") 全面分析特斯拉機(jī)器人“超算”芯片
全面分析特斯拉機(jī)器人“超算”芯片
存算一體/GPU架構(gòu)和AI專(zhuān)家,高級(jí)職稱(chēng)。中關(guān)村云計(jì)算產(chǎn)業(yè)聯(lián)盟,中國(guó)光學(xué)工程學(xué)會(huì)專(zhuān)家,國(guó)際計(jì)算機(jī)學(xué)會(huì)(ACM)會(huì)員,中國(guó)計(jì)算機(jī)學(xué)會(huì)(CCF)專(zhuān)業(yè)會(huì)員。曾任AI企業(yè)首席科學(xué)家、存儲(chǔ)芯片大廠3D NAND設(shè)計(jì)負(fù)責(zé)人,主要成就包括國(guó)內(nèi)首個(gè)大算力可重構(gòu)存算處理器產(chǎn)品架構(gòu)(已在互聯(lián)網(wǎng)大廠完成原型內(nèi)測(cè)),首個(gè)醫(yī)療領(lǐng)域?qū)S肁I處理器(已落地應(yīng)用),首個(gè)RISC-V/x86/ARM平臺(tái)兼容的AI加速編譯器(與阿里平頭哥/芯來(lái)合作,已應(yīng)用),國(guó)內(nèi)首個(gè)3D NAND芯片架構(gòu)與設(shè)計(jì)團(tuán)隊(duì)建立(與三星對(duì)標(biāo)),國(guó)內(nèi)首個(gè)嵌入式閃存編譯器(與臺(tái)積電對(duì)標(biāo),已平臺(tái)級(jí)應(yīng)用)。
本文將深入特斯拉D1處理器的整體架構(gòu)和設(shè)計(jì)哲學(xué),并結(jié)合特斯拉的專(zhuān)利對(duì)其進(jìn)行深度分析,包括矩陣計(jì)算單元、指令集、Chiplet封裝、編譯生態(tài)等。
2022年9月最后一天,特斯拉的人工智能日,特斯拉“擎天柱”機(jī)器人正式登臺(tái)亮相。按照特斯拉工程師的說(shuō)法,2022 年人工智能日是特斯拉機(jī)器人第一次在沒(méi)有任何外部支持的情況下被“放出“。“他“步姿端莊,大方向場(chǎng)上觀眾打招呼。除了動(dòng)作稍微遲緩之外,其他都很自然。
1,特斯拉機(jī)器人強(qiáng)大在于“內(nèi)芯”?
特斯拉展示了機(jī)器人在辦公室周?chē)肮ぷ鳌钡?a href="http://www.xsypw.cn/v/" target="_blank">視頻。名為擎天柱的機(jī)器人搬運(yùn)物品,給植物澆水,甚至自主的在工廠工作了一段時(shí)間。”我們的目標(biāo)是盡快制造出有用的人形機(jī)器人”,特斯拉表明,他們的目標(biāo)是讓機(jī)器人的價(jià)格低于 2 萬(wàn)美元,或者比特斯拉的電動(dòng)汽車(chē)便宜。
特斯拉機(jī)器人之所以這么強(qiáng),除了特斯拉本身在AI技術(shù)的積累外,更主要得益于特斯拉強(qiáng)勁的自研AI芯片。這顆AI芯片,不是傳統(tǒng)上的CPU,更不是GPU,是一種更適合復(fù)雜AI計(jì)算的形態(tài)。
D1處理器與其他自動(dòng)駕駛/機(jī)器人處理器的對(duì)比
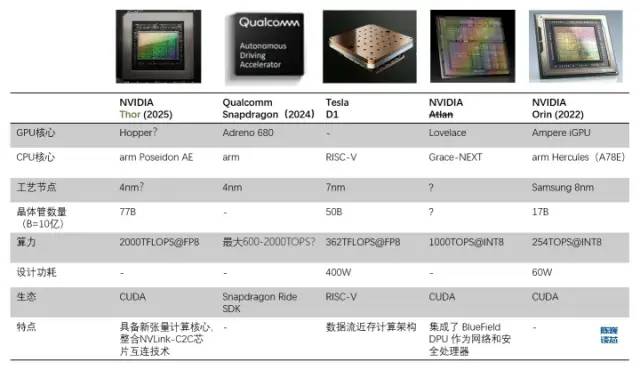
1.1 基于數(shù)據(jù)流近存架構(gòu)打造一顆超越GPU的通用AI芯片
特斯拉打造自有芯片的原因是,GPU 并不是專(zhuān)門(mén)為處理深度學(xué)習(xí)訓(xùn)練而設(shè)計(jì)的,這使得GPU在計(jì)算任務(wù)中的效率相對(duì)較低。特斯拉與 Dojo(Dojo既是訓(xùn)練模組的名稱(chēng),又是內(nèi)核架構(gòu)名稱(chēng)) 的目標(biāo)是“實(shí)現(xiàn)最佳的 AI 訓(xùn)練性能。啟用更大、更復(fù)雜的神經(jīng)網(wǎng)絡(luò)模型,實(shí)現(xiàn)高能效且經(jīng)濟(jì)高效的計(jì)算。” 特斯拉的標(biāo)準(zhǔn)是制造一臺(tái)比其他任何計(jì)算機(jī)都更擅長(zhǎng)人工智能計(jì)算的計(jì)算機(jī),從而他們將來(lái)不需要再使用 GPU。
構(gòu)建超級(jí)計(jì)算機(jī)一個(gè)關(guān)鍵點(diǎn)是如何在擴(kuò)展計(jì)算能力同時(shí)保持高帶寬(困難)和低延遲(非常困難)。特斯拉給出的解決方案是強(qiáng)大的芯片和獨(dú)特的網(wǎng)格結(jié)構(gòu)組成的分布式 2D 架構(gòu)(平面),或者說(shuō)是數(shù)據(jù)流近存計(jì)算架構(gòu)。
特斯拉算力單元的層級(jí)劃分
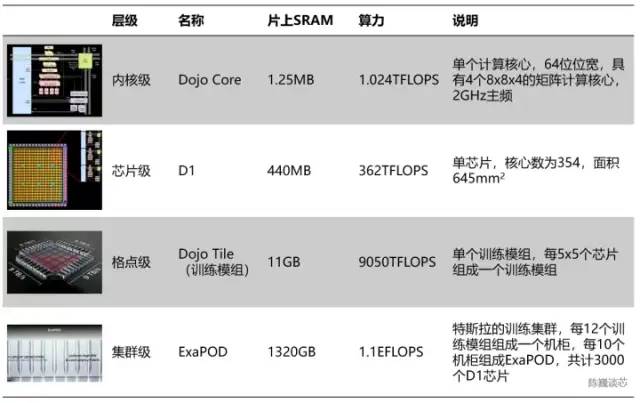
按照層次劃分的話(huà),每354個(gè)Dojo核心組成一塊D1芯片,而每25顆芯片組成一個(gè)訓(xùn)練模組。最后120個(gè)訓(xùn)練模組組成一組ExaPOD計(jì)算集群,共計(jì)3000顆D1芯片。
一個(gè)特斯拉Dojo芯片訓(xùn)練模組可以達(dá)到6組GPU服務(wù)器的性能,成本卻少于單組GPU服務(wù)器。單臺(tái)Dojo服務(wù)器算力甚至達(dá)到了54PFLOPS。只用 4 個(gè) Dojo 機(jī)柜就能取代由 4000 顆 GPU 組成的 72 組 GPU 機(jī)架。Dojo 將通常需要幾個(gè)月的AI計(jì)算(訓(xùn)練)工作減少到了1 周。這樣的“大算力出奇跡”,與特斯拉自動(dòng)駕駛的風(fēng)格一脈相承。顯然芯片也會(huì)大大加速特斯拉AI技術(shù)的進(jìn)步速度。
當(dāng)然,這一芯片模組還沒(méi)有到達(dá)“完美”的程度,盡管采用了數(shù)據(jù)流近存計(jì)算的思路,其算力能效比并沒(méi)有超過(guò)GPU。單個(gè)服務(wù)器的功耗巨大,電流達(dá)到了2000A,需要特殊定制的電源供電。特斯拉D1芯片已經(jīng)是近存計(jì)算架構(gòu)的結(jié)構(gòu)極限了。如果特斯拉采用“存內(nèi)計(jì)算”或者“存內(nèi)邏輯”架構(gòu),或許芯片性能或能效比還會(huì)有大幅度提升。

特斯拉Dojo芯片服務(wù)器由12個(gè)Dojo訓(xùn)練模組組成(2層,每層6個(gè))
1.2 特斯拉的Dojo架構(gòu)設(shè)計(jì)哲學(xué)
Dojo核心是一個(gè)8路譯碼的內(nèi)核,具有較高吞吐量和4路矩陣計(jì)算單元(8x8)以及 1.25 MB 的本地 SRAM。但是Dojo核心的尺寸卻不大,相比之下,富士通的A64FX在同一工藝節(jié)點(diǎn)上占據(jù)的面積是其兩倍以上。
通過(guò)Dojo核心的結(jié)構(gòu),我們可以看出特斯拉在通用AI處理器上的設(shè)計(jì)哲學(xué):
面積精簡(jiǎn):特斯拉通過(guò)將大量計(jì)算內(nèi)核集成到芯片中,以最大限度提高AI計(jì)算的吞吐量,因此需要在保障算力的情況下使單個(gè)內(nèi)核的面積盡可能小,更好的折衷超算系統(tǒng)中算力堆疊和延遲的矛盾。
緩存與延遲精簡(jiǎn):為了實(shí)現(xiàn)其區(qū)域計(jì)算效率最大化,Dojo內(nèi)核以相對(duì)保守的 2 GHz 運(yùn)行(保守時(shí)鐘電路往往占用較少的面積),只使用基本的分支預(yù)測(cè)器和小的指令緩存,在如此精簡(jiǎn)只保留必要部件的架構(gòu)下。其余面積盡可能留給向量計(jì)算和矩陣計(jì)算單元。當(dāng)然,如果內(nèi)核程序的代碼占用量很大,或分支較多時(shí),這種策略可能會(huì)犧牲一些性能。
功能精簡(jiǎn):通過(guò)削減對(duì)運(yùn)行內(nèi)部計(jì)算不是必須的處理器功能來(lái)進(jìn)一步減少功耗和面積使用。Dojo核心不進(jìn)行數(shù)據(jù)端緩存,不支持虛擬內(nèi)存,也不支持精確異常。
對(duì)于特斯拉和馬斯克而言,Dojo不僅僅形狀布局像道場(chǎng),其設(shè)計(jì)哲學(xué)也與道場(chǎng)的精神息息相關(guān),充分體現(xiàn)了“少即是多”的處理器設(shè)計(jì)美學(xué)。
2,D1核心是RISC-V架構(gòu)嗎?
我們先來(lái)看看每個(gè)Dojo的結(jié)構(gòu)和特點(diǎn)。
每個(gè)Dojo核心是帶有向量計(jì)算/矩陣計(jì)算能力的處理器,具有完整的取指、譯碼、執(zhí)行部件。Dojo核心具有類(lèi)似CPU的 風(fēng)格,似乎比GPU 更能適應(yīng)不同的算法和分支代碼。D1的指令集類(lèi)似于 RISC-V,處理器運(yùn)行在2GHz,具有4組8x8矩陣乘法計(jì)算單元。同時(shí)具有一組自定義向量指令,專(zhuān)注于加速AI計(jì)算。
對(duì)RISC-V領(lǐng)域熟悉的大概能看出,特斯拉Dojo架構(gòu)圖的配色方案像是在致敬伯克利的BOOM處理器架構(gòu)圖,上黃中綠下紫。
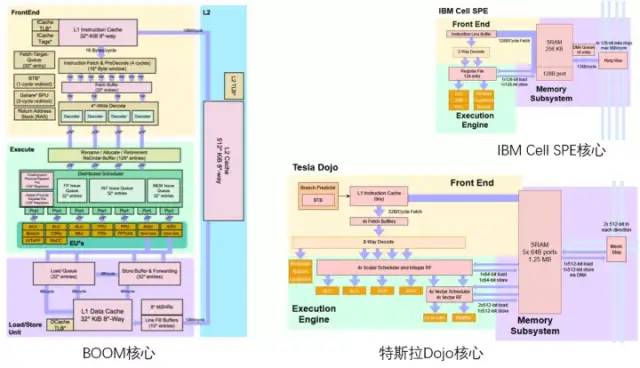
特斯拉Dojo核心與伯克利BOOM/ IBM Cell核心對(duì)比
2.1 D1核心整體架構(gòu)
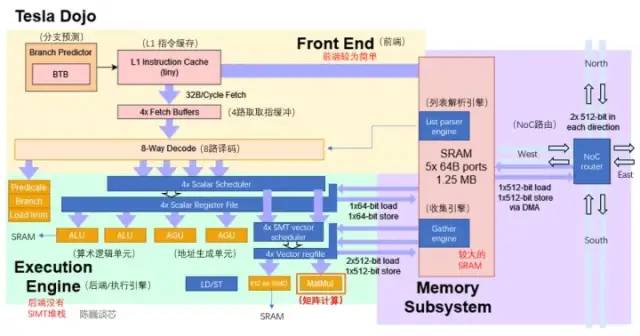
D1核心結(jié)構(gòu)(藍(lán)色部分為添加/修改的細(xì)節(jié))
從目前的架構(gòu)圖來(lái)看,Dojo核心由前端、執(zhí)行單元、SRAM和NoC路由4部分組成,比CPU和GPU的控制部件都更少,具有類(lèi)似CPU的AGU和思路類(lèi)似GPU張量核心(Tensor core)的矩陣計(jì)算單元。
Dojo核心結(jié)構(gòu)比BOOM更加精簡(jiǎn),沒(méi)有Rename這些改善執(zhí)行部件利用率的組件,同時(shí)也難于支持虛擬內(nèi)存。但這樣設(shè)計(jì)的好處是減少了控制部分占用的面積,可以把芯片上更多的面積劃分給計(jì)算執(zhí)行單元。每個(gè)Dojo核心提供了1.024TFLOPS的算力。可以看到,每個(gè)幾乎所有的算力都由矩陣計(jì)算單元提供。因而矩陣計(jì)算單元和SRAM共同決定了D1處理器的計(jì)算能效比。
Dojo核心的主要參數(shù)

分支預(yù)測(cè):相對(duì)GPU這類(lèi)SIMT架構(gòu),Dojo核心也沒(méi)有SIMT堆棧核心來(lái)進(jìn)行多線程分支任務(wù)的分配。但Dojo核心具有 BTB(分支目標(biāo)緩沖區(qū)),因此D1可以通過(guò)簡(jiǎn)單的分支預(yù)測(cè)來(lái)提升性能。
BTB將分支成功的分支指令的地址和它的分支目標(biāo)地址都放到一個(gè)緩沖區(qū)中保存起來(lái),緩沖區(qū)以分支指令的地址作為標(biāo)識(shí)。可以通過(guò)預(yù)測(cè)分支的路徑和緩存分支使用的信息來(lái)減少流水線處理器中分支的性能損失。
指令緩存:較小的L1指令緩存直接與核心中的SRAM相連獲取計(jì)算指令。
取指:每個(gè)Dojo內(nèi)核具有 32 B 的取指窗口,最多可容納 8 條指令。
譯碼:一個(gè)8路解碼器每個(gè)周期可以處理兩個(gè)線程。譯碼階段從取指緩沖獲取指令并譯碼,并根據(jù)每條指令的要求分配必要的執(zhí)行資源。
線程調(diào)度:在較寬的8路譯碼之后,則是向量的調(diào)度器(Scheduler)和寄存器堆(Register File)。貌似這里沒(méi)有分支聚合的掩碼判斷,實(shí)際的分支執(zhí)行效率可能會(huì)比GPU略低。希望特斯拉有一個(gè)強(qiáng)大的編譯器吧。
執(zhí)行單元:具有2路ALU和2路AGU,以及針對(duì)向量/矩陣計(jì)算的512位SIMD和矩陣計(jì)算單元(分別執(zhí)行512位向量計(jì)算和4路8x8矩陣乘法)。其中矩陣計(jì)算單元是D1芯片的算力主體。(在下一節(jié)具體介紹)
ALU和AGU主要負(fù)責(zé)矩陣計(jì)算之外的少量邏輯計(jì)算。其中AGU是地址生成單元,主要用于生成操作SRAM所需的地址和訪問(wèn)其他核心的地址。通過(guò)由與 CPU 的其余部分并行運(yùn)行地址計(jì)算。
普通CPU 在執(zhí)行各種操作時(shí),需要計(jì)算從內(nèi)存(或SRAM)中取數(shù)據(jù)所需的內(nèi)存地址。例如,必須先計(jì)算數(shù)組元素的內(nèi)存位置,然后 CPU內(nèi)核才能從實(shí)際內(nèi)存位置獲取數(shù)據(jù)。這些地址生成計(jì)算涉及不同的整數(shù)算術(shù)運(yùn)算,例如加法、減法、模運(yùn)算或位移。計(jì)算內(nèi)存地址可以編譯多個(gè)通用機(jī)器指令,也可以類(lèi)似特斯拉Dojo這樣通過(guò)AGU的硬件電路直接執(zhí)行。這樣各種地址生成計(jì)算可以從ALU卸載,減少執(zhí)行AI計(jì)算所需等待的CPU 周期數(shù),從而提高計(jì)算性能。
SIMD主要負(fù)責(zé)激活等特殊功能計(jì)算和數(shù)據(jù)的累加。
矩陣計(jì)算單元是Dojo的主要算力原件,負(fù)責(zé)二維矩陣計(jì)算,進(jìn)而實(shí)現(xiàn)卷積、Transformer等計(jì)算。
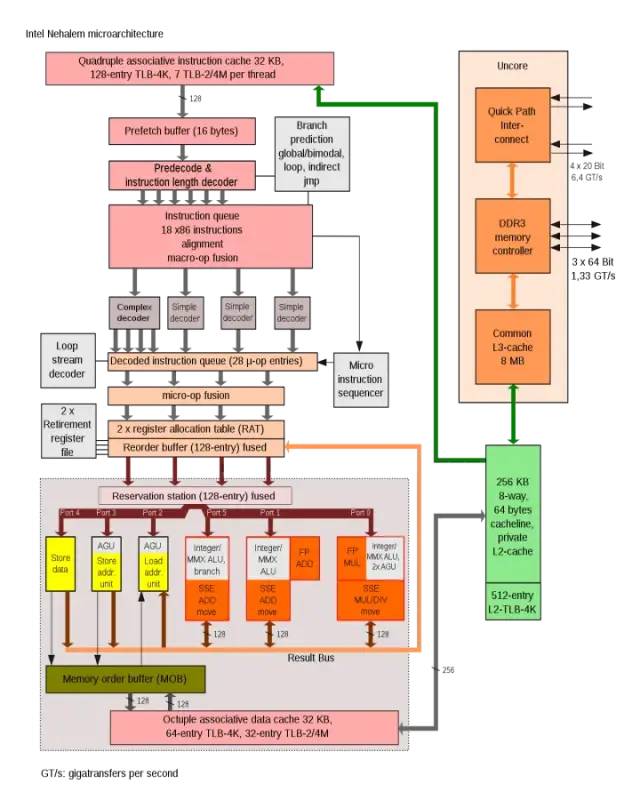
Intel Nehalem架構(gòu)中使用AGU來(lái)提升單周期地址訪問(wèn)效率
Dojo內(nèi)核的連接方式比較像 IBM 的 Cell處理器中的SPE內(nèi)核連接方式。主要的相似點(diǎn)包括:
D1或 SPE 上運(yùn)行的代碼都不能直接訪問(wèn)系統(tǒng)內(nèi)存,應(yīng)用程序主要在本地 SRAM 中工作;
如果需要來(lái)自主存儲(chǔ)器(DDR或HBM)的數(shù)據(jù),須使用 DMA 操作進(jìn)行讀入
D1 和 Cell 的 SPE 都不支持虛擬內(nèi)存。
下面將介紹計(jì)算與矩陣乘法模塊與內(nèi)核的存儲(chǔ)。
2.2 算力核心矩陣計(jì)算單元與片內(nèi)存儲(chǔ)
Dojo架構(gòu)算力增強(qiáng)的核心是矩陣計(jì)算單元。矩陣計(jì)算單元與核心SRAM的數(shù)據(jù)交互構(gòu)成了主要的內(nèi)核數(shù)據(jù)搬運(yùn)功耗。
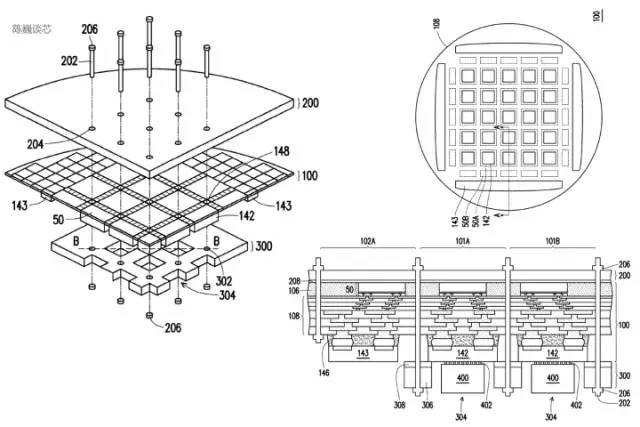
特斯拉矩陣計(jì)算單元相應(yīng)的專(zhuān)利如下圖。該模塊關(guān)鍵部件是一個(gè)8x8矩陣-矩陣乘法單元(圖中稱(chēng)為矩陣計(jì)算器)。輸入為數(shù)據(jù)輸入陣列和權(quán)重輸入陣列,計(jì)算矩陣乘法后直接在輸出進(jìn)行累加。每個(gè)Dojo核心包括4路8x8矩陣乘法單元。
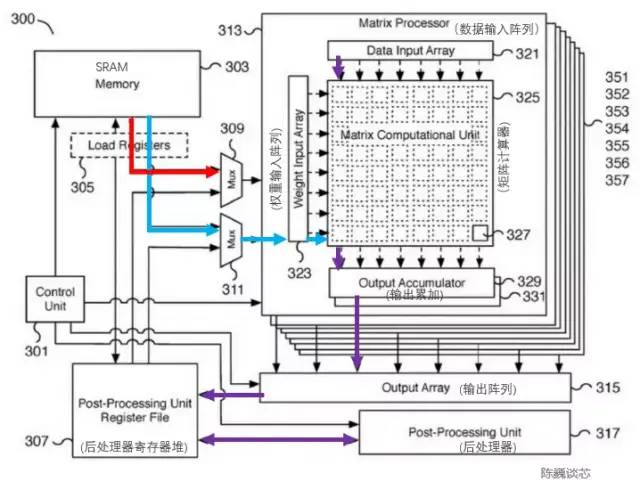
特斯拉矩陣計(jì)算單元專(zhuān)利
由于架構(gòu)圖上只有一個(gè)L1 緩存和SRAM,大膽猜測(cè)特斯拉精簡(jiǎn)了RISC-V的緩存結(jié)構(gòu),目的是節(jié)約緩存面積并減少延遲。每個(gè)核心1.25MB的SRAM塊可以為SIMD和矩陣計(jì)算單元提供2x512位的讀(對(duì)應(yīng)AI計(jì)算的權(quán)重和數(shù)據(jù))和512位的寫(xiě)帶寬,以及面向整數(shù)寄存器堆的64位讀寫(xiě)能力。計(jì)算的主要數(shù)據(jù)流是從SRAM到SIMD和矩陣乘法單元。
矩陣計(jì)算單元的主要處理流程為:
通過(guò)多路選擇器(Mux)從SRAM中加載權(quán)重到權(quán)重輸入陣列(Weight input array),同時(shí)SRAM中加載數(shù)據(jù)到數(shù)據(jù)輸入陣列(Data input array)。
輸入的數(shù)據(jù)與權(quán)重在矩陣計(jì)算器(Matrix computation Unit)中進(jìn)行乘法計(jì)算(內(nèi)積或外積?)
乘法計(jì)算結(jié)果輸出到輸出累加(Output accumulator)中進(jìn)行累加。這里計(jì)算時(shí)可以通過(guò)矩陣劃分拼接的方式進(jìn)行超過(guò)8x8的矩陣計(jì)算。
累加后的輸出傳入后處理器寄存器堆進(jìn)行緩存,隨后進(jìn)行后處理(可執(zhí)行例如激活、池化、Padding等操作)。
整個(gè)計(jì)算流程由控制單元(Control unit)直接控制,無(wú)需CPU干預(yù)。
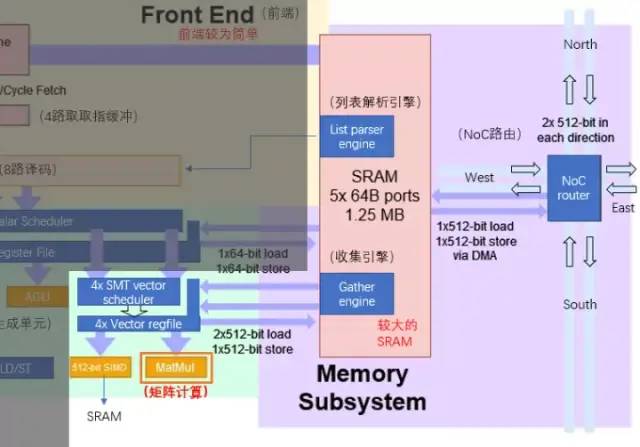
執(zhí)行單元與SRAM/NoC的數(shù)據(jù)交互
Dojo核心內(nèi)的SRAM具有非常大的讀寫(xiě)帶寬,可以以 400 GB/秒的速度加載并以 270 GB/秒的速度寫(xiě)入。Dojo核心指令集具有專(zhuān)用的網(wǎng)絡(luò)傳輸指令,通過(guò)NoC路由,可以直接將數(shù)據(jù)移入或移出 D1 芯片中甚至Dojo訓(xùn)練模塊中其他內(nèi)核的SRAM 存儲(chǔ)器。
與普通的SRAM不同,Dojo的SRAM包括列表解析引擎(list parser engine)和一個(gè)收集引擎(gather engine)。列表解析功能是 D1芯片的關(guān)鍵特性之一,通過(guò)列表解析引擎可以將復(fù)雜的不同數(shù)據(jù)類(lèi)型的傳輸序列進(jìn)行打包,提升傳輸效率。
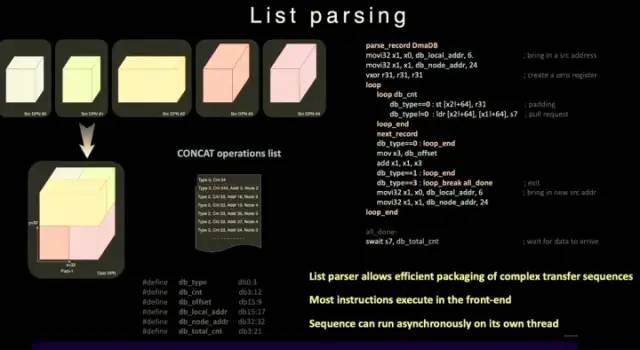
列表解析功能
為了進(jìn)一步減少操作延遲、面積和復(fù)雜度,D1 并不支持虛擬內(nèi)存。在通常的處理器中,程序使用的內(nèi)存地址不是直接訪問(wèn)物理內(nèi)存地址,而是由 CPU 使用操作系統(tǒng)設(shè)置的分頁(yè)結(jié)構(gòu)轉(zhuǎn)換為物理地址。
在 D1內(nèi)核中, 4 路 SMT 功能讓計(jì)算具備顯式并行性,簡(jiǎn)化 AGU 和尋址計(jì)算方式,以讓特斯拉以足夠低的延遲訪問(wèn) SRAM,其優(yōu)勢(shì)是可避免中間L1 數(shù)據(jù)緩存的延遲。
2.3 Dojo指令集

D1處理器指令集
D1參考了RISC-V 架構(gòu)的指令,并且自定義了一些指令,特別是矢量計(jì)算相關(guān)的指令。
D1指令集支持 64 位標(biāo)量指令和 64字節(jié) SIMD 指令,網(wǎng)絡(luò)傳輸與同步原語(yǔ)和機(jī)器學(xué)習(xí)/深度學(xué)習(xí)相關(guān)的專(zhuān)用原語(yǔ)(例如8x8矩陣計(jì)算)。
在網(wǎng)絡(luò)數(shù)據(jù)傳輸和同步原語(yǔ)方面,支持從本地存儲(chǔ)(SRAM)到遠(yuǎn)程存儲(chǔ)傳輸數(shù)據(jù)的指令原語(yǔ)(Primitives),以及信號(hào)量(Semaphore)和屏障約束( Barrier constraints)。這可以使D1支持多線程,其存儲(chǔ)操作指令可以在多個(gè) D1 內(nèi)核中運(yùn)行。
針對(duì)機(jī)器學(xué)習(xí)和深度學(xué)習(xí),特斯拉定義了包括 shuffle、transpose 和 convert 等數(shù)學(xué)操作的指令,以及隨機(jī)舍入( stochastic rounding ),padding相關(guān)的指令。
2.4 數(shù)據(jù)格式
D1核心具備FP32和FP16這兩個(gè)標(biāo)準(zhǔn)的計(jì)算格式,同時(shí)還具備更適合Inference的BFP16格式。為了達(dá)到混合精度計(jì)算提升性能的目的, D1還采用了用于較低精度和更高吞吐量的 8 位 CFP8 格式。
采用CFP8的優(yōu)勢(shì)在于可以節(jié)約更多的乘法器空間實(shí)現(xiàn)幾乎同樣的算力,這對(duì)提升D1的算力密度非常有幫助。
Dojo 編譯器可以在尾數(shù)精度附近滑動(dòng),以涵蓋更廣泛的范圍和精度。在任何給定時(shí)間,最多可以使用 16 種不同的矢量格式,靈活提升算力。
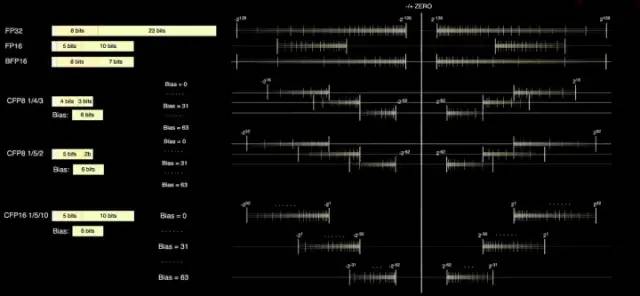
D1處理器的數(shù)據(jù)格式
根據(jù)特斯拉提供的信息,在矩陣乘法單元內(nèi)部可使用CFP8來(lái)進(jìn)行計(jì)算(存儲(chǔ)為CFP16格式)。
3,Dojo架構(gòu)處理器能否超過(guò)GPU?
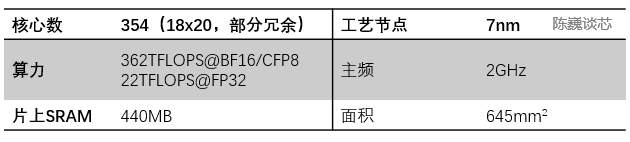
D1處理器由臺(tái)積電制造,采用7納米制造工藝,擁有500億個(gè)晶體管,芯片面積為645mm2,小于英偉達(dá)的A100(826 mm2)和AMD Arcturus(750 mm2)。
3.1 Dojo數(shù)據(jù)流近存計(jì)算架構(gòu)
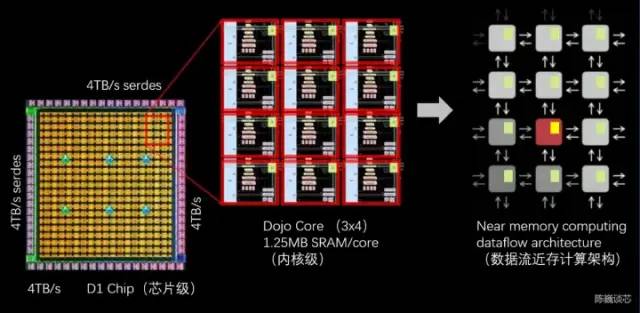
D1處理器結(jié)構(gòu)
每個(gè)D1處理器由 18 x 20 的Dojo核心拼接構(gòu)成。每個(gè)D1處理器中有354個(gè)Dojo核心可用。(之所以只使用360個(gè)核心中的354個(gè)是出于良率和每處理器核心穩(wěn)定考慮)由臺(tái)積電制造,采用7nm制造工藝,擁有500億個(gè)晶體管,芯片面積為645mm2。
每個(gè)Dojo核心有一塊1.25MB的SRAM作為主要的權(quán)重和數(shù)據(jù)存儲(chǔ)。不同的Dojo核心通過(guò)片上網(wǎng)絡(luò)路由(NoC路由)進(jìn)行連接,不同的Dojo內(nèi)核通過(guò)復(fù)雜的NoC網(wǎng)絡(luò)進(jìn)行數(shù)據(jù)同步,而不是共享數(shù)據(jù)緩存。NoC 可以處理跨節(jié)點(diǎn)邊界4個(gè)方向(東南西北)的 8 個(gè)數(shù)據(jù)包,每個(gè)方向 64 B/每個(gè)時(shí)鐘周期,即在所有四個(gè)方向上一個(gè)數(shù)據(jù)包輸入和一個(gè)數(shù)據(jù)包輸出到網(wǎng)格中每個(gè)相鄰的Dojo核心。該NoC路由還可以在每個(gè)周期對(duì)核心內(nèi)的 SRAM 進(jìn)行一次 64 B 雙向讀寫(xiě)。
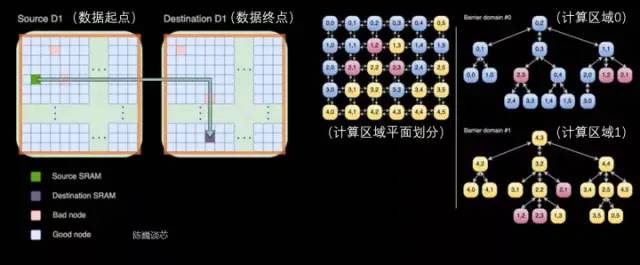
跨處理器傳輸和D1處理器內(nèi)部的任務(wù)劃分
每個(gè)Dojo核心都是一個(gè)相對(duì)完整的帶矩陣計(jì)算能力的類(lèi)CPU(由于每個(gè)核心具備單獨(dú)的矩陣計(jì)算單元,且前端相對(duì)較小,所以這里稱(chēng)為類(lèi)CPU)其數(shù)據(jù)流架構(gòu)則有點(diǎn)類(lèi)似于SambaNova的二維數(shù)據(jù)流網(wǎng)格結(jié)構(gòu),數(shù)據(jù)直接在各個(gè)處理核心之間流轉(zhuǎn),無(wú)需回到內(nèi)存。
D1芯片運(yùn)行在2GHz,擁有巨大的440MB SRAM。特斯拉將設(shè)計(jì)重心放在計(jì)算網(wǎng)格中的分布式SRAM,通過(guò)大量更快更近的片上存儲(chǔ)和片上存儲(chǔ)之間的流轉(zhuǎn)減少對(duì)內(nèi)存的訪問(wèn)頻度,來(lái)提升整個(gè)系統(tǒng)的性能,具有明顯的數(shù)據(jù)流存算一體架構(gòu)(數(shù)據(jù)流近存計(jì)算)特征。
每顆D1 芯片有 576 個(gè)雙向 SerDes 通道,分布在四周,可連接到其他 D1 芯片,單邊帶寬為 4 TB/秒。
D1處理器芯片主要參數(shù)
3.2 Dojo訓(xùn)練模組的Chiplet封裝互連技術(shù)
每個(gè)D1訓(xùn)練模塊由5x5的 D1芯片陣列排布而成,以二維Mesh結(jié)構(gòu)互連。片上跨內(nèi)核SRAM達(dá)到驚人的11GB,當(dāng)然耗電量也達(dá)到了15kW的驚人指標(biāo)。能效比為0.6TFLOPS/W@BF16/CFP8。(希望是我算錯(cuò)了,否則這個(gè)能效比確實(shí)不是太理想)。外部32GB共享HBM內(nèi)存。(HBM2e或HBM3)
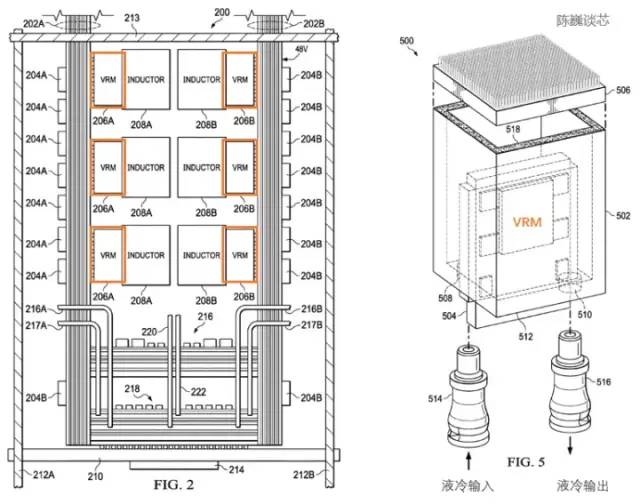
特斯拉D1處理器的散熱結(jié)構(gòu)專(zhuān)利
特斯拉使用了專(zhuān)用的電源調(diào)節(jié)模塊(VRM)和散熱結(jié)構(gòu)來(lái)進(jìn)行功耗管理。在這里功耗管理的主要目的有2個(gè):
減少不必要的功耗損失,提升能效比。
減少散熱形變?cè)斐傻奶幚砥髂=M失效。
根據(jù)特斯拉的專(zhuān)利,我們可以看到電源調(diào)節(jié)模塊與芯片本身垂直,極大的減少了對(duì)處理器平面的面積占用,且可以通過(guò)液冷來(lái)迅速平衡處理器的溫度。
特斯拉D1處理器的散熱和封裝結(jié)構(gòu)專(zhuān)利
訓(xùn)練模組在封裝上采用InFO_SoW(Silicon on Wafer)封裝來(lái)提高芯片間的互連密度。該封裝除了TSMC的INFO_SoW技術(shù)之外,也采用了特斯拉自己的機(jī)械封裝結(jié)構(gòu),以減小處理器模組的失效。
每個(gè)訓(xùn)練模塊外部邊緣的 40 個(gè) I/O 芯片達(dá)到了 36 TB/s的聚合帶寬,或者10TB/s的橫跨帶寬。每層訓(xùn)練模塊都連接著超高速存儲(chǔ)系統(tǒng):640GB 運(yùn)行內(nèi)存可以提供超過(guò) 18TB/s的帶寬,另外還有超過(guò) 1TB/s的網(wǎng)絡(luò)交換帶寬。
數(shù)據(jù)傳輸方向與芯片平面平行,供電及液冷方向與芯片平面垂直。這是一個(gè)非常優(yōu)美的結(jié)構(gòu)設(shè)計(jì),不同的訓(xùn)練模塊之間還可以互連。通過(guò)立體結(jié)構(gòu),節(jié)約了芯片模組的供電面積,盡可能減少計(jì)算芯片間的距離。
一個(gè) Dojo POD 機(jī)柜由兩層計(jì)算托盤(pán)和存儲(chǔ)系統(tǒng)組成。每一層托盤(pán)都有 6 個(gè) D1 訓(xùn)練模組。兩層共 12個(gè)訓(xùn)練模組組成的一個(gè)機(jī)柜,可提供 108PFLOPS 的深度學(xué)習(xí)算力。

Dojo模組與Dojo POD機(jī)柜
3.3 電源管理與散熱控制
超算平臺(tái)的散熱,一直是衡量超算系統(tǒng)水平的重要維度。
D1 芯片的熱設(shè)計(jì)功率(TDP) 為 400 W。將 25 顆 D1 芯片緊密封裝成為一個(gè)訓(xùn)練模組,僅處理器TDP就可能高達(dá) 10 kW。在如此之高密度的計(jì)算芯片矩陣環(huán)境下,綜合考慮散熱和電力傳輸,特斯拉需要為D1芯片提供全新的方案。
特斯拉在 Dojo POD 上使用了全自研的 VRM(電壓調(diào)節(jié)模組),單個(gè) VRM可以在不足 25 美分硬幣面積的電路上,提供52V電壓和超過(guò) 1000A 的巨大電流,電流目的為0.86A每平方毫米,共計(jì)12個(gè)獨(dú)立供電相位。
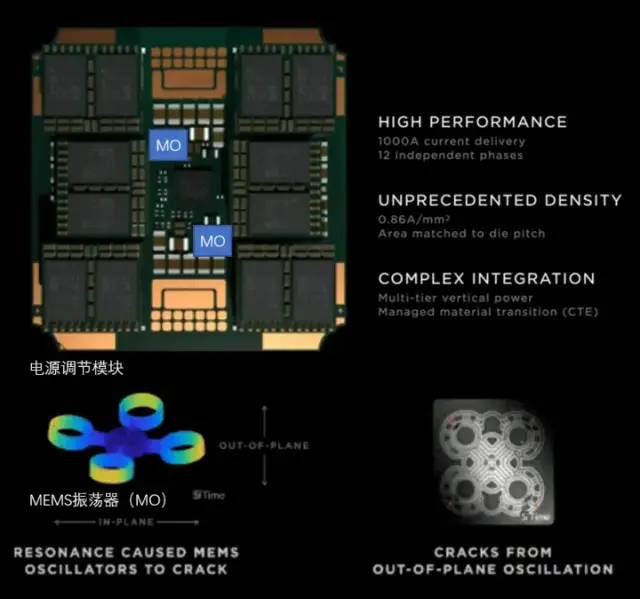
特斯拉的電源調(diào)節(jié)模組
對(duì)高密度芯片散熱而言,其重點(diǎn)是控制熱膨脹系數(shù)(CTE)。Dojo系統(tǒng)的芯片密度極高,如果CTE稍微失控,都可能導(dǎo)致結(jié)構(gòu)變形/失效,進(jìn)而出現(xiàn)連接故障。
特斯拉這套自研 VRM 在過(guò)去2年內(nèi)迭代了 14 個(gè)版本,采用了MEMS振蕩器(MO)來(lái)感知電源調(diào)節(jié)模組的熱形變,最終才完全符合內(nèi)部對(duì) CTE 指標(biāo)的要求。這種通過(guò)MEMS技術(shù)主動(dòng)調(diào)節(jié)電源功率的方式,與控制火箭箭身振動(dòng)的主動(dòng)調(diào)節(jié)方式類(lèi)似。
3.4 Dojo架構(gòu)處理器的編譯生態(tài)
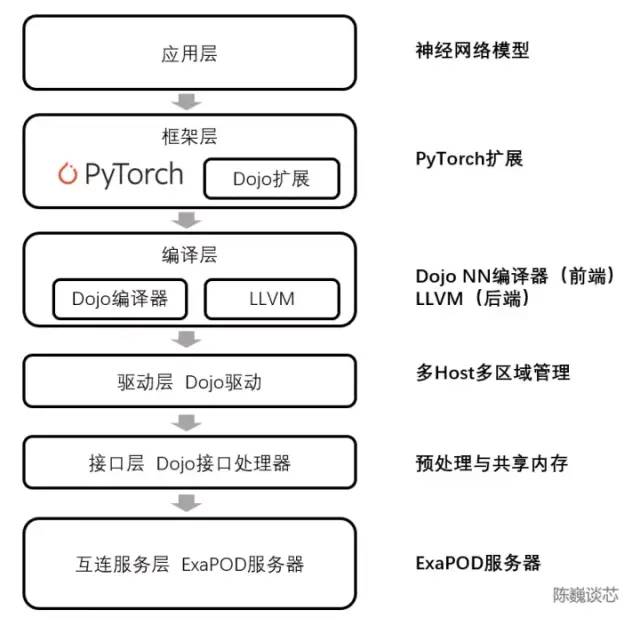
D1處理器軟件棧
對(duì)于D1這類(lèi)AI芯片來(lái)說(shuō),編譯生態(tài)的重要性不低于芯片本身。
在D1處理器平面上,D1被劃分為矩陣式的計(jì)算單元。編譯工具鏈負(fù)責(zé)任務(wù)的劃分和配置數(shù)據(jù)存儲(chǔ),并且通過(guò)多種方式進(jìn)行細(xì)粒度的并行計(jì)算,并減少存儲(chǔ)占用。
Dojo編譯器支持的并行方式包括數(shù)據(jù)并行、模型并行和圖并行。支持的存儲(chǔ)分配方式包括分布式張量、重算分配和分割填充。
編譯器本身可以處理各種CPU中常用的動(dòng)態(tài)控制流,包括循環(huán)和圖優(yōu)化算法。借助Dojo編譯器,用戶(hù)可將Dojo大型分布式系統(tǒng)視作一個(gè)加速器進(jìn)行整體設(shè)計(jì)和訓(xùn)練。
整個(gè)軟件生態(tài)的頂層基于PyTorch,底層基于Dojo驅(qū)動(dòng),中間使用Dojo編譯器和LLVM形成編譯層。這里加入LLVM后,可以使特斯拉更好的利用LLVM上已有的各種編譯生態(tài)進(jìn)行編譯優(yōu)化。
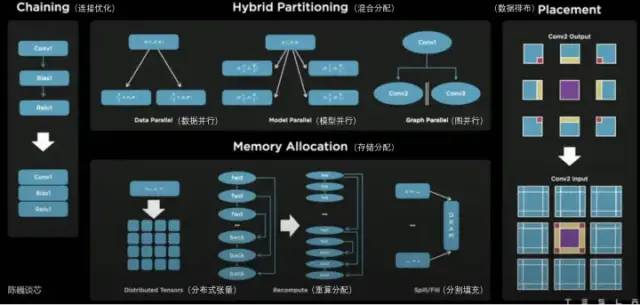
特斯拉Dojo 編譯器
4,結(jié)語(yǔ)
通過(guò)特斯拉AI日,我們看到了特斯拉機(jī)器人的真身,并且對(duì)其強(qiáng)大的“內(nèi)芯”有了更多的認(rèn)識(shí)。
特斯拉的Dojo核心與以往的CPU和GPU架構(gòu)特點(diǎn)都有差別,可以說(shuō)是結(jié)合了CPU特點(diǎn)的精簡(jiǎn)GPU,相信其在編譯上也會(huì)與CPU和GPU有較大的差異。為了提升計(jì)算密度,特斯拉做了極致精簡(jiǎn)的優(yōu)化,并且提供了主動(dòng)調(diào)節(jié)的電源管理機(jī)制。
特斯拉Dojo架構(gòu)不止名為道場(chǎng),其設(shè)計(jì)也確實(shí)以簡(jiǎn)為道,以少為多。那這種架構(gòu)會(huì)不會(huì)成為繼CPU和GPU之后的另一算力芯片架構(gòu)典型形態(tài)呢?讓我們拭目以待。
審核編輯 :李倩
-
機(jī)器人
+關(guān)注
關(guān)注
211文章
28420瀏覽量
207111 -
特斯拉
+關(guān)注
關(guān)注
66文章
6313瀏覽量
126568
原文標(biāo)題:全面分析特斯拉機(jī)器人“超算”芯片(超越GPGPU?)
文章出處:【微信號(hào):AI_Architect,微信公眾號(hào):智能計(jì)算芯世界】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論