗刑幚怼?/p>
布爾表達式和范圍檢查
一個常用的布爾表達式是用于判斷變量是否位于某個范圍內(nèi),例如,檢查一個圖形坐標是否位于一個窗口內(nèi):
boolPointInRectangelArea(Pointp,Rectangle*r)
{
return(p.x>=r->xmin&&p.xxmax&&
p.y>=r->ymin&&p.yymax);
}
這里有一種更快的方法:x>min && x
boolPointInRectangelArea(Pointp,Rectangle*r)
{
return((unsigned)(p.x-r->xmin)xmax&&
(unsigned)(p.y-r->ymin)ymax);
}
布爾表達式和零值比較
處理器的標志位在比較指令操作后被設置。標志位同樣可以被諸如MOV、ADD、AND、MUL等基本算術和裸機指令改寫。如果數(shù)據(jù)指令設置了標志位,N和Z標志位也將與結(jié)果與0比較一樣進行設置。N標志表示結(jié)果是否是負值,Z標志表示結(jié)果是否是0。
C語言中,處理器中的N和Z標志位與下面的指令聯(lián)系在一起:有符號關系運算x<0,x>=0,x==0,x!=0;無符號關系運算x==0,x!=0(或者x>0)。
C代碼中每次關系運算符的調(diào)用,編譯器都會發(fā)出一個比較指令。如果操作符是上面提到的,編譯器便會優(yōu)化掉比較指令。例如:
intaFunction(intx,inty)
{
if(x+y
盡可能的使用上面的判斷方式,這可以在關鍵循環(huán)中減少比較指令的調(diào)用,進而減少代碼體積并提高代碼性能。C語言沒有借位和溢出位的概念,因此,如果不借助匯編,不可能直接使用借位標志C和溢出位標志V。但編譯器支持借位(無符號溢出),例如:
intsum(intx,inty)
{
intres;
res=x+y;
if((unsigned)res
懶檢測開發(fā)
在if(a>10 && b=4)這樣的語句中,確保AND表達式的第一部分最可能較快的給出結(jié)果(或者最早、最快計算),這樣第二部分便有可能不需要執(zhí)行。
用switch()函數(shù)替代if…else…
對于涉及if…else…else…這樣的多條件判斷,例如:
if(val==1)
dostuff1();
elseif(val==2)
dostuff2();
elseif(val==3)
dostuff3();
使用switch可能更快:
switch(val)
{
case1:dostuff1();break;
case2:dostuff2();break;
case3:dostuff3();break;
}
在if()語句中,如果最后一條語句命中,之前的條件都需要被測試執(zhí)行一次。Switch允許我們不做額外的測試。如果必須使用if…else…語句,將最可能執(zhí)行的放在最前面。
二分中斷
使用二分方式中斷代碼而不是讓代碼堆成一列,不要像下面這樣做:
if(a==1){
}elseif(a==2){
}elseif(a==3){
}elseif(a==4){
}elseif(a==5){
}elseif(a==6){
}elseif(a==7){
}elseif(a==8)
{
}
使用下面的二分方式替代它,如下:
if(a<=4)?{
????if(a==1)?????{
????}??else?if(a==2)??{
????}??else?if(a==3)??{
????}??else?if(a==4)???{
????}
}
else
{
????if(a==5)??{
????}?else?if(a==6)???{
????}?else?if(a==7)??{
????}?else?if(a==8)??{
????}
}
或者如下:
if(a<=4)
{
????if(a<=2)
????{
????????if(a==1)
????????{
????????????/*?a?is?1?*/
????????}
????????else
????????{
????????????/*?a?must?be?2?*/
????????}
????}
????else
????{
????????if(a==3)
????????{
????????????/*?a?is?3?*/
????????}
????????else
????????{
????????????/*?a?must?be?4?*/
????????}
????}
}
else
{
????if(a<=6)
????{
????????if(a==5)
????????{
????????????/*?a?is?5?*/
????????}
????????else
????????{
????????????/*?a?must?be?6?*/
????????}
????}
????else
????{
????????if(a==7)
????????{
????????????/*?a?is?7?*/
????????}
????????else
????????{
????????????/*?a?must?be?8?*/
????????}
????}
}
比較如下兩種case語句:
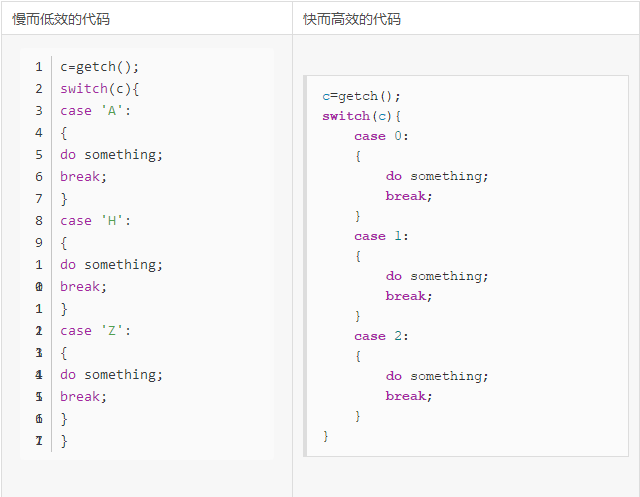 ======001
======001
switch語句vs查找表
Switch的應用場景如下:
調(diào)用一到多個函數(shù)
設置變量值或者返回一個值
執(zhí)行一到多個代碼片段
如果case標簽很多,在switch的前兩個使用場景中,使用查找表可以更高效的完成。例如下面的兩種轉(zhuǎn)換字符串的方式:
char*Condition_String1(intcondition){
switch(condition){
case0:return"EQ";
case1:return"NE";
case2:return"CS";
case3:return"CC";
case4:return"MI";
case5:return"PL";
case6:return"VS";
case7:return"VC";
case8:return"HI";
case9:return"LS";
case10:return"GE";
case11:return"LT";
case12:return"GT";
case13:return"LE";
case14:return"";
default:return0;
}
}
char*Condition_String2(intcondition){
if((unsigned)condition>=15)return0;
return
"EQNECSCCMIPLVSVCHILSGELTGTLE"+
3*condition;
}
第一個程序需要240 bytes,而第二個僅僅需要72 bytes。
循環(huán)
循環(huán)是大多數(shù)程序中的常用的結(jié)構;程序執(zhí)行的大部分時間發(fā)生在循環(huán)中,因此十分值得在循環(huán)執(zhí)行時間上下一番功夫。
循環(huán)終止
如果不加注意,循環(huán)終止條件的編寫會導致額外的負擔。我們應該使用計數(shù)到零的循環(huán)和簡單的循環(huán)終止條件。簡單的終止條件消耗更少的時間。看下面計算n!的兩個程序。第一個實現(xiàn)使用遞增的循環(huán),第二個實現(xiàn)使用遞減循環(huán)。
intfact1_func(intn)
{
inti,fact=1;
for(i=1;i<=?n;?i++)
??????fact?*=?i;
????return?(fact);
}
?
int?fact2_func(int?n)
{
????int?i,?fact?=?1;
????for?(i?=?n;?i?!=?0;?i--)
???????fact?*=?i;
????return?(fact);
}
第二個程序的fact2_func執(zhí)行效率高于第一個。
更快的for()循環(huán)
這是一個簡單而高效的概念。通常,我們編寫for循環(huán)代碼如下:
for(i=0;i<10;??i++){?...?}
i從0循環(huán)到9。如果我們不介意循環(huán)計數(shù)的順序,我們可以這樣寫:
for(i=10;i--;){...}
這樣快的原因是因為它能更快的處理i的值–測試條件是:i是非零的嗎?如果這樣,遞減i的值。對于上面的代碼,處理器需要計算“計算i減去10,其值非負嗎?如果非負,i遞增并繼續(xù)”。
簡單的循環(huán)卻有很大的不同。這樣,i從9遞減到0,這樣的循環(huán)執(zhí)行速度更快。
這里的語法有點奇怪,但確實合法的。循環(huán)中的第三條語句是可選的(無限循環(huán)可以寫為for(;;))。如下代碼擁有同樣的效果:
for(i=10;i;i--){}
或者更進一步的:
for(i=10;i!=0;i--){}
這里我們需要記住的是循環(huán)必須終止于0(因此,如果在50到80之間循環(huán),這不會起作用),并且循環(huán)計數(shù)器是遞減的。使用遞增循環(huán)計數(shù)器的代碼不享有這種優(yōu)化。
合并循環(huán)
如果一個循環(huán)能解決問題堅決不用二個。但如果你需要在循環(huán)中做很多工作,這坑你并不適合處理器的指令緩存。這種情況下,兩個分開的循環(huán)可能會比單個循環(huán)執(zhí)行的更快。下面是一個例子:
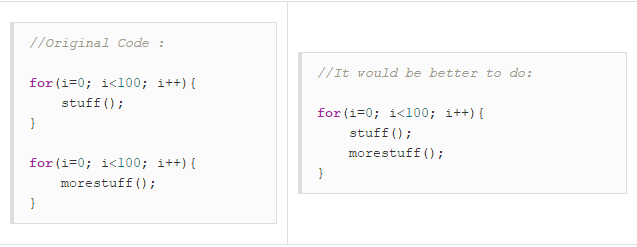 ======002
======002
函數(shù)循環(huán)
調(diào)用函數(shù)時總是會有一定的性能消耗。不僅程序指針需要改變,而且使用的變量需要壓棧并分配新變量。為提升程序的性能,在函數(shù)這點上有很多可以優(yōu)化的。在保持程序代碼可讀性的同時也需要代碼的大小是可控的。
如果在循環(huán)中一個函數(shù)經(jīng)常被調(diào)用,那么就將循環(huán)納入到函數(shù)中,這樣可以減少重復的函數(shù)調(diào)用。代碼如下:
for(i=0;i<100?;?i++)
{
????func(t,i);
}
-
-
-
void?func(int?w,d)
{
????lots?of?stuff.
}
應改為:
func(t);
-
-
-
voidfunc(w)
{
for(i=0;i<100?;?i++)
????{
????????//lots?of?stuff.
????}
}
循環(huán)展開
簡單的循環(huán)可以展開以獲取更好的性能,但需要付出代碼體積增加的代價。循環(huán)展開后,循環(huán)計數(shù)應該越來越小從而執(zhí)行更少的代碼分支。如果循環(huán)迭代次數(shù)只有幾次,那么可以完全展開循環(huán),以便消除循壞帶來的負擔。
這會帶來很大的不同。循環(huán)展開可以帶非常可觀的節(jié)省性能,原因是代碼不用每次循環(huán)需要檢查和增加i的值。例如:
 ======003
======003
編譯器通常會像上面那樣展開簡單的,迭代次數(shù)固定的循環(huán)。但是像下面的代碼:
for(i=0;i
下面的代碼(Example 1)明顯比使用循環(huán)的方式寫的更長,但卻更有效率。block-sie的值設置為8僅僅適用于測試的目的,只要我們重復執(zhí)行“l(fā)oop-contents”相同的次數(shù),都會有很好的效果。
在這個例子中,循環(huán)條件每8次迭代才會被檢查,而不是每次都進行檢查。由于不知道迭代的次數(shù),一般不會被展開。因此,盡可能的展開循環(huán)可以讓我們獲得更好的執(zhí)行速度。
//Example1
#include
#defineBLOCKSIZE(8)
voidmain(void)
{
inti=0;
intlimit=33;/*couldbeanything*/
intblocklimit;
/*ThelimitmaynotbedivisiblebyBLOCKSIZE,
*goasnearaswecanfirst,thentidyup.
*/
blocklimit=(limit/BLOCKSIZE)*BLOCKSIZE;
/*unrolltheloopinblocksof8*/
while(i
統(tǒng)計非零位的數(shù)量
通過不斷的左移,提取并統(tǒng)計最低位,示例程序1高效的檢查一個數(shù)組中有幾個非零位。示例程序2被循環(huán)展開四次,然后通過將四次移位合并成一次來優(yōu)化代碼。經(jīng)常展開循環(huán),可以提供很多優(yōu)化的機會。
//Example-1
intcountbit1(uintn)
{
intbits=0;
while(n!=0)
{
if(n&1)bits++;
n>>=1;
}
returnbits;
}
//Example-2
intcountbit2(uintn)
{
intbits=0;
while(n!=0)
{
if(n&1)bits++;
if(n&2)bits++;
if(n&4)bits++;
if(n&8)bits++;
n>>=4;
}
returnbits;
}
盡早的斷開循環(huán)
通常,循環(huán)并不需要全部都執(zhí)行。例如,如果我們在從數(shù)組中查找一個特殊的值,一經(jīng)找到,我們應該盡可能早的斷開循環(huán)。例如:如下循環(huán)從10000個整數(shù)中查找是否存在-99。
found=FALSE;
for(i=0;i<10000;i++)
{
????if(?list[i]?==?-99?)
????{
????????found?=?TRUE;
????}
}
?
if(?found?)?
????printf("Yes,?there?is?a?-99.?Hooray!n");
上面的代碼可以正常工作,但是需要循環(huán)全部執(zhí)行完畢,而不論是否我們已經(jīng)查找到。更好的方法是一旦找到我們查找的數(shù)字就終止繼續(xù)查詢。
found=FALSE;
for(i=0;i<10000;?i++)
{
????if(?list[i]?==?-99?)
????{
????????found?=?TRUE;
????????break;
????}
}
if(?found?)?
????printf("Yes,?there?is?a?-99.?Hooray!n");
假如待查數(shù)據(jù)位于第23個位置上,程序便會執(zhí)行23次,從而節(jié)省9977次循環(huán)。
函數(shù)設計
設計小而簡單的函數(shù)是個很好的習慣。這允許寄存器可以執(zhí)行一些諸如寄存器變量申請的優(yōu)化,是非常高效的。
函數(shù)調(diào)用的性能消耗
函數(shù)調(diào)用對于處理器的性能消耗是很小的,只占有函數(shù)執(zhí)行工作中性能消耗的一小部分。參數(shù)傳入函數(shù)變量寄存器中有一定的限制。這些參數(shù)必須是整型兼容的(char,shorts,ints和floats都占用一個字)或者小于四個字大小(包括占用2個字的doubles和long longs)。
如果參數(shù)限制個數(shù)為4,那么第五個和之后的字就會存儲在棧上。這便在調(diào)用函數(shù)是需要從棧上加載參數(shù)從而增加存儲和讀取的消耗。
看下面的代碼:
intf1(inta,intb,intc,intd){
returna+b+c+d;
}
intg1(void){
returnf1(1,2,3,4);
}
intf2(inta,intb,intc,intd,inte,intf){
returna+b+c+d+e+f;
}
ingg2(void){
returnf2(1,2,3,4,5,6);
}
函數(shù)g2中的第五個和第六個參數(shù)存儲于棧上并在函數(shù)f2中進行加載,會多消耗2個參數(shù)的存儲。
減少函數(shù)參數(shù)傳遞消耗
減少函數(shù)參數(shù)傳遞消耗的方法有:
盡量保證函數(shù)使用少于四個參數(shù)。這樣就不會使用棧來存儲參數(shù)值。
如果函數(shù)需要多于四個的參數(shù),盡量確保使用后面參數(shù)的價值高于讓其存儲于棧所付出的代價。
通過指針傳遞參數(shù)的引用而不是傳遞參數(shù)結(jié)構體本身。
將參數(shù)放入一個結(jié)構體并通過指針傳入函數(shù),這樣可以減少參數(shù)的數(shù)量并提高可讀性。
盡量少用占用兩個字大小的long類型參數(shù)。對于需要浮點類型的程序,double也因為占用兩個字大小而應盡量少用。
避免函數(shù)參數(shù)既存在于寄存器又存在于棧中(稱之為參數(shù)拆分)。現(xiàn)在的編譯器對這種情況處理的不夠高效:所有的寄存器變量也會放入到棧中。
避免變參。變參函數(shù)將參數(shù)全部放入棧。
葉子函數(shù)
不調(diào)用任何函數(shù)的函數(shù)稱之為葉子函數(shù)。在以下應用中,近一半的函數(shù)調(diào)用是調(diào)用葉子函數(shù)。由于不需要執(zhí)行寄存器變量的存儲和讀取,葉子函數(shù)在任何平臺都很高效。
寄存器變量讀取的性能消耗,相比于使用四五個寄存器變量的葉子函數(shù)所做的工作帶來的系能消耗是非常小的。所以盡可能的將經(jīng)常調(diào)用的函數(shù)寫成葉子函數(shù)。
函數(shù)調(diào)用的次數(shù)可以通過一些工具檢查。下面是一些將一個函數(shù)編譯為葉子函數(shù)的方法:
避免調(diào)用其他函數(shù):包括那些轉(zhuǎn)而調(diào)用C庫的函數(shù)(比如除法或者浮點數(shù)操作函數(shù))。
對于簡短的函數(shù)使用__inline修飾()。
內(nèi)聯(lián)函數(shù)
內(nèi)聯(lián)函數(shù)禁用所有的編譯選項。使用__inline修飾函數(shù)導致函數(shù)在調(diào)用處直接替換為函數(shù)體。這樣代碼調(diào)用函數(shù)更快,但增加代碼的大小,特別在函數(shù)本身比較大而且經(jīng)常調(diào)用的情況下。
__inlineintsquare(intx){
returnx*x;
}
#include
doublelength(intx,inty){
returnsqrt(square(x)+square(y));
}
使用內(nèi)聯(lián)函數(shù)的好處如下:
沒有函數(shù)調(diào)用負擔。函數(shù)調(diào)用處直接替換為函數(shù)體,因此沒有諸如讀取寄存器變量等性能消耗。
更小的參數(shù)傳遞消耗。由于不需要拷貝變量,傳遞參數(shù)的消耗更小。如果參數(shù)是常量,編譯器可以提供更好的優(yōu)化。
內(nèi)聯(lián)函數(shù)的缺陷是如果調(diào)用的地方很多,代碼的體積會變得很大。這主要取決于函數(shù)本身的大小和調(diào)用的次數(shù)。
僅對重要的函數(shù)使用inline是明智的。如果使用得當,內(nèi)聯(lián)函數(shù)甚至可以減少代碼的體積:函數(shù)調(diào)用會產(chǎn)生一些計算機指令,但是使用內(nèi)聯(lián)的優(yōu)化版本可能產(chǎn)生更少的計算機指令。
使用查找表
函數(shù)通常可以設計成查找表,這樣可以顯著提升性能。查找表的精確度比通常的計算低,但對于一般的程序并沒什么差異。
許多信號處理程序(例如,調(diào)制解調(diào)器解調(diào)軟件)使用很多非常消耗計算性能的sin和cos函數(shù)。對于實時系統(tǒng),精確性不是特別重要,sin、cos查找表可能更合適。當使用查找表時,盡可能將相似的操作放入查找表,這樣比使用多個查找表更快,更能節(jié)省存儲空間。
浮點運算
盡管浮點運算對于所有的處理器都很耗時,但對于實現(xiàn)信號處理軟件時我們?nèi)匀恍枰褂谩T诰帉懜↑c操作程序時,記住如下幾點:
浮點除法很慢。浮點除法比加法或者乘法慢兩倍。通過使用常量將除法轉(zhuǎn)換為乘法(例如,x=x/3.0可以替換為x=x*(1.0/3.0))。常量的除法在編譯期間計算。
使用float代替double。Float類型的變量消耗更好的內(nèi)存和寄存器,并由于精度低而更加高效。如果精度夠用,盡可能使用float。
避免使用先驗函數(shù)。先驗函數(shù),例如sin、exp和log是通過一系列的乘法和加法實現(xiàn)的(使用了精度擴展)。這些操作比通常的乘法至少慢十倍。
簡化浮點運算表達式。編譯器并不能將應用于整型操作的優(yōu)化手段應用于浮點操作。例如,3*(x/3)可以優(yōu)化為x,而浮點運算就會損失精度。因此,如果知道結(jié)果正確,進行必要手工浮點優(yōu)化是有必要的。
然而,浮點運算的表現(xiàn)可能不能滿足特定軟件對性能的需求。這種情況下,最好的辦法或許是使用定點算數(shù)運算。當值的范圍足夠小,定點算數(shù)操作比浮點運算更精確、更快速。
其他技巧
通常,可以使用空間換時間。如果你能緩存經(jīng)常用的數(shù)據(jù)而不是重新計算,這便能更快的訪問。比如sine和cosine查找表,或者偽隨機數(shù)。
盡量不在循環(huán)中使用++和–。例如:while(n–){},這有時難于優(yōu)化。
減少全局變量的使用。
除非像聲明為全局變量,使用static修飾變量為文件內(nèi)訪問。
盡可能使用一個字大小的變量(int、long等),使用它們(而不是char,short,double,位域等)機器可能運行的更快。
不使用遞歸。遞歸可能優(yōu)雅而簡單,但需要太多的函數(shù)調(diào)用。
不在循環(huán)中使用sqrt開平方函數(shù),計算平方根非常消耗性能。
一維數(shù)組比多維數(shù)組更快。
編譯器可以在一個文件中進行優(yōu)化-避免將相關的函數(shù)拆分到不同的文件中,如果將它們放在一起,編譯器可以更好的處理它們(例如可以使用inline)。
單精度函數(shù)比雙精度更快。
浮點乘法運算比浮點除法運算更快-使用val*0.5而不是val/2.0。
加法操作比乘法快-使用val+val+val而不是val*3。
put()函數(shù)比printf()快,但不靈活。
使用#define宏取代常用的小函數(shù)。
二進制/未格式化的文件訪問比格式化的文件訪問更快,因為程序不需要在人為可讀的ASCII和機器可讀的二進制之間轉(zhuǎn)化。如果你不需要閱讀文件的內(nèi)容,將它保存為二進制。
如果你的庫支持mallopt()函數(shù)(用于控制malloc),盡量使用它。MAXFAST的設置,對于調(diào)用很多次malloc工作的函數(shù)由很大的性能提升。如果一個結(jié)構一秒鐘內(nèi)需要多次創(chuàng)建并銷毀,試著設置mallopt選項。
最后,但是是最重要的是-將編譯器優(yōu)化選項打開!看上去很顯而易見,但卻經(jīng)常在產(chǎn)品推出時被忘記。編譯器能夠在更底層上對代碼進行優(yōu)化,并針對目標處理器執(zhí)行特定的優(yōu)化處理。
-- End--
審核編輯黃宇
-
處理器
+關注
關注
68文章
19286瀏覽量
229854 -
ARM
+關注
關注
134文章
9097瀏覽量
367586 -
C語言
+關注
關注
180文章
7604瀏覽量
136842 -
編譯器
+關注
關注
1文章
1634瀏覽量
49133
發(fā)布評論請先 登錄
相關推薦
嵌入式C語言代碼優(yōu)化的經(jīng)驗與方法
嵌入式C語言代碼優(yōu)化的經(jīng)驗與方法
嵌入式C語言進階之道
嵌入式實時程序設計中C/C++代碼的優(yōu)化
嵌入式程序設計中C/C++代碼的優(yōu)化
嵌入式系統(tǒng)C語言位操作的移植與優(yōu)化
嵌入式系統(tǒng)高級C語言編程

嵌入式系統(tǒng)C語言的特點及程序設計中代碼優(yōu)化的技巧
嵌入式C語言知識總結(jié)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論