 Web的應用基礎
Web的應用基礎
一.Web概況
20世紀80年代,使用互聯網的人還是少數,“如何讓這部分人共享資料”成為課題。最初的想法是設計“超文本(HyperText)”,來相互關聯不同的文檔,進而連成可相互訪問并閱讀的Web。Web是由數以億計的客戶和服務器組成,這些客戶和服務器通過網絡連接,客戶可以是人或者瀏覽器,而服務器可以理解為物理服務器(安裝了Web服務器軟件)。如下圖所示:
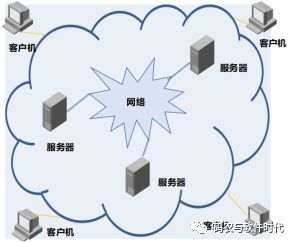
Web(World Wide Web,萬維網)是一種基于超文本和HTTP的、全球性的、動態交互的、跨平臺的分布式圖形信息系統。Web的發展已從1.0發展到3.0:
| Web歷程 | 特點 | 中心 | 代表 |
|---|---|---|---|
| Web1.0 | 門戶網站提供內容、引導用戶訪問感興趣的網站 | 信息 | 新浪、搜狐和網易 |
| Web2.0 | 用戶自已提供、擁有和享用各種服務和內容 | 人 | 淘寶、微博、微信 |
| Web3.0 | 機器、網絡與人的交互,智能化服務 | 機器 | 小蜜、百度小度 |
不論Web是1.0還是2.0還是3.0,其本質就是一個網站。但用戶的體驗卻發生了質的變化。Web1.0時代,用戶的身份是信息的消費者,是信息的被動接收者,到了Web2.0時代,用戶既是信息的消費者,也是生產者,關注的重點在“人”。再到Web3.0時代,機器能夠理解用戶的意圖,并推薦個性化的服務方案。如用戶輸入“周末怎么玩”,機器將結合你的位置、時間以及平時的興趣愛好,推薦一系列的景點、餐館、出行方式等等,一站式解決問題。
二、Web流程
1.基礎鏈路
現在上網已經是人們生活中的一部分,大家習慣于去點鏈接查信息,對于Web本身是如何運轉的,很少去思考。但作為新時代的碼農或者Web應用的開發人員,我們需要清楚在用戶點鏈接之后究竟發生了什么,分別用到了什么技術。
在互聯網發展的今天,一個Web應用不但要滿足海量用戶的高并發請求,而且還要快速響應用戶的請求。所以一個典型的Web應用基礎鏈接為:

當一個用戶在瀏覽器輸入URL地址后,瀏覽器將:
①請求DNS服務器,將域名解析成對應的IP地址;
②根據IP地址,發起網絡資源請求,靜態資源從CDN中獲取,如果CDN
沒有對應資源,將向源服務器拉取資源;
③如果對外提供服務的服務器有多個,則根據負載均衡進行資源的獲取;
④服務器接收請求,并做邏輯處理響應請求,返回請求資源;
⑤客戶端接收數據并進行渲染展示。
2.數據流
下面我們從數據在“客戶端-網絡--服務端”的流向做下簡單的說明。在我們學習計算機網絡時,被灌輸的知識是網絡設備之間的通信都采用TCP\\IP協議,并在邏輯上劃分了四層:應用層、傳輸層、網絡層、數據鏈路層。在每層上,客戶端和服務端進行對等通信。在用戶瀏覽網頁并點擊鏈接時,生成HTTP數據從應用層向下傳輸,經過層層封裝,從網卡上將數據發送到網絡上,在服務端又經過層層解封裝,還原HTTP數據,如下圖所示:

TCP\\IP模型在邏輯上的分層,每層都有對應的職責,這些職責又如何落實到具體的系統實現中呢?客戶端,操作系統提供了TCP\\IP協議除應用層的大部分實現,并向上提供Socket接口供瀏覽器調用。服務端,操作系統同樣提供了大部分功能,中間件實現了Socket和HTTP協議的轉換,使用Web應用程序本身專注于處理HTTP數據。如下圖所示:

三. Web應用
Web應用建立在HTTP協議基礎之上的,我們對于底層的數據流向和解封裝可以不用過多關注,而將重心放在HTTP請求與響應的日常任務和業務邏輯處理上。
①如何將HTTP協議公開給編程語言?
②如何實現請求參數到編程語言的數據綁定?
③如何驗證數據?
④如何組織業務邏輯?
⑤如何實現編程語言對象到數據庫數據的轉換?
下圖是一個回答上述問題的簡單示例。

-
Web
+關注
關注
2文章
1263瀏覽量
69460 -
HTTP
+關注
關注
0文章
505瀏覽量
31222 -
信息系統
+關注
關注
0文章
205瀏覽量
20445
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論