") 再現(xiàn)輝煌:瑞典國(guó)家圖書(shū)館運(yùn)用 AI 解析數(shù)百年數(shù)據(jù)
再現(xiàn)輝煌:瑞典國(guó)家圖書(shū)館運(yùn)用 AI 解析數(shù)百年數(shù)據(jù)
瑞典國(guó)家圖書(shū)館正在使用五百年來(lái)的瑞典語(yǔ)文本訓(xùn)練最先進(jìn)的 AI 模型,以支持歷史、語(yǔ)言學(xué)、媒體研究等方面的人文研究。
從價(jià)值連城的中世紀(jì)手稿到今天的披薩店菜單,瑞典國(guó)家圖書(shū)館在過(guò)去 500 年中收藏了幾乎所有瑞典語(yǔ)出版物。
由于瑞典法律要求一切瑞典語(yǔ)出版物都要上交副本至瑞典國(guó)家圖書(shū)館(也稱(chēng)為瑞典皇家圖書(shū)館),因此該圖書(shū)館的藏品涵蓋了各清晰度的書(shū)籍、報(bào)紙、無(wú)線(xiàn)廣播、電視廣播、互聯(lián)網(wǎng)內(nèi)容、博士論文、明信片、菜單和電子游戲。這個(gè)內(nèi)容豐富的收藏集含近 26 PB 的數(shù)據(jù),是訓(xùn)練尖端 AI 的最佳選擇。
瑞典國(guó)家圖書(shū)館數(shù)據(jù)實(shí)驗(yàn)室 KBLab 的負(fù)責(zé)人 Love B?rjeson 表示:“我們有最好的數(shù)據(jù),所以我們可以構(gòu)建最先進(jìn)的瑞典語(yǔ) AI 模型。”
該團(tuán)隊(duì)使用 NVIDIA DGX 系統(tǒng)開(kāi)發(fā)了二十多個(gè)可在 Hugging Face 上使用的開(kāi)源 Transformer 模型。這些模型推動(dòng)了圖書(shū)館和其他學(xué)術(shù)機(jī)構(gòu)的研究,每月的開(kāi)發(fā)者下載量多達(dá) 20 萬(wàn)。
B?rjeson 表示:“在我們的實(shí)驗(yàn)室成立前,研究者無(wú)法在圖書(shū)館訪問(wèn)數(shù)據(jù)集,他們每次只能查閱一個(gè)對(duì)象。因此,為幫助那些需要大量查閱資料的研究者,創(chuàng)建圖書(shū)館的數(shù)據(jù)集十分必要。”
這樣,研究者很快就能創(chuàng)建專(zhuān)門(mén)的數(shù)據(jù)集。例如,調(diào)出所有描繪教堂的瑞典明信片、所有特定風(fēng)格的文本或是所有提到某一歷史人物的書(shū)籍、報(bào)紙文章及電視廣播。
從圖書(shū)館檔案到 AI 訓(xùn)練數(shù)據(jù)
瑞典國(guó)家圖書(shū)館的數(shù)據(jù)集涵蓋了瑞典語(yǔ)的所有變體,包括各種正式和非正式變體、地區(qū)方言以及隨著時(shí)間的推移而產(chǎn)生的變化。
B?rjeson 表示:“數(shù)據(jù)還在持續(xù)不斷地涌入并增長(zhǎng),我們每個(gè)月都會(huì)增加超過(guò) 50 TB 的新數(shù)據(jù)。在處理成倍增長(zhǎng)的數(shù)據(jù)的同時(shí),我們還要將數(shù)百年前的實(shí)物藏品轉(zhuǎn)換成數(shù)據(jù)錄入,所以我們一直在不斷擴(kuò)大我們的數(shù)據(jù)集。”
2019 年 KBLab 成立后不久,B?rjeson 就看到了運(yùn)用龐大的圖書(shū)館檔案訓(xùn)練 Transformer 語(yǔ)言模型的潛力。谷歌早期的多語(yǔ)言自然語(yǔ)言處理模型含有 5GB 瑞典語(yǔ)文本,他從此受到了啟發(fā)。
KBLab 的第一個(gè)模型使用了谷歌多語(yǔ)言自然語(yǔ)言處理模型 4 倍之多的數(shù)據(jù)——B?rjeson 團(tuán)隊(duì)的目標(biāo)是使用至少 1 TB 的瑞典語(yǔ)文本訓(xùn)練模型。在發(fā)現(xiàn)多語(yǔ)言數(shù)據(jù)集可能提高 AI 的性能之后,這座實(shí)驗(yàn)室開(kāi)始進(jìn)行實(shí)驗(yàn),在其數(shù)據(jù)集中添加荷蘭語(yǔ)、德語(yǔ)和挪威語(yǔ)內(nèi)容。
NVIDIA AI 和 GPU 加速模型開(kāi)發(fā)
該實(shí)驗(yàn)室一開(kāi)始使用的是消費(fèi)級(jí) NVIDIA GPU,但 B?rjeson 很快發(fā)現(xiàn)他的團(tuán)隊(duì)需要數(shù)據(jù)中心規(guī)模的計(jì)算來(lái)訓(xùn)練更大的模型。
B?rjeson 表示:“我們意識(shí)到在小型工作站上無(wú)法完成這項(xiàng)工作,所以 NVIDIA DGX 是明智之選。我們很多的工作離不開(kāi) DGX 系統(tǒng)。”
該實(shí)驗(yàn)室使用兩套來(lái)自瑞典供應(yīng)商 AddPro 的 NVIDIA DGX 系統(tǒng)進(jìn)行本地 AI 開(kāi)發(fā)。這些系統(tǒng)用于處理敏感數(shù)據(jù)、開(kāi)展大規(guī)模實(shí)驗(yàn)和微調(diào)模型。它們還準(zhǔn)備在全歐盟搭載 GPU 的大型超級(jí)計(jì)算機(jī)上進(jìn)行更大規(guī)模的運(yùn)行,其中包括盧森堡的 MeluXina 系統(tǒng)。
B?rjeson 表示:“我們?cè)?DGX 系統(tǒng)上的工作至關(guān)重要,因?yàn)槲覀兿M軌蛟诟咝阅苡?jì)算環(huán)境中做到最好,這必須將超級(jí)計(jì)算機(jī)的作用發(fā)揮到極致。”
該團(tuán)隊(duì)還采用了用于訓(xùn)練大型語(yǔ)言模型的 PyTorch 框架 NVIDIA NeMo Megatron。其內(nèi)置的 NVIDIA CUDA 和 NVIDIA NCCL 庫(kù)可優(yōu)化 GPU 在多節(jié)點(diǎn)系統(tǒng)中的使用。
B?rjeson 表示:“我們十分依賴(lài) NVIDIA 的框架。因?yàn)槲覀儗?shí)驗(yàn)室的規(guī)模較小,無(wú)法派出 50 名工程師優(yōu)化每個(gè)項(xiàng)目的 AI 訓(xùn)練,NVIDIA 的優(yōu)勢(shì)在這就十分明顯了。”
利用多模態(tài)數(shù)據(jù)開(kāi)展人文科學(xué)研究
除了能夠理解瑞典語(yǔ)文本的 Transformer 模型外,KBLab 還有一個(gè)能將聲音轉(zhuǎn)換成文本的 AI 工具。這使得圖書(shū)館能夠?qū)⑵浯罅康臒o(wú)線(xiàn)廣播收藏轉(zhuǎn)換成數(shù)據(jù)集,以便研究者能夠搜索錄音中的具體內(nèi)容。
KBLab 還在開(kāi)發(fā)生成式文本模型,同時(shí)還在研究一個(gè)可以處理視頻并自動(dòng)生成內(nèi)容描述的 AI 模型。
B?rjeson 表示:“我們還希望將各種模態(tài)的數(shù)據(jù)聯(lián)系起來(lái)。當(dāng)你在圖書(shū)館數(shù)據(jù)庫(kù)中搜索一個(gè)特定的詞語(yǔ)時(shí),系統(tǒng)將能夠返回包括文本、音頻和視頻在內(nèi)的結(jié)果。”
KBLab 與哥德堡大學(xué)的研究者開(kāi)展了合作。這些研究者正在使用該 KBLab 的模型開(kāi)發(fā)用于語(yǔ)言學(xué)研究的下游應(yīng)用程序。項(xiàng)目之一是幫助瑞典學(xué)院升級(jí)用于創(chuàng)建瑞典語(yǔ)詞典的數(shù)據(jù)驅(qū)動(dòng)技術(shù)。
B?rjeson 表示:“這些模型的社會(huì)效益遠(yuǎn)遠(yuǎn)超出了我們的最初預(yù)想。”
 ?
?
?
?
?
?點(diǎn)擊“閱讀原文”或掃描下方海報(bào)二維碼,即可免費(fèi)注冊(cè) GTC 23,切莫錯(cuò)過(guò)這場(chǎng) AI 和元宇宙時(shí)代的技術(shù)大會(huì)!
原文標(biāo)題:再現(xiàn)輝煌:瑞典國(guó)家圖書(shū)館運(yùn)用 AI 解析數(shù)百年數(shù)據(jù)
文章出處:【微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3783瀏覽量
91247
原文標(biāo)題:再現(xiàn)輝煌:瑞典國(guó)家圖書(shū)館運(yùn)用 AI 解析數(shù)百年數(shù)據(jù)
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
新型儲(chǔ)能產(chǎn)業(yè)發(fā)展現(xiàn)狀及趨勢(shì)-2024年上半年數(shù)據(jù)發(fā)布簡(jiǎn)版
二維碼掃描頭嵌入在圖書(shū)自助管理設(shè)備中的應(yīng)用案例

如何保障圖書(shū)館用電安全?——安科瑞 丁佳雯

智慧圖書(shū)館能耗監(jiān)測(cè)優(yōu)化管理系統(tǒng)方案
NVIDIA為AI城市挑戰(zhàn)賽構(gòu)建合成數(shù)據(jù)集
榮耀參展百年IFA,折疊新品Magic V3海外正式發(fā)布
數(shù)據(jù)產(chǎn)業(yè)年均增速有望超20%
聚徽-什么是智能圖書(shū)館
OBOO鷗柏智能化臥式觸控查詢(xún)一體機(jī)在大學(xué)圖書(shū)館的創(chuàng)新應(yīng)用案例展覽展示

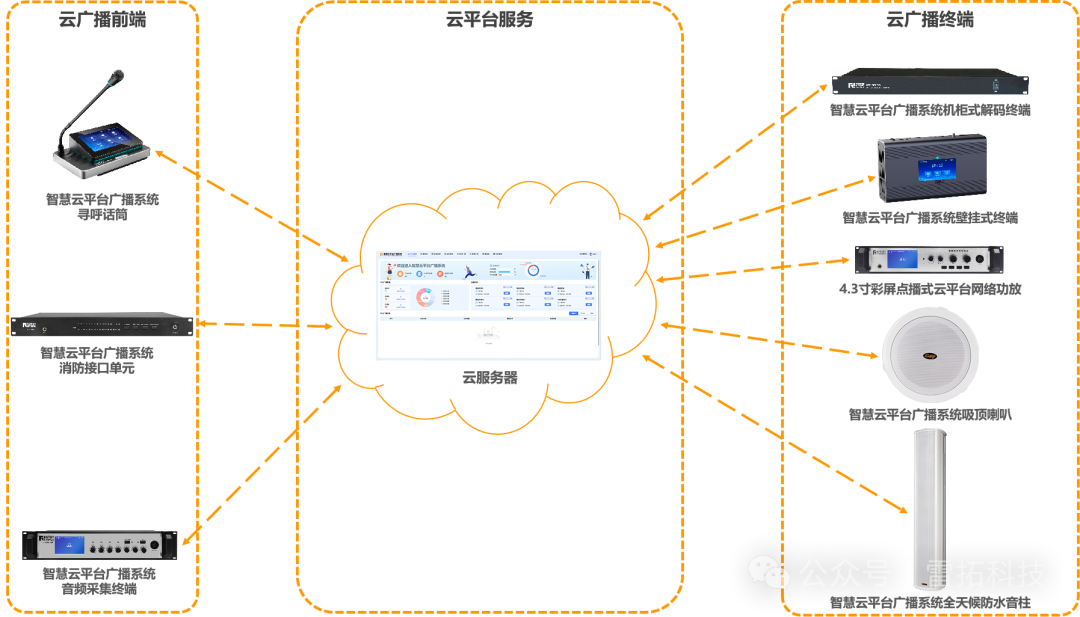
雷拓科技云廣播助力江西省蘆溪縣新圖書(shū)館打造沉浸式觀展體驗(yàn)!
如果通過(guò)物聯(lián)網(wǎng)技術(shù)提升學(xué)校圖書(shū)館管理水平
RFID智能書(shū)架:圖書(shū)館智能化管理的新趨勢(shì)
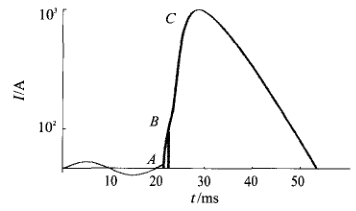
淺談限流式保護(hù)器在高校圖書(shū)館電氣火災(zāi)預(yù)防中的應(yīng)用
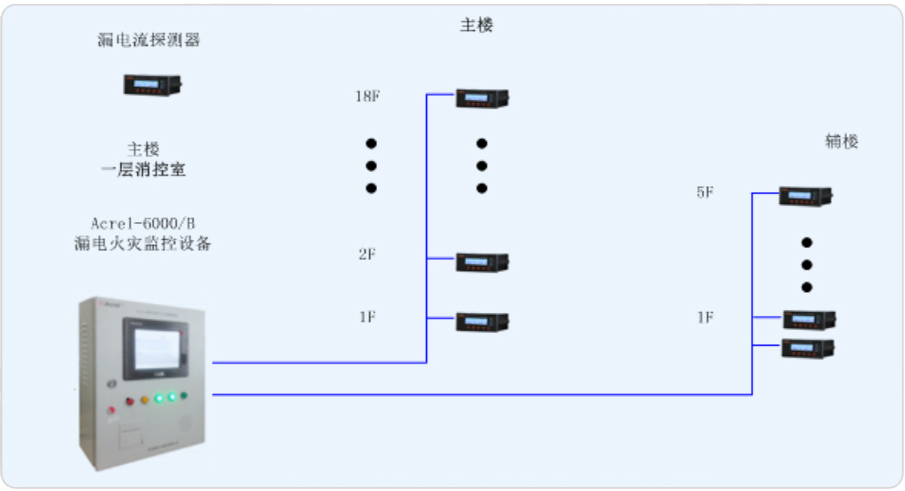
上海交通大學(xué)徐匯校區(qū)包兆龍圖書(shū)館修繕工程電氣火災(zāi)監(jiān)控系統(tǒng) Acrelsale1
基于智能定位功能的座位預(yù)約卡 解決圖書(shū)館找座難題的理想方案






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論