 Google二進制編解碼技術之Protobuf 3
Google二進制編解碼技術之Protobuf 3
字段名稱與字段類型
對于任何一個有用的信息都包含這樣幾部分:
- 字段名稱
- 字段類型
- 字段值
就像C/C++中定義變量時:
int i = 100;
在這里,字段名稱就是i,字段類型是int,字段值是100。
剛才我們用varint以及ZigZag編碼解決了字段值表示的問題,那么該怎樣表示字段名稱和字段類型呢?
首先,對于字段類型還比較簡單,因為字段類型就那么多,protobuf中定義了6種字段類型:
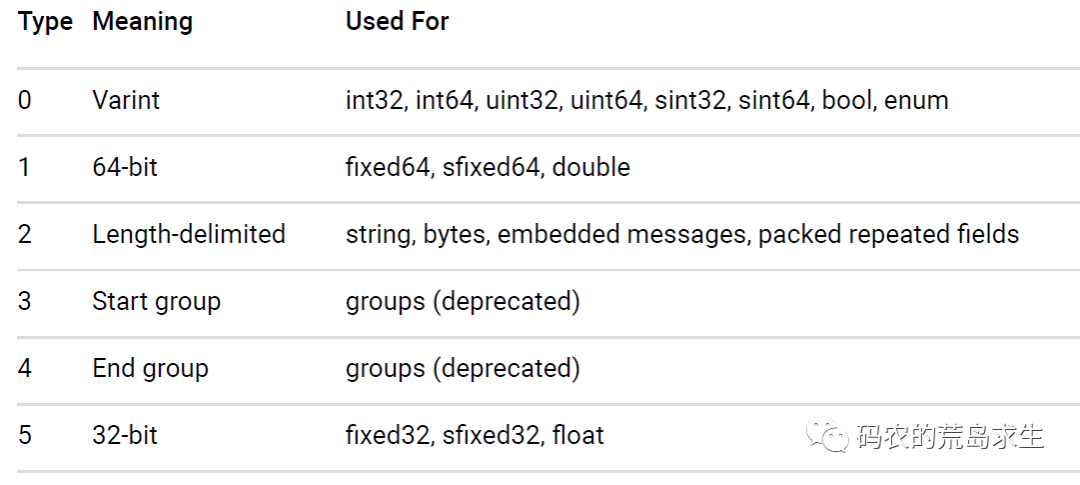
對于6種字段類型我們使用3個比特位來表示就足夠了。
接下來比較有趣的是字段名稱該怎么表示呢?假設我們需要傳遞這樣一個字段:
int long_long_name = 100;
那么我們真的需要把“long_long_name”這么多字符通過網絡傳遞給對端嗎?
既然通信雙方需要協議,那么“long_long_name”這字段其實是client和server都知道的,它們唯一不知道的就是“ 哪些值屬于哪些字段 ”。
為解決這個問題, 我們給每個字段都進行編號 ,比如通信雙方都知道“long_long_name”這個字段的編號是2,那么對于:
int long_long_name = 100;
這個信息我們只需要傳遞:
- 字段名稱:2 (2對應字段“long_long_name”)
- 字段類型:0 (0表示varint類型,參見上圖)
- 字段值:100
所以我們可以看到, 無論你用多么復雜的字段名稱也不會影響編碼后占據的空間,字段名稱根本就不會出現在編碼后的信息中, so clever。
從宏觀上看
我們已經在protobuf中看到了數字以及字段名稱以及字段類型是怎么表示了,現在是時候從宏觀角度來看看多個字段該怎么編碼了。
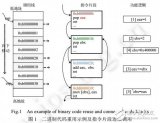
從本質上講,protobuf被編碼后形成一系列的key-value,每個key-value對應一個proto中的字段。
也就是鍵值對:

其中value比較簡單,也就是字段值;而字段名稱和字段類型會被拼接成key,protobuf中共有6種類型,因此只需要3個比特位即可;字段名稱只需要存儲對應的編號,這樣可以就可以這樣編碼:
(字段編號 << 3) | 字段類型
假設server接收到了一個key為0x08,其二進制的表示為:
0000 1000
由于key也是利用varint編碼的,因此需要將第一個比特位去掉,這樣我的得到:
000 1000
根據key的編碼方式,其后三個比特位表示字段類型,即:
000
也就是0,這樣我們知道該key的類型是Varint(第0號類型),而字段編號為抹掉后3個比特位的值,即:
0001
這樣,我們就知道了該key對應的字段編號為1,得到編號我們就能根據編號找到對應的編號名稱。
嵌套數據
與Json和XML類似,protobuf中也支持嵌套消息,就像這樣:
message SubMsg {
optional int32 id = 1;
}
message Msg {
optional SubMsg msg = 1;
}
其實現也比較簡單,這依然遵循被編碼后形成一系列的key-value,只不過對于嵌套類型的key來說,其value是由子消息的key-value組成。

protobuf與編譯語言
與Json一樣,protobuf也是一門語言,兼具了文本的可讀性以及二進制的高效。
protobuf之所以能做到這一點就好比C語言與機器指令。
C語言是給程序員看的,可讀性好,而機器指令是給硬件使用的,性能好,編譯器會將C語言程序轉為機器可執行的機器指令。
而protobuf也一樣,protobuf也是一門語言,會將可讀性較好的消息編碼為二進制從而可以在網絡中進行傳播,而對端也可以將其解碼回來。
在這里protobuf中定義的消息就好比C語言,編碼后的二進制消息就好比機器指令。
而protobuf作為事實上語言必然有自己的語法,其語法就是這樣:

怎么樣,還覺得編譯原理沒什么用嗎?
不理解編譯原理是不可能發明protobuf這種技術的。
總結
我在寫這篇文章時不斷感嘆,Google的這項技術節省了多少程序員的時間,同時我們也能看到這種基石般的技術依賴的底層原理卻非常古老:
- 信息的編解碼
- 編譯原理
怎么樣,這些是不是遠遠沒有IT界各種流行的技術聽上去時髦有趣,而正是這種樸素的技術支撐起了工業界,現在你也應該能明白底層技術的重要性了吧。
-
計算機
+關注
關注
19文章
7519瀏覽量
88216 -
Server
+關注
關注
0文章
91瀏覽量
24054 -
網絡編程
+關注
關注
0文章
72瀏覽量
10085
發布評論請先 登錄
相關推薦
探討2對4二進制解碼器及4到16二進制解碼器配置

什么是二進制計數器,二進制計數器原理是什么?
二進制電平,什么是二進制電平
基于軟件二進制代碼重用技術綜述
二進制解碼器到底是什么






 工商網監
工商網監
評論