 在FPGA上實現深度學習
在FPGA上實現深度學習
在上一篇文章中,談到了深度學習是什么以及在 FPGA 上進行深度學習的好處。在本課程的后續文章中,我們將開始開發針對 FPGA 的深度學習設計。特別是,在本文中,我們將首先在 Python 上運行訓練代碼,并創建一個網絡模型方便在后續 FPGA 上運行。
在后續文章中,我們將根據實際源碼進行講解。稍后將提供包括 FPGA 設計在內的所有代碼。
要使用的數據集工具
MNIST 數據庫
本課程針對的問題是通常稱為圖像分類的任務。在這個任務中,我們輸出一個代表輸入圖像的標簽。這里的標簽例如是圖像中物體的通用名稱。
MNIST 數據庫是一個包含 0 到 9 的手寫數字的數據集,并為每個手寫數字定義了正確的標簽 (0-9)。由于輸入是一張28x28的灰度圖,輸出最多10個類,在圖像分類任務中屬于非常初級的任務。除了 MNIST 之外,主要的圖像分類數據集包括CIFAR10和ImageNet,并且往往會按上訴列出的順序成為更難的問題。
MNIST 在許多深度學習教程中都有使用,因為它是一個非常簡單的數據集。由于本課程的主要目的是在 FPGA 上實現深度學習,因此我們將創建一個針對 MNIST 的學習模型。

MNIST 數據庫——維基百科
PyTorch
PyTorch是來自 Facebook 的開源深度學習框架,也是與來自 Google 的TensorFlow一起使用最頻繁的框架之一。在本文中,我們將在 PyTorch 上學習和創建網絡模型。
PyTorch安裝參考官網步驟。我使用的 Ubuntu 16.04 LTS 上安裝的 Python 3.5 不支持最新的 PyTorch,所以我使用以下命令安裝了舊版本。
pipinstalltorch==1.4.0torchvision==0.5.0
由于本文的重點不在于如何使用PyTorch,所以我將省略代碼的解釋,尤其是學習部分。如果有興趣,建議嘗試下面的官方教程,盡管它是英文的。
卷積神經網絡
卷積神經網絡 (CNN) 是一種旨在在圖像任務中表現出色的神經網絡。本文創建的網絡模型是一個卷積神經網絡,該網絡由以下三層和激活函數的組合組成。
全連接層
卷積層
池化層
激活函數
下面概述了每一層的處理和作用。
全連接層
全連接層是通過將輸入向量乘以內部參數矩陣來輸出向量的過程。如果只說神經網絡沒有前言比如卷積,往往指的就是這個全連接層。
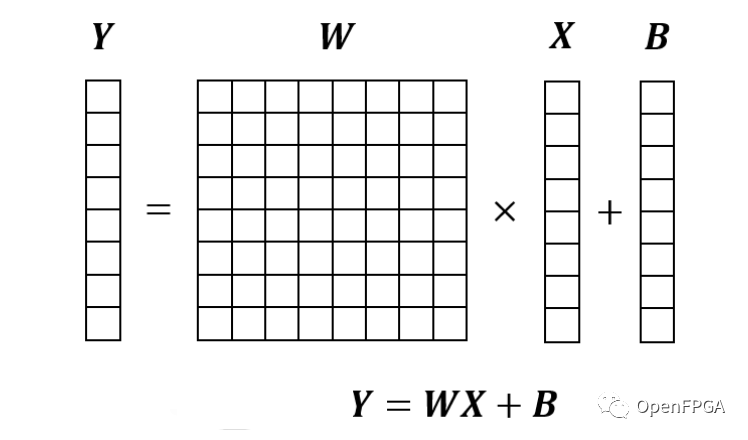
由于全連接層的輸入是向量,所以無法得到圖像中應該注意的與周圍像素點的關系。在卷積神經網絡中,全連接層主要用于將卷積層和池化層創建的壓縮圖像信息(特征)轉換為標簽數據(0-9)。
卷積層
卷積層是對圖像進行卷積處理的層。如果熟悉圖像處理,可能會稱其為濾鏡處理。
在卷積層中,對于輸入圖像中的每個像素,獲取周圍像素的像素值,每個像素值乘以一個數組(kernel),它是一個內參,求和就是像素值輸出圖像。這以圖形方式表示,如下所示。
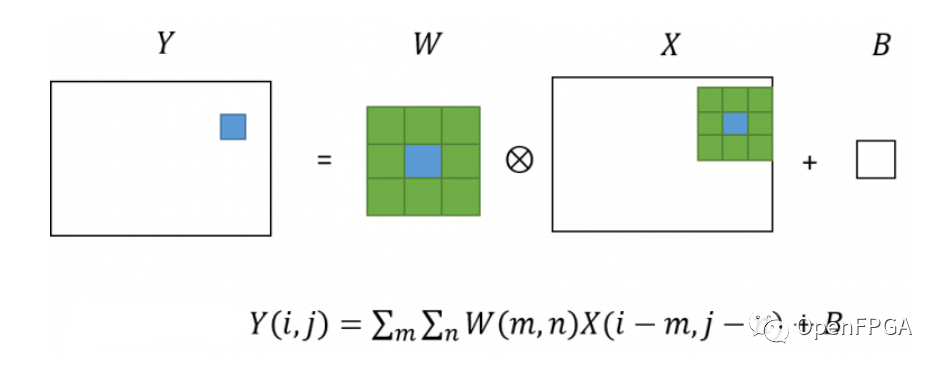
卷積神經網絡的許多層都是由這個卷積層組成的,因為它以這種方式針對圖像處理。
池化層
池化層是用于壓縮由卷積層獲得的信息的層。使用本次使用的參數,通過取圖像中2x2塊的最大值將圖像大小減半。下圖顯示了最大值的減少處理。
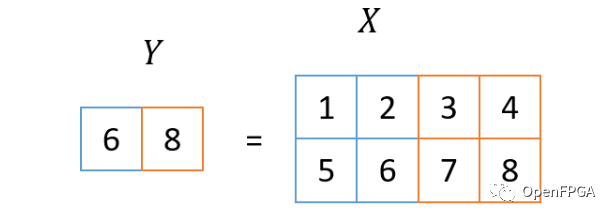
通過應用多個池化層,聚合圖像每個部分的信息,并接近表示最終圖像整體的標簽信息。
激活函數
激活函數是一個非線性函數,插入在卷積層和全連接層之后。這是為了避免將實際上是線性函數的兩層合并為一層。已經提出了各種類型的激活函數,但近年來 ReLU 是主要使用的激活函數。
ReLU 是 Rectified Linear Unit 的縮寫。該函數會將小于0的輸入值置為0,大于0的值原樣輸出。
創建網絡模型
使用的網絡模型是著名網絡模型LeNet的簡化版。LeNet 是早期的卷積神經網絡之一,和這個一樣,都是針對手寫識別的。
本文使用的模型定義如下。與原來的LeNet相比,有一些不同之處,例如卷積層的核大小減小,激活函數為ReLU。
classNet(nn.Module): def__init__(self,num_output_classes=10): super(Net,self).__init__() self.conv1=nn.Conv2d(in_channels=1,out_channels=4,kernel_size=3,padding=1) #激活函數ReLU self.relu1=nn.ReLU(inplace=True) # self.pool1=nn.MaxPool2d(kernel_size=2,stride=2) #4ch->8ch,14x14->7x7 self.conv2=nn.Conv2d(in_channels=4,out_channels=8,kernel_size=3,padding=1) self.relu2=nn.ReLU(inplace=True) self.pool2=nn.MaxPool2d(kernel_size=2,stride=2) #全連接層 self.fc1=nn.Linear(8*7*7,32) self.relu3=nn.ReLU(inplace=True) #全連接層 self.fc2=nn.Linear(32,num_output_classes) defforward(self,x): #激活函數ReLU x=self.conv1(x) x=self.relu1(x) #縮小 x=self.pool1(x) #2層+縮小 x=self.conv2(x) x=self.relu2(x) x=self.pool2(x) #(Batch,Ch,Height,Width)->(Batch,Ch) x=x.view(x.shape[0],-1) #全連接層 x=self.fc1(x) x=self.relu3(x) x=self.fc2(x) returnx
使用netron可視化此模型的數據流如下所示:

按照數據的順序流動,首先輸入一張手寫圖像(28×28, 1ch),在第一個Conv2d層轉換為(28×28, 4ch)的圖像,通過ReLU變成非負的。
然后通過 Maxpool2d 層將該圖像縮小為 (14×14, 4ch) 圖像。隨后的 Conv2d、ReLU、MaxPool2d 遵循幾乎相同的程序,生成 (7×7, 8ch) 圖像。將此圖像視為7x7x8 = 392度的向量,應用兩次全連接層最終將輸出10度的向量。此 10 階向量中具有最大值的元素的索引 (argmax) 是推斷字符 (0-9)。
學習/推理
使用上述模型訓練 MNIST。這里需要執行三個步驟:
加載訓練/測試數據
循環學習
測試(推理)
首先,讀取數據。PyTorch 帶有一個預定義的 MNIST 加載器,我們用它來加載數據(訓練集/測試集)。trainloader/testloader 是定義如何讀取每個數據集中數據的對象。
importtorch importtorchvision importtorchvision.transformsastransforms #2.定義數據集讀取方法 #獲取MNIST的學習測試數據 trainset=torchvision.datasets.MNIST(root='./data',train=True,download=True,transform=transforms.ToTensor()) testset=torchvision.datasets.MNIST(root='./data',train=False,download=True,transform=transforms.ToTensor()) #數據讀取方法的定義 #1步驟的每個學習測試讀取16張圖像 trainloader=torch.utils.data.DataLoader(trainset,batch_size=16,shuffle=True) testloader=torch.utils.data.DataLoader(testset,batch_size=16,shuffle=False)
現在數據讀取已經完成,是時候開始學習了。首先,我們定義損失函數(誤差函數)和優化器。在后續的學習中,我們會朝著損失值減小的方向學習。
#損失函數,最優化器的定義 loss_func=nn.CrossEntropyLoss() optimizer=torch.optim.Adam(net.parameters(),lr=0.0001)
學習循環像這樣:從trainloader讀取輸入數據(inputs),糾正標簽(labels),通過網絡得到輸出(outputs),得到帶有正確標簽的error(loss)。
然后我們使用一種稱為誤差反向傳播 (loss.backward()) 的技術來計算每一層的學習方向(梯度)。優化器使用獲得的梯度來優化模型(optimizer.step())。這是一步學習流程,在此代碼中,重復學習直到夠 10 個數據集。
由于我們將使用 FPGA 進行推理處理,因此即使不了解此處描述的學習過程也沒有問題。如果你對我們為什么這樣學習感興趣,請參考上一篇文章中一些通俗易懂的文獻。
#循環直到使用數據集中的所有圖像10次
forepochinrange(10):
running_loss=0
#在數據集中循環
fori,datainenumerate(trainloader,0):
#導入輸入批(圖像,正確標簽)
inputs,labels=data
#零初始化優化程序
optimizer.zero_grad()
#通過模型獲取輸入圖像的輸出標簽
outputs=net(inputs)
#與正確答案的誤差計算+誤差反向傳播
loss=loss_func(outputs,labels)
loss.backward()
#使用誤差優化模型
optimizer.step()
running_loss+=loss.item()
ifi%1000==999:
print('[%d,%5d]loss:%.3f'%
(epoch+1,i+1,running_loss/1000))
running_loss=0.0
測試代碼如下所示:該測試與學習循環幾乎相同,但省略了學習的損失計算。scikit-learn我們還使用這里的函數來accuracy_score, confusion_matrix輸出準確度和混淆矩陣。
fromsklearn.metricsimportaccuracy_score,confusion_matrix #4.測試 ans=[] pred=[] fori,datainenumerate(testloader,0): inputs,labels=data outputs=net(inputs) ans+=labels.tolist() pred+=torch.argmax(outputs,1).tolist() print('accuracy:',accuracy_score(ans,pred)) print('confusionmatrix:') print(confusion_matrix(ans,pred))
通過到目前為止的實施,可以在 PyTorch 上訓練和推斷 MNIST。當我在 i7 CPU 上實際運行上述代碼時,該過程在大約 3 分鐘內完成。日志在下面。
[n, m] loss: X這條線表示第n個epoch(使用數據集的次數)和學習數據集中第m個數據時的損失(錯誤)。可以看出,隨著學習的進行,損失幾乎接近于 0。即使是這種非常小的網絡模型也可以成功學習。
測試準確率最終顯示出足夠高的準確率,達到 97.26%。接下來的矩陣是混淆矩陣(confusion_matrix),其中第i行第j列的值代表正確答案i和推理結果j。這次數據的準確性足夠了,結果似乎沒有什么明顯的偏差。這一次,我們一次性得到了足夠的準確率,但是我們在原來的開發中并沒有得到我們想要的準確率,所以我們在這里回顧一下模型和學習方法。
[1,1000]loss:1.765 [1,2000]loss:0.655 [1,3000]loss:0.475 ... [10,1000]loss:0.106 [10,2000]loss:0.101 [10,3000]loss:0.104 accuracy:0.9726 confusionmatrix: [[973010020220] [0112821002020] [3399780127101] [10696801205108] [1030960012213] [310508702074] [1021178927020] [1390100100617] [51112433892710] [56031010104970]]
最后,使用以下代碼保存模型。前者是從 PyTorch 重新評估的模型文件,后者用于在 PyTorch 的 C++ API(libtorch)上讀取網絡模型。
#5.保存模型
#用于從PyTorch正常讀取的模型文件
torch.save(net.state_dict(),'model.pt')
#保存用于從libtorch(C++API)讀取的TorchScriptModule
example=torch.rand(1,1,28,28)
traced_script_module=torch.jit.trace(net,example)
traced_script_module.save('traced_model.pt')
總結
在本文中,我們使用 MNIST 數據集作為學習目標來創建、訓練和推斷網絡模型。
使用基于 LeNet 的輕量級網絡模型,我們能夠在 MNIST 數據集上實現良好的準確性。在下一篇和后續文章中,我們的目標是在 FPGA 上運行該模型,并在考慮高級綜合(HLS)的情況下開始 C++ 實現。
審核編輯:劉清
-
FPGA
+關注
關注
1630文章
21769瀏覽量
604646 -
數據庫
+關注
關注
7文章
3839瀏覽量
64543 -
python
+關注
關注
56文章
4801瀏覽量
84859 -
Ubuntu系統
+關注
關注
0文章
91瀏覽量
3998 -
MNIST
+關注
關注
0文章
10瀏覽量
3386
原文標題:從FPGA說起的深度學習(二)
文章出處:【微信號:Open_FPGA,微信公眾號:OpenFPGA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論