 二進制通信協議序列化介紹
二進制通信協議序列化介紹
通信協議可以理解兩個節點之間為了協同工作實現信息交換,協商一定的規則和約定,例如規定字節序,各個字段類型,使用什么壓縮算法或加密算法等。常見的有tcp,udp,http,sip等常見協議。協議有流程規范和編碼規范。流程如呼叫流程等信令流程,編碼規范規定所有信令和數據如何打包/解包。
編碼規范就是我們通常所說的編解碼,序列化。不光是用在通信工作上,在存儲工作上我們也經常用到。如我們經常想把內存中對象存放到磁盤上,就需要對對象進行數據序列化工作。
本文采用先循序漸進,先舉一個例子,然后不斷提出問題-解決完善,這樣一個迭代進化的方式,介紹一個協議逐步進化和完善,最后總結。看完之后,大家以后在工作就很容易制定和選擇自己的編碼協議。
緊湊模式
本文例子是A和B通信,獲取或設置基本資料,一般開發人員第一步就是定義一個協議結構:
struct userbase
{
//1-get, 2-set, 定義一個short,為了擴展更多命令
unsigned short cmd;
//1 – man , 2-woman
unsigned char gender;
//當然這里可以定義為 string name;或len + value 組合,
為了敘述方便,就使用簡單定長數據
char name[8];
}
在這種方式下,A基本不用編碼,直接從內存copy出來,再把cmd做一下網絡字節序變換,發送給B。B也能解析,一切都很和諧愉快。
這時候編碼結果可以用圖表示為(1格一個字節)

這種編碼方式,我稱之為緊湊模式,意思是除了數據本身外,沒有一點額外冗余信息,可以看成是Raw Data。在dos年代,這種使用方式非常普遍,那時候可是內存和網絡都是按K計算,cpu還沒有到1G。如果添加額外信息,不光耗費捉襟見肘的cpu,連內存和帶寬都傷不起。
可擴展性
有一天,A在基本資料里面加一個生日字段,然后告訴B
struct userbase
{
unsigned short cmd;
unsigned char gender;
unsigned int birthday;
char name[8];
}
這是B就犯愁了,收到A的數據包,不知道第3個字段到底是舊協議中的name字段,還是新協議中birthday。這是后A,和B終于從教訓中認識到一個協議重要特性——兼容性和可擴展性。
于是乎,A和B決定廢掉舊的協議,從新開始,制定一個以后每個版本兼容的協議。方法很簡單,就是加一個version字段。
struct userbase
{
unsigned short version;
unsigned short cmd;
unsigned char gender;
unsigned int birthday;
char name[8];
}
這樣,A和B就松一口氣,以后就可以很方便的擴展。增加字段也很方便。這種方法即使在現在,應該還有不少人使用。
更好的擴展性
過了一段較長時間,A和B發現又有新的問題,就是每增加一個字段就改變一下版本號,這還不是重點,重點是這樣代碼維護起來相當麻煩,每個版本一個case分支,到了最好,代碼里面case 幾十個分支,看起來丑陋而且維護起來成本高。
A 和 B仔細思考了一下,覺得光靠一個version維護整個協議,不夠細,于是覺得為每個字段增加一個額外信息——tag,雖然增加內存和帶寬,但是現在已經不像當年那樣,可以容許這些冗余,換取易用性。
struct userbase
{
unsigned short version;
unsigned short cmd;
unsigned char gender;
unsigned int birthday;
char name[8];
}

制定完這些協議后,A和B很得意,覺得這個協議不錯,可以自由的增加和減少字段。隨便擴展。
現實總是很殘酷的,不久就有新的需求,name使用8個字節不夠,最大長度可能會達到100個字節,A和B就愁懷了,總不能即使叫“steven”的人,每次都按照100個字節打包,雖然不差錢,也不能這樣浪費。
于是A和B尋找各方資料,找到了ANS.1編碼規范,好東西啊.. ASN.1是一種ISO/ITU-T 標準。其中一種編碼BER(Basic Encoding Rules)簡單好用,它使用三元組編碼,簡稱TLV編碼。
每個字段編碼后內存組織如下

字段可以是結構,即可以嵌套

A和B使用TLV打包協議后,數據內存組織大概如下:

TLV具備了很好可擴展性,很簡單易學。同時也具備了缺點,因為其增加了2個額外的冗余信息,tag 和len,特別是如果協議大部分是基本數據類型int ,short, byte. 會浪費幾倍存儲空間。另外Value具體是什么含義,需要通信雙方事先得到描述文檔,即TLV不具備結構化和自解釋特性。
自解釋性
當A和B采用TLV協議后,似乎問題都解決了。但是還是覺得不是很完美,決定增加自解釋特性,這樣抓包就能知道各個字段類型,不用看協議描述文檔。這種改進的類型就是 TT[L]V(tag,type,length,value),其中L在type是定長的基本數據類型如int,short, long, byte時候,因為其長度是已知的,所以L不需要。
于是定義了一些type值如下
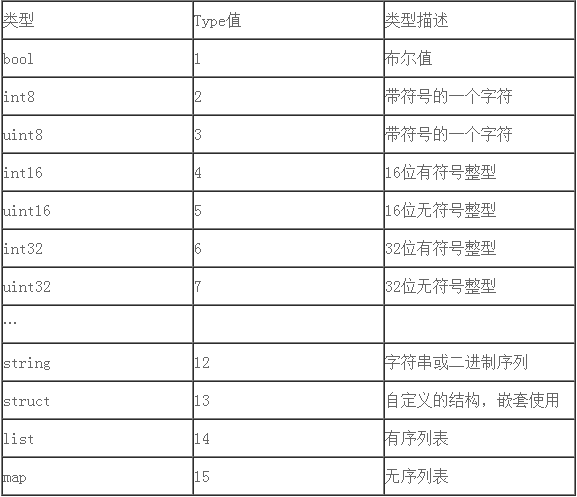
按照ttlv序列化后,內存組織如下
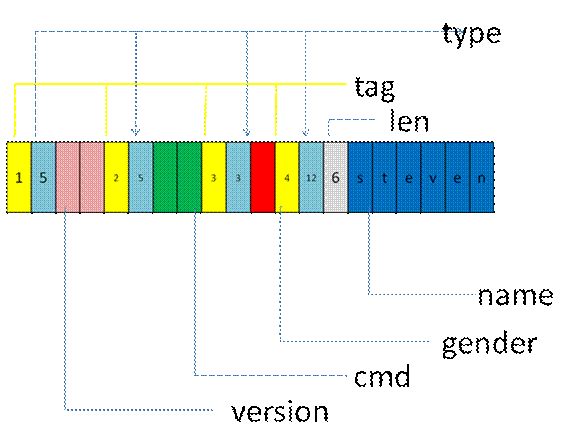
改完后,A和B發現,的確帶來很多好處,不光可以隨心所以的增刪字段,還可以修改數據類型,例如把cmd改成int cmd;可以無縫兼容。真是太給力了。
跨語言特性
有一天來了一個新的同事C,他寫一個新的服務,需要和A通信,但是C是用java或PHP的語言,沒有無符號類型,導致負數解析失敗。為了解決這個問題,A重新規劃一下協議類型,做了有些剝離語言特性,定義一些共性。對使用類型做了強制性約束。雖然帶來了約束,但是帶來通用型和簡潔性,和跨語言性,大家表示都很贊同,于是有了一個類型(type)規范。
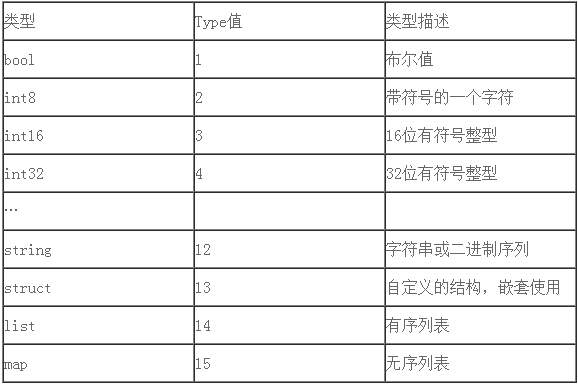
代碼自動化
但是A和B發現了新的煩惱,就是每搞一套新的協議,都要從頭編解碼,調試,雖然TLV很簡單,但是寫編解碼是一個毫無技術含量的枯燥體力活,一個非常明顯的問題是,由于大量copy/past,不管是對新手還是老手,非常容易犯錯,一犯錯,定位排錯非常耗時。于是A想到使用工具自動生成代碼。
IDL(Interface Description Language),它是一種描述語言,也是一個中間語言,IDL一個使命就是規范和約束,就像前面提到,規范使用類型,提供跨語言特性。通過工具分析idl文件,生成各種語言代碼
Gencpp.exe sample.idl 輸出 sample.cpp sample.h
Genphp.exe sample.idl 輸出 sample.php
Genjava.exe sample.idl 輸出 sample.java
是不是簡單高效。
總結
大家看到這里,是不是覺得很面熟。是的,協議講到最后,其實就是和facebook的thrift和google protocol buffer協議大同小異了。包括公司無線使用的jce協議。咋一看這些協議的idl文件,發現幾乎是一樣的。只是有些細小差異化。
這些協議在一些細節上增加了一些特性:
1、 壓縮,這里壓縮不是指gzip之類通用壓縮,是指針對整數壓縮,如int類型,很多情況下值是小于127(值為0的情況特別多),就不需要占用4個字節,所以這些協議做了一些細化處理,把int類型按照情況,只使用1/2/3/4字節,實際上還是一種ttlv協議。
2、 reuire/option 特性: 這個特性有兩個作用,1、還是壓縮,有時候一個協議很多字段,有些字段可以帶上也可以不帶上,不賦值的時候不是也要帶一個缺省值打包,這樣很浪費,如果字段是option特性,沒有賦值的話,就不用打包。2、有點邏輯上約束功能,規定哪些字段必須有,加強校驗。
序列化是通信協議的基礎,不管是信令通道還是數據通道,還是rpc,都需要使用到。在設計協議早期就考慮到擴展性和跨語言特性。會為以后省去不少麻煩。
-
通信協議
+關注
關注
28文章
883瀏覽量
40311 -
二進制
+關注
關注
2文章
795瀏覽量
41653 -
TCP
+關注
關注
8文章
1353瀏覽量
79077 -
UDP
+關注
關注
0文章
325瀏覽量
33941
發布評論請先 登錄
相關推薦

什么是二進制計數器,二進制計數器原理是什么?
二進制電平,什么是二進制電平
LabVIEW二進制數組轉換二進制字符串的詳細資料免費下載
一種面向私有二進制協議的報文聚類方法
一種全新的未知二進制協議格式推斷方法
一種全新的未知二進制協議格式推斷方法
什么是序列化 為什么要序列化






 工商網監
工商網監
評論